
一、业务场景概述
目标是实现一个公司的申请审批流程,整个业务流程涉及到两种角色,分别为商务角色与管理员角色。整个流程如下图所示:
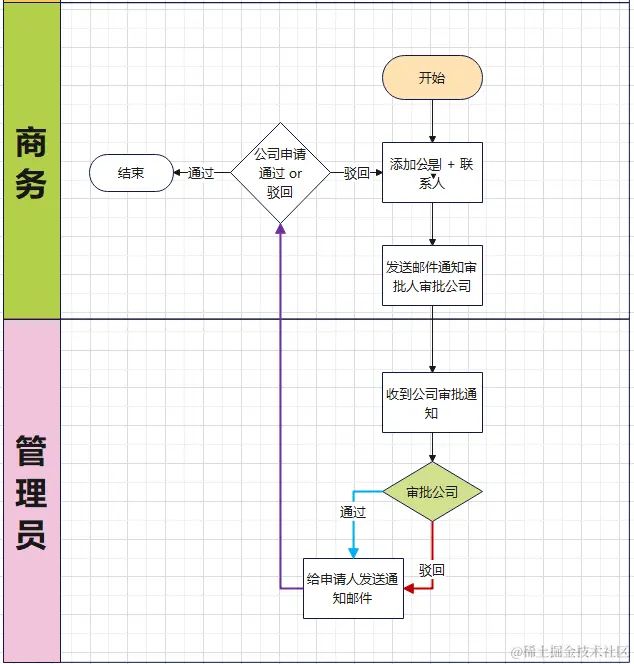
核心流程总结为一句话:商务角色申请添加公司后由管理员进行审批。
商务在添加公司时,可能为了方便,直接填写公司简称,而公司全称可能之前已经被添加过了,为了防止添加重复的公司,所以管理员在针对公司信息审批之前,需要查看以往添加的公司信息里有无同一个公司。
二、实现思路
以上是一个业务场景的大概介绍。从技术层面需要考虑实现的功能点:
分词
与库里已有数据进行匹配
按照匹配度对结果进行排序
分词功能有现成的分词器,所以整个需求的核心重点在于如何与数据库中的数据匹配并按照匹配度排序。
三、模糊匹配技术选型
方案一:引入ES
方案二:利用MySQL实现
本系统规模较小,单纯为了实现这个功能引入ES成本较大,还要涉及到数据同步等问题,系统复杂性会提高,所以尽量使用MySQL已有的功能进行实现。
MySQL提供了以下三种模糊搜索的方式:
like匹配:要求模式串与整个目标字段完全匹配;
RegExp正则匹配:要求目标字段包含模式串即可;
Fulltext全文索引:在字段类型为CHAR,VARCHAR,TEXT的列上创建全文索引,执行SQL进行查询。
针对于上述业务场景,对相关技术进行优劣分析:
like匹配:无法满足需求,所以pass;
全文索引:可定制性差,不支持任意匹配查询,pass;
正则匹配:可实现任意模式匹配,缺点在于执行效率不如全文索引。
针对于这个场景,记录数目相对来说没有那么多,所以对于效率稍低的结果可以接受,因此技术选型方面采用RegExp正则匹配来实现模糊匹配的需求。
四、实现效果展示

五、核心代码
整个逻辑基于 提取公司名称关键信息 -->分词 --> 匹配 三个核心步骤。
对输入的公司名称去除无用信息,保留关键信息。这里的无用信息指的是地名,圆括号,以及集团,股份,有限等。
匹配前处理公司名称
/*** 匹配前去除公司名称的无意义信息* @param targetCompanyName* @return*/private String formatCompanyName(String targetCompanyName){String regex = "(?<province>[^省]+自治区|.*?省|.*?行政区|.*?市)" +"?(?<city>[^市]+自治州|.*?地区|.*?行政单位|.+盟|市辖区|.*?市|.*?县)" +"?(?<county>[^(区|市|县|旗|岛)]+区|.*?市|.*?县|.*?旗|.*?岛)" +"?(?<village>.*)";Matcher matcher = Pattern.compile(regex).matcher(targetCompanyName);while(matcher.find()){String province = matcher.group("province");log.info("province:{}",province);if (StringUtils.isNotBlank(province) && targetCompanyName.contains(province)){targetCompanyName = targetCompanyName.replace(province,"");}log.info("处理完省份的公司名称:{}",targetCompanyName);String city = matcher.group("city");log.info("city:{}",city);if (StringUtils.isNotBlank(city) && targetCompanyName.contains(city)){targetCompanyName = targetCompanyName.replace(city,"");}log.info("处理完城市的公司名称:{}",targetCompanyName);String county = matcher.group("county");log.info("county:{}",county);if (StringUtils.isNotBlank(county) && targetCompanyName.contains(county)){targetCompanyName = targetCompanyName.replace(county,"");}log.info("处理完区县级的公司名称:{}",targetCompanyName);}String[][] address = AddressUtil.ADDRESS;for (String [] city: address) {for (String b : city ) {if (targetCompanyName.contains(b)){targetCompanyName = targetCompanyName.replace(b, "");}}}log.info("处理后的公司名称:{}",targetCompanyName);return targetCompanyName;}
地名工具类
public class AddressUtil {public static final String[][] ADDRESS = {{"北京"},{"天津"},{"安徽","安庆","蚌埠","亳州","巢湖","池州","滁州","阜阳","合肥","淮北","淮南","黄山","六安","马鞍山","宿州","铜陵","芜湖","宣城"},{"澳门"},{"香港"},{"福建","福州","龙岩","南平","宁德","莆田","泉州","厦门","漳州"},{"甘肃","白银","定西","甘南藏族自治州","嘉峪关","金昌","酒泉","兰州","临夏回族自治州","陇南","平凉","庆阳","天水","武威","张掖"},{"广东","潮州","东莞","佛山","广州","河源","惠州","江门","揭阳","茂名","梅州","清远","汕头","汕尾","韶关","深圳","阳江","云浮","湛江","肇庆","中山","珠海"},{"广西","百色","北海","崇左","防城港","贵港","桂林","河池","贺州","来宾","柳州","南宁","钦州","梧州","玉林"},{"贵州","安顺","毕节地区","贵阳","六盘水","黔东南苗族侗族自治州","黔南布依族苗族自治州","黔西南布依族苗族自治州","铜仁地区","遵义"},{"海南","海口","三亚","直辖县级行政区划"},{"河北","保定","沧州","承德","邯郸","衡水","廊坊","秦皇岛","石家庄","唐山","邢台","张家口"},{"河南","安阳","鹤壁","焦作","开封","洛阳","漯河","南阳","平顶山","濮阳","三门峡","商丘","新乡","信阳","许昌","郑州","周口","驻马店"},{"黑龙江","大庆","大兴安岭地区","哈尔滨","鹤岗","黑河","鸡西","佳木斯","牡丹江","七台河","齐齐哈尔","双鸭山","绥化","伊春"},{"湖北","鄂州","恩施土家族苗族自治州","黄冈","黄石","荆门","荆州","十堰","随州","武汉","咸宁","襄樊","孝感","宜昌"},{"湖南","长沙","常德","郴州","衡阳","怀化","娄底","邵阳","湘潭","湘西土家族苗族自治州","益阳","永州","岳阳","张家界","株洲"},{"吉林","白城","白山","长春","吉林","辽源","四平","松原","通化","延边朝鲜族自治州"},{"江苏","常州","淮安","连云港","南京","南通","苏州","宿迁","泰州","无锡","徐州","盐城","扬州","镇江"},{"江西","抚州","赣州","吉安","景德镇","九江","南昌","萍乡","上饶","新余","宜春","鹰潭"},{"辽宁","鞍山","本溪","朝阳","大连","丹东","抚顺","阜新","葫芦岛","锦州","辽阳","盘锦","沈阳","铁岭","营口"},{"内蒙古","阿拉善盟","巴彦淖尔","包头","赤峰","鄂尔多斯","呼和浩特","呼伦贝尔","通辽","乌海","乌兰察布","锡林郭勒盟","兴安盟"},{"宁夏回族","固原","石嘴山","吴忠","银川","中卫"},{"青海","果洛藏族自治州","海北藏族自治州","海东地区","海南藏族自治州","海西蒙古族藏族自治州","黄南藏族自治州","西宁","玉树藏族自治州"},{"山东","滨州","德州","东营","菏泽","济南","济宁","莱芜","聊城","临沂","青岛","日照","泰安","威海","潍坊","烟台","枣庄","淄博"},{"山西","长治","大同","晋城","晋中","临汾","吕梁","朔州","太原","忻州","阳泉","运城"},{"陕西","安康","宝鸡","汉中","商洛","铜川","渭南","西安","咸阳","延安","榆林"},{"上海"},{"四川","阿坝藏族羌族自治州","巴中","成都","达州","德阳","甘孜藏族自治州","广安","广元","乐山","凉山彝族自治州","泸州","眉山","绵阳","内江","南充","攀枝花","遂宁","雅安","宜宾","资阳","自贡"},{"西藏","阿里地区","昌都地区","拉萨","林芝地区","那曲地区","日喀则地区","山南地区"},{"新疆维吾尔","阿克苏地区","阿勒泰地区","巴音郭楞蒙古自治州","博尔塔拉蒙古自治州","昌吉回族自治州","哈密地区","和田地区","喀什地区","克拉玛依","克孜勒苏柯尔克孜自治州","塔城地区","吐鲁番地区","乌鲁木齐","伊犁哈萨克自治州","直辖县级行政区划"},{"云南","保山","楚雄彝族自治州","大理白族自治州","德宏傣族景颇族自治州","迪庆藏族自治州","红河哈尼族彝族自治州","昆明","丽江","临沧","怒江僳僳族自治州","普洱","曲靖","文山壮族苗族自治州","西双版纳傣族自治州","玉溪","昭通"},{"浙江","杭州","湖州","嘉兴","金华","丽水","宁波","衢州","绍兴","台州","温州","舟山"},{"重庆"},{"台湾","台北","高雄","基隆","台中","台南","新竹","嘉义"},};}
pom文件:引入IK分词器相关依赖
<!-- ikAnalyzer 中文分词器 --><dependency><groupId>com.janeluo</groupId><artifactId>ikanalyzer</artifactId><version>2012_u6</version><exclusions><exclusion><groupId>org.apache.lucene</groupId><artifactId>lucene-core</artifactId></exclusion><exclusion><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId></exclusion><exclusion><groupId>org.apache.lucene</groupId><artifactId>lucene-analyzers-common</artifactId></exclusion></exclusions></dependency><!-- lucene-queryParser 查询分析器模块 --><dependency><groupId>org.apache.lucene</groupId><artifactId>lucene-queryparser</artifactId><version>7.3.0</version></dependency>
IKAnalyzerSupport类:用于配置分词器
@Slf4jpublic class IKAnalyzerSupport {/*** IK分词* @param target* @return*/public static List<String> iKSegmenterToList(String target) throws Exception {if (StringUtils.isEmpty(target)){return new ArrayList();}List<String> result = new ArrayList<>();StringReader sr = new StringReader(target);// false:关闭智能分词 (对分词的精度影响较大)IKSegmenter ik = new IKSegmenter(sr, true);Lexeme lex;while((lex=ik.next())!=null) {String lexemeText = lex.getLexemeText();result.add(lexemeText);}return result;}}
ServiceImpl类:进行分词处理
/*** 对目标公司名称进行分词* @param targetCompanyName* @return*/private String splitWord(String targetCompanyName){log.info("对处理后端公司名称进行分词");List<String> splitWord = new ArrayList<>();String result = targetCompanyName;try {splitWord = iKSegmenterToList(targetCompanyName);result = splitWord.stream().map(String::valueOf).distinct().collect(Collectors.joining("|")) ;log.info("分词结果:{}",result);} catch (Exception e) {log.error("分词报错:{}",e.getMessage());}return result;}
ServiceImpl类:匹配核心代码
public JsonResult matchCompanyName(CompanyDTO companyDTO, String accessToken, String localIp) {// 对公司名称进行处理String sourceCompanyName = companyDTO.getCompanyName();String targetCompanyName = sourceCompanyName;log.info("处理前公司名称:{}",targetCompanyName);// 处理圆括号targetCompanyName = targetCompanyName.replaceAll("[(]|[)]|[(]|[)]","");// 处理公司相关关键词targetCompanyName = targetCompanyName.replaceAll("[(集团|股份|有限|责任|分公司)]", "");if (!targetCompanyName.contains("银行")){// 去除行政区域targetCompanyName = formatCompanyName(targetCompanyName);}// 分词String splitCompanyName = splitWord(targetCompanyName);// 匹配List<Company> matchedCompany = companyRepository.queryMatchCompanyName(splitCompanyName,targetCompanyName);List<String> result = new ArrayList();for (Company companyInfo : matchedCompany) {result.add(companyInfo.getCompanyName());if (companyDTO.getCompanyId().equals(companyInfo.getCompanyId())){result.remove(companyInfo.getCompanyName());}}return JsonResult.successResult(result);}
Repository类:编写SQL语句
/*** 模糊匹配公司名称* @param companyNameRegex 分词后的公司名称* @param companyName 分词前的公司名称* @return*/@Query(value ="SELECT * FROM company WHERE isDeleted = '0' and companyName REGEXP ?1ORDER BY length(REPLACE(companyName,?2,''))/length(companyName) ",nativeQuery = true)List<Company> queryMatchCompanyName(String companyNameRegex,String companyName);
按照匹配度排序这个功能点,LENGTH(companyName)返回companyName的长度,LENGTH(REPLACE(companyName, ?2, ''))计算出companyName中关键词出现的次数。通过这种方式,我们可以根据匹配程度进行排序,匹配次数越多的公司名称排序越靠前。
参考资料
MySQL模糊搜索
zhuanlan.zhihu.com/p/343198664
IK分词器集成Spring Boot
blog.csdn.net/Cy_LightBule/article/details/107181771








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721