
MySQL 主从延时的原因是什么?
具体哪个环节发生延时?
如何解决呢?
对于这“三连问”,极少有同学能通关,甚至有同学连主从复制原理都不清楚。
这个并不是存粹的八股文,因为在实际工作场景中,很多同学都遇到过。
不多说,上文章目录。
一、什么是主从延时?
有时候我们遇到从数据库中获取不到信息的诡异问题时,会纠结于代码中是否有一些逻辑会把之前写入的内容删除,但是你又会发现,过了一段时间再去查询时又可以读到数据了,这基本上就是主从延迟在作怪。
主从延迟,其实就是“从库回放” 完成的时间,与 “主库写 binlog” 完成时间的差值,会导致从库查询的数据,和主库的不一致。
二、为什么会主从延时?
探讨这个问题前,我们需要知道主从复制的原理。
MySQL 的主从复制是依赖于 binlog,也就是记录 MySQL 上的所有变化并以二进制形式保存在磁盘上二进制日志文件。
主从复制就是将 binlog 中的数据从主库传输到从库上,一般这个过程是异步的,即主库上的操作不会等待 binlog 同步地完成。
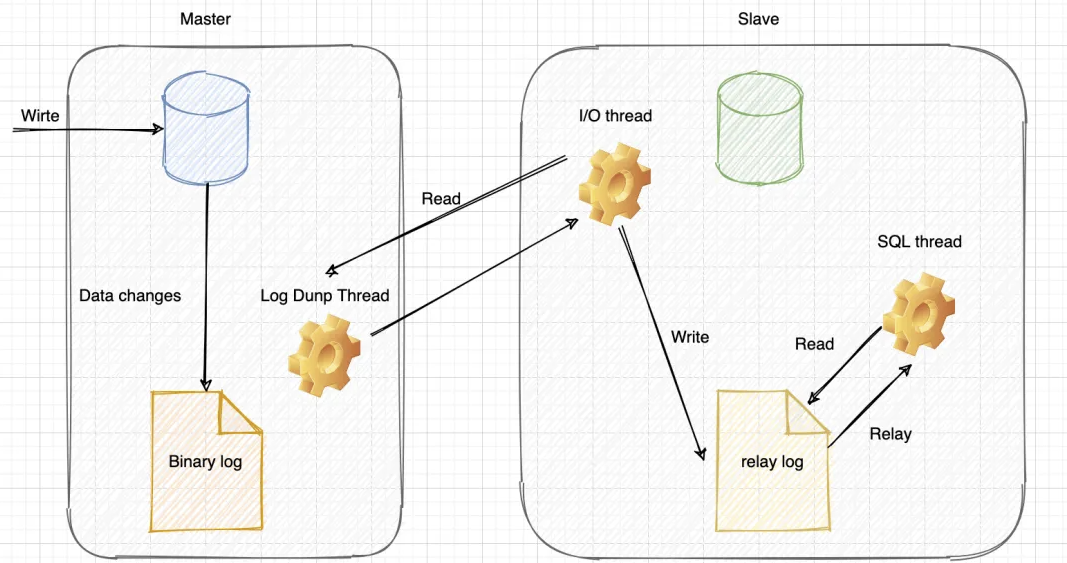
详细流程如下:
主库写 binlog:主库的更新 SQL(update、insert、delete) 被写到 binlog;
主库发送 binlog:主库创建一个 log dump 线程来发送 binlog 给从库;
从库写 relay log:从库在连接到主节点时会创建一个 IO 线程,以请求主库更新的 binlog,并且把接收到的 binlog 信息写入一个叫做 relay log 的日志文件;
从库回放:从库还会创建一个 SQL 线程读取 relay log 中的内容,并且在从库中做回放,最终实现主从的一致性。
我们分析一下主从复制的过程。
MySQL 的主从复制都是单线程的操作,主库对所有 DDL 和 DML 产生 binlog,binlog 是顺序写,所以效率很高。
Slave 的 Slave_IO_Running 线程会到主库取日志,放入 relay log,效率会比较高。
Slave 的 Slave_SQL_Running 线程将主库的 DDL 和 DML 操作都在 Slave 实施,DML 和 DDL 的 IO 操作是随机的,不是顺序的,因此成本会很高。
还可能是 Slave 上的其他查询产生 lock 争用,由于 Slave_SQL_Running 也是单线程的,所以一个 DDL 卡住了,需要执行 10 分钟,那么所有之后的 DDL 会等待这个 DDL 执行完才会继续执行,这就导致了延时。
总结一下主从延迟的主要原因:主从延迟主要是出现在 “relay log 回放” 这一步,当主库的 TPS 并发较高,产生的 DDL 数量超过从库一个 SQL 线程所能承受的范围,那么延时就产生了,当然还有就是可能与从库的大型 query 语句产生了锁等待。
三、如何解决主从延时?
我们先看看,哪些情况会导致主从延时:
从库机器性能:从库机器比主库的机器性能差,只需选择主从库一样规格的机器就好。
从库压力大:可以搞了一主多从的架构,还可以把 binlog 接入到 Hadoop 这类系统,让它们提供查询的能力。
从库过多:要避免复制的从节点数量过多,从库数据一般以3-5个为宜。
大事务:如果一个事务执行就要 10 分钟,那么主库执行完后,给到从库执行,最后这个事务可能就会导致从库延迟 10 分钟啦。日常开发中,不要一次性 delete 太多 SQL,需要分批进行,另外大表的 DDL 语句,也会导致大事务。
网络延迟:优化网络,比如带宽 20M 升级到 100M。
MySQL 版本低:低版本的 MySQL 只支持单线程复制,如果主库并发高,来不及传送到从库,就会导致延迟,可以换用更高版本的 MySQL,支持多线程复制。
面试时,有些同学能回答出使用缓存、查询主库、提升机器配置等,仅仅这些么?
最容易想到的方法,缩短主从同步时间:
提升从库机器配置,可以和主库一样,甚至更好;
避免大事务;
搞多个从库,即一主多从,分担从库查询压力;
优化网络宽带;
选择高版本 MySQL,支持主库 binlog 多线程复制。
也可以从业务场景考虑:
使用缓存:我们在同步写数据库的同时,也把数据写到缓存,查询数据时,会先查询缓存,不过这种情况会带来 MySQL 和 Redis 数据一致性问题。
查询主库:直接查询主库,这种情况会给主库太大压力,核心场景可以使用,比如订单支付。
如果能把上面基本回答出来,就已经非常厉害了,还有么?
其实还可以在 MySQL 架构上来考虑。
主库对数据安全性较高,设置配置如下:
sync_binlog = 1innodb_flush_log_at_trx_commit = 1
而 slave 不需要这么高的数据安全,完全可以将 sync_binlog 设置为 0,或者关闭 binlog,innodb_flushlog 也可以设置为 0,来提高 sql 的执行效率。
架构方案:使用多台 slave 来分摊读请求,再从这些 slave 中取一台专用的服务器,只作为备份用,不进行其他任何操作,比如设置 sync_binlog 为0,或者关闭 binglog 等,提升从库查询性能。
再问一下,还有么?可以在评论区讨论~
四、后记
再回过头来看这个问题,估计很多同学能回答出一二,但是这个不能成为你的加分项。
面对如此激烈的竞争环境,同样一个问题,你就需要比别人掌握得更多,回答得更全面,面试官才能对你刮目相看。
其实笔者当年面试小米时,也面试过这个问题,当时就是基于上面回答的。
后来的一次 MySQL 分享,讲得还不错,当时主管就说,笔者的 MySQL 掌握得挺好的,记得当时面试时问过一个 MySQL 主从复制问题,他都能回答到非常底层。
没想到,这都一年多了,当时的那场面试,居然给主管留下那么深刻的印象。
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721