
张松坡,腾讯云数据库架构师,主要负责腾讯云数据库MySQL、Redis等数据库架构设计、数据库运维、运营开发等工作。曾就职于腾讯新闻、腾讯视频。
写在前面,感谢腾讯云数据库架构师团队祝海强、杜川、刘志祥在排障思路、源码分析上面提供的帮助,让我学习到了很多,不敢居功,特此鸣谢!
本文将以数据库实际使用中的某典型案例来分析造成主从延迟的原因。
1、某用户在使用数据库过程中,出现主从延迟很大的情况,show slave status\G,已经差了60多个binlog了。

2、观察发现,应该是卡在一个大事物上面(Retrieved_Gtid_Set一直在上升,但是Executed_Gtid_Set卡在一个点不动了),通过分析relay_log找到这个大事物:是对表A进行删除操作的一个事物。
Relay_Log_File: relay-bin.000010
Relay_Log_Pos: 95133771
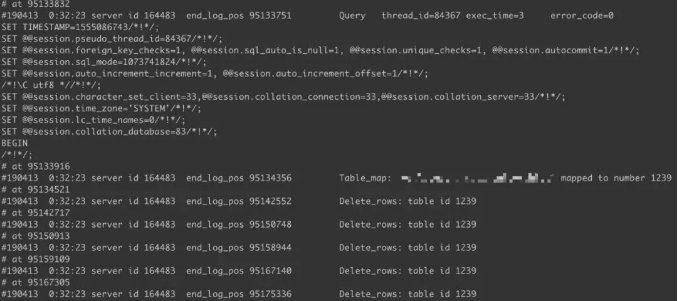
看到这里,感觉又是一例在ROW模式下表没有主键,引起的主从延迟。看看表结构确认一下,发现这张表不小,字段有上百个,有主键,且是一张分区表,分区很多。这就有意思了!并不是我们碰到过多次的由于ROW模式下没有主键,DML引起的主从延迟(PS:为什么这种情况下会引起延迟?而是有主键,且走了二级索引,那为什么回放还会这么慢呢?)。
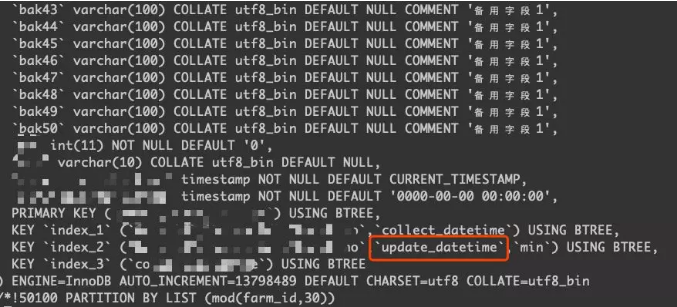
后来了解到用户是在存储过程里面调用delete语句来进行归档数据清理,看了一下存储过程,现在的问题就可以简化为:在存储过程中调用delete语句,走了二级索引删除有主键的分区表,从机回放延迟。
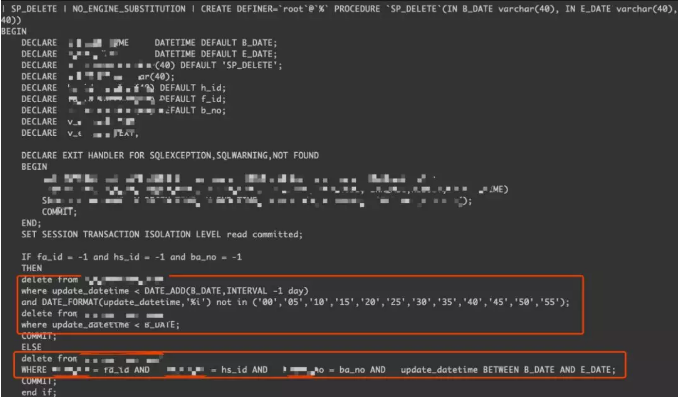
这个时候,我们需要拆解一下问题,控制好变量,一个一个的查:
1、直接执行delete,SQL会以statement的格式出现,且不会产生主从延迟。
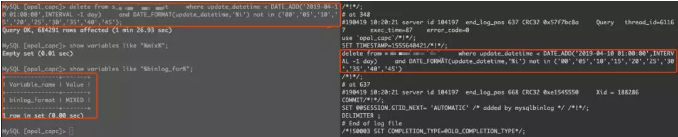

2、调用procedure,该delete语句在procedure中执行的时候会变成ROW格式,且会导致延迟。
OK,有以上两个测试,我们的问题可以聚焦为:
1、为什么同样delete语句,直接执行和在procedure里面执行记录的binlog格式不一样(ROW格式的binlog导致回放慢,全局设置在mixed模式下,这条SQL应该走的是statement格式,为什么在procedure里执行就变成了ROW格式,怎么样才能让这条SQL再procedure里执行变成statement记录到binlog里面)。
delete from xxxxx
where update_datetime < DATE_ADD(B_DATE,INTERVAL -1 day)
and DATE_FORMAT(update_datetime,'%i') not in ('00','05','10','15','20','25','30');
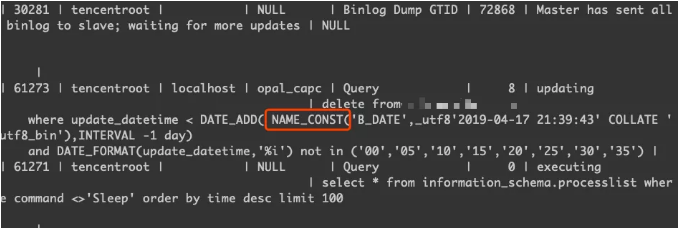
通过show processlist,可以看到这条delete在procedure内部执行的时候,被MySQL自动加上了NAME_CONST函数,所以导致了以ROW模式记录binlog格式。那为什么在procedure中会被改写成这样的SQL呢?怎么样才能让这条SQL记录为statement的格式呢?

看了MySQL官方在procedure里面的限制描述,MySQL会自动加上NAME_CONST主要是为了从机可以识别到B_DATE这个SP的Local vairable,不至于从机回放的时候报错。
2、为什么ROW模式的binlog在从库回放的时候,即使delete的这张表有主键也很慢。
我们先看一下SQL线程回放是卡在哪里了?为什么会慢?
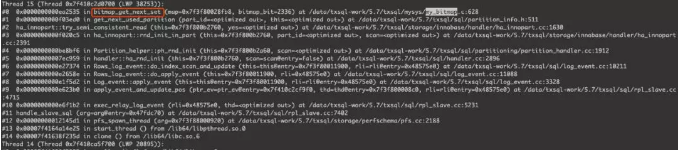
通过pstack抓取堆栈,找到SQL_thread线程对应的thread 15,再结合perf信息,可以看到从机回放慢是卡在了bitmap_get_next_set()。
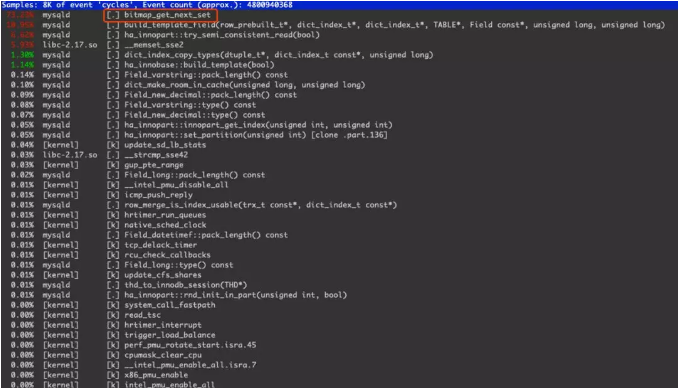
看一下bitmap_get_next_set()的代码。
bitmap_get_next_set()都是一些位运算,速度按理来说应该很快。所以不应该是程序卡在了这个函数中,大概率是因为多次调用了这个函数。所以我们再往上层继续看代码。
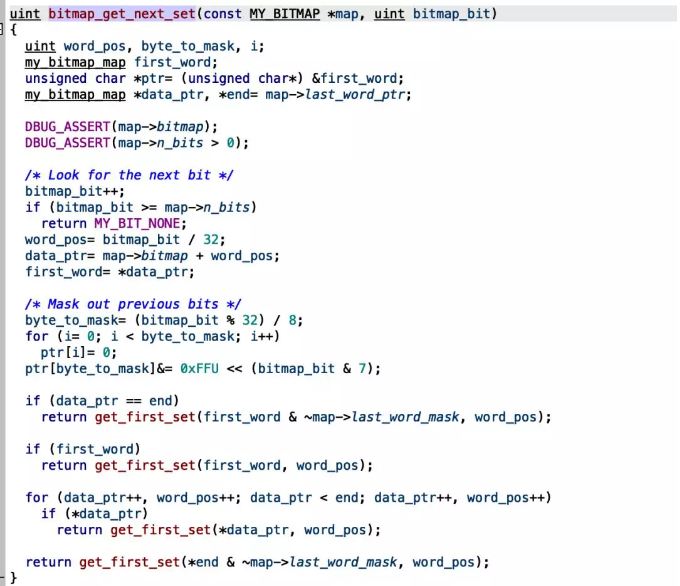
get_next_used_partition(uint part_id) 直接调用了bitmap_get_next_set(),继续往上看。

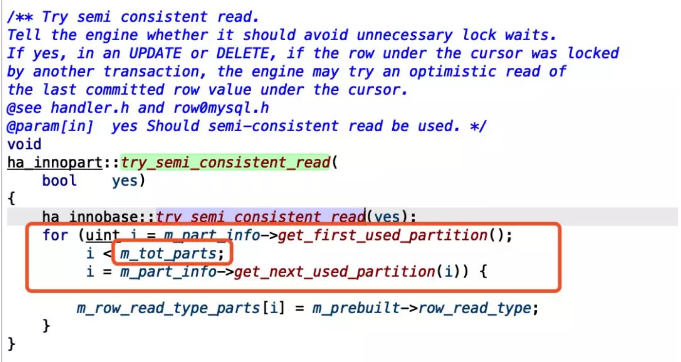
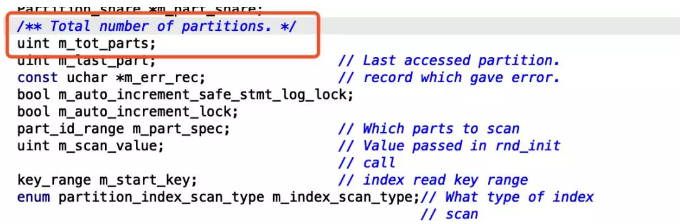
try_semi_consistent_read() 这个函数中出现了可疑的循环,这里会调用m_tot_parts次get_next_used_partition。看了一下定义m_tot_parts是分区表的总分区数!!!
看到这里,就真相大白了。
这个delele的SQL变更的行数大约在300W行左右,总共的分区表数是7200个。那么这里调用bitmap_get_next_set的次数就被放大成了216亿次!
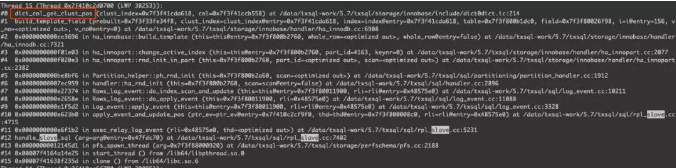
对比以statement格式回放,从机的堆栈信息,并不会进入bitmap_get_next_set。
分析了这么久,怎么处理这么问题呢?
方案1:我们最后在SP中强制制定了session的binlog_format=statement,让这条delete在从机以statement的模式回放,这样就避免触发MySQL中的这个bug。
方案2:修复内核。
方案3:在shell里面去调度,而不使用存储过程。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721