
在众多的MySQL开源软件中,Galera是非常有特色的,它的特点及优势是具有良好的并发性和一致性。Galera Cluster的主要用途是为MySQL提供一致性的集群化解决方案,以一个dlopenable通用复制库的形式提供给MySQL,并通过自身的Write-Set提供复制服务,实现MySQL的多线程并行复制。此外,它自带集群节点管理机制,可以主动监测集群节点状态,自动管理有问题的数据节点,同时也可以实现集群的多点写入和平滑扩容。它对待事务的行为时,要么在所有节点上执行,要么都不执行,这种实现机制决定了它对待一致性的行为非常严格,能够非常完美地保证MySQL集群的数据一致性。
目前,对Galera Cluster的封装有两个,虽然名称不同,但实质都是一样的,使用的都是Galere群集。一个是MySQL的创始人Monty在自己全新的MariaDB上实现的MariaDB Cluster,一个是著名的MySQL服务和工具提供商Percona实现的Percona Xtradb Cluster,简称为PXC。
从2016年开始,我参与了“移动云”的MySQL数据库运维管理工作。“移动云”是一个不断发展壮大的云服务供应商,订单和用户数据非常重要,随着“移动云”在网用户数量的不断增长,对数据库的高可用性和数据一致性提出了更高的要求。经过长期研究,不断地试错,终于在Galera的基础上,实现了一套自己的MySQL运维方案,截止到现在,已经有相当数量的线上集群运行着经过标准化改造的PXC,在这个过程中,我们也积累了很多Galera的技术经验,希望这些经验也能帮助其他Galera使用者解决疑难或规避问题。
Percona XtraDB Cluster是一个完全开源的MySQL的高可用性解决方案。它将Percona Server和Percona XtraBackup与Galera库集成,以实现同步多主复制。集群由节点组成,其中每个节点包含同一组数据同步的跨节点。推荐的配置是至少有3个节点。每个节点都是常规的MySQL服务器实例(例如Percona Server)。可以将现有的MySQL服务器实例转换为节点,并使用此节点作为基础来运行集群。还可以从集群中分离任何节点,并将其用作常规的MySQL服务器实例。

集群为多主的模式,三个节点之间完全是对等的,都可以作为主节点,用户可以使用结构化查询语言(SQL)对数据进行修改和查询。该系统采用share nothing的架构,每个节点都可以提供读写服务。任何节点的修改都会自动同步到所有节点,当有客户端在某个节点写入数据时,集群会将新数据自动同步到其它节点,具有严格的数据一致性。
集群节点间通过同步复制进行数据同步,通过心跳实现异常节点的检测和剔除。配合上层的负载均衡,可以实现集群的高可用,单个节点宕机不会影响服务。在具有3个节点的基本设置中,将任何节点关闭,Percona XtraDB Cluster仍可以继续工作。在任何时间点,可以关闭任何节点以执行维护或更改配置。即使在计划外情况(如节点崩溃或它网络变得不可用),群集会继续工作,可在工作节点上运行查询。
如果在节点关闭时对数据进行了更改,则节点在加入时可以使用两个选项加入集群:
1、State Snapshot Transfer(SST)是将所有数据从一个节点复制到另一个节点的过程。当新节点加入群集并从现有节点接收所有数据时,通常使用SST。Percona XtraDB群集中有三种SST方法:
mysqldump
rsync
xtrabackup
mysqldump和rsync的缺点是,你的集群在数据存在时变成READ-ONLY 复制(SST应用FLUSH TABLES WITH READ LOCK命令)。
SST使用XtraBackup不需要READ LOCK命令整个同步过程中,只要同步.FRM文件(一样定期备份)。
2、Incremental State Transfer(IST)是指仅将增量更改从一个节点复制到另一个节点。即使在群集没有锁定为只读状态,SST在正常操作服务时可能会侵入和干扰。IST可以避免这样。如果1个节点在很短的时间出现故障,它只能获取发生在它失效时发生的那些更改。IST是在节点上使用高速缓存机制来实现的。每个节点包含一个缓存,环形缓冲区(大小可配置)最后N个更改,并且节点间能够传输该高速缓存的一部分。显然,只有当转移所需的变化量小于N时IST才能完成。如果它超过N则加入节点必须执行SST。
可以使用以下命令监视节点的当前状态:
SHOW STATUS LIKE 'wsrep_local_state_comment';
当节点处于Synced(6)状态时,它是集群的一部分并准备处理流量。
多主复制意味着可以写入任何节点并确保写入对集群中所有节点都是一致的。这与常规MySQL复制不同,在常规MySQL复制中,您必须将写入应用于master以确保它被同步。
事务在本地节点执行时采取乐观策略,成功广播到所有节点后再做冲突检测;
检测出冲突是,本地事务优先被回滚;
每个节点独立、异步执行队列中的write set;
事务在本地节点执行成功返回客户端后,其他节点保证该事务一定会被执行,因此有可能存在延时,即虚拟同步。
对于多主复制,任何写入都在所有节点上提交或根本不提交。所有查询都在节点上本地执行,并且仅在COMMIT上有特殊处理。当COMMIT查询发出时,事务必须通过所有节点上的认证。如果它没有通过,你会收到ERROR作为响应。通过之后,事务在本地节点上应用。COMMIT的响应时间包括以下内容:
网络往返时间;
认证时间;
本地申请。
注意:在远程节点上应用事务不会影响COMMIT的响应时间。
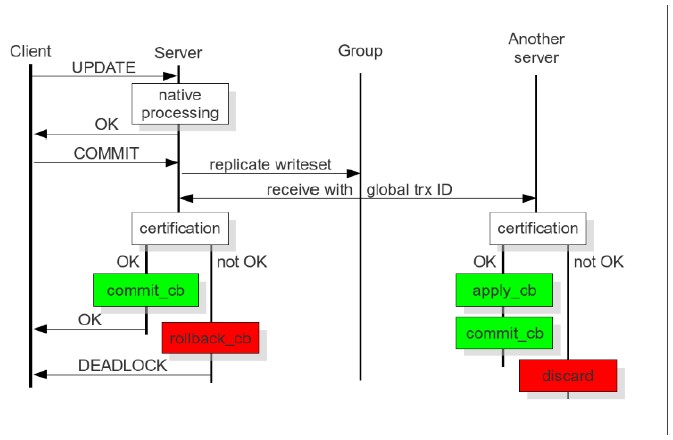
这种架构有两个重要的后果:
可以并行使用几个应用程序。这实现了真正的并行复制。使用 wsrep_slave_threads 变量配置的线程从机可以有多个并行。
slave可能有一个小的时间段不同步。这是因为master可以申请事件比slave更快。如果你从slave读取,可以读取尚未更改的数据。但可以通过设置 wsrep_causal_reads = ON 变量来更改。在这种情况下,在slave上读取将等待,直到事件被应用(会明显增加读取的响应时间)。Slave和Master之间的差距是这种复制被称为虚拟同步的原因,而不是真正的同步复制。
所以如果运行写事务到两个不同的节点,集群将使用乐观锁。事务在个别查询期间不会检查可能的锁冲突,而是在COMMIT阶段,可能会收到ERROR响应。
前面了解了PXC是虚拟同步,事务在本地节点提交成功时,其他节点保证执行该事务。在提交事务时,本地节点把事务复制到所有节点,之后各个节点独立、异步地进行certification test、事务插入待执行队列、执行事务。
然而由于不同节点之前执行事务的速度不一样,长时间运行后,慢节点的待执行队列可能会越积越长,最终导致事务丢失。PXC继承了Galera的flow control机制,作用是协调各个节点,保证所有节点执行事务的速度大于队列增长的速度。实现原理是,集群中同时只有一个节点可以广播消息,每个节点都会获得广播消息的机会,当慢节点的执行队列超过一定长度后,它会广播一个FC_PAUSE消息,其他节点收到消息后会暂缓广播消息,知道该慢节点的执行队列长度减少到一定程度后,集群数据同步又开始恢复。
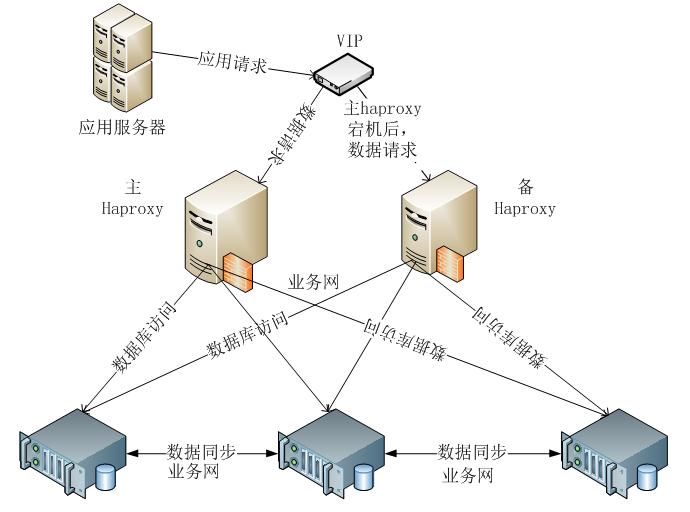
PXC部署架构分本地存储和网络存储两种情况。其中,采用本地存储的架构,其架构图如下图:
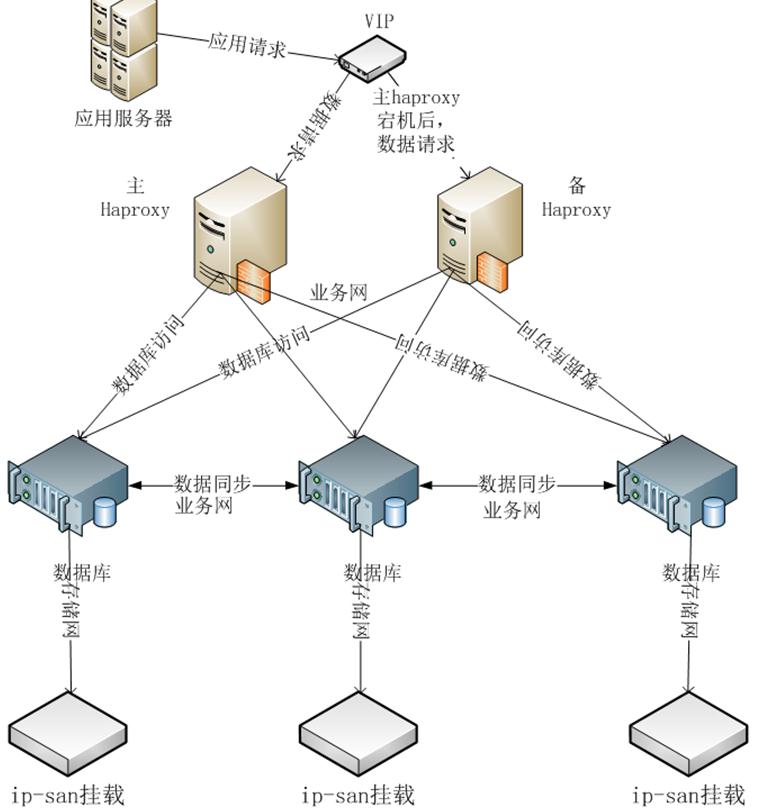
采用网络存储的架构,其架构图如下:
介绍完PXC的原理和架构,下面看一下具体的日常运维工作。
数据库巡检的内容通常涵盖主机硬件、操作系统和MySQL巡检项。其中,主机/os巡检主要包括:主机的硬件配置、CPU/内存/磁盘使用率以及磁盘的I/O使用情况;MySQL巡检项包括:数据库配置、用户权限、大表数据量、业务表主键和自增长情况、数据库的并发性、当前和历史连接情况统计、备份执行情况以及日志记录和慢SQL的分析优化等。

1、查看MySQL服务器配置信息及运行状况
通过show variables来查看mysql服务器配置信息,例如show variables like '%slow%';用于查看慢查询,show variables like 'max_connections';;用于查看最大连接数。
通过ps -ef | grep mysql查看mysql进程运行状况。
2、通过show status统计各种SQL的执行频率
通过show status可以查看服务器状态信息。show status可以根据需要显示session 级别的统计结果和global级别的统计结果。
1)以下几个参数对Myisam和Innodb存储引擎都计数:
Com_select 执行select 操作的次数,一次查询只累加1;
Com_insert 执行insert 操作的次数,对于批量插入的insert 操作,只累加一次;
Com_update 执行update 操作的次数;
Com_delete 执行delete 操作的次数。
2)以下几个参数是针对Innodb存储引擎计数的,累加的算法也略有不同:
Innodb_rows_read 执行select 查询返回的行数;
Innodb_rows_inserted 执行insert 操作插入的行数;
Innodb_rows_updated 执行update 操作更新的行数;
Innodb_rows_deleted 执行delete 操作删除的行数。
通过以上几个参数,可以很容易的了解当前数据库的应用是以插入更新为主还是以查询操作为主,以及各种类型的SQL大致的执行比例是多少。对于更新操作的计数,是对执行次数的计数,不论提交还是回滚都会累加。
对于事务型的应用,通过Com_commit和Com_rollback可以了解事务提交和回滚的情况,对于回滚操作非常频繁的数据库,可能意味着应用编写存在问题。
3)以下几个参数便于我们了解数据库的基本情况:
Connections 试图连接Mysql 服务器的次数;
Uptime 服务器工作时间;
Slow_queries 慢查询的次数。
3、通过show status判断系统瓶颈
1)QPS(每秒Query量)
QPS = Questions(or Queries) / seconds
mysql > show global status like 'Question%';
2)TPS(每秒事务量)
TPS = (Com_commit + Com_rollback) / seconds
mysql > show global status like 'Com_commit';
mysql > show global status like 'Com_rollback';
3)key Buffer 命中率
mysql>show global status like 'key%';
key_buffer_read_hits = (1-key_reads / key_read_requests) * 100%
key_buffer_write_hits = (1-key_writes / key_write_requests) * 100%
4)InnoDB Buffer命中率
mysql> show status like 'innodb_buffer_pool_read%';
innodb_buffer_read_hits = (1 - innodb_buffer_pool_reads /
innodb_buffer_pool_read_requests) * 100%
5)Query Cache命中率
mysql> show status like 'Qcache%';
Query_cache_hits = (Qcahce_hits / (Qcache_hits + Qcache_inserts )) * 100%;
6)Table Cache状态量
mysql> show global status like 'open%';
比较open_tables与opend_tables值。
7)Thread Cache 命中率
mysql> show global status like 'Thread%';
mysql> show global status like 'Connections';
Thread_cache_hits = (1 - Threads_created / connections ) * 100%
创建用来处理连接的线程数。如果 Threads_created 较大,你可能要增加 thread_cache_size 值。缓存访问率的计算方法 Threads_created/Connections。
8)锁定状态
mysql> show global status like '%lock%';
Table_locks_waited/Table_locks_immediate 如果这个比值比较大的话,说明表锁造成的阻塞比较严重。
Innodb_row_lock_waits:innodb行锁,太大可能是间隙锁造成的。
Table_locks_waited:不能立即获得的表的锁的次数。如果该值较高并且有性能问题,应首先优化查询,然后拆分表或使用复制。
9)Tmp Table 状况(临时表状况)
mysql >show status like 'Created_tmp%';
Created_tmp_disk_tables/Created_tmp_tables比值最好不要超过10%,如果Created_tmp_tables值比较大,可能是排序子句过多或者是连接子句不够优化。
10)Binlog Cache 使用状况
mysql > show status like 'Binlog_cache%';
如果Binlog_cache_disk_use值不为0 ,可能需要调大 binlog_cache_size大小。
11)Innodb_log_waits
mysql > show status like 'innodb_log_waits';
Innodb_log_waits值不等于0的话,表明 innodb log buffer 因为空间不足而等待。
12)连接数大小——max_connections
mysql> show variables like 'max_connections';
+-----------------------+-------+
| Variable_name | Value |
+----------------------+--------+
| max_connections | 500 |
+---------------------+--------+
mysql> show global status like 'max_used_connections';
+------------------------------+--------+
| Variable_name | Value |
+------------------------------+--------+
| Max_used_connections | 498 |
+-----------------------------+--------+
设置的最大连接数是500,而响应的连接数是498 。
max_used_connections / max_connections * 100% = 99.6% (理想值 ≈ 85%)
13)Handler_read_rnd
mysql> show status like 'Handler_read_rnd';
如果 Handler_read_rnd 太大 ,则你写的 SQL 语句里很多查询都是要扫描整个表,而没有发挥键的作用。
14)Key_reads
mysql> show status like 'key_read%';
+--------------------------+---------+
| Variable_name | Value |
+--------------------------+---------+
| Key_read_requests | 1190 |
| Key_reads | 2 |
+--------------------------+---------+
如果 Key_reads 太大,则应该把 my.cnf 中 key_buffer_size 变大,可以用 Key_reads/Key_read_requests计算出 cache 失败率。
15)Handler_read_rnd
mysql> show status like 'Handler_read_rnd';
根据固定位置读一行的请求数。如果正执行大量查询并需要对结果进行排序该值较高。可能使用了大量需要MySQL 扫描整个表的查询或连接没有正确使用键。
16)Handler_read_rnd_next
mysql>show status like 'Handler_read_rnd_next';
在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
17)Select_full_join
mysql>show status like 'Select_full_join';
没有使用索引的联接的数量。如果该值不为 0, 你应仔细检查表的索引。
18)Select_range_check
mysql>show status like 'Select_range_check';
在每一行数据后对键值进行检查的不带键值的联接的数量。如果不为 0 ,你应仔细检查表的索引。
19)Sort_merge_passes
mysql>show status like 'Sort_merge_passes';
排序算法已经执行的合并的数量。如果这个变量值较大,应考虑增加 sort_buffer_size 系统变量的值。
20)Handler_read_first
mysql>show status like 'Handler_read_first';
索引中第一条被读的次数。如果较高,它表明服务器正执行大量全索引扫描。例如, SELECT col1 FROM foo ,假定col1 有索引。
21)Handler_read_key
mysql>show status like 'Handler_read_key';
根据键读一行的请求数。如果较高,说明查询和表的索引正确。
22)Handler_read_next
mysql>show status like 'Handler_read_next';
按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。
23) Handler_read_prev
mysql>show status like 'Handler_read_prev';
按照键顺序读前一行的请求数。该读方法主要用于优化 ORDER BY ... DESC 。
24)Handler_read_rnd
mysql>show status like 'Handler_read_rnd';
根据固定位置读一行的请求数。如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要MySQL 扫描整个表的查询或你的连接没有正确使用键。
4、打开相应的监控信息
1)error log
在配置文件my.cnf中进行配置,在运行过程中不能改变。
2)打开慢查询
set global slow_query_log='ON';
3)设置慢查询的时间阈值
set global long_query_time = 0.1;
4)未使用索引的sql语句打开
set global log_queries_not_using_indexes='ON
早期我们通过执行自动化脚本来输出巡检报告,巡检报告内容需要人工去检查和确认,执行巡检脚本主要包括以下步骤:
首先是,在本地下载python3.5并安装,打开后进入python解析器;
通过pip方式安装python依赖包;
因为脚本中需要获取graphid,要登录zabbix管理网站去获取;
然后登录堡垒机,配置端口转发策略;
登录每一套数据库,创建数据库巡检账号;
最后在本地执行巡检脚本,并最终合成word巡检报告。
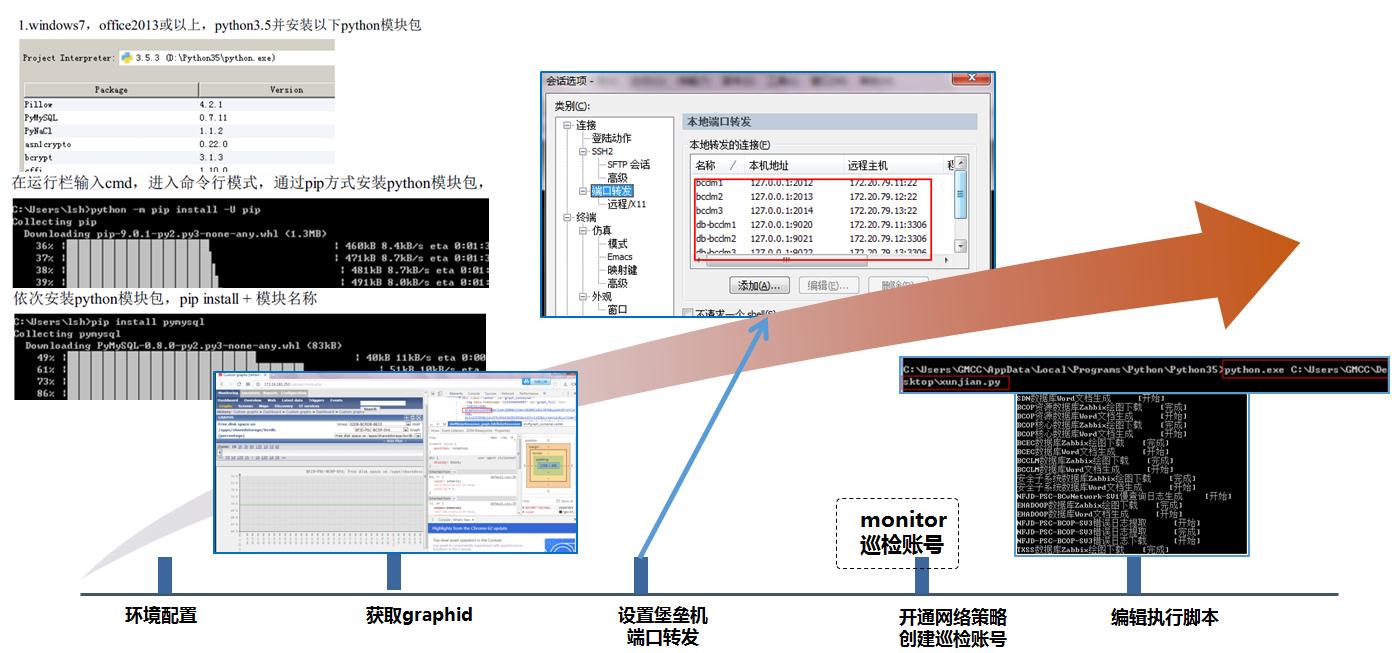
虽然比手工执行巡检,要简化很多,并且可以按资源池批量执行巡检,但总的来说过程还是略繁琐。目前我们在做的是采用平台化的方式,取代传统的脚本和工具巡检。通过搭建数据库管理平台,实现巡检管理,其中一键巡检功能用于数据库的例行巡检。可选择多台数据库批量执行巡检。巡检结果能在web页面上查看。并针对每个数据库实例会生成一份标准格式的巡检报告,报告可以从web页面直接下载。

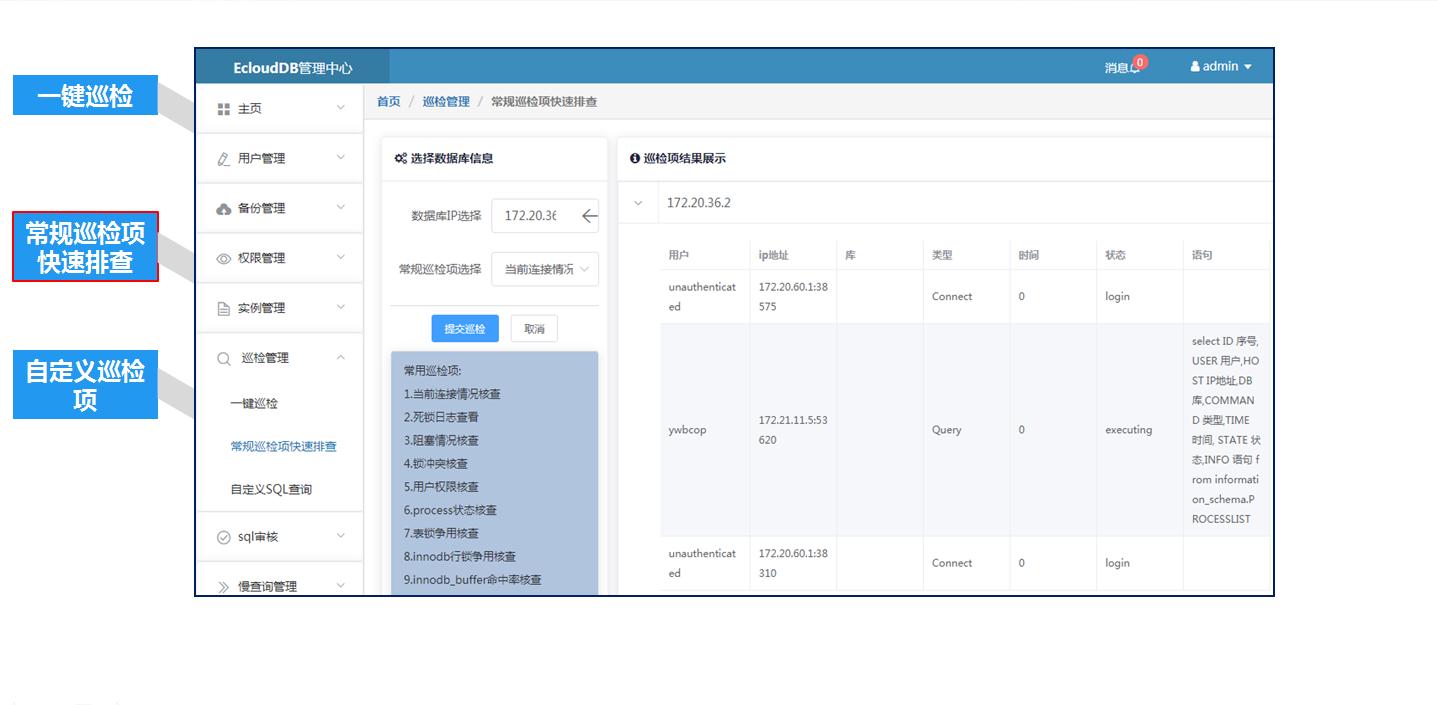
另外,平台也提供了快速巡检的功能,用于对一些常规项巡检进行快速排查,常规巡检项主要是DBA根据以往故障处理的经验,总结下来的一些常用的排查项目,例如:processlist当前连接情况核查,并且可以保留快照,数据库阻塞的情况核查、流控的情况检查、锁争用的核查以及一些临时表和询缓存等情况的检查,下图中的例子是对当前连接情况的排查,可以看到什么用户正连接数据库在执行哪些操作。
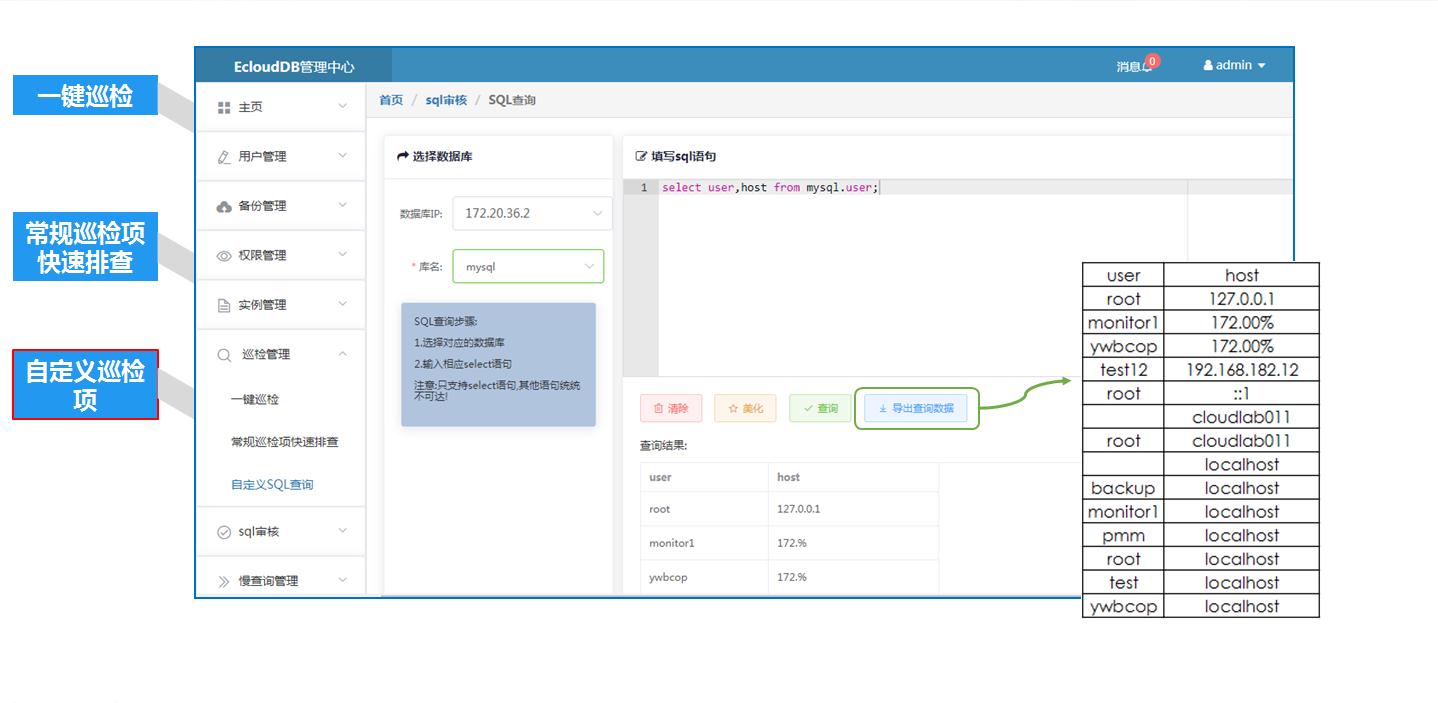
另外,作为对常规巡检项的补充,也提供了自定义巡检项的功能。可以执行一些临时的查询语句,并且结合了语义审核和转译的功能,能够保证sql语句的正确使用,查询结果可以从web页面上导出。下图中的例子是临时对数据库账号的进行查询,并导出结果。
1、打开复制引擎的调试信息-wsrep_debug
在运行过程中,可以通过set global wsrep_debug = 'ON';来动态地打开wsrep的调试信息(调试信息会输入到错误日志中),可以帮助复制引擎定位问题。
2、Galera集群监控
1)监控集群的一致性
mysql>show status like 'wsrep_cluster_state_uuid';
通过检查变量wsrep_cluster_state_uuid的值,确认此节点是否属于正确的集群。该变量的值在集群的各个节点中必须相同,如果某个节点出现不同的值,说明此节点没有连接到集群中。
mysql>show status like 'wsrep_cluster_conf_id';
通过检查变量wsrep_cluster_conf_id的值,用于查看集群发生变化的总数,同时确认此节点是否属于主集群。该变量的值在集群的各个节点中必须相同,如果某个节点出现不同的值,说明此节点脱离集群了,需要检查网络连接等将其恢复到一致的状态。
mysql>show status like 'wsrep_cluster_size';
通过检查变量wsrep_cluster_size的值,查看集群节点的总数。
mysql> show status like 'wsrep_cluster_status';
通过检查变量wsrep_cluster_status的值,查看节点的状态是否为Primary,若不为Primary,表示集群部分节点不可用,甚至可能是集群出现了脑裂。
如果所有节点的状态都不为Primary,就需要重置仲裁,如果不能重置仲裁,就需要手动重启。
第一步,关闭所有节点
第二步,重启各个节点,重启过程中可以参考wsrep_last_committed的值确定主节点。
注:手动重启的缺点是会造成缓存丢失,从而不能做IST。
2)监控节点状态
mysql> show status like 'wsrep_ready';
通过检查变量wsrep_ready的值,查看该节点的状态是否可以正常使用SQL语句。如果为ON,表示正常,若为OFF,需进一步检查wsrep_connected的值。
mysql> show status like 'wsrep_connected';
如果此变量的值为OFF,说明该节点还没有加入到任何一个集群组件中,这很可能是因为配置文件问题,例如wsrep_cluster_address或者wsrep_cluster_name值设置错误,也可以通过查看错误日志进一步定位原因。
如果节点连接没有问题,但wsrep_ready的值还为OFF,检查wsrep_local_state_comment的值。
mysql> show status like 'wsrep_local_state_comment';
当节点的状态为Primary时,wsrep_local_state_comment的值一般为Joining, Waiting for SST, Joined, Synced或者Donor,如果wsrep_ready为OFF,并且wsrep_local_state_comment的值为Joining, Waiting for SST, Joined其中一个,说明此节点正在执行同步。
当节点的状态不为Primary时,wsrep_local_state_comment的值应该为Initialized。任何其他状态都是短暂的或临时的。
3)检测复制的健康状态
mysql> show status like 'wsrep_flow_control_paused';
通过检查变量wsrep_flow_control_paused的值,可以确认有多少slave延迟在拖慢整个集群的,从而查看复制的健康状态。这个值越接近0.0越好,优化的方法主要通过增加配置文件中wsrep_slave_threads的值,或者将复制很慢的节点剔除出集群。wsrep_slave_threads取值可以参考wsrep_cert_deps_distance,wsrep_cert_deps_distance表示并发事务处理数的均值,wsrep_slave_threads的值不应该比wsrep_cert_deps_distance高很多。
4)检测网络慢的问题
mysql> show status like 'wsrep_local_send_queue_avg';
通过检查变量wsrep_local_send_queue_avg的值,可以检测网络状态。如果此变量的值偏高,说明网络连接可能是瓶颈。造成此情况的原因可能出现在物理层或操作系统层的配置上。
5)集群监控通知扩展
通过wsrep_notify_cmd参数调用命令脚本的二次扩展。
wsrep状态监控
mysql> show status like '%wsrep%';
+------------------------------------------+-------------------------------------------------------+
| Variable_name | Value |
+------------------------------------------+-------------------------------------------------------+
| wsrep_local_state_uuid | e8149a5c-636a-11e5-8b4b-67b16bb666a4 |
| wsrep_protocol_version | 7 |
| wsrep_last_committed | 526498 |
| wsrep_replicated | 526498 |
| wsrep_replicated_bytes | 238196578 |
| wsrep_repl_keys | 1926403 |
| wsrep_repl_keys_bytes | 27520685 |
| wsrep_repl_data_bytes | 176980021 |
| wsrep_repl_other_bytes | 0 |
| wsrep_received | 7970 |
| wsrep_received_bytes | 64791 |
| wsrep_local_commits | 526357 |
| wsrep_local_cert_failures | 0 |
| wsrep_local_replays | 0 |
| wsrep_local_send_queue | 0 |
| wsrep_local_send_queue_max | 2 |
| wsrep_local_send_queue_min | 0 |
| wsrep_local_send_queue_avg | 0.000041 |
| wsrep_local_recv_queue | 0 |
| wsrep_local_recv_queue_max | 4 |
| wsrep_local_recv_queue_min | 0 |
| wsrep_local_recv_queue_avg | 0.034504 |
| wsrep_local_cached_downto | 1 |
| wsrep_flow_control_paused_ns | 22690449177 |
| wsrep_flow_control_paused | 0.000005 |
| wsrep_flow_control_sent | 0 |
| wsrep_flow_control_recv | 371 |
| wsrep_cert_deps_distance | 74.734609 |
| wsrep_apply_oooe | 0.000000 |
| wsrep_apply_oool | 0.000000 |
| wsrep_apply_window | 1.000000 |
| wsrep_commit_oooe | 0.000000 |
| wsrep_commit_oool | 0.000000 |
| wsrep_commit_window | 1.000000 |
| wsrep_local_state | 4 |
| wsrep_local_state_comment | Synced |
| wsrep_cert_index_size | 43 |
| wsrep_cert_bucket_count | 126282 |
| wsrep_gcache_pool_size | 261431296 |
| wsrep_causal_reads | 0 |
| wsrep_cert_interval | 0.000002 |
| wsrep_incoming_addresses | 10.130.7.5:3306,,10.130.7.4:3306 |
| wsrep_evs_delayed | |
| wsrep_evs_evict_list | |
| wsrep_evs_repl_latency | 0/0/0/0/0 |
| wsrep_evs_state | OPERATIONAL |
| wsrep_gcomm_uuid | e813b31f-636a-11e5-90c7-0f6d378e1dfb |
| wsrep_cluster_conf_id | 5 |
| wsrep_cluster_size | 3 |
| wsrep_cluster_state_uuid | e8149a5c-636a-11e5-8b4b-67b16bb666a4 |
| wsrep_cluster_status | Primary |
| wsrep_connected | ON |
| wsrep_local_bf_aborts | 0 |
| wsrep_local_index | 2 |
| wsrep_provider_name | Galera |
| wsrep_provider_vendor | Codership Oy <info@codership.com> |
| wsrep_provider_version | 3.11(rXXXX) |
| wsrep_ready | ON |
+----------------------------------------+---------------------------------------------------+
58 rows in set (0.12 sec)
wsrep相关参数含义介绍:
wsrep_local_state_uuid:存储于该节点的UUID状态
wsrep_protocol_version:wsrep协议使用的版本
wsrep_last_committed:最后提交事务的序列号
wsrep_replicated:发送到其他节点的writesets总数
wsrep_replicated_bytes:发送到其他节点的writesets总字节数
wsrep_repl_keys:复制keys总数
wsrep_repl_keys_bytes:复制keys总字节数
wsrep_repl_data_bytes:复制数据的总字节数
wsrep_repl_other_bytes:其他复制的总字节数
wsrep_received:从其他节点接收的writesets总数
wsrep_received_bytes:从其他节点接收的writesets总字节数
wsrep_local_commits:该节点提交的writesets总数
wsrep_local_cert_failures:认证测试中失败的writesets总数
wsrep_local_replays:因非对称锁粒度回放的事务数
wsrep_local_send_queue:当前发送队列的长度,表示等待被发送的writesets数
wsrep_local_send_queue_avg:网络瓶颈的预兆。如果这个值比较高的话,可能存在网络瓶
wsrep_local_recv_queue:当前接收队列的长度,表示等待被使用的writesets数
wsrep_local_recv_queue_avg:表示slave事务队列的平均长度,slave瓶颈的预兆
wsrep_local_cached_downto:gcache的最小序列号,这个变量可以用来判断是用IST,还是SST。如果此值为0,表示gcache中没有writesets
wsrep_flow_control_paused_ns:表示复制停止了多长时间,以纳秒为单位
wsrep_flow_control_paused:表示复制停止了多长时间。即表明集群因为Slave延迟而慢的程度,值为0~1,越靠近0越好,值为1表示复制完全停止。可优化wsrep_slave_threads的值来改善
wsrep_flow_control_sent:表示该节点已经停止复制了多少次
wsrep_flow_control_recv:表示该节点已经停止复制了多少次
wsrep_cert_deps_distance:有多少事务可以并行应用处理。wsrep_slave_threads设置的值不应该高出该值太多
wsrep_apply_oooe:并发执行效率,writesets应用于out-of-order的频率
wsrep_apply_oool:大序列值的writeset比小序列值的writeset多出的执行频率
wsrep_apply_window:同时使用的最高序列值和最小序列值间的平均差值
wsrep_commit_oooe:事务脱离队列的频率
wsrep_commit_window:同时提交的最大序列值和最小序列值间的平均差值
wsrep_local_state:galera状态值
1 - Joining (requesting/receiving State Transfer) –表示此节点正在加入集群
2 - Donor/Desynced –表示正在加入的节点是donor
3 - Joined –表示节点已经加入集群r
4 - Synced –表示节点已经和集群同步
wsrep_local_state_comment:galera状态,如果wsrep_connected为On,但wsrep_ready为OFF,则可以从该项查看原因
wsrep_cert_index_size:certification索引的entries数量
wsrep_cert_bucket_count:哈希表中certification索引的cells数
wsrep_gcache_pool_size:page pool或者为gcache动态分配的字节数
wsrep_causal_reads:writesets处理数
wsrep_incoming_addresses:以逗号分隔显示集群中的节点地址
wsrep_evs_repl_latency:提供集群节点间通信复制延迟信息
wsrep_evs_delayed:被剔除出集群的UUID
wsrep_evs_evict_list:有延迟的节点列表
wsrep_evs_state:EVS协议状态
wsrep_gcomm_uuid:galera的view_id,不同于集群的uuid,在gvwstate.dat可以查看到
wsrep_cluster_conf_id:集群成员发生变化的数目,正常情况下所有节点上该值是一样的。如果值不同,说明该节点被临时"分区"了。当节点之间网络连接恢复的时候应该会恢复一样的值
wsrep_cluster_size:集群中的节点数目,如果这个值跟预期的节点数一致,则所有的集群节点已经连接
wsrep_cluster_state_uuid:集群的UUID值,在集群所有节点的值应该是相同的,有不同值的节点,说明其没有连接入集群
wsrep_cluster_status:集群节点的状态。如果不为"Primary",说明出现"分区"或是"split-brain"状况,可能的取值为:Primary、Non-Primary、Disconnected
wsrep_connected:节点是否连接到集群,如果该值为Off,且wsrep_ready的值也为Off,则说明该节点没有连接到集群。(可能是wsrep_cluster_address或wsrep_cluster_name等配置错造成的。具体错误需要查看错误日志)
wsrep_local_bf_aborts:被其他节点上的事务终止的正在执行的本地事务数
wsrep_local_index:集群节点索引
wsrep_provider_name:wsrep程序提供者
wsrep_provider_vendor:wsrep供应商
wsrep_provider_version:wsrep程序提供者的版本
wsrep_ready:节点是否可以提供查询。该值为ON,则说明可以接受SQL负载。如果为Off,则需要检查wsrep_connected
对于我们来说,数据库的备份和恢复是很日常的工作。因为平时难免会遇到服务器宕机、磁盘损坏等情况,在这种情况下,要保证数据不丢失或者最小程度的丢失,平时进行有效的备份就显得非常重要了。
因此对于DBA来说,备份工具的使用、备份策略的选择以及备份系统的完善都是需要特别关注的,另外,像备份文件校验通常是比较容易忽视的问题,出现故障时发现备份文件不可用,会造成很严重损失。
我们平时常用的备份工具是mysqldump、Percona Xtrabackup,分别用于逻辑备份和物理备份,其实大多数DBA的备份/恢复体系都是围绕这两个工具展开的。
早期我们通过在数据库本地,定期执行脚本的方式进行备份,策略是:每周日凌晨2点执行一次全量备份,周一到周六每天凌晨2点执行增量备份,在本地存储空间充足的情况下,要求至少要求保留1个月的备份数据,备份恢复测试是通过在备份恢复测试机上面执行‘测试脚本’,每周六分时段从各个数据库拉取备份文件到本机进行恢复测试,并通过日志记录恢复操作是否成功。
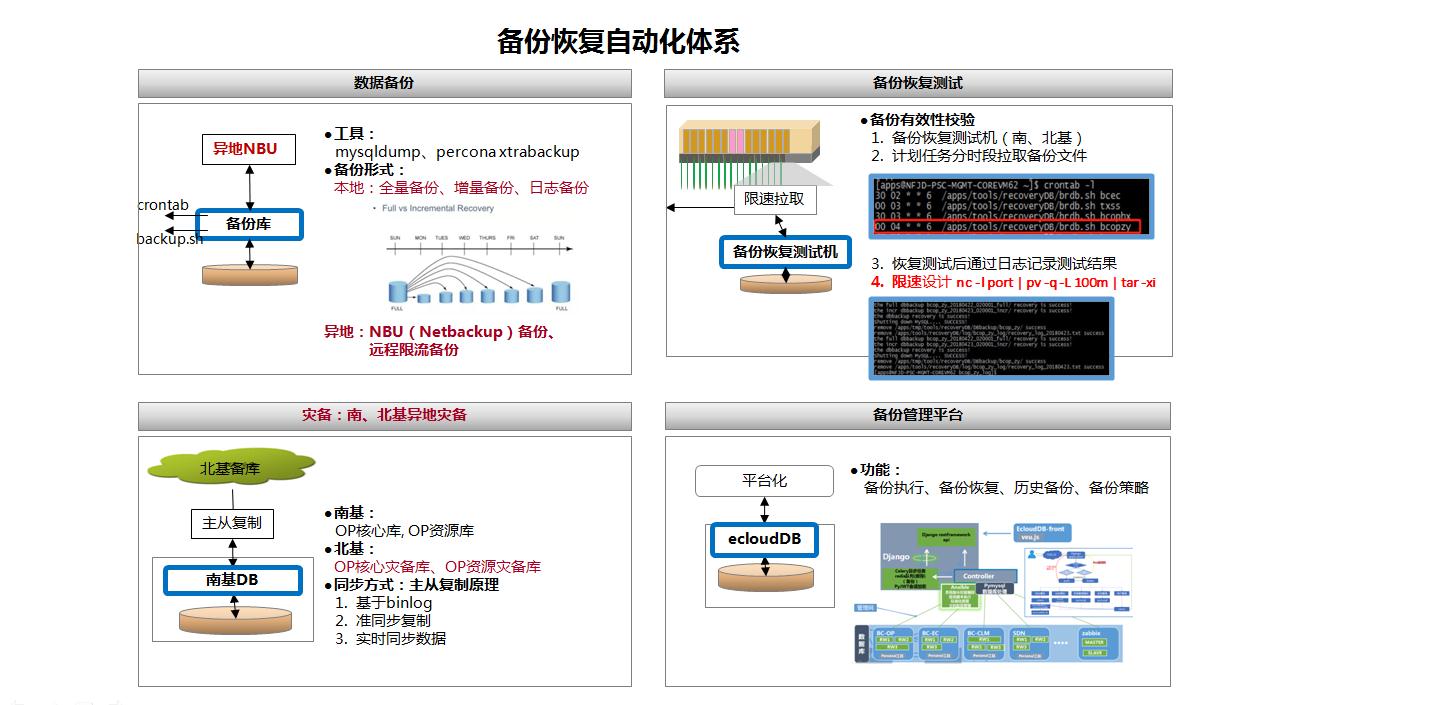
那当面对成百上千个MySQL实例的维护,以上备份恢复方式会有哪些问题呢?我们具体来看一下。
1、首先是对本地存储空间需求较大,并且占用服务器系统总线,内存,CPU,磁盘IO资源,使得备份对线上业务有一定的影响。
在现网环境中,由于本地磁盘空间有限,通常本地仅保留一个月左右的备份数据,对于更早的数据如无特殊需求,到后期会自动删除,对于较重要的数据要保留更久要通过远程备份实现,不过在远程备份时,备份传输引发的网卡流量会对线上业务造成影响,需要考虑到网卡的能力。这时可以考虑使用双网卡,一块用于备份,一块用来提供线上服务。如果没有这个条件,要通过在备份时限速来达到目的。
2、其次是,集中化管理缺失,备份节点较多,备份方式多样化,备份完成情况、占用空间大小、完成时间以及校验结果等内容的记录和呈现也不够直观,缺少图形化界面。突发故障或变更前的临时备份依然靠手工执行,存在效率低和安全性差的问题。
3、集群备份节点选择问题。备份或多或少对线上业务都有影响,建议备份任务在slave或只读节点上执行, 那么当集群发生主备切换,如果备份节点没有动态进行切换,导致在写库上进行备份,使线上业务受备份操作影响。
为了解决上述问题,我们还是采用平台化的方式,通过开发来实现集中化管理,包括:备份执行与恢复管理、历史备份查看以及备份策略修改和管理等功能。
另外想要提一下的是容灾,容灾是指在备份的基础上建立一个异地的数据系统,这个系统是本地关键应用数据的一个实时复制。
在灾难发生时,可以支持自动和手工灾备切换功能,保正业务的连续性。
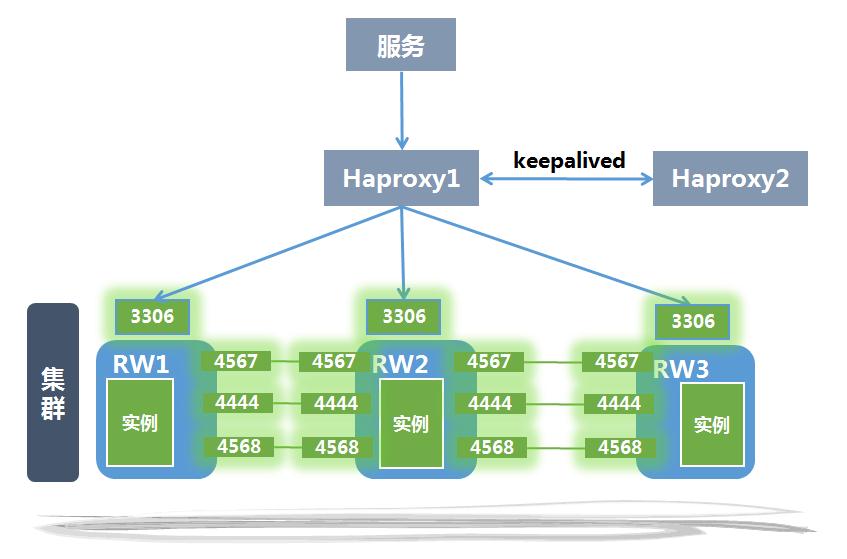
当集群中出现读写服务节点宕机的情况时,应该按如下所述步骤进行处理,以对外提供服务。
1)读写服务节点宕机
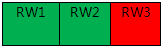
① 查看集群各节点状态:ps –ef | grep rdb
结果:读写节点(RW3)进程不存在,其他节点服务正常
② 查看error log日志,检查宕机原因
③ 重启RW3
④ 启动完成后,确认RW3状态是否正常
2)某两个读写服务节点宕机
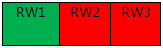
① 查看集群各节点状态:ps –ef | grep rdb
结果:读写节点(RW2、RW3)进程不存在,RW1节点服务正常
② 查看error log日志,检查宕机原因
③ 此时,RW1读写服务节点正常工作,重启RW2和RW3
④ 启动完成后,确认RW2和RW3状态是否正常
3)读写服务节点都宕机
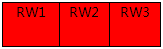
① 查看集群各节点状态:ps –ef | grep rdb
结果:读写节点(RW1、RW2、RW3)进程均不存在,此时集群无法提供正常服务
② 查看error log日志,发现最后宕机的是RW3
③ 关闭集群:kill -15 PID
④ 重新启动最后宕掉的读写服务节点RW3
⑤ RW3状态恢复正常后,根据实际负载情况判断是否继续启动RW2和RW1,预判如果可能做SST,由于做donor的节点无法提供服务,服务恢复时间比较长,可以先不起后面的节点,暂时只让RW3提供服务,闲时再启动其他节点,这种情况下要注意限制数据库的连接数。启动RW2节点
⑥ 待数据同步结束,RW2状态恢复正常后,启动RW1节点
⑦ 检查各个节点的状态,是否能正常提供服务
当集群中出现任一读写节点无响应时,应该按如下所述步骤进行处理,以对外提供服务。
1)负载高
主要查看以下几项:CPU使用率,内存使用率,操作系统IO,网络IO,网络连接数等。对应的命令和工具为:SystemTap,LatencyTOP,vmstat, sar, iostat, top, tcpdump等。通过观察这些指标,我们就可以定位系统的性能问题。具体检查顺序可参看下述步骤:
① 先看CPU使用率,如果CPU使用率不高,但系统的Throughput和Latency上不去,这说明应用程序并没有忙于计算,而是忙于别的一些事,比如IO。(另外,CPU的利用率还要看内核态的和用户态的,内核态的上去了,整个系统的性能就下来了。而对于多核CPU来说,CPU 0 是相当关键的,如果CPU 0的负载高,那么会影响其它核的性能,因为CPU各核间是需要有调度的,这靠CPU0完成)。
② 查看一下IO大不大,IO和CPU一般是反着来的,CPU利用率高则IO不大,IO大则CPU利用率就低。关于IO,我们要看三个事,一个是磁盘文件IO,一个是驱动程序的IO(如:网卡),一个是内存换页率。这三个事都会影响系统性能。
③ 查看一下网络带宽使用情况,在Linux下,你可以使用iftop, iptraf, ntop, tcpdump这些命令来查看,或是用Wireshark来查看。
④如果CPU不高,IO不高,内存使用不高,网络带宽使用不高,但是系统的性能上不去。这说明你的程序有问题,比如,你的程序被阻塞了。可能是因为等哪个锁,可能是因为等某个资源,或者是在切换上下文。
通过了解操作系统的性能,我们才知道性能的问题,比如:带宽不够,内存不够,TCP缓冲区不够等等,很多时候,不需要调整程序的,只需要调整一下硬件或操作系统的配置就可以了。
注:OS常用查看命令
cpu – vmstat、top、sar
内存– ipcs、free
io – iostat、sar
网络– tcpdump、netstat –i、sar
预防措施:
合理调整数据库的参数;
应用上线前进行测试,优化后上线。防止应用大批量处理sql,insert、select等语句;
监控系统资源负荷情况;
限制报表并发查询数量,参照业务吞吐量。
处理方法:
① 排查执行时间较长的sql语句,步骤如下:
在各节点执行show full processlist;将执行时间较长的sql语句及执行该语句的线程ID(show full processlist显示结果中的列Id值)记录下来;
② 针对记录下来的sql语句,与应用相关人员确认是否能够终止;
说明:对于发现执行时间较长且仍在执行的select语句,为了降低风险,在必要情况下可以直接终止;对于涉及数据更新的语句,需要根据实际情况进行相关处理(比如记录下 SQL语句以便后续分析);
③ 终止执行时间较长且已得到终止确认的sql语句,kill QUERY ID或者KILL ID(执行sql语句的线程ID);
④ 确认集群是否正常响应。
2)连接满
根据历史统计信息修改max_connections。
方法一:
① 第max_connections+1连接只能由拥有super privileges用户登录,当连接数满时,拥有super_priv的用户登陆数据库修改max_ connections值:
set GLOBAL max_connections=XXXX;修改完成后实时生效,无需重启数据库。
② 进入配置文件my.cnf,设置max_connections值,该值与步骤一的值相同。
方法二:
进入配置文件my.cnf,设置max_connections值,并重启该节点服务。
3)有锁表情况
预防措施:
① 监控锁等待数量,暂设置10个报警;
② 避免业务忙时进行批量更新操作。
当出现有锁表情况而导致数据库响应慢的情况时,应该按如下所述步骤进行处理:
方法一:
① 获取锁表情况的相关信息,步骤如下:
(a) 以root用户登陆到各主节点机器上;
调用客户端连接工具;
在各主节点的mysql提示符下执行use information_schema;
在各主节点的mysql提示符下执行如下sql语句;
select a.trx_id ,a.trx_query , b.lock_data
from innodb_trx a ,innodb_locks bwhere a.trx_id = b.lock_trx_id;
② 针对锁信息查询语句的查询结果,与应用相关人员确认是否可以kill
③ 如果应用确认可以kill,则kill对应的sql
方法二:
调整innodb_lock_wait_timeout值。
当集群出现分裂的情况时,应该按如下所述步骤进行处理,以对外提供服务。
1)集群中有节点状态是Primary
① 使用以下命令查看集群状态,查找状态为non-Primary的节点
SHOW STATUS where Variable_name="wsrep_cluster_status";
+------------------------------+----------+
| Variable_name | Value |
+-----------------------------+----------+
| wsrep_cluster_status |non- Primary |
+--------------------------+---------------+
② 重启状态为non-Primary的节点
③ 检查各个节点的状态,是否能正常提供服务
2)集群中所有节点状态都不是Primary
① 使用以下命令查看集群状态,发现集群已经整个分裂,状态均为non-Primary
SHOW STATUS where Variable_name="wsrep_cluster_status";
+-----------------------------+----------------+
| Variable_name | Value |
+-----------------------------+----------------+
| wsrep_cluster_status |non- Primary |
+-----------------------------+----------------+
② 重新执行选主。选主规则:以最后提交事务的数据库节点选为主,作为启动集群的主节点。同时,主节点对应的seqno也是最大的,可以通过以下命令查看
SHOW STATUS LIKE 'wsrep_last_committed';
+---------------------------+---------+
|Variable_name |Value |
+--------------------------+---------+
|wsrep_last_committed|409745|
③ 如果RW1是当前的主节点,则在RW1下执行下面的命令,重新引导RW1为primary:
set global wsrep_provider_options ="pc.bootstrap=1";Kill -15 pid关闭其他节点,关闭后可以通过grastate.dat里的uuid和seqno判断是否会做SST,kill -15关闭的一般不会有SST,只有IST,可以立即重启其他节点
④ 首先启动RW2节点
⑤ 待数据同步结束,RW2状态恢复正常后,启动RW3节点
⑥ 检查各个节点的状态,是否能正常提供服务
1)集群因断电宕机
① ping 服务器端IP地址失败
② 联系网络管理员或系统管理员进行处理,重启服务器
③ 重启数据库
通过查看各节点的日志,假设最后关闭节点是RW1
重新启动最后关闭的读写服务节点RW1
待数据同步结束,RW1状态恢复正常后,启动RW2节点
待数据同步结束,RW2状态恢复正常后,启动RW3节点
检查各个节点的状态,是否能正常提供服务
2)网络交换机故障造成集群对外连接中断
① ping 服务器端IP地址失败
② 查看/var/log/messages
③ 联系网络管理员或系统管理员进行处理
3)网络交换机故障造成集群内部连接中断
① ping 服务器端IP地址成功
② ping 集群内部各节点IP失败
③ 查看/var/log/messages
④ 联系网络管理员或系统管理员进行处理
4)磁盘故障造成集群无法提供服务
① 使用smartctl检测磁盘健康状态
② 联系系统管理员更换磁盘
③ 重启数据库
去年9月8号,晚上11点左右,研发人员对数据库进行操作时,执行了1个事务,向用户注册表添加数据,这是一条insert语句,但是忘了提交,然后又执行了另一条sql,去修改同一张表的表结构,前面没有提交的insert语句已对用户注册表添加了排他锁,导致后续大量sql语句等待执行,引发数据库阻塞,直到30min后第1个事务超时,数据库阻塞才解除。
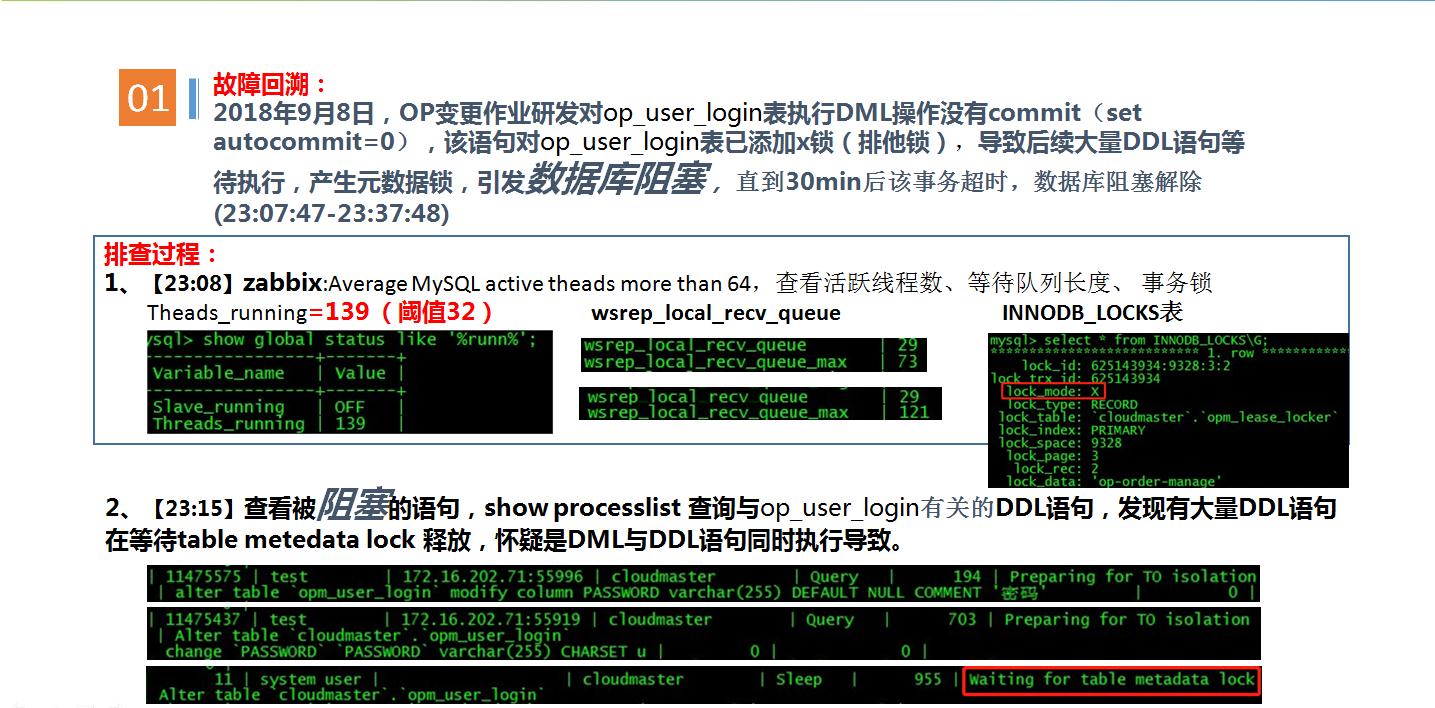
我们当时在11:08收到zabbix告警,显示数据库活跃线程数已达到139,一般活跃线程数超过32就会开始积压,这个跟CPU能处理的线程数有关,因此告警值设置为32。初步排查原因为元数据索导致,11:07用户开了一个insert语句没有提交,导致元数据锁。
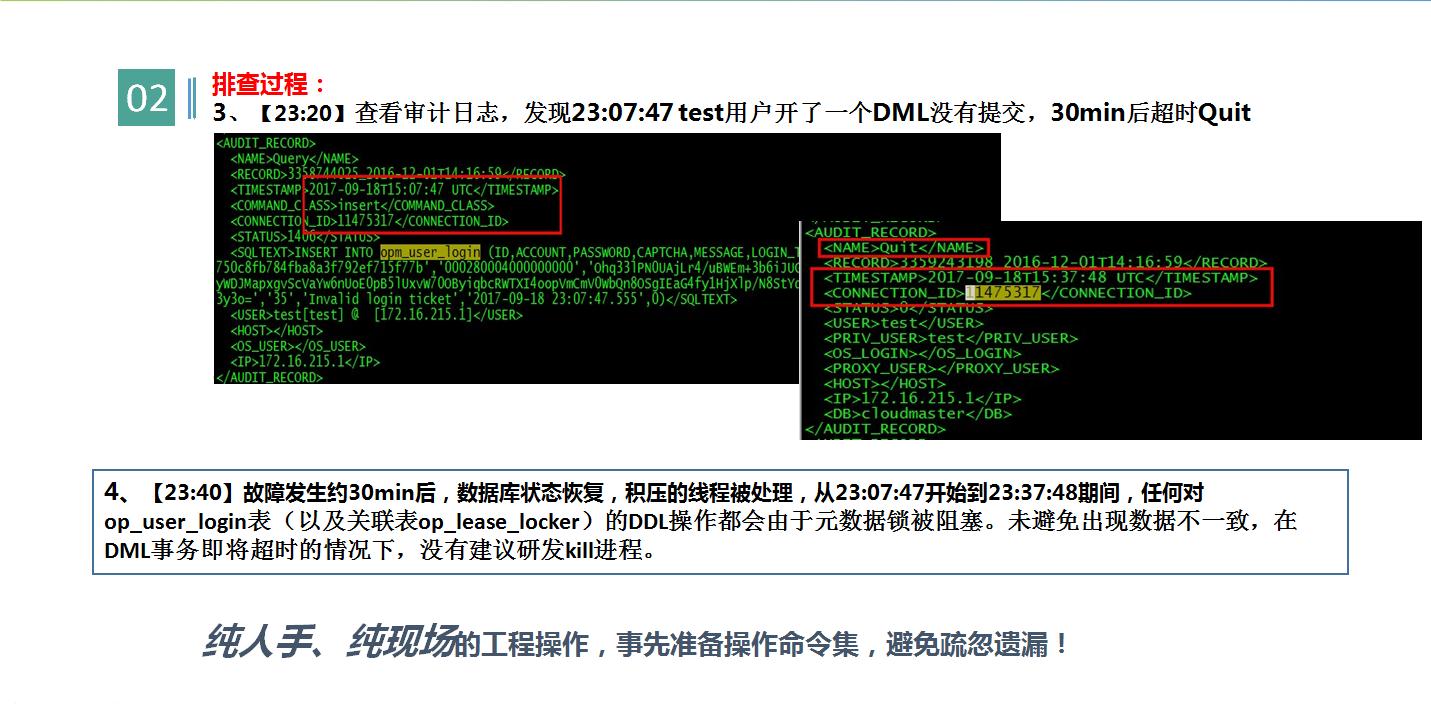
元数据锁产生的原因,简单来说就是修改表数据的同时,修改表结构。为了避免这种情况,mysql innodb 在执行写入操作时会对表,添加排它锁,修改表结构,要等待锁释放后才能执行。这次故障处理,没有直接kill掉阻塞线程,因为按以往经验,这种方式可以解决阻塞,但也有一定概率会引起数据文件损坏,所以在阻塞事务即将超时的情况下,并没有做任何操作,而是等待事务超时后,数据库自动恢复。
第二个例子是,去年11月1号,研发人员在数据库执行查询操作,因为使用排序产生临时表,又因为instance表,跟关联查询语句中的任何表都没有关联关系,导致笛卡尔积,生成的临时表文件过大最终将/目录占满,从而引发故障。

第三个案例是由于网络设备故障引起的,存储网卡闪断导致数据库宕机,在去年6月1日上午10:46,数据库进程故障,有12台数据库同时宕机,一线接到客户投诉‘华北节点控制台无法打开’,当时看了一下,由于mysqld进程属于非正常关闭,启动之前要登录集群3个节点,查看启动位置sequence number,找出具有最完整数据的节点,作为集群第一个节点优先启动,然后再启动另外两个节点同步数据。

但是,在尝试执行mysqld_safe命令查看启动位置的时候失败了,继续排查,最后找到故障原因:数据库主机挂载块存储的目录变成只读状态,重新挂载后命令可以正常执行,然后将数据库陆续启动。
这次故障原因,在后面回溯的时候发现是因为数据库主机存储网卡与上层网络设备互联信息过程中发生了闪断,导致存储目录变为只读状态,最后引发故障。
以上内容是在我们日常工作经验的基础之上,在平时维护MySQL的过程中,觉得需要引起注意或需要弄清楚的一些知识点,结合一些工作中的实际案例分享出来,希望能够对大家有所帮助。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721