
作者介绍
韩思捷,亚马逊AWS解决方案架构师,曾负责大企业客户在AWS上的售后技术支持工作,目前负责基于AWS的云计算方案架构咨询和设计。在加入AWS之前,在中国医药集团,Oracle以及EMC研发中心工作,有多年开发和运维经验,并对各种数据库以及存储应用的高可用架构,方案及性能调优有深入研究。
随着Amazon Aurora数据库被客户从认识到认可,越来越多的企业客户在完成功能和性能的验证以后,会考虑把他们在生产环境中运行的MySQL数据库迁移到Amazon Aurora数据库上。
本文描述了在各种不同的场景下,如何把MySQL数据库的数据迁移到Amazon Aurora里。
以下内容的描述,如果没有特别说明,都是基于AWS的us-west-2区进行介绍,并且按照从简单到复杂的顺序对各种场景进行描述。
场景一:Amazon MySQL RDS迁移到Amazon Aurora并有停机时间
如果客户正在使用Amazon MySQL RDS,并且有足够的停机迁移的时间窗口的话,那么可以通过RDS快照的方式进行迁移。具体操作过程如下:
1)停止应用程序对源数据库的写入操作。
2)对源数据库创建快照,可以使用图形界面进行操作,选中要迁移的数据库实例,Actions下来菜单中选择Take snapshot,如下图所示:
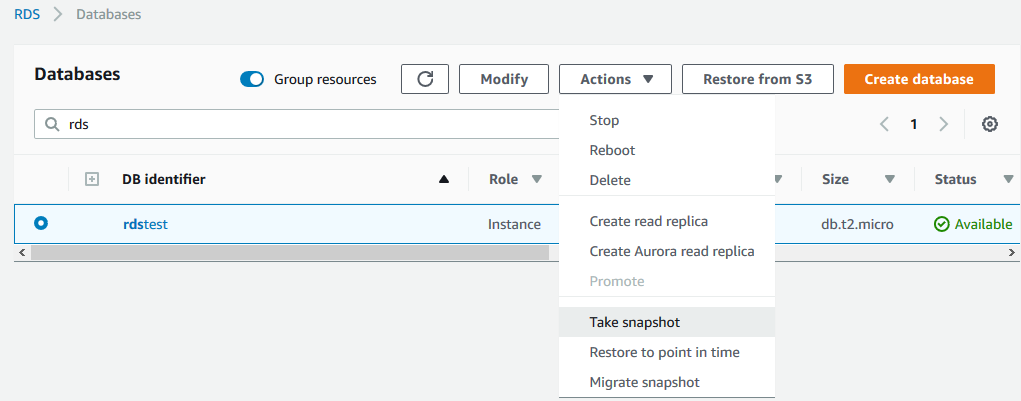
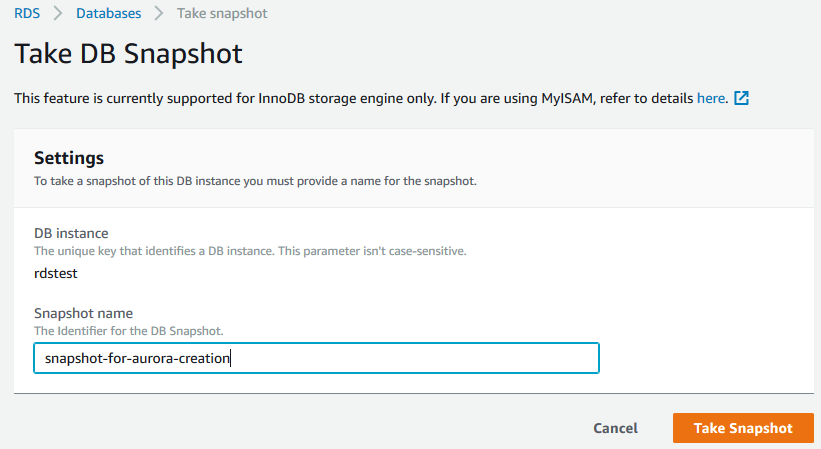
3)根据快照恢复出一个Aurora数据库。可以使用图形界面操作,在数据库列表中,选中之前创建快照的数据库实例,Actions下来列表中选择Migrate snapshot,如下图所示:
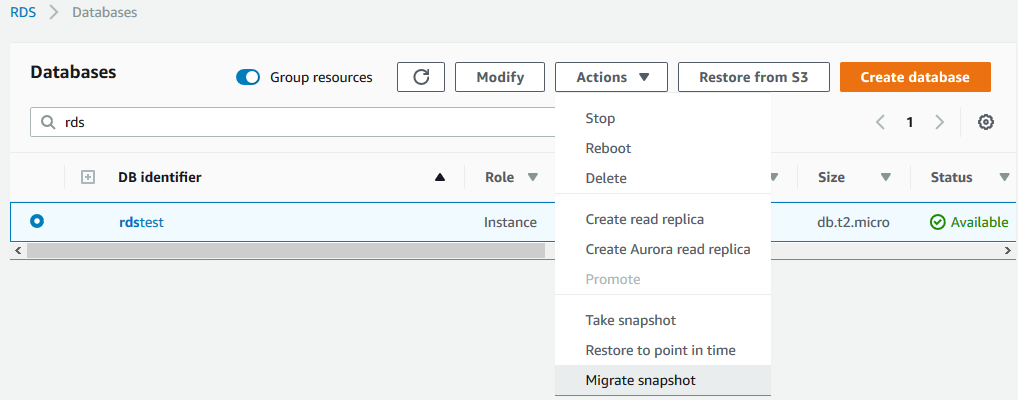
在随后显示的页面中,输入Aurora数据库的相关信息即可,包括指定一个新的Aurora数据库实例名称,网络配置等,这部分内容与直接创建一个新的Aurora数据库是完全一致的。
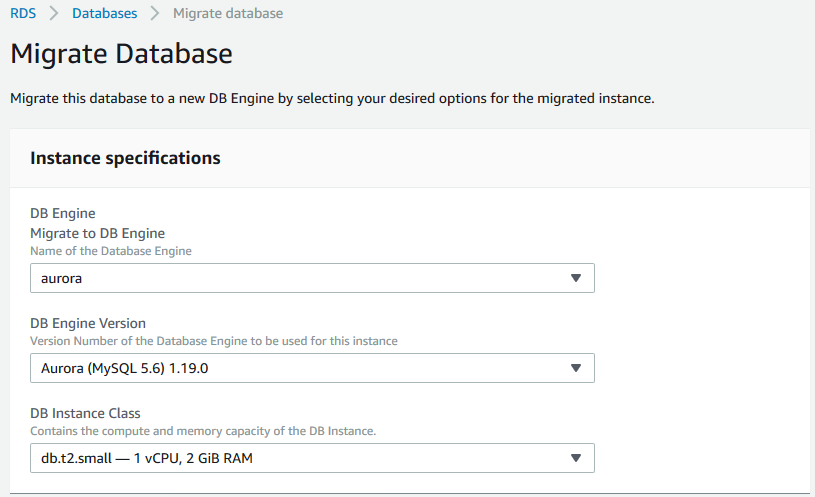
4)等到Aurora数据库创建好以后,就可以修改应用程序的连接字符串,指向Aurora,从而投入使用了。
场景二:Amazon MySQL RDS迁移到Amazon Aurora并要求最小停机时间
如果客户正在使用Amazon MySQL RDS,并且没有足够的停机时间来通过snapshot的方式进行迁移的话,那么可以通过为MySQL RDS创建Aurora读副本的方式进行迁移。具体操作过程如下:
1)在控制台界面上选中要迁移的MySQL RDS数据库,在Actions下拉菜单中选择Create Aurora read replica,如下图所示:
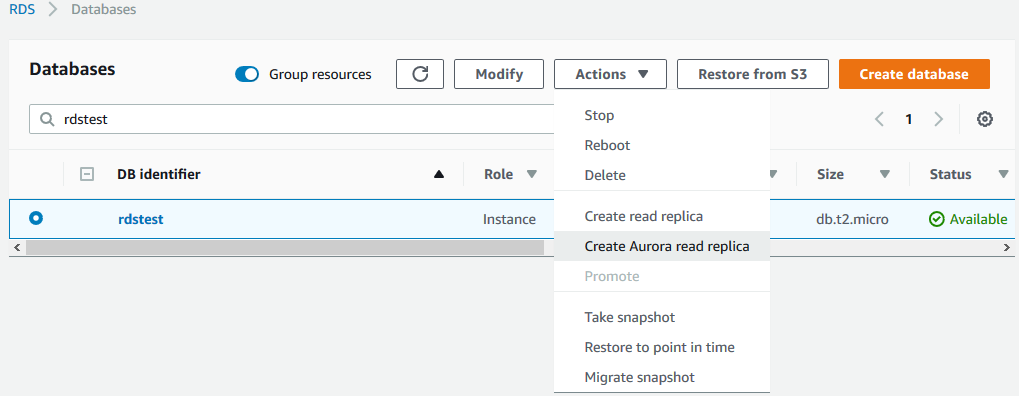
2)在创建Aurora副本的界面上输入相关的信息,其过程与创建一个新的Aurora数据库类似。
在创建Aurora读副本的过程中,源MySQL RDS数据库可以仍然被业务系统访问并使用。在读副本创建完毕以后,该副本的内容会自动与MySQL RDS主库保持数据同步。
在确定要进行切换之前(通常都是在业务低谷的时间段),关闭应用程序,从而停止应用程序对主库的写入操作,并登陆到Aurora里执行下面的命令来判断Aurora读副本是否与主库保持同步了:
show slave status \G
检查输出里的Seconds_Behind_Master字段的值,如果为0则表示Aurora读副本已经与MySQL RDS主库保持同步了。否则继续等待,直到该字段为0为止。然后选择Aurora只读副本,在Actions下拉菜单中选择Promote选项:
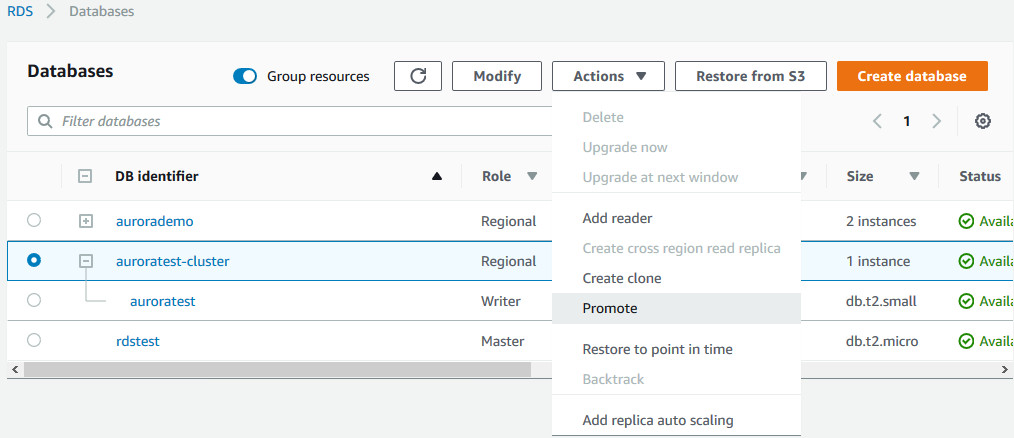
在弹出的界面中,选择Promote Read Replica按钮,从而把Aurora只读副本提升为主库:
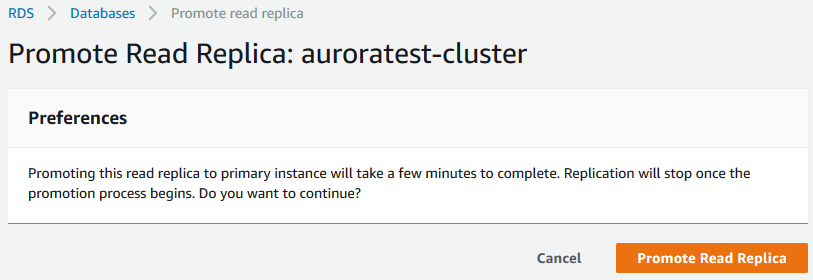
一旦完成主从切换,再次登陆到Aurora数据库,执行show slave status的时候,会发现已经没有输出信息了。这也就说明Aurora数据库已经不再是一个只读副本,而变成了一个完全独立的数据库。
修改应用程序的数据库连接字符串,使其指向Aurora数据库,并启动应用程序,从而开始在生产环境中使用Aurora数据库。
场景三:自建MySQL数据库迁移到Amazon Aurora并有足够的停机时间
如果客户没有使用Amazon MySQL RDS,而是在EC2虚拟机里,或者本地数据中心的服务器上,由客户自己部署安装的MySQL数据库,需要迁移到Aurora数据库,同时也有足够的停机迁移时间窗口,那么可以使用备份恢复的方式,进行迁移。其操作过程如下:
1)到Percona官方网站上下载XtraBackup工具,这里下载4.1版本。
下载链接:
https://www.percona.com/downloads/Percona-XtraBackup-2.4/LATEST/
如下所示:
wget
https://www.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.1/binary/tarball/percona-xtrabackup-2.4.1-Linux-x86_64.tar.gz
tar -xzvf percona-xtrabackup-2.4.1-Linux-x86_64.tar.gz
2)执行Percona XtraBackup命令,创建备份。比如下面的例子:
innobackupex –user=root –password=<your password> –database=myaurora –stream=tar ~/s3-restore/backup2 | split -d –bytes=51200000 – ~/s3-restore/backup.tar
3)把数据库备份(本例中是tar开头的文件,比如backup.tar00,其中包含了xtrabackup生成的数据库备份文件)上传到S3,如果是在本地数据中心生成的备份,并且尺寸特别大的话,可以使用AWS Snowball服务进行上传。
具体参考:
https://aws.amazon.com/cn/snowball/
4)把备份从S3恢复到Amazon Aurora数据库里。如下图所示:
a.在RDS控制台上选择Restore from S3按钮

b.选择Aurora引擎
c.指定备份的相关信息,如下图所示:
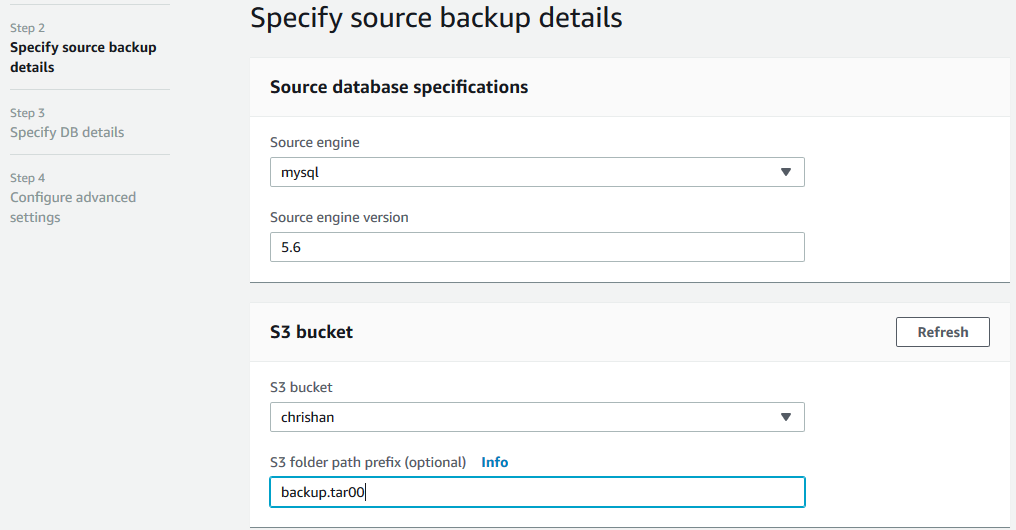
d.在数据库的配置的相关页面上,输入Aurora数据库的信息,比如数据库的名称,管理员名称与密码等,这一步与正常创建Aurora数据库的过程是一样的。
5)当Aurora数据库恢复完成以后,就可以投入生产使用了。
场景四:自建MySQL数据库迁移到Amazon Aurora并要求最小停机时间
如果客户是在EC2或者本地数据中心自己部署的MySQL数据库,希望迁移到Amazon Aurora数据库,同时没有足够的停机时间来通过备份恢复的方式完成整个迁移。
这种场景相对比较复杂,通常可以使用两种方式来进行最小时间停机的迁移。
方式1:通过构建MySQL主从副本的方式完成迁移,整个流程如下所示:
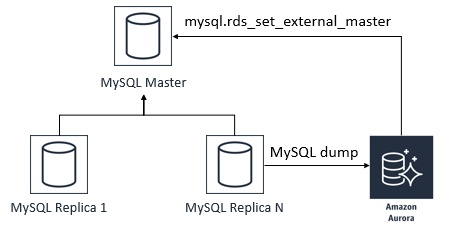
1)创建Aurora从库(即读副本),通过binlog与MySQL主库保持同步,如下图所示:
2)MySQL主,Aurora从的关系建立起来以后,持续进行数据同步,如下图所示:
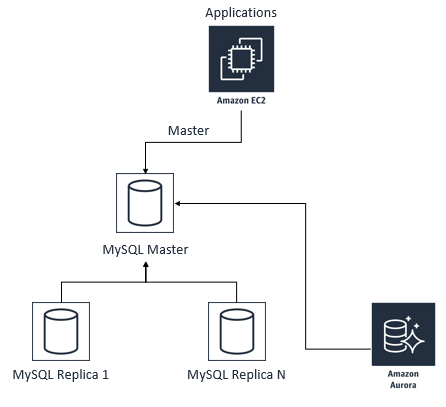
在这个阶段,Aurora数据库只能进行读操作,不能进行写操作,可以把Aurora的read_only参数设置为1强制只读,或者也可以保持0,而是从应用程序端进行控制,禁止其在Aurora数据库里进行写操作。
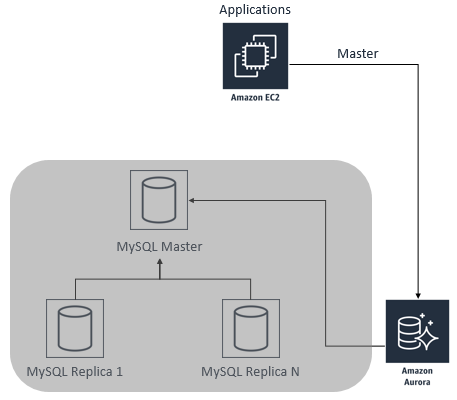
3)当需要进行切换的时候,也就是业务低谷的时候,停止应用程序在源MySQL数据库里的写入操作,然后等到Aurora从库的数据与MySQL主库的数据完全一致以后,修改应用程序的连接字符串,使其指向Aurora从库,使得Aurora数据库变为主要的写入数据库。如果你之前把Aurora数据库的read_only设置为了1,则需要把其改回到0,从而允许写入Aurora数据库。
而原来的MySQL数据库则可以被销毁。该阶段如下图所示:
具体操作过程如下:
1)使用xtrabackup对主库进行备份,并指定–slave-info,从而生成日志点的位置信息,如下例所示:
innobackupex –user=root –password=<your password> –database=myaurora –slave-info –stream=tar ~/s3-restore/backup2 | split -d –bytes=51200000 – ~/backup.tar
2)提取tar开头的文件(比如backup.tar00)里的xtrabackup_binlog_info文件,其中存放了日志点的信息。
3)把备份(这里是tar开头的文件,比如backup.tar00)上传到S3,并按照场景三所示的方式恢复出一个Aurora数据库。
4)进入Aurora数据库,并执行下面的存储过程,从而把Aurora数据库配置为MySQL的副本:
CALL mysql.rds_stop_replication;
CALL mysql.rds_set_external_master (
'172.31.20.125'
,'3306'
, 'repadmin'
, '<password>'
, 'mysql-bin.000001'
, '1024'
, 0
);
CALL mysql.rds_start_replication;
注意这里的mysql-bin.000001和1024就是从xtrabackup_binlog_info文件中找出来的、备份的时候的日志点的信息。
5)一旦Aurora数据库与主库建立起了主从复制的关系以后,等到业务低谷的时候,停止应用程序对MySQL数据库的写入操作,并等到Aurora与MySQL完全一致以后,把应用程序的数据库连接字符串改为Aurora数据库即可。
方式2:通过使用AWS DMS服务完成迁移,整个流程如下所示:
AWS Database Migration Service(DMS)服务可以帮助客户在最小停机时间的情况下, 采用在源库上捕获变化数据,并在目标库上应用变化数据的形式,进行数据库的整体迁移。
DMS不仅可以进行相同数据库引擎的迁移,同时还支持不同数据库引擎之间的迁移。
不过DMS只能迁移数据本身,其他数据库对象,比如存储过程等,是不能迁移的。需要手工在目标数据库里创建。
有关DMS的详细信息可以参考:
具体操作过程如下所示:
1)创建复制实例。复制实例的目的在于管理DMS在运行复制过程中的一些元数据。创建过程如下图所示:
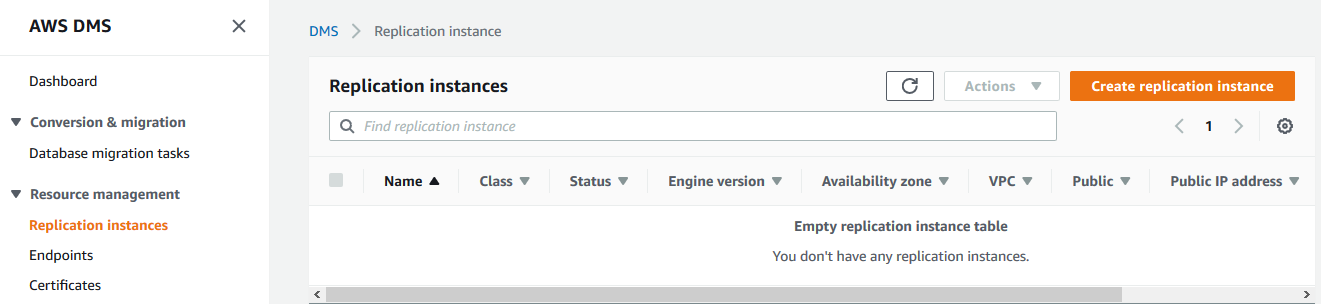
在DMS的主页上,选择Replication instances,然后在右边点击Create replication instance按钮。
在显示的界面上输入DMS实例相关的一些信息,比如实例名称,实例大小等。
需要注意的是,如果需要传输的数据量比较大,同时源数据库上有较大的工作压力的话,应该选择较大的机型。
具体细节可以参考:
2)创建source endpoint,指向源数据库。
在右边选择Endpoints,点击Create endpoint按钮:
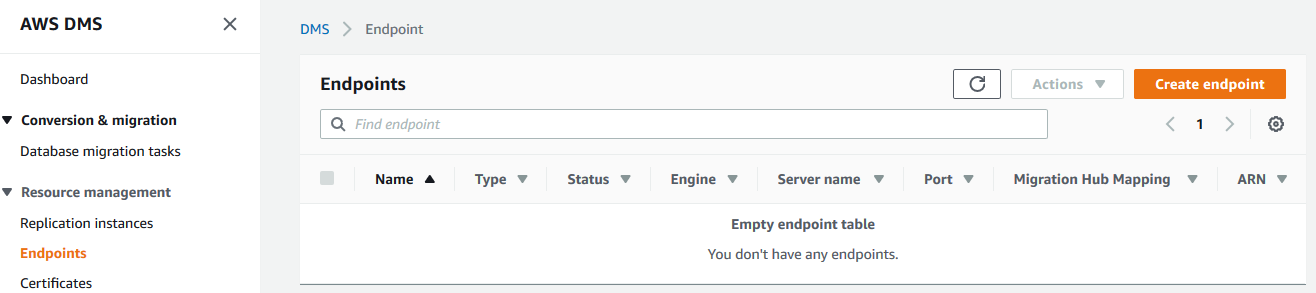
选择endpoint type为Source endpoint,并指定源数据库的信息,如下所示:
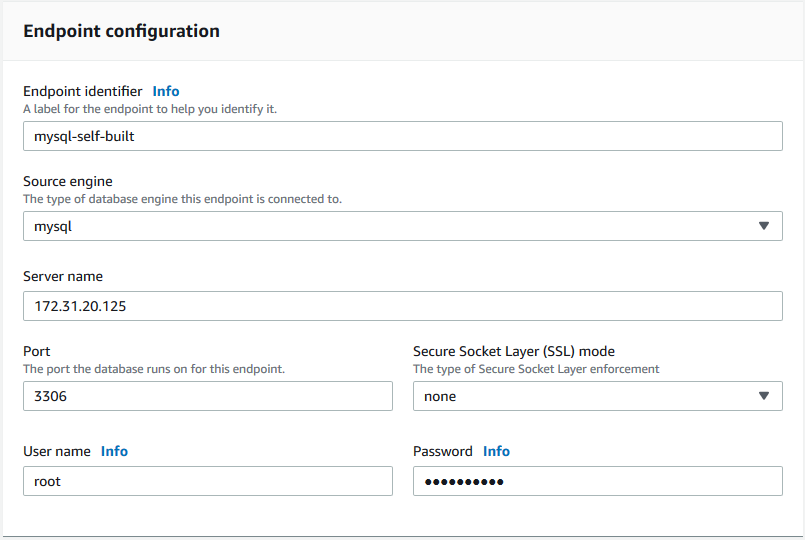
点击创建endpoint按钮从而创建source endpoint:
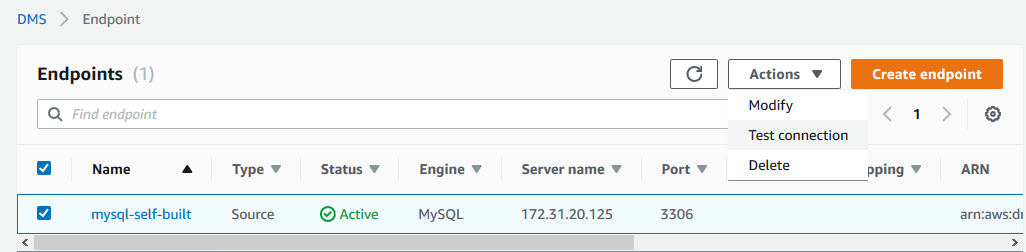
创建了source endpoint以后,我们可以进行连接测试:
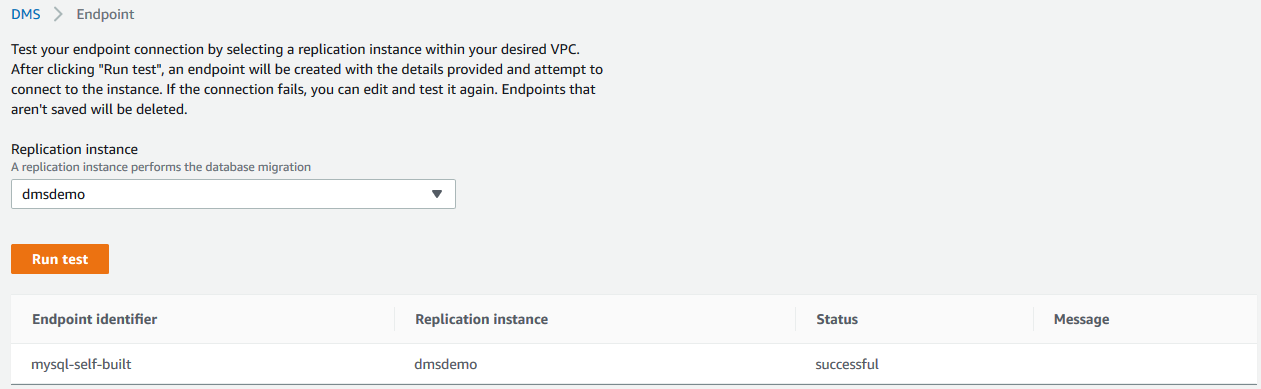
3)创建target endpoint,指向目标数据库。
先创建一个空的、不包含业务数据的Aurora数据库作为目标库,然后创建一个类型为target endpoint、并指向该Aurora数据库的endpoint:
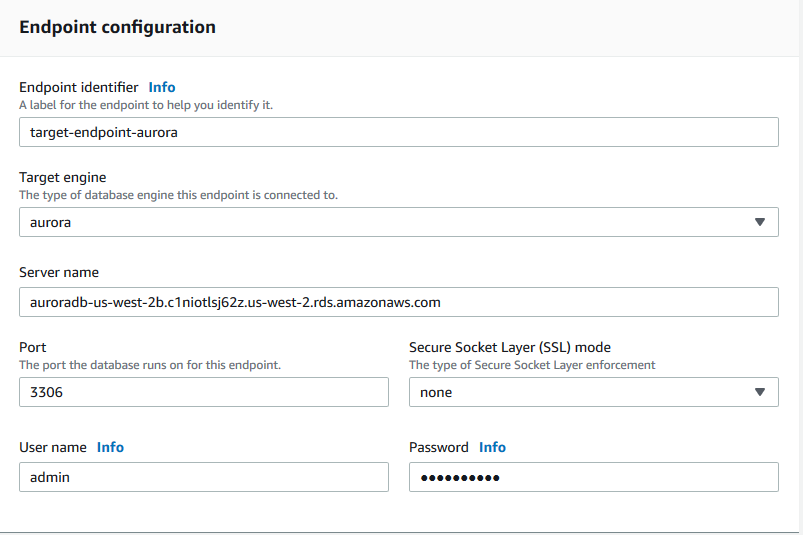
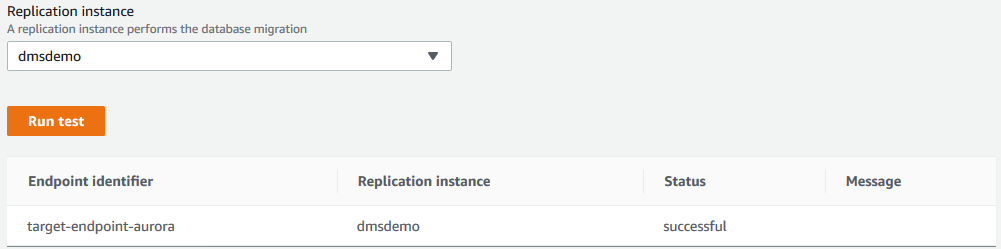
当target endpoint创建完毕以后,我们可以进行连接测试:
4)创建task,启动复制任务。
创建了源和目标endpoint以后,可以开始创建复制任务。选择Database migration tasks链接,然后选择Create task按钮:
在创建任务的界面上,选择之前创建的source endpoint和target endpoint,migration type选择Migrating existing data and replicate ongoing changes,同时选择Enable CloudWatch logs复选框。
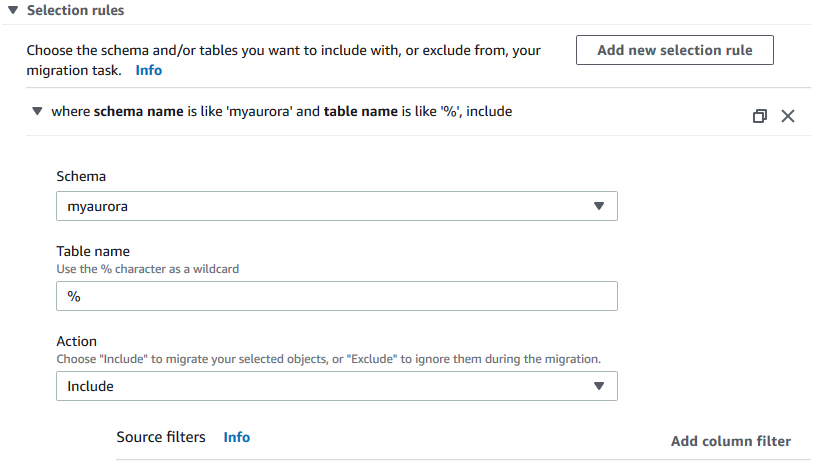
在Selection rules部分,我们指定把MySQL里的myaurora数据库的数据复制到Aurora里,如下图所示:
参考以下文档了解其他选项的含义:
https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Tasks.Creating.html
在设置好参数以后,点击Create task按钮。
等到任务正常运行以后,则源MySQL数据库和目标Aurora数据库之间就通过DMS服务进行数据同步,并且该同步过程是同步增量数据。如下图所示:
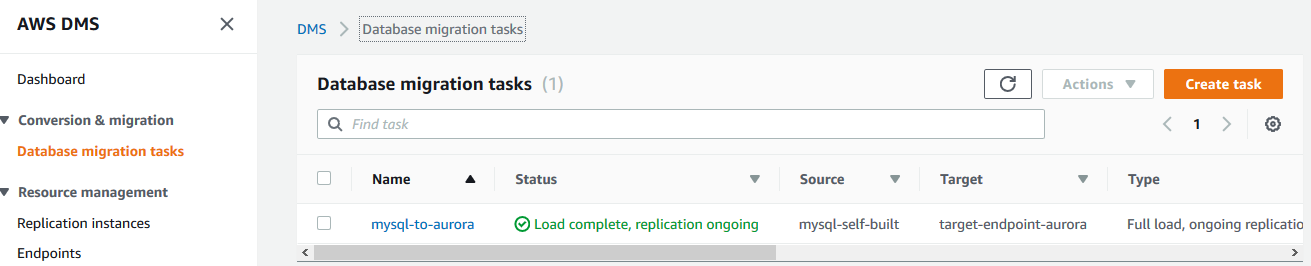
当需要进行数据库切换的时候,通常都是业务低谷的时间段:
停止应用程序向MySQL数据库写入数据。
等到所有数据都同步到Aurora以后,停止DMS任务。
修改应用程序的连接字符串,使其指向Aurora数据库,则可以完成整个迁移过程。
使用AWS DMS把自建的MySQL数据库迁移到Aurora数据库的最大好处,在于整个操作过程非常简单,没有太多的步骤,也就不容易出错。在进行DMS迁移的过程中,参考如下的建议:
如果要迁移的数据库很大,则建议使用较大的机型作为复制实例
把小的表集中作为一个任务进行复制。而把每个较大的表作为一个单独的任务进行复制。
总的来说,本文按照从简单到复杂的顺序,详细描述了各种场景下,MySQL数据库如何迁移到Amazon Aurora数据库上。大家可以根据自己的实际场景,选择自己最适合的方式进行数据库的迁移。
作者:韩思捷
来源:
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721