
作者介绍
王文安,网易游戏MySQL DBA, 主要负责网易游戏MySQL SaaS平台的设计与维护,也有关注TiDB、CockRoachDB等分布式数据库。更多文章发布在网易游戏运维平台订阅号(ID:neteasegameops)
DDL 一向是业务的痛点,尤其是对大型表的 DDL 操作,具有操作时间久,对性能影响大,可能影响业务正常使用等问题。
本文将详细解释 MySQL DDL 的原理,并分享一些尽可能减少 DDL 对业务的影响的办法。
一、MySQL DDL的方法
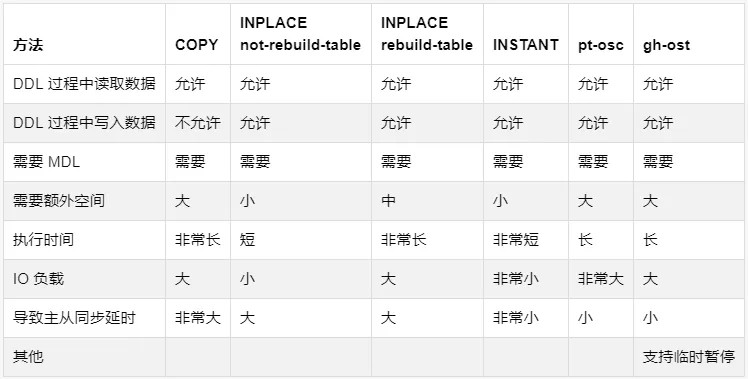
MySQL 的 DDL 有很多种算法。
MySQL 本身自带三种算法:
COPY 算法,为最古老的算法,在 MySQL 5.5 及以下为默认算法。
INPLACE 算法,从 MySQL 5.6 开始被引入并默认使用。
INPLACE 算法还包含两种类型:rebuild-table 和 not-rebuild-table。MySQL 使用 INPLACE 算法时,会自动判断,能使用 not-rebuild-table 的情况下会尽量使用,不能的时候才会使用 rebuild-table。当 DDL 涉及到主键和全文索引相关的操作时,无法使用 not-rebuild-table,必须使用 rebuild-table。其他情况下都会使用 not-rebuild-table。
INSTANT 算法,从 MySQL 8.0.12 开始被引入并默认使用。目前 INSTANT 算法只支持增加列等少量 DDL 类型的操作,其他类型仍然会默认使用 INPLACE。
有一些第三方工具也可以实现 DDL 操作,最常见的是 percona 的 pt-online-schema-change 工具(简称为 pt-osc),和 GitHub 的 gh-ost 工具,均支持 MySQL 5.5 以上的版本。
推荐工具:

1)COPY
MySQL 5.5 及以下,直接正常 DDL 即可。
MySQL 5.6 及以上,如果希望使用 COPY 算法,需要使用 ALGORITHM=COPY 指定算法类型,例如:
2)INPLACE
MySQL 5.7,直接正常 DDL 即可。
MySQL 8.0 及以上,如果希望使用 INPLACE 算法,需要使用 ALGORITHM=INPLACE 指定算法类型。
3)INSTANT
MySQL 8.0 ,直接正常 DDL 即可。目前已经有以下 DDL 类型支持 INSTANT:
添加列。
添加或者删除一个虚拟列(不支持删除普通列)。
添加或者删除一个列的默认值。
修改 ENUM 或者 SET 列的定义。
变更索引的类型(B树,哈希)。
使用 ALTER 语法重命名表。
可以使用 ALGORITHM = INSTANT 强制使用 INSTANT 算法。如果不支持则 MySQL 会报错,不进行任何操作。
需要注意以下几点:
添加列时,INSTANCE 算法不能使用 AFTER 关键字控制列的位置,只能添加在表的末尾(最后一列)。
开启压缩的 InnoDB 表无法使用 INSTANT 算法。
不支持包含全文索引的表。
仅支持使用 MySQL 8.0 新表空间格式的表。
不支持临时表。
包含 INSTANT 列的表无法在旧版本的 MySQL上使用(即物理备份无法恢复)。
在旧版本上,如果表或者表的索引已经损坏,除非已经执行 fix 或者 rebuild,否则升级到新版本后无法添加 INSTANT 列。
pt-online-schema-change
参见工具官方文档:
https://www.percona.com/doc/percona-toolkit/LATEST/pt-online-schema-change.html
gh-ost
参见工具官方文档:
https://github.com/github/gh-ost
二、MySQL DDL使用注意事项
MySQL 在大型表上的 DDL 会带来耗时较久、负载较高、额外空间占用、MDL、主从同步延时等情况。需要特别引起重视。
大部分情况在上面的性能对比表格已经描述,这里不再重复,这里着重讲一些重点问题:
DDL 的执行时间,和非常非常多的因素相关,很难预先对执行时间做出估计。如果项目非常在意这个时间,建议提前做测试。
可以新建一个新的测试实例,将备份数据导出到测试实例,执行 DDL 操作,判断执行时间,作为对线上执行的一个估计。但是请注意,该估计仍然可能不准确,因为线上实例的负载可能会比测试实例高。
如果使用的是 gh-ost,工具会反馈执行进度。
如果使用的是 MySQL 自带的 DDL,可以开启 InnoDB 的 DDL 监控( MySQL 默认不开启),开启方法为在 my.cnf 中增加配置:
开启之后可以使用以下语句查看 DDL 执行进度:
所有方式对大表做 DDL 都会增加负载,只是程度的不同,主要为 IO 的负载。如果是 IO 使用非常高的实例,建议在 IO 较小的时间段执行 DDL 操作。
COPY、INPLACE rebuild-table、gh-ost、pt-online-schema-change,都会将表完整复制一份出来再做 DDL 变更,因此会使用和原表空间一样大(甚至更大,如果是加列的操作的话)的额外空间,另外还会生成大量的临时日志。
请特别注意剩余空间,确保空间充裕,不然可能导致 DDL 过程中 MySQL 崩溃。
所有方式做 DDL 均会引发主从同步延时。
其中 COPY 和 INPLACE 算法,只有主完成了 DDL 操作之后,binlog 才会同步给从,从才能开始操作 DDL,从操作完 DDL 之后才能开始操作其他语句,从而会造成巨大的(大概两倍 DDL 操作时间)的延时。
其他方法产生的延时较小,但仍然可能有几秒的延时。
除了 COPY 算法会有持续性的锁(DDL 的整个过程期间无法向该表写入任何数据)之外,所有方式做 DDL 均只会产生短暂的 MDL(metadata lock)。
除了 COPY 模式之外的所有模式,大概的锁过程如下:
在 DDL 的开始阶段,申请该表的 EXCLUSIVE-MDL 锁,禁止读写
降级 EXCLUSIVE-MDL 锁,允许读写
在 DDL 的最终 COMMIT 阶段,升级 EXCLUSIVE-MDL 锁,禁止读写
其中的阶段一和阶段三,其 MDL 的持续时间都是非常短暂的,也就是申请到了 MDL 锁之后会在很快的时间(一般小于一秒)处理完成相关操作并释放锁,一般情况下是不会影响业务的。
只有阶段二是真正在处理数据,持续时间较长,但是阶段二期间是允许数据读写的。
还有可能出现在阶段一和阶段三无法申请到 MDL 的情况。这是因为 MDL 和所有的读写语句都是冲突的。
如果是在申请 MDL 的时候,之前有读写的事务一直没有执行完成(或者执行完成之后一直没有 COMMIT),MDL 就会无法立刻申请到,这个时候,DDL 语句以及所有在该 DDL 语句之后的读写事务,都会阻塞并等待之前的读写事务完成,导致整个实例处于不可用状态。
这个时候 SHOW PROCESSLIST 看到的语句状态为 waiting for metadata lock。
由于目前所有的 DDL 语句都会产生 MDL,无法避免,因此在执行 DDL 操作期间,请尽可能确保不要有未执行完成的长事务。
如果发生了 warting for metadata lock 导致的阻塞,有以下三种处理方法:
耐心等待之前的事务全部执行完成。
将之前未执行完成的事务全部 kill 掉。
kill 掉 DDL 语句。
如果想要知道当前 MDL 的情况,可以开启 MDL 监控(MySQL 8.0 以上默认开启),开启方法为在 my.cnf 中增加配置:
开启后,可以使用以下语句来查看 MDL 的当前情况,判断是哪些事务导致的阻塞,从而可以 kill 掉这些事务:
SELECT OBJECT_TYPE,OBJECT_SCHEMA,OBJECT_NAME,LOCK_STATUS,processlist_id
FROM performance_schema.metadata_locks mdl
INNER JOIN performance_schema.threads thd ON mdl.owner_thread_id = thd.thread_id
WHERE processlist_id <> @@pseudo_thread_id;
MySQL 的 INPLACE 算法虽然支持在 DDL 过程中间的读写,但是对写入的数据量有上限,不能超过 innodb_online_alter_log_max_size(默认为 128M)。
如果超过上限可能导致执行失败。如果有超过该上限的可能,请调大该参数。
三、MySQL DDL原理简析
以 MySQL 5.7 为准,目前各类 DDL 操作所使用的算法见下图:

较简单的实现方法,MySQL 会建立一个新的临时表,把源表的所有数据写入到临时表,在此期间无法对源表进行数据写入。MySQL 在完成临时表的写入之后,用临时表替换掉源表。
INPLACE 算法包含两类:inplace-no-rebuild 和 inplace-rebuild,两者的主要差异在于是否需要重建源表。
INPLACE 算法的操作阶段主要分为三个:
Prepare阶段:
创建新的临时 frm 文件(与 InnoDB 无关)。
持有 EXCLUSIVE-MDL 锁,禁止读写。
根据 ALTER 类型,确定执行方式(copy,online-rebuild,online-not-rebuild)。
更新数据字典的内存对象。
分配 row_log 对象记录数据变更的增量(仅 rebuild 类型需要)。
生成新的临时ibd文件 new_table(仅 rebuild 类型需要)。
Execute 阶段:
降级 EXCLUSIVE-MDL 锁,允许读写。
扫描 old_table 聚集索引(主键)中的每一条记录(称为 rec)。
遍历 new_table 的聚集索引和二级索引,逐一处理。
根据 rec 构造对应的索引项。
将构造索引项插入 sort_buffer 块排序。
将 sort_buffer 块更新到 new_table 的索引上。
记录 online-ddl 执行过程中产生的增量(仅 rebuild 类型需要)。
重放 row_log 中的操作到 new_table 的索引上(not-rebuild 数据是在原表上更新)。
重放 row_log 中的 DML 操作到 new_table 的数据行上。
Commit 阶段:
当前 Block 为 row_log 最后一个时,禁止读写,升级到 EXCLUSIVE-MDL 锁。
重做 row_log 中最后一部分增量。
更新 innodb 的数据字典表。
提交事务(刷事务的 redo 日志)。
修改统计信息。
rename 临时 ibd 文件,frm 文件。
变更完成,释放 EXCLUSIVE-MDL 锁。
MySQL 8.0.12 才提出的新算法,目前只支持添加列等少量操作,利用 8.0 新的表结构设计,可以直接修改表的 metadata 数据,省掉了 rebuild 的过程,极大的缩短了 DDL 语句的执行时间。
新的算法依赖于 MySQL 8.0 对表 metadata 结构做出的一些变更。
8.0 除了在表的 metadata 信息中新增了 INSTANT 列的默认值以及非 INSTANT 列的数量以外,还在数据的物理记录中加入了 info_bit,包括一个 flag 来标记这条记录是否为添加 INSTANT 列之后才更新、插入的,以及 column_num,用来记录行数据总共有多少列。
当使用 INSTANT 算法来添加列的时候,无需 rebuild 表,直接把列的信息记录到 metadata 中即可,对这些行进行操作时,可以读取 metadata 的信息来组合出完整的行数据。
各类语句的实现方式也发生了一些变更:
SELECT:读取一行数据的物理记录时,会根据 flag 来判断是否需要去 metadata 中获取 INSTANT 列的信息;如果需要,则根据 column_num 来读取实际的物理数据,再从 metadata 中补全缺少的 INSTANT 列数据。
INSERT:额外记录语句执行时的 flag 和 column_num。
DELETE:与以前的版本保持一致。
UPDATE:如果表的 instant column 数量发生了变化,对旧数据的 UPDATE 会在内部转换成 DELETE 和 INSERT 操作。
当对包含 INSTANT 列的表进行 rebuild 时,所有的数据在 rebuild 的过程中重新以旧的数据格式(包含所有列的内容)写入到表中,所以 rebuild 表之后,information_schema 中有关这个表的 INSTANT 的信息会被重置。
可以使用如下 SQL 命令可以查看每个表当前 INSTANT 列的数量,如果该表没有添加过 INSTANT 列,则 instant_cols 默认显示 0。如果增加过,则最后的该对应数字个数的列为 INSTANT 列(因为 INSTANT 列只能在最末尾)。
借鉴了 COPY 算法的思路,由外部工具来完成临时表的建立,数据同步,用临时表替换源表这三个步骤。其中数据同步是利用 MySQL 的触发器来实现的,会少量影响到线上业务的 QPS 及 SQL 响应时间。
由于 pt-osc 使用了 MySQL 的触发器,在写入量较大的情况下,触发器可能导致 MySQL 的负载增大。
不使用触发器,而是直接通过 binlog 来读取数据并进行同步。避免了 pt-osc 的触发器导致的负载增大问题。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721