
作者介绍
王鹏冲,平安科技数据库技术专家,浸淫数据库行业十多年,对Oracle数据库有浓厚兴趣,也对MySQL、MongoDB、Redis等数据库有一定架构和运维经验,目前正沉迷在PostgreSQL数据库与Oracle数据库的PK之中,重点在关系型数据库的分布式架构研究。
引言
关系型数据库强调事务的ACID特性,对于事务的持久性,主流的关系型数据库都是通过写事务日志来实现的。写数据是随机IO,写日志是顺序IO,常规的机械磁盘,随机IO比顺序IO要昂贵很多。所以虽然写日志同样要刷到磁盘才能算事务提交完成(Oracle、PG、MySQL写日志的控制也各自有不同的机制,后续有空再对比总结),但是由于写日志的速率高于写数据,所以每次会话commit时将事务日志同步刷入online redo logfile,比将数据同步刷入datafile要更加高效。
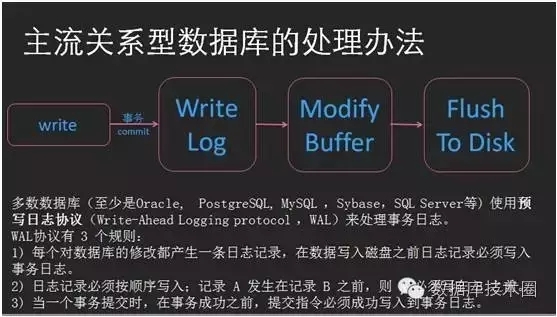
Oracle数据库一样是先写日志后写数据的设计,那么问题就来了,当基于Oracle数据库的应用系统,在业务举办抢售类促销活动等高并发的场景下,短时间内有大量的事务日志需要写入online reo log的时候,日志写的效率就会有一定问题,这个时候Oracle数据库的log file sync会成为主要的系统性能瓶颈,本篇就针对这个问题看看都有什么样的优化思路,以及过往我们都采取过什么样的措施来应对。
一、问题现象
从一次具体案例谈起:
0点整,业务抢售活动开始,几万人同时在线抢单。
APP到DB的连接池瞬时用完,应用线程开始等待。
DB主机cpu使用率迅速100%,DB内部大量wait event。

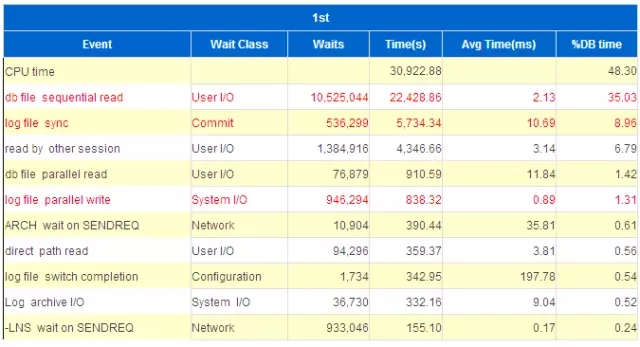
15分钟的AWR如下:
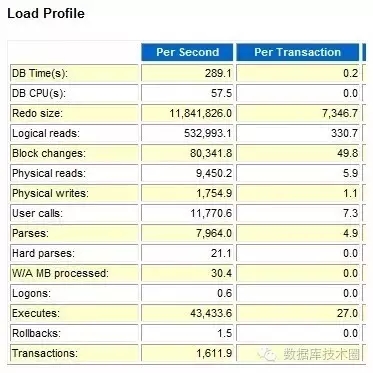
每秒redo size11.8MB、每秒事务量1611.9、每秒执行4.3万、每秒buffer gets 53万…
这还是15分钟的平均值,推算某尖峰时刻可能更高:
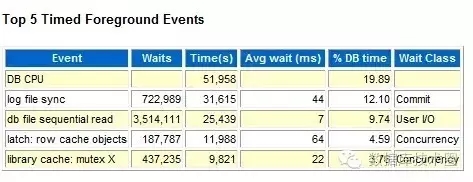
Top 5events里面,log file sync贡献了12.1%的DB time, 当然还有其它的一些latch等待,这些是另外需要分析优化并解决的话题,本篇先不做讨论。

Cpu 使用率100%:
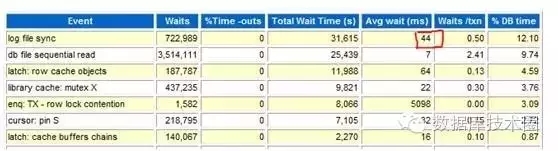
各位看官请继续先忽略其它event,这里看过来:
logfile sync平均等待时间44ms
logfile parallel write平均等待时间9ms。

数据库的架构是:
小型机(solaris)+ Filesystem(Vxfs)+Oracle single instance(11.2.0.3.0)
VCS主备的HA、高端SAN存储
抢售活动过后,此库的并发压力仍旧很大,后期不定期还会有LGWR超时报出:
Warning: log write elapsed time 6123ms,size 1KB
每次LGWR超时,都会引起jdbc连接池Suspended:
CannotGetJdbcConnectionException,Could not create pool connection.
The DBMS driver exception was:IO 错误: The Network Adapter could not establish the connection
每次应用报错,DBA都要被拉去批一次。
各位看官,持续好几个月的这个问题我们不知道怎么熬过去的,幸亏买有Oracle ACS工程师做我们的背锅侠,不对,应该是“坚强后盾”。
什么?你还不知道什么是Oracle ACS工程师,那还玩什么Oracle?
强烈建议购买Oracle ACS服务,有Oracle 驻场专家工程师白天的现场陪伴,有飞虎队之称的Oracle SSC工程师7*24小时全年无休的随时守候,你还担心什么?
二、问题分析与应对
直观来看,是LGWR写入redo log较慢,(当然,log file sync 比log file parallel write多出35ms也不正常,这里面的因素我们先不考虑),本能的反应是将online redolog切换到更高的存储上。但存储方面看到的监控指标,一直其实并没有看到有明显异常。
存储老大如此说:
存储提供的SLA为io能力在0.5ms写,对于特别特征的IO写响应时间会延长到1ms~3ms,(几乎对所有目前其它的oracle数据FRA区写入都是这样的写入响应时间,写fra会比写redo和data长3~6倍的原因是写fra的数据块比较大),为何此库不能忍受而其他库能忍受?
这个现象其实我们也讨论过,总结如下更加形象一点:
假设A、B两个库,平时平均的active session看到A、B库都是100个,但是A库平均每个sql(或事务)都是1ms左右的执行时间,B库平均每个sql(或事务)都是1s左右的,那么当log file sync堵塞了1s的时候,对A库的影响就是瞬间堵塞了1000个会话,而对B库基本没有什么感知。
但是迫于应用压力,更换存储的措施最后还是实施了,但由于当时还未大量采用全闪存存储,所以换到另外一台较为空闲的存储上之后,结果并未得到明显改善。
这里说点废话:
做技术的无法坚持自己的判断,迫于各种蛋疼的因素,不得不去干一些废活,真是奇耻大辱。
后记:
近来存储开始采用大量闪存技术后,我们已经制定数据库存储规范,将所有online redo log要求放到全闪存的DG里面,这个措施有很明显的效果,很多库的log file sync的效率都在零点几毫秒。
我们与solaris工程师、symantec工程师、Oracle工程师进行了联合诊断:
通过truss定位到LGWR的写请求最终都等在KAIO()和pwrite()的调用上,这些是OS层的函数调用。OS pwrite()函数在平时和故障时间段,写相同300k的数据最快一次调用只需要0.0017,但是最慢也达到了1.586秒。
发现了LGWR被VXFS的vx_rwsleep_rec_lock() 阻塞。
随后solaris工程师祭出大招DTrace,倚天一出、谁与争锋!
DTrace脚本的目的是抓取LGWR进程其中一个pwrite上下文的call stack。
……
中间各方各种pk波折,容我先哭会儿:
满纸荒唐言,一把辛酸泪。
都说DB堵,谁解其原委?
由于我们的数据库使用的是文件系统,没有使用ASM,所以lgwr每次写入online redo log file,都要经过Filesystem这一层。
第一篇《Oracle高并发系列1:DML引起的常见问题及优化思路》中亮相过的大内第一高手再次发话:“如果问题真的出在vx_rwsleep_rec_lock或者vx_rwunlock上,那么即使使用direct_io也是无法解决问题的,还是会有inode上的rw lock,但是ODM可以彻底解决这个问题。”
ODM技术其实也是主机同事一直建议启用的,但是由于对于读有副作用,所以之前我们一直没有考虑实施。
没有其它办法了,逼上梁山了。
ODM(Oracle Disk Manager)
Whenthe Veritas ODM library is linked, Oracle is able to bypass all caching andlocks at the file system layer and to communicate directly with raw volumes.The SF Oracle RAC implementation of ODM generates performance equivalent toperformance with raw devices while the storage uses easy-to-manage filesystems.
更多信息参考这两篇MOS文档:
How to Enable/Disable the Veritas ODM forOracle database (文档 ID 755159.1)
How To Validate/Verify ODM (Oracle DiskManager) Is Enabled. (文档 ID 1352242.1)
ODM虽然能够加快写的性能,但是由于启用ODM绕过了Filesystem这一层,对于数据库最常见的physical read,就失去了可以从os cache读到数据的益处了,这个其实对数据库的一些有物理读发生的sql影响很大,经过我们的测试验证(不同IO子系统环境测试结果不一样,主要看对比值,不是绝对值):
启用ODM之前,db file sequential read为2ms,
启用ODM之后,db file sequential read 为6ms。
(插播DBA守则1条: 生产任何重要变更之前,都要做测试验证,必要时做dbreplay负载重演测试。)
所以,为了解决此问题,我们要考虑加大db cache size,增加db cache size可以提高缓存命中率,使得发生物理读的次数减少。
但是如果还是有SQL只要发生了物理读,其效率还是会下降的,这部分的风险始终存在。
那么如何评估这部分风险到底有多高呢?
大致总结了一个评估表格:
假设数据库总的读的request一定的前提下,根据我们统计到的db和os的cache命中率等数据,数据库只会有少于2%的读请求会落在dbcache之外:

而且对于directpath read这种通过PGA的读的场景, 对于filesystemcache也不会敏感。
*oscache命中率1.32 =(1-98.39%)*82%, 82%是通过kstat大致算出来的oscache命中率。而且这个82%里面,可能os本身、oracle软件本身等都贡献了一部分, 那么真正数据库数据文件在os cache里面的命中率其实是还要更低于82%的。
综合来看,风险较小。
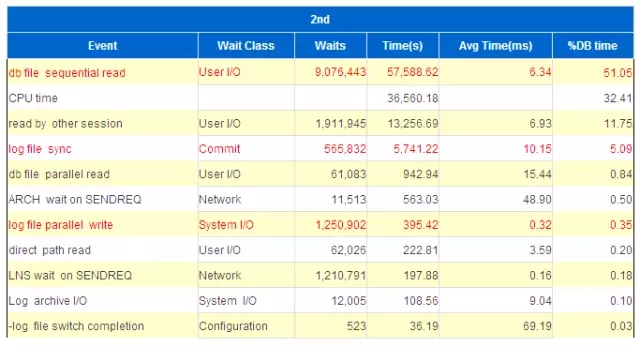
db file sequential read 等待次数下降了,因为db cache增加了;但是平均单次等待时间变长,因为没有了OS cache。
Log file parallel write 的等待次数增加了,今天的事务量有增加,但是平均等待时间降低了,0.8ms -> 0.3ms ,是启用ODM的效果。
Direct path read平均等待时间没有怎么变化,与之前预测一致。
之前预测的Db cache size增加20GB之后的cache命中率:
(1-(1-0.9839)*0.8)*100 = 98.712 %
(其中0.8是根据db cache advice得到的物理读减少的百分比)
调整后实际的命中率,与预测也差不多:

小明:老师,Log file sync平均等待时间没有怎么变化,为什么?
王老师:估计跟_use_adaptive_log_file_sync有关,目前平均都是10ms。如果调整完毕隐参的话,估计会看到更明显的优化效果。
三、尼玛,_use_adaptive_log_file_sync又是干嘛的?
1、在11.2.0.3之前, log file sync是Post/wait的行为:
When a user session commits (or rollsback), the redo information needs to be flushed to the redo logfile. The usersession will post the LGWR to write all redo required from the log buffer tothe redo log file. The user session waits on ‘log file sync’ while waiting forLGWR to post it back to confirm all redo changes are safely on disk.
2、在11.2.0.3以及之后, log file sync是根据内部算法在Post/wait 和 polling两种形式之间进行切换(这个就叫Adpative Log FileSync):
Thereare 2 methods by which LGWR and foreground processes can communicate in orderto acknowledge that a commit has completed:
Post/wait - traditional method available in previous Oracle releases LGWR explicitly posts all processes waiting for the commit to complete.The advantage of the post/wait method is that sessions should find out almost immediately when the redo has been flushed to disk.
Polling - Foreground processes sleep and poll to see if the commit is complete.The advantage of this new method is to free LGWR from having to inform many processes waiting on commit to complete thereby freeing high CPU usage by the LGWR.
Initially the LGWR uses post/wait andaccording to an internal algorithm evaluates whether polling is better. Underhigh system load polling may perform better because the post/waitimplementation typically does not scale well. If the system load is low, thenpost/wait performs well and provides better response times than polling. Oraclerelies on internal statistics to determine which method should be used. Because switching between post/wait and polling incurs an overhead, safe guardsare in place in order to ensure that switches do not occur too frequently.
3、如何定位11.2.0.3以及以后版本的数据库的log file sync受到了这个行为变化的影响:
当发现数据库有较多的log file sync,并且其平均等待时间较长,例如7-8ms,且直方图分布落在1ms以下的较少;但与此同时log file paralle write 的平均等待时间并不长,比如说1-3ms,说明不是因为LGWR写慢造成的log file sync,而同时应用commit也不是很大量的增长, 则有可能是由于Adpative Log File Sync造成的log file sync。
可以从$ORACLE_BASE/diag/***/trace/*lgwr.trc 这个lgwr的trace文件里面看到较为频繁的post->poll / poll->post 的来回切换:

4、如何禁用adpative log filesync:
alter system set"_use_adaptive_log_file_sync"=false scope=both;
5、如何查看确认修改后的效果:
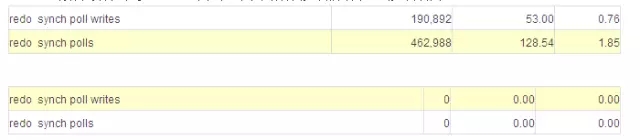
log file paralle write 的平均等待时间不变,修改完毕隐含参数后,log file sync 平均等待时间变短,比如从7ms 降到了3ms。
AWR报告或者v$sysstat里面的这两个指标修改前有值,修改后为0:
四、全部调整完毕的效果
对比发现Log fileparallel write 和log file sync 的平均等待时间明显降低,Logfile parallel write从1ms左右降到当前0.3ms,logfile sync上月大部分都在1.5ms以上,而调整后数据基本都在1ms以下。
调整前:
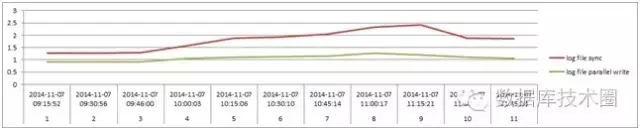
调整后:

另外,db filesequential read的平均等待时间虽然有增加,但是应用层监控并没有发现有明显变慢的情况,所以基本也符合预期。
数据库启用ODM对存储端性能的影响:
读IOPS量巨增,开启前繁忙时段在1500*2=3000左右,开启后繁忙时段在5500*2=11000左右,大概有3.6倍。
写IOPS量略有下降,开启前繁忙时段在300*2=600左右,开启后繁忙时段在250*2=500左右.
读响应时间从原来的8~9ms左右,降低为7~8ms左右。同时发现读命中率上升,开启前是20%~25%,开启后是30%~50%。原因是频繁访问的数据进入了存储cache中。
写响应时间,开启前繁忙时段0.25ms左右,开启后上升到0.5ms左右,分析发现写命中率有下降,开启前40%~70%,开启后是20%~50%。原因是存储cache是读写共享的,如果大量的Read IO占用了内存空间,Write IO的空间就会减少
RG使用率在开启ODM后整体上升了2%左右。
当然,后期我们除了优化log file sync之外,还联合开发人员一起优化了其它前期发现的一些应用层的数据库设计问题,例如sql的cursor pin S等等。
在后续的又一次年度抢售活动中,系统表现优异:
每秒的SQL执行量达到7万+。
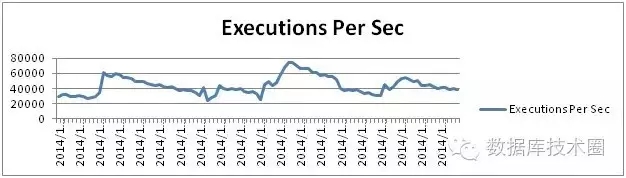
高峰期每秒的事务量每秒达到3000。
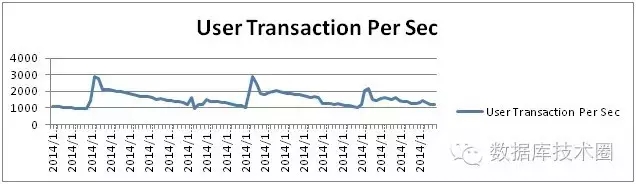
IO 效率的指标如下:
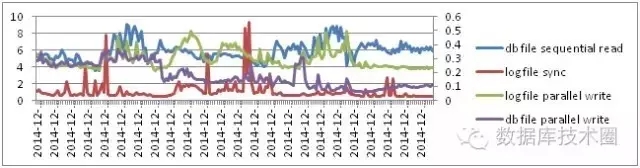
其中log file sync在在启用odm并关闭adaptive log file sync后,在抢售活动的高并发压力下,等待次数有较大增长的情况下,平均等待时间为2ms,效果非常突出。

五、还有可能影响log file sync的其它因素
精力有限,篇幅有限,另外简单罗列两点可能因素:
1、进程优先级
1)在10g中,要考虑参数_high_priority_processes是否需要将LGWR进程设置。
2) 在11.2.0.2以上的环境中,详见SPARC: Reducing High Waitson 'log file sync' on Oracle Solaris SPARC by Increasing Priority of Log Writer(Doc ID 1523164.1)。
3)在11.2.0.4之后,lgwr的进程优先级自动为FX的class的进程优先级。
2、log file switch
适当调整log buffer,适当增加 log file size,可以使得logfile switch的频率变长, 有机会使得log file switch 的次数减少,间接一定程度上减少log file sync等待发生的几率。因为有时候log file sync的holder可能是log file switch。 而且log file switch太频繁会导致后台频繁报cannot allocatenew log(这个可能也跟CKPT有关,这个因素另当别论)。
也有些Oracle老司机会说,LGWR刷日志的条件是: user commit、1/3满、1MB、3秒、在DBWR之前,已经很频繁了,所以将log buffer调小对于log file sync没有太大意义。但是,其实是有其它关联的:
当你发现Oracle数据库的归档日志切换特别频繁,比如说1分钟1-2个,而且磁盘上实际的archivedlog的size远远小于online redo logsize的时候,说明有可能是下面这个问题引发,请参考如下材料分析和调整。
参考文档:
Archived redolog is (significant) smaller than the redologfile.(Doc ID 1356604.1)
Archive Logs Are Created With Smaller, Uneven Size Than TheOriginal Redo Logs. Why (Doc ID 388627.1)
简单来讲:
cpu count、log buffer、online redologfile size, 会影响到Oracle计算分配redostrand的个数、以及redo strand的size,以及online redo log被多个redo strand瓜分的机制,进而当Oracle并发redo stand去从logbuffer写redo entry到redolog file时,就会出现任意一个strand写满时,就要求发生log file switch的情况出现。
为解决这个问题,我们制定的规范:
16MB =< Log_buffer <= min(128MB, max(AUTO_SIZE,16M))
300MB =< online redoLog file size <= 1024MB
其中AUTO_SIZE = (number of strand) * (size of perstands)
=(cpu_count/16) * (cpu_count*128)
在上述取值范围内,再考虑其它方面(例如log_buffer本身是否足够、redo log 1小时的切换次数等等),适当调整二者的大小。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721