

陈宏义,10年开发,10年DBA,曾服务于SONY,ORACLE GCS,现在就职于北京中亦安图上海分公司。
公式:
COL >= val谓词的选择率(无直方图)
((high_value - val)/(high_value - low_value)) * A4NULLS
A4NULLS为非空率
A4NULLS = (NUM_ROWS - NUM_NULLS)/NUM_ROWS
实验:
drop table t1;
create table t1 (id number);
declare
vid number;
begin
for i in 1..1000 loop
if mod(i,30) = 0 then
vid := null;
else
vid :=i;
end if;
insert into t1 values(vid);
end loop;
end;
exec dbms_stats.gather_table_stats(null,'T1');
col high_value for a20
col low_value for a20
select num_rows from user_tables where table_name = 'T1';
NUM_ROWS
----------
1000
select high_value,low_value,num_nulls,histogram from user_tab_columns where table_name='T1' and column_name='ID';
HIGH_VALUE LOW_VALUE NUM_NULLS HISTOGRAM
-------------------- ------------------------------ ---------- ---------------
C20B C102 33 NONE
drop table t1;
create table t1 (id number);
declare
vid number;
begin
for i in 1..1000 loop
if mod(i,30) = 0 then
vid := null;
else
vid :=i;
end if;
insert into t1 values(vid);
end loop;
end;
exec dbms_stats.gather_table_stats(null,'T1');
col high_value for a20
col low_value for a20
select num_rows from user_tables where table_name = 'T1';
NUM_ROWS
----------
1000
select high_value,low_value,num_nulls,histogram from user_tab_columns where table_name='T1' and column_name='ID';
HIGH_VALUE LOW_VALUE NUM_NULLS HISTOGRAM
-------------------- ------------------------------ ---------- ---------------
C20B C102 33 NONE
HIGH_VALUE , LOW_VALUE 可以用dbms_stats.conver_raw_value转换成可以读懂的数字,字符,日期。
这个案例里ID列的最小值是1,最大值是1000。
NUM_ROWS:1000
LOW_VALUE:1
HIGH_VALUE:1000
NUM_NULLS:33
HISTOGRAM: NONE
根据上面的公式,可以算出选择率:
谓词:ID>=700
A4NULLS=(1000-33)/1000=0.967
Selectivity=(1000-700+1)/(1000-1)*0.967=.291358358
Cardinality = 1000*.291358358 = 291.358358
最后得出的cardinality是291
四舍五入,最小值是1
用执行计划来验证一下:
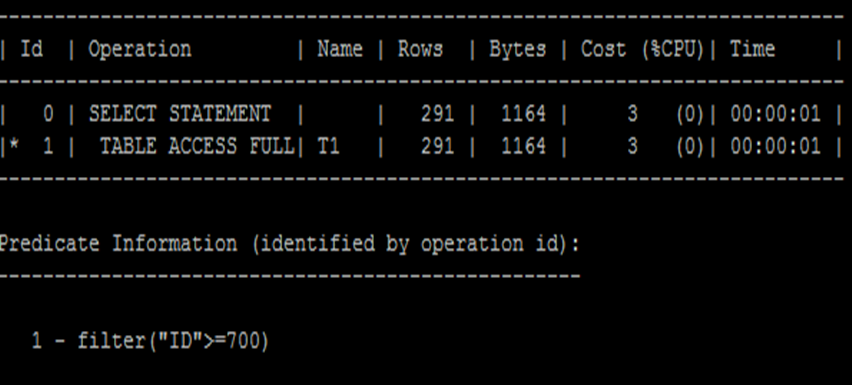
数字可以简单地加减,但是字符串就没有办法了。
字符串是没有办法进行加、减运算的,Oracle会把它转换成一个内部的数字 ,这个转换算法在SQLT中公布出来。
SQLT中的函数名为:get_internal_value
Create or replace FUNCTION get_internal_value (p_value IN VARCHAR2)
RETURN VARCHAR2
IS
temp_n NUMBER := 0;
BEGIN
FOR i IN 1..15
LOOP
temp_n := temp_n + POWER(256, 15 - i) * ASCII(SUBSTR(RPAD(p_value, 15, CHR(0)), i, 1));
END LOOP;
RETURN TO_CHAR(ROUND(temp_n, -21));
EXCEPTION
WHEN OTHERS THEN
RETURN p_value;
END get_internal_value;
这是用pl/sql实现的转换字符串为数字的算法。CBO在算的时候,一定不是用pl/sql是用C
例如,
Sample,
------------------------
SQL> select get_internal_value('AAAAA') from dual;
GET_INTERNAL_VALUE('AAAAA')
--------------------------------------------------------------------------------
338822822454670000000000000000000000
CBO在算>,< between这类谓词时用的就是这个数字。
这个算法,不具有唯一性,经常会不同的字符串得到相同的internal_value, 如果因为这个问题导致了数据分布倾斜,Oracle会为这个列收集直方图,并用endpoint_actaul_value来校准
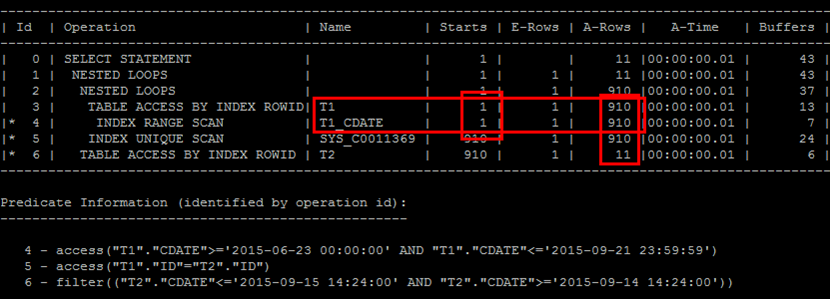
drop table t1;
drop table t2;
create table t1(id number primary key,cdate varchar2(20));
create table t2(id number primary key,cdate varchar2(20));
create index t1_cdate on t1(cdate);
declare
s date;
begin
s := to_date('2015-03-23 00:00:00','yyyy-mm-dd hh24:mi:ss');
for i in 1..10000 loop
insert into t1 values(i,to_char(s,'yyyy-mm-dd hh24:mi:ss'));
insert into t2 values(i,to_char(s,'yyyy-mm-dd hh24:mi:ss'));
s := s+0.1;
end loop;
commit;
end;
/
exec dbms_stats.gather_table_stats(null,'T1',method_opt=>'for all columns size 1');
exec dbms_stats.gather_table_stats(null,'T2',method_opt=>'for all columns size 1');
alter session set statistics_level=all;
select * from t1,t2 where t1.id = t2.id and
t1.cdate between '2015-06-23 00:00:00'
and '2015-09-21 23:59:59'
and t2.cdate between '2015-09-14 14:24:00' and '2015-09-15 14:24:00';
select * from table(dbms_xplan.display_cursor(null,null,'ALLSTATS'));
这是sample的代码
从上面的执行计划中可以看出,T1表通过谓词t1.cdate between '2015-06-23 00:00:00' and '2015-09-21 23:59:59'的过滤得到910行数据,而CBO估算它1行。
T2表通谓词t2.cdate between '2015-09-14 14:24:00' and '2015-09-15 14:24:00'的过滤,得到11行数据,而CBO却估算成910行.
由于这个估算偏差导致错误地使用了T1作为nested loop的驱动表。
我们看一下'2015-06-23 00:00:00','2015-09-21 23:59:59'这两个字符串,化成的internal value是什么。
'2015-06-23 00:00:00' = 260592297225015000000000000000000000
'2015-09-21 23:59:59' = 260592297225015000000000000000000000
由于这两个值是相同的,所以这个条件,就相当于=了。所以计算出的cardinality就非常低。
解决方案:
1. 收集直方图;
2. 将varchar2型改成date型。
收集直方图后,执行计划变为:
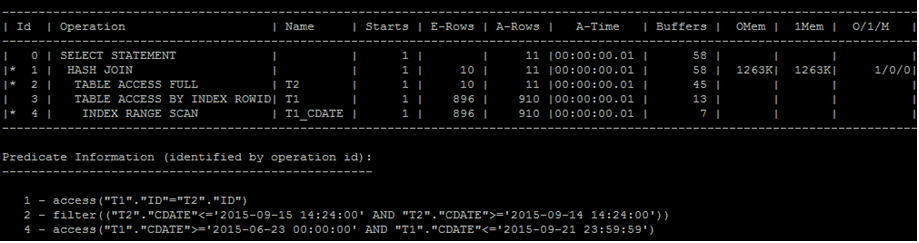
另外,dba_histograms.endpoint_actaul_value这个列就是干这个用的。校准 internal value重复的情况。
“DBA+社群”将陆续在各大城市群进行线上专题分享活动,以后的每周二、周四晚上都将成为【DBA+专题分享】的固定时间,欢迎大家积极加入我们。无论是内容还是形式,有好的建议我们都会积极采纳。想参与的小伙伴们可关注我们的微信号:dbaplus。

扫码关注
DBAplus社群
来自各领域的牛逼DBA正在向我们汇聚








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721