
大年初三,酒足饭饱后,拉着亲朋好友就这么餐桌上一围,小赌正式开始。正要胡牌时,手机响了。一看竟然是客户的电话!难道是给我拜年么?!应该不是,昨天就拜过了。难道出什么问题了?!果然。。这来的也太不是时候了。不过作为一个资深的运维DBA,对于这种7*24*365式实时守候待命的日子早就习以为常。麻将顺势一推,迅速更换为笔记本,开始一段抽丝拨茧之旅!
2016年02月10日,某省账务库日账出现严重延迟现象,期间其他应用运行正常。
对于这种性能突变的问题,还是采取老套路,采集“凶案现场”情况如下:
注:(性能突变的数据库为11g R2 RAC)
1、两节点的数据库alert日志信息。
2、两节点问题时间段的snapshot(注:收集多份及正常时间段的AWR报告进行对比分析)。
3、两节点问题时间段及前后一小时的OSW日志。
4、两节点问题时间段所有相关trace信息。

5、问题时间段的ASH DUMP数据。

1、通过LGWR的trace信息,我们可以发现问题时段log write写超过500ms的告警,说明当时redo IO性能应该存在一些问题。
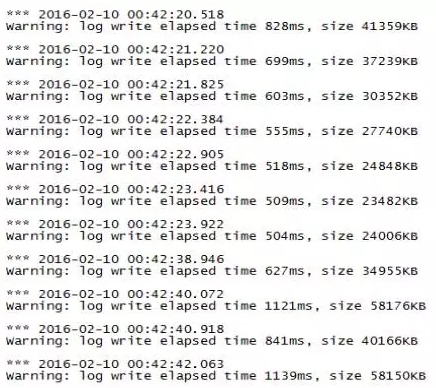
2、通过分析ASH DUMP信息我们可发现,44%的会话被log file sync堵塞,同时 log file sync在等待log file parallel write 。
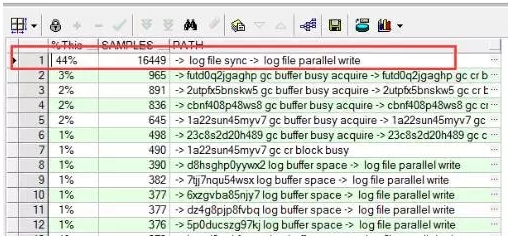
3、通过查看AWR报告我们可以发现,log file sync等待高达431ms,同时出现大量GC等待事件,并且出现log buffer space等待事件。
那么导致该问题是由于log_buffer配置太小?还是redo log太小导致redo log切换过于频繁?如果是的话,那么为什么2月10号前的日账没有问题,该结论不成立!那么应用端是否存在变化?!
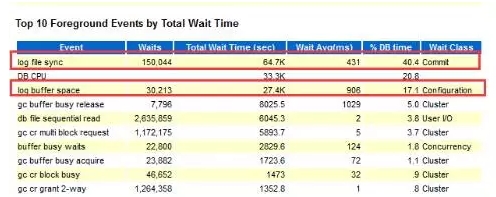
4、针对TOP中大量的GC等待,我们对比分析了1月10日跟2月10日的Global Cache统计数据,发现事发时段GC接收的块较以往增幅20%,同时私网流量也从21M上升到26M,GC交互的增加是否可以说明应用侧做了调整呢?!
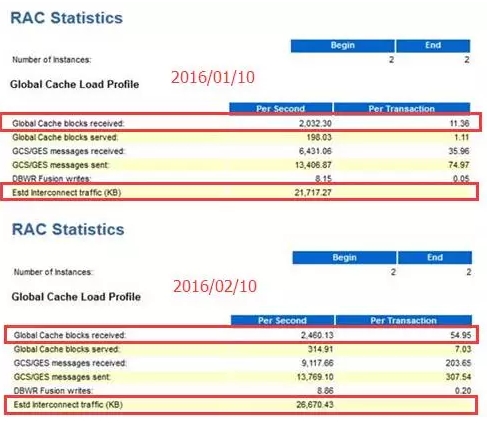
通过咨询应用维护人员,我了解到,日账数据量会伴随时间的推移而增加,同时日账的时间同步也会有所延迟。如下图所示:
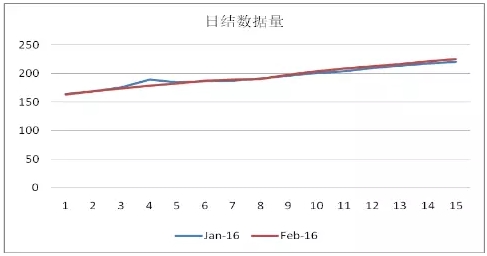
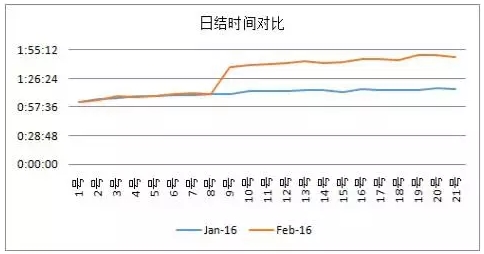
虽然日账数据量及执行时间在同一月内会伴随时间的推移而增加,但是通过上面的“日结时间对比”图可以看出,2月10日的日账时间明显突增,说明导致该问题的还有其他原因。
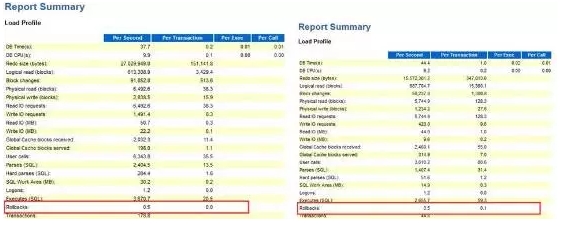
5、通过问题前后的AWR报告对比分析,我们发现,在2月10日之后,ROLLBACKS从之前的每秒0.5次增长至每秒3.5次,增长了7倍。
6、通过分析log file sync发现,自10号凌晨开始数据库写入时间较之前出现明显上升。
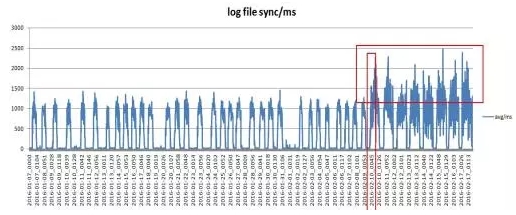
问题时段log file sync/log file parallel write较之前开始出现明显下降,如下表所示:

7、通过OSW的VMSTAT数据,我们也可以发现,在批量日账未运行之时,B列值相对较低,在问题时间段B列在10以上,这说明所有的CPU都是pending在I/O层面。
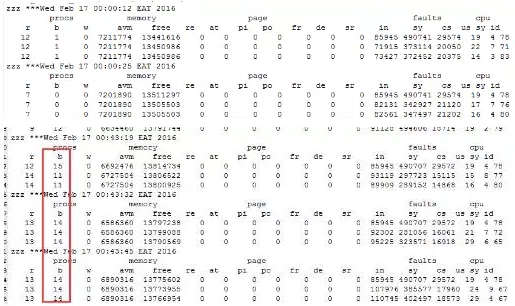
8、通过OSW的MPSTAT数据,我们也可以发现,问题时间段部分磁盘始终处于100%busy的状态,而且磁盘平均服务时间在80ms以上。
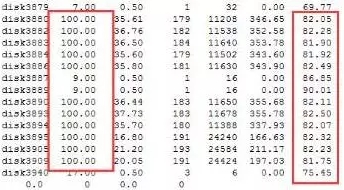
综上所述,主要有以下几方面的影响因素:
log file sync及log file parallel write 性能明显下降, redo IO性能变差导致GC严重及数据库性能严重下降。需要主机及存储厂商配合确认。
应用侧是否存在调整,导致GC交互的增加及其他引发问题。需要应用侧配合确认。
问题前后的每秒rollback次数增长了7倍,建议协调应用一起排查rollbacks异常增长的原因。
通过分析,问题可能出现在主机or存储or应用层面上,通过逐个沟通确认,得到回复如下:
主机球员:
通过分析,主机侧未发现异常,还请知悉!
存储球员:
从我这边看是正常的,没有出现瓶颈或者非常慢的情况。
应用球员:
你好,
通过应用侧核实,在日账问题前后属于春节封网时段,无任何应用变更。
足联主席:
To DB运维组
请尽快完成日帐问题定位,为了避免影响月底出账,请务必在月底前完成定位并修复。
通过一轮咨询,各组成员都反馈尚未发现异常,怎么办?!都没异常,那日账为何会突然延迟呢?!此时球兜了一圈又回到了咱们dba手上。此刻要冷静,再回首缕一缕。
从剖析日志及各组反馈的结果综合看来,问题肯定来自redo io层面,既然主机及存储侧都反馈无异常,那么问题是否在最底层(存储链路)? 马上联系HDS工程师,令其去查看存储链路是否存在异常。
30min后接收到HDS工程师的反馈,兄弟们,根源找到了!这才合上笔记本仰天长叹!!!
我们来看下底层架构:
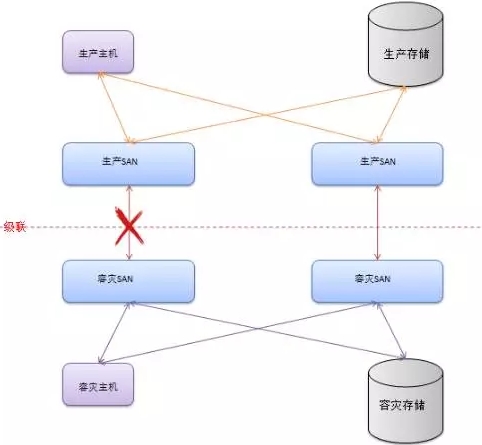
该省账务库物理容灾采用Veritas镜像技术实现存储底层同步。当应用发起变更数据请求时,必须等待生产、容灾两份存储全部完成写入后,方可反馈提交信息。事发当天该库对应的2条SAN级联链路中有一条出现了异常,到容灾存储的数据变更速率均减半,这样就导致了批量操作(日账)延迟!
作者介绍:张玉朋
新炬网络高级技术专家。
5年以上电信行业运维经验。
擅长oracle架构规划,故障诊断、性能优化、shell编程等,对大型IT系统的oracle数据库运维有丰富的经验。
曾主导某省移动核心CRM、BOSS升级项目。
往期作品:玩转Greenplum集群主备机替换
全球敏捷运维峰会【杭州站】

2016 年4月16日,与你相约杭州,来一场敏捷与运维的美丽邂逅!DBA+社群联合三墩IT人开启全球敏捷运维峰会第一站:杭州站!峰会力邀来自互联网与传统企 业的资深专家,各路大咖齐聚,汇聚500+行业精英,聚焦架构、敏捷、运维三大主线,开启一场专属于IT人的年度之约!
专家阵容:或行业资深派、或著书力作派、或传统转型派、或一线实战派,总有一款是你喜欢!
绝对干货:聚焦架构、敏捷、运维三大主线,共讨传统企业在技术转型过程中的实践与困境、互联网企业在前沿技术方面的应用与心得、技术服务型企业在新老技术之间如何切换与落地,拒绝无营养的广告,绝对干货,精彩不容错过!
连接联动:汇聚社群数百顶级专家人脉,携数万社群成员声势,联合数十家媒体单位,共同打造一场连接敏捷与运维圈子的年度之约!
门票:免费!(限时限额)
VIP票:199元(限3月20日前)








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721