
IMO,即In-Memory Option。为Oracle 12c中最为重要的新特性之一。12.1开始支持该新特性。
目录
基本介绍
可以启用In-Memory列存储功能的级别
适合使用IMO功能的操作类型
可以使用INMEMORY子句的命令
查询数据库中哪些segment启用了IM
不适合使用IM的操作
数据压缩
IM的存储设置
与IMO相关的初始化参数
在表,表空间,或者物化视图上启用IM
与IM相关的等待事件
与IM相关的统计信息
一.基本介绍
In-Memory列存储组件,为12c 中SGA的可选组件。可以用来存储表、表分区、以及其他数据库对象的副本。启用该选项,我们可以在SGA中按列存储某些对象,而不是原来的按行存储。
ps:看到按列存储,会有人想到Sybase的IQ数据库咩?
In-Memory列存储是SGA中的一个新的静态池(static pool)。所谓静态,也就是说里面的对象需要我们dba手工管理。在该池中,数据都是按列存储,而原来sga的db buffer cache中,数据依然还是按行存储。这样,整个内存,就可以同时提供数据的按行和按列存储。要启用该选项,INMEMORY_SIZE参数,需要设置为非零值。当然,不能小于100M,否则,你会碰到如下错误:

二. 可以启用In-Memory列存储功能的级别
Column
Table
Materialized view
Tablespace
Partition
如果在表空间级别上启用该功能,则所有存储在该表空间中的表和物化视图都将继承这一功能。
三. 适合使用IMO功能的操作类型
A query that scans a large number of rows and applies filters that use operators such as the following: =, <, >, and IN
A query that selects a small number of columns from a table or materialized view with a large number of columns, such as a query that selects five columns from a table with 100 columns 查询一个多列对象中的少数几列
A query that joins a small table to a large table
A query that aggregates data
需要注意的一个点:一般情况下,复合索引可以用来提升某些分析或者报表查询的性能。但是,当数据为按列存储时,这些索引,基本就不需要了。
四. 可以使用INMEMORY子句的命令
CREATE TABLE
ALTER TABLE
CREATE TABLESPACE
ALTER TABLESPACE
CREATE MATERIALIZED VIEW
ALTER MATERIALIZED VIEW
五. 查询数据库中哪些segment启用了IM
想查询当前数据库中哪些segment启用了IM,可以执行如下查询语句:
SELECT OWNER, SEGMENT_NAME, INMEMORY_PRIORITY, INMEMORY_COMPRESSION
FROM V$IM_SEGMENTS;
例如:


注意这个查询的后两列:
INMEMORY_PRIORITY,优先级设置,如果没有设置则为none。
INMEMORY_COMPRESSION 压缩级别,也就是说,可以压缩存储。
需要注意的是,数据库对象即便启用了IM,该对象也不一定就会放到内存中。所以,执行该查询,可能无法查到你想要的结果。比如:

--查询结果当中木有啊,那把这张表在IM中的优先级设置一下看看。
--注:关于优先级,我们后面再说。

--恩,还是木有。是优先级太低了?
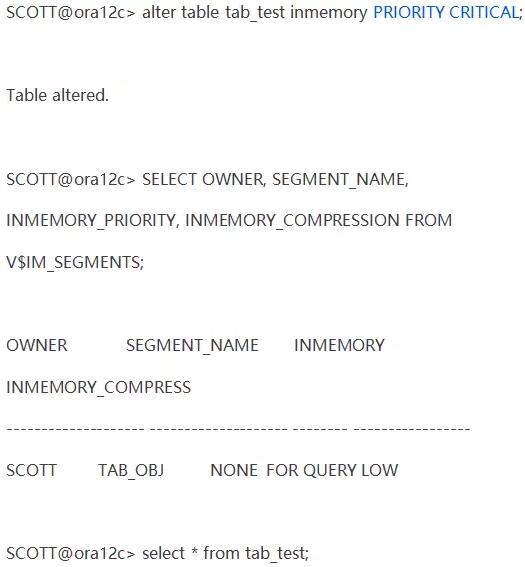

在对表tab_test启用IM时,即便设置了最高的优先级,也还是查询不到。
在这里稍微推测一下,应该跟表的数据量相关。
六. 不适合使用IM的操作
Queries with complex predicates
Queries that select a large number of columns
Queries that return a large number of rows
Queries with multiple large table joins
另外,如果对象的所有者为sys,或者是存储在SYSTEM 或SYSAUX表空间中的,则无法使用IM选项。
七. 数据压缩
在IM列存储选项中,可以将数据压缩,然后缓存到内存中。压缩选项如下:

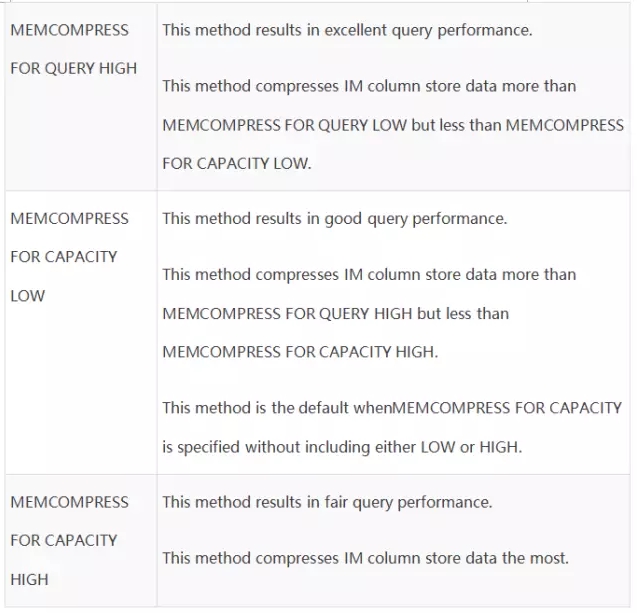
IM操作,可以分别针对DML、query以及capacity等数据缓存用途进行不同级别的压缩,压缩级别越高,可存储的对象也就越多,但是性能就会下降。
来看个例子:
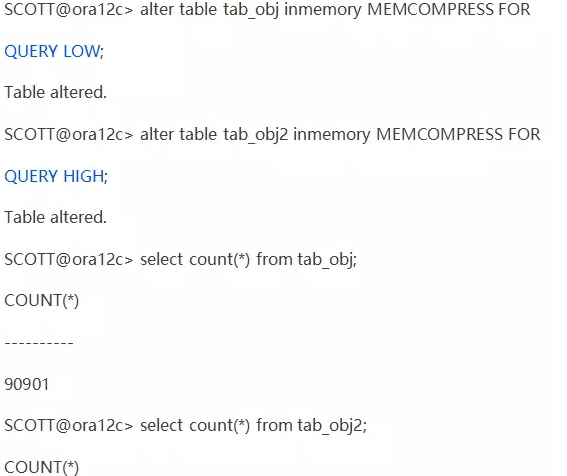

可以看到压缩效果。
注:这两个测试表都是通过CTAS方式以dba_objects中的数据创建。
八. IM的存储设置
IM占用的是SGA的空间,由参数inmemory_size手动控制。
但是该参数为上限设置,如果要启用IM选项的对象大小加起来超过了该参数的值,那怎么办?
当我们对多个对象启用IM时,我们可以让oracle自己来处理,看看空间不够的时候,oracle会把哪些对象移出IM。
另外一种方法,则是在给对象启用IM时设置优先级。
IM中可以设置的优先级如下:
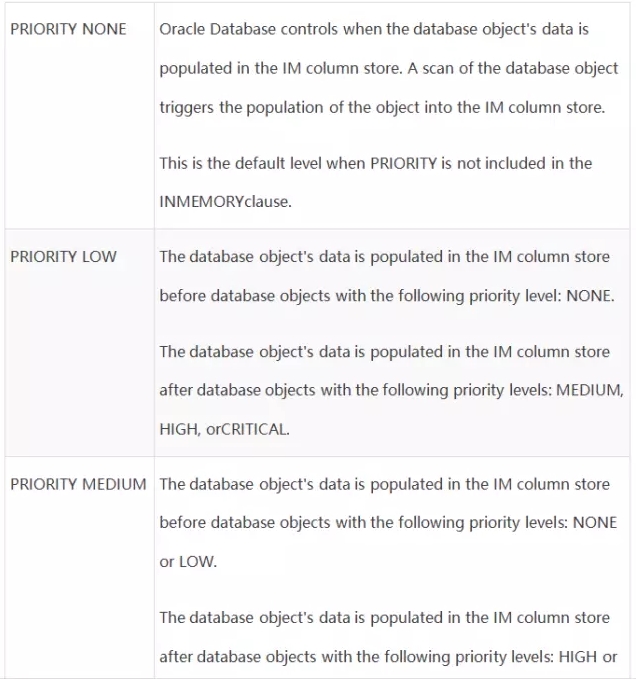
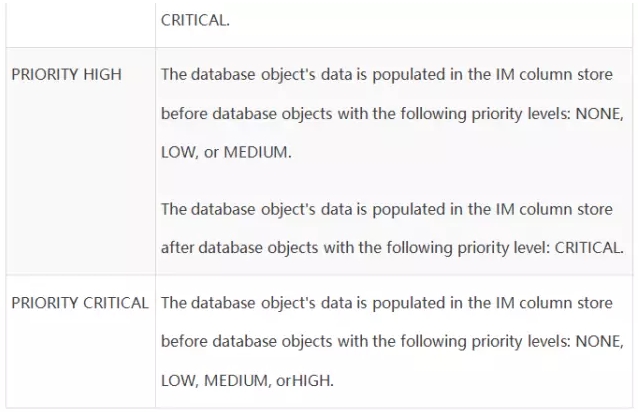
表格中的优先级从低到高,优先级越高,往IM里面存放的时候,就越优先考虑。实质上,算是对要缓存对象的优先级排序,以便oracle在IM空间不足的时候,知道如何处理对象。
当数据库重启时,所有优先级为非none的对象,都将在数据库启动过程中缓存到IM中。
需要注意的是:
1,优先级只能应用于表或者表的分区级别,而无法应用到列级别上。
2,如果对象小于64K,则该对象不会存放到IM中。前面的tab_test就是如此。
来看实验:
数据库版本12.1.0.2,os版本rhel6.4,本IM系列文章均是如此。





ok,那么,如果启用IM的表,数据量发生了变化,那IM能自己探测么?
往下看:
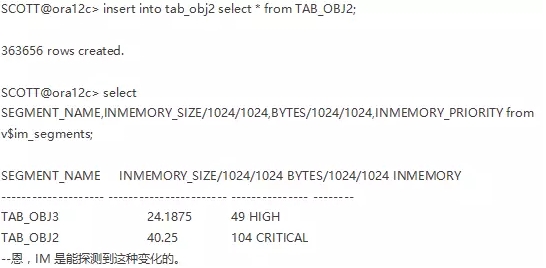
但是我又查了下统计信息收集,user_tables里面反倒木有更新:

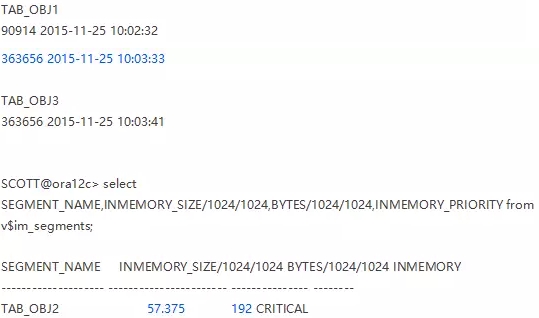
注意蓝色的内容,行数和统计信息收集时间都没有发生变,但是IM中的却都变化了。
另外,我又测试了下tab_obj3,将其优先级从high降至low,然后也是立马就被丢出IM了········

稍微总结一下:
1.即便设置了表的inmemory选项,也必须要在访问表中数据之后,才会被缓存到IM中。
2.已经缓存在IM中的表,如果降低其优先级,将会被从IM中移除(实际上,只要优先级发生改变,则该表就会被移除。这一点,各位可以自行测试确认)。
3.IM会自动感知存放在IM中的表的数据变化,但是原有以行模式存储的数据的统计信息,则不会自动更新。
继续做实验:



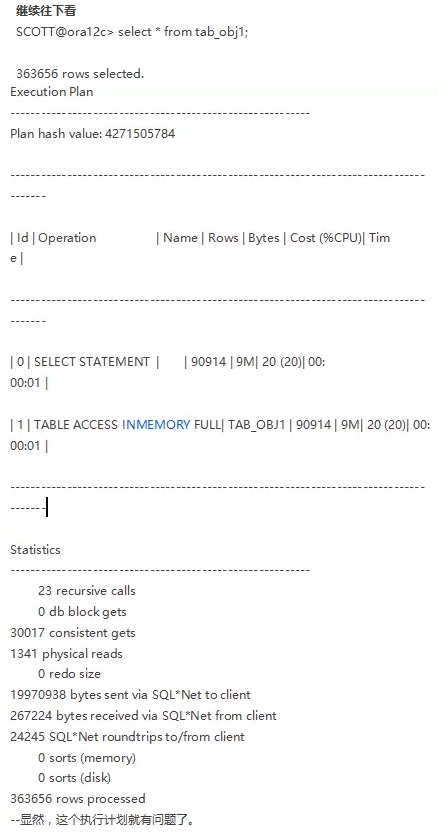
也就是说,如果给表启用了IM,即便这张表没有被存入到IM中,其执行计划显示也会是TABLE ACCESS INMEMORY FULL。
当然,实际的执行计划显然不会是这个。这一点,我们需要注意。
九. 与IMO相关的初始化参数
INMEMORY_SIZE:IM使用的内存空间大小,默认为0。如果非零,则不得小于100M。但是在多租户环境下,单个pdb的IM size,便不受CDB中该参数大小的制约,如果你手工设置某一个或者某几个PDB的IM size的话。如果不单独设置,则各个pdb直接继承CDB中该参数的设置。
INMEMORY_FORCE:是否启用IM,如果为default,则启用;为off,不启用。
INMEMORY_CLAUSE_DEFAULT:该参数指定了默认的IM子句的内容。如果为空,也就是其默认值,等同于no inmemory。但是如果指定了非空值,则会改变IM的默认设置。
例如:
alter system set
INMEMORY_CLAUSE_DEFAULT='INMEMORY MEMCOMPRESS FOR CAPACITY HIGH'
scope=spfile;
然后重启数据库,选择一张表,启用IM:
alter table tab_test inmemory;
则等同于:
alter table tab_test inmemory memcompress for capacity high;
关于该参数,更详细的内容,可参考:
https://docs.oracle.com/database/121/REFRN/GUID-5772F775-2A3E-4BC8-AA03-B8FF383BEE52.htm#REFRN10350
INMEMORY_QUERY:指定是否启用IM查询。将其设置为enable,则启用;disable,则不启用。
INMEMORY_MAX_POPULATE_SERVERS:该参数指定了处理IM数据的最大后台进程个数。依赖于系统的cpu内核数目,有点类似于并行进程相关的参数设置。
INMEMORY_TRICKLE_REPOPULATE_SERVERS_PERCENT: 该参数用于控制IM中对象数据的重新载入的进程数,该值为INMEMORY_MAX_POPULATE_SERVERS参数的百分比。
OPTIMIZER_INMEMORY_AWARE:用于控制CBO是否使用IM选项,为false,则忽略;为true,则考虑。
十. 在表,表空间,或者物化视图上启用IM
要在表,表空间,或者物化视图上启用IM功能,你需要先在数据库级别启用IM选项,也就是说,你要满足如下条件:
1.数据库版本在12.1.0或者以上。
2.inmenory_size设置为100M或者以上。
3.重启数据库
4.查看下当前im可以使用的内存大小:
show parameter inmemory_size。
当然,这一步可选。
与表相关的IM的几个例子:
1.在创建表时直接启用IM:
CREATE TABLE test_inmem (
id NUMBER(5) PRIMARY KEY,
test_col VARCHAR2(15))
INMEMORY;
2.创建表完成之后,使用alter命令启用IM:
ALTER TABLE oe.product_information INMEMORY;
3.启用IM并设置压缩级别:
ALTER TABLE oe.product_information INMEMORY
MEMCOMPRESS FOR CAPACITY LOW;
4.启用IM并设置优先级:
ALTER TABLE oe.product_information INMEMORY PRIORITY HIGH;
5.启用IM并同时设置压缩级别和优先级:
ALTER TABLE oe.product_information INMEMORY
MEMCOMPRESS FOR CAPACITY HIGH
PRIORITY LOW;
6.对表中部分列组合启用IM,并设置压缩级别:

注:可以查看v$im_column_level视图来了解列的压缩级别。
7.关闭IM:
ALTER TABLE oe.product_information NO INMEMORY;
再注:对于列,无法设置单独的优先级,只能对表,或者表分区设置。
又注:可以通过查看v$im_segments来了解哪些对象已经被缓存到了IM中。
与表空间相关的几个IM的例子:
1.在创建表空间时启用IM:
CREATE TABLESPACE tbs1
DATAFILE 'tbs1.dbf' SIZE 40M
ONLINE
DEFAULT INMEMORY;
注:因为我们没有指定该表空间的压缩级别及优先级,所以其默认值为MEMCOMPRESS FOR QUERY, 以及 PRIORITY NONE。
2.使用alter命令修改表空间的IM选项设置:
ALTER TABLESPACE tbs1 DEFAULT INMEMORY
MEMCOMPRESS FOR CAPACITY HIGH
PRIORITY LOW;
与物化视图相关的IM的几个例子:
1.创建物化视图时启用IM:
CREATE MATERIALIZED VIEW oe.prod_info_mv INMEMORY
AS SELECT * FROM oe.product_information;
注:此时的压缩级别及优先级设置,与上面表空间的默认设置一样。
2.创建后修改IM设置:
ALTER MATERIALIZED VIEW oe.prod_info_mv INMEMORY PRIORITY HIGH;
Data Pump中的im应用:
在impdp对象的时候,可以指定如下选项
TRANSFORM=INMEMORY:y 保留导出对象的IM设置
TRANSFORM=INMEMORY:n 不保留导出对象的IM设置
TRANSFORM=INMEMORY_CLAUSE:string 在导入时重新设置导出时的IM设置
当然,你也可以在EM中使用IM,详情可参见:
https://docs.oracle.com/database/121/ADMIN/memory.htm#ADMIN14309
12c中,与IM相关的数据字典表,我特意去查了下官方文档,无论是cdb,dba,all还是user打头的,基本都没有相关的内容。于是我搜了下v$开头的视图,查询结果如下:

这其中,V$IM_COLUMN_LEVEL和V$IM_SEGMENTS两个在前面已经涉及到过。我们这里统一把这些视图说一下:
V$INMEMORY_AREA:启用IM的对象所占用的内存空间。查询该视图,你就会知道,IM用于存储对象的内存区域,分为两个部分,一个以1M为分配单位,用于存储列数据,另外一个以64K为分配单位,用于存储对象的元数据(metadata)和事务日志(transaction journal)。
来看例子:

V$IM_COLUMN_LEVEL:用于记录列的压缩级别。
V$IM_COL_CU:记录IMCU中基于列的统计信息。
V$IM_HEADER:记录IM区对象所分配IMCU的详细信息。
V$IM_SEGMENTS:记录存储在IM中的段的属性。
V$IM_SEGMENTS_DETAIL:记录存储在IM中的段的详细属性(至于详细到什么程度,各位去对比这两个视图的列名即可。
V$IM_SEG_EXT_MAP:记录IM区对象的所有区间映射关系。
V$IM_SMU_CHUNK:记录IM中对象的元数据的块信息。
V$IM_SMU_HEAD:记录IM中对象的元数据的头信息。
V$IM_TBS_EXT_MAP:记录IM区1M子池对象的区间映射关系。
V$IM_USER_SEGMENTS:记录当前用户下IM段对象的存储属性。
*IMCU 是In Memory Compression Units
是数据在内存中分配的块的大小,比较类似于数据库中extent的概念。后台进程ora_w00*在装载数据时,会分配自己的IMCU,并将分配给该进程的数据加载到该IMCU中。此后,当访问IM区中的列数据时,我们在统计信息中看到的consistent gets值也就是统计所访问IMCU的个数和所需访问metadata块的个数之和。特定对象所分配IMCU的详细信息,可从视图V_$IM_HEADER中查询。而其metadata块的信息可从视图V_$IM_SMU_CHUNK和V_$IM_SMU_HEAD查询。
在In Memory内部,以IMCU为单位,Oracle维护了一个In Memory Storage Index,记录IMCU单元中该列的最大值,最小值。此外,Oracle也会在metadata区为每个IMCU建立相应的metadata dictionary, metadata信息中会有一些列的统计信息。视图V_$IM_COL_CU可以帮助查询这些metadata dictionary信息。
十一.与IM相关的等待事件
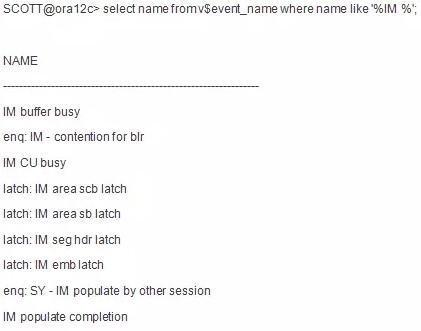
十二. 与IM相关的统计信息

Oracle官方文档中IMO相关内容(https://docs.oracle.com/database/121/ADMIN/memory.htm#ADMIN14257)
作者介绍:史跃东
TJOUG发起人,Oracle 10g/11g OCM。
超过九年的数据库、数据仓库及相关行业经历。
目前从事oracle数据库培训行业。专注于Oracle、MySQL技术,也进行大数据,云计算等相关技术的研究。
小编精心为大家挑选了近日最受欢迎的几篇热文↓↓↓
(关注订阅号dbaplus,回复以下数字,即可获取相应文章)
回复001,看陈爱珍《从文艺女到技术咖,一位美女工程师的华丽转身》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复003,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复004,看陈科《memcached&redis等分布式缓存的实现原理》;
回复005,看陆传胜《听阿里巴巴JVM工程师为你分析常见Java故障案例》;
回复006,看郑晓辉《存储和数据库不得不说的故事》;
回复007,看袁伟翔《揭秘Oracle数据库truncate原理》;
回复008,看OpenSkill陈荣华《时下最火搜索引擎:ElasticSearch详解与优化设计》;
回复009,看丁启良《LINUX类主机JAVA应用程序占用CPU、内存过高分析手段》;
回复010,看周李洋《面对Schema free的MongoDB,如何规范你的schema》。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721