

转载声明:本文为DBA+社群原创文章,转载必须连同本订阅号二维码全文转载,并注明作者名字及来源:DBA+社群(dbaplus)。
目录
问题解决过程
反思总结
ORACLE的RAC数据库集群现在已经被广泛应用,最近在数据集市项目中将原来AIX平台10G单节点数据库迁移升级至X86平台11R2RAC集群数据库,为了保证数据库的高可用性和可扩展性,采用了RAC的GRID大集群和数据库小集群方式(例如本次问题的环境是4节点ASM集群支撑2套2节点RAC数据库,每个实例1台主机)。部署好第一套2节点RAC数据库之后,因项目进展的需要,再添加2节点给另一个地市使用。在将GRID和DB集群软件、数据库都创建完成之后,同事告诉我新添加的2节点RAC数据库不能用SQLPLUS正常启动,必须使用集群命令启动。凭着以往的经验,RAC节点的数据库无论是用SQLPLUS还是集群命令都必须可以在任意节点进行任意顺序启动,不需要按照特定的顺序启动。
现在这套RAC节点数据库还在安装阶段,还没有投入使用,因此可以进行各种各样的操作和测试。接到这个问题请求之后,首先进行测试,按照同事的说法,先启动1节点,后启动2节点,数据库可以使用SQLPLUS正常启动;先启动2节点,后启动1节点,发现2节点可以正常启动,1节点连NOMOUNT状态都未能进入,就报错退出。退出之后,就查看数据库的ALERT日志,发现在退出前报错集群无法进行通信。
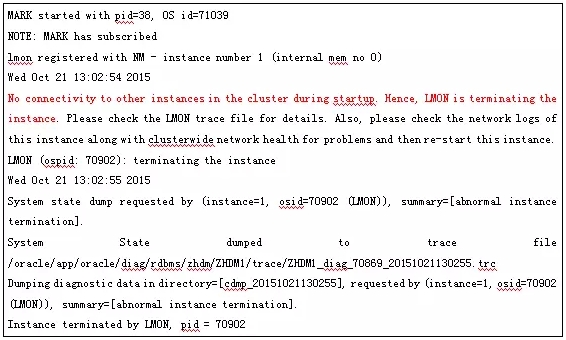
根据报错信息分析,是由于集群间无法通信,导致数据库无法启动,那么根据这一点提示信息就拼命的从集群通信方面入手。因为这2个节点是后期采用添加节点的方式添加进去,第一怀疑是不是添加节点加出了问题,反复询问同事,明确回复我在添加节点时无任何的报错信息。那么就只能从使用集群命令对整个集群进行检查。使用了crsctl status resource –t ,crsctl check cluster –all,oifcfg,olsnodes,srvctl等命令进行检查,检查的结果都无异议,从中未能发现一点蛛丝马迹。

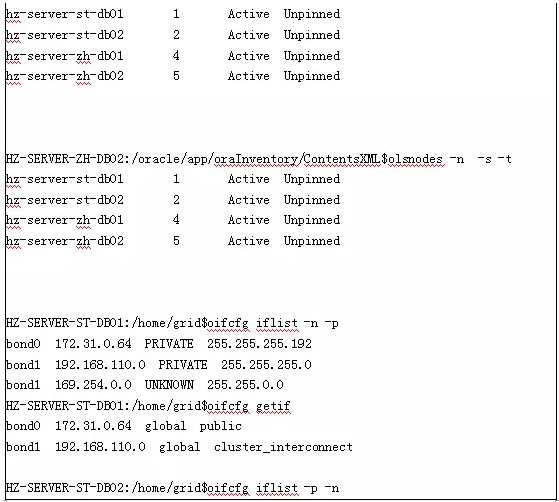
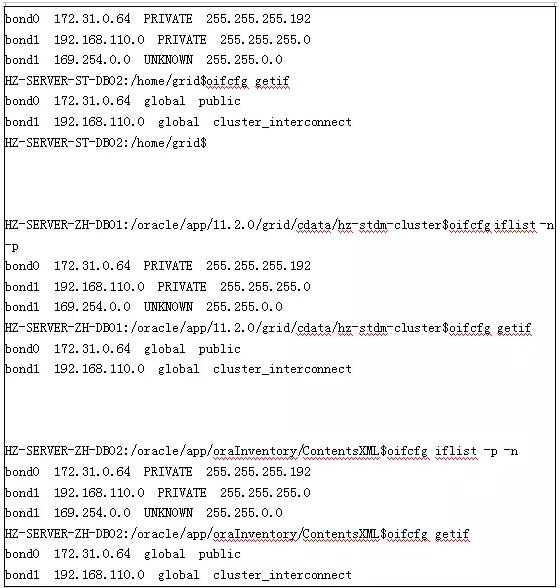
再仔细对1节点的数据库ALERT日志向上查看,发现有打印私网通信地址为169.254.183.196,立即查看数据库的私网通信地址发现是192.168.110.12。此时就有一个疑问,数据库ALERT日志中打印的私网IP地址与规划的私网IP不一致。这个时候只好外事不决问百度,问了百度之后发现是ORACLE在11.2.0.2.0之后添加的新特性HAIP。

又因为项目赶进度,所以在内部进行商讨,看看有无遇到相似或相同的案例,结果听同事说过,他们遇到过,也是相同的问题,但没有找到根本原因。后续申请协调各种资源进行分析 ,终于有了进一步的发现。发现在2节点使用SQLPLUS启库时,ALERT日志中打印的集群IP有问题,集群间通信应该使用私网,怎么使用SQPLUS启库打印为公网IP,这点就特别疑惑了。

172.31.0.116这个IP在此套RAC数据库中定义为公网IP,那么这个问题就初步归结为2节点使用SQLPLUS启库会使用公网IP作为集群的通信网络。又再次对集群的公网、私网等网络进行核查和分析,并协调网络厂家、操作系统厂家进行核查,都没有发现问题。
到这里之后,几乎是山穷水尽,问题依然存在。再次百度,得到的答案是由于HAIP异常引起。于是分别独立启动单节点库,查看其对就的HAIP,发现1节点为169.254.183.196,2节点为172.31.0.116。

再次对2个节点的数据库ALERT日志进行对比,发现其中存在一些不同的报错信息。1节点独立启库,能够正常获取公网、私网的IP信息。2节点则提示GPNP异常,未能获取正常的私网、公网信息。后续紧接着查看GPNP的日志,发现GPNP在正常工作,未有任何的报错信息。

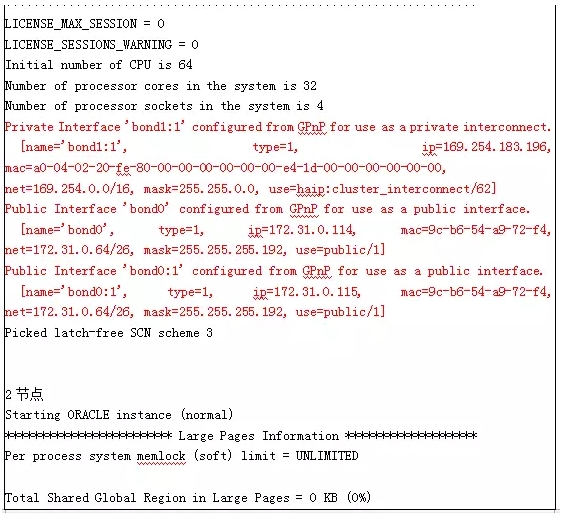

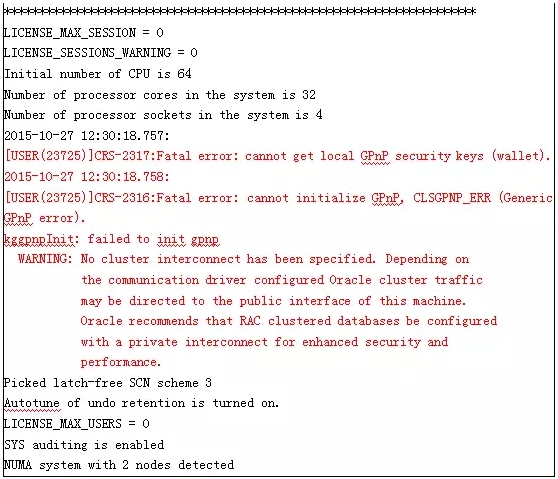
于是到这里,突然灵光一闪,是不是可以用TRACE的方法跟踪启动过程,能否从TRACE中分析出2节点为什么使用公网IP做为集群通信。由于是启库,只能重新启动2节点至NOMOUNT状态,然后创建PFILE,在PFILE中添加10046事件,然后使用PFILE启动数据库至NOMOUNT状态。然后到TRACE目录中去查看TRACE文件。对TRACE文件打开分析,发现TRACE文件中提示GPNP中某个文件无法访问。
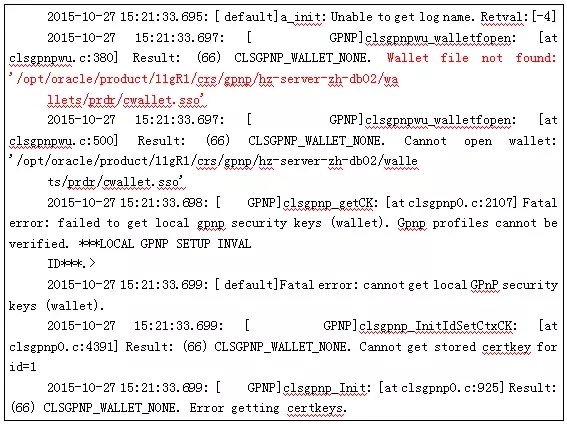
使用LS命令对文件进行查看,发现的确不存该文件,再仔细一看路径,这个路径不是GRID集群的安装路径。

仔细一看这个目录,再结合操作系统为SUSE LINUX 11 SP2,初步确定为ORACLE用户的环境变量问题。如果对2个节点ORACLE的环境变量进行对比,果然不同,2节点多了2行。

看到2节点多出来的2个环境变更ORA_CRS_HOME、ORA_ASM_HOME,立即找到SUSE LINUX为ORACLE特意准备的环境变量文件/etc/profile.d/oracle.sh,立即将这个文件重命名,然后退出会话,重新登陆,环境变量消失。于是使用2个会话窗口,1个查看数据库ALERT日志,另1个使用SQLPLUS启库,ALERT日志中显示数据库正常能够获取私网、公网的IP网络,而且HAIP也是使用169网段的。待2节点使用SQLPLUS启库完成之后,再在1节点使用SQLPLUS启库,一切正常。然后再核查其他3个节点的/etc/profile.d/oracle.sh发现该文件要么被删除、要么被重命名。
至此为止,经过不断的折腾,这个问题终于被解决,但是回想整个解决过程,其实很冗长,也走了很多的弯路。
检查数据库ALERT日志,只检查出问题节点,没有立即检查未出问题节点。
未对操作系统及其对应的环境变量熟悉,其实/etc/profile.d/oracle.sh是SUSE专门为ORACLE定制的环境变量,加上这是第1次使用SUSE安装ORACLE数据库,经验不足,也是其一。
其实也曾想过是不是配置有问题,引起此次问题。在其中曾让当初部署的同事按照ORACLE的官方文档对操作系统配置进行一遍彻底的核查。但也未能核查出隐藏在/etc/profile.d/oracle.sh这个环境变量文件。这也正是SUSE为ORACLE定制的特色。
作者介绍:夏海雁
新炬网络公司高级技术专家,7年Oracle数据库、TimesTen内存数据库运维管理经验。
精通Oracle 10g、11g数据库管理和Linux/Unix系统管理。
擅长进行数据库及集群的故障诊断与系统优化,并持续专注于故障诊断技术的研究与实践。
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复013,看吕海波《去不去O,谁说了算?》;
回复014,看黎君原《扒一扒Oracle数据库迁移中的各种坑》;
回复015,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复016,看陈能技《基于Docker的开发模式驱动持续集成落地实施》;
回复017,看朱贤文《数据库与存储系统》;
回复018,看楼方鑫《数据库中间层,这样定制可能更好》;
回复019,看王佩《基于Docker的mysql mha 的集群环境构建实践》;
回复020,看王津银《互联网运维的整体理念与最佳实践》
DBA+社群是中国最大的涵盖各种架构师、数据库、中间件的微信社群!线上分享2次/周、线下沙龙1次/月,顶级峰会6次/年,直接受众10000+,间接影响50万+ITer。DBA+社群致力于搭建一个学习交流、专业人脉、跨界合作的公益平台,更多精彩请持续关注dbaplus微信订阅号!

扫码关注
DBAplus社群
超越DBA圈子,连接的不仅仅是DBA








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721