








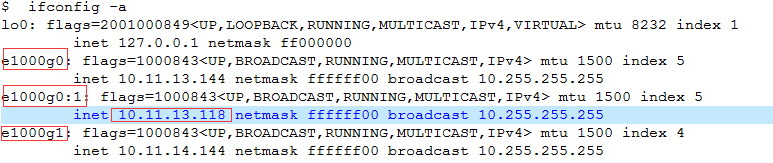

其实问题的原因也无须掉书袋,经过快速定位和分析,就是因为这样的DB link,听起来好像也不大合理,怎么会有这样的问题呢,问题服务器上存在着大量的数据库连接,会直接更新本地表,间接通过db link来引用其他的表,在业务稳定的时候没有差别,在一定程度上和设置的逻辑IP有一些关系,网络一旦发生抖动和不稳定,就会把这个网络的延迟放大,传播,大批量的会话开始阻塞,等待,就会变成活跃会话,数据库负载急剧提升,如果应用端持续调用都存在等待,系统资源就会逐渐耗尽,导致出现无响应的情况,这种问题的解决方案目前是采用了折中的一个方案,既然通过db link,我们把一部分的网络压力放在物理网卡2上。在tnsnames.ora中修改对应的IP和端口即可。至少在一定程度上能够极大缓解问题,后续会建议从应用层面,系统层面来持续改进。
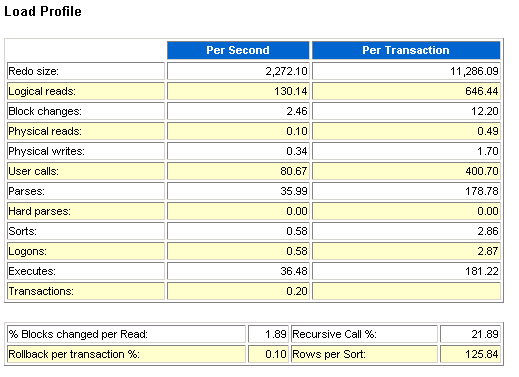
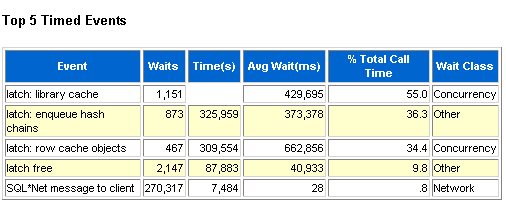
当然处理问题的过程中,发现有大量的等待,首要的等待就是library cache的争用,这个可以从下面的图示看出。可以看到shared pool确实很紧张,而且同时buffer cache其实使用一点都不紧张,我们重置一下SGA的组件,这个地方需要提醒一下,在这种情况下需要评估影响范围。

我印象中是存在一个bug,会导致实例直接宕掉,评估了之后决定先改进一下。alter system set shared_pool=xxx运行下去,实例还真宕掉了。
<span color:black;"="" style="word-wrap: break-word; font-size: 10pt;">Errors in file /U03/app/oracle/admin/test/bdump/test_mman_944.trc:
ORA-00600: internal error code, arguments: [kmgs_pre_process_request_6], [1], [107], [18], [3], [0xA7024DB68], [], []
Mon Oct 3 22:45:17 2016
MMAN: terminating instance due to error 822


