
本文根据DBAplus社群第91期线上分享整理而成。

李旦
京东监控系统资深工程师
曾任职于富士通、中兴通讯
目前负责设计开发京东MDC系统和弹性集群监控告警服务
拥有丰富的容器监控系统设计研发经验
大家好,我是来自京东商城-基础平台-集群技术部的李旦,目前主要参与负责京东统一监控平台的设计研发,以及弹性集群的建设工作。这次分享的主题是:大规模集群(物理机&容器)环境下,监控系统的设计与实践经验。
主题简介:
一、MDC架构设计详解
二、海量监控实践
这次分享主要包含两部分内容,第一是对京东监控系统MDC的架构设计做一个简单介绍,第二是分享一下我们在实践过程中遇到的问题以及总结的经验。
MDC架构设计详解

先简单介绍一下MDC系统,MDC系统由京东自主研发,对下针对物理机、容器的基础资源使用情况,以及业务常用组件的性能实施监控;对上为用户提供高效的监控数据服务和告警服务。
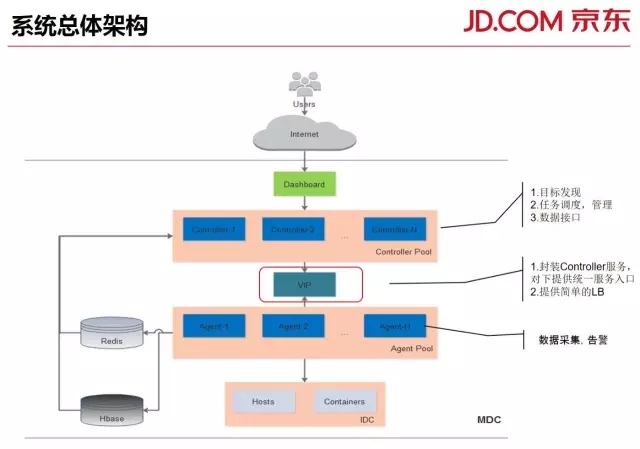
系统的总体架构很简单,功能划分得也很清晰,将采集与任务管理解耦。任务可以无状态地在Agent间迁移,方便横向扩展。
主要分为三部分:
Dashboard,Web-UI。
Controller,控制器。对内负责采集资源的管理和采集任务的调度,对外提供丰富的数据获取,报表生成接口。
Agent,采集器。实际的数据采集,告警执行者。
另外,我们在Controller上挂了一层VIP,把Controller服务整体封装成统一入口,可以方便采集服务(Agent)发现的实现和对外接口调用。
这里的Agent是一个逻辑上的概念,实际包含采集、告警、数据处理等多个模块。
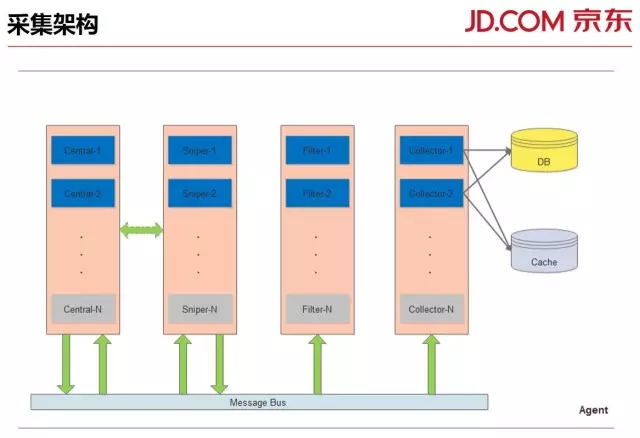
这是Agent内部的架构,这里列出了主要的四个部件,它们之间通过消息队列相互通信。
按消息流向来看,Central负责采集任务的处理,并把任务下发到Sniper。
Sniper功能划分得很简单,它只用来做数据采集,没有掺杂其他业务逻辑,这样能在一定程度上保证采集效率不受干扰。
Sniper在采集完成后,通过消息队列将采集到的数据返回到Central中,Central在对数据处理完成后,将其发送到Filter和Collector的队列中。
Filter负责过滤数据,进行告警。Collector进行数据处理聚合,然后将数据放入缓存,存储。

采集Sniper,用插件的方式实现不同采集类型的灵活加载。
目前通过SNMP+IPMI,采集物理机的资源使用情况和一些硬件信息。
容器采集的实现,是在宿主机上部署DockerPull采集代理,对外暴露RESTful Api,Sniper通过RESTful Api通用插件获取其数据。

告警设置包含三部分,用户组、告警组和资源组。支持多级别、多阈值、多间隔、多种通知途径的规则设置,最大程度的方便用户订制告警。
海量监控实践
从前面的运营数据可以看出,MDC系统承载监控目标的量还是很大的,而且增速较快。所以在设计之初,我们就确定了几个设计目标:高性能、低开销、高扩展、高可用。接下来分享我们在这些方面的一些实践。

MDC的数据采集采用了“pull”的模式:通过SNMP和IPMI协议获取物理机的监控信息,通过在目标节点上部署Agent,获取容器的监控信息。
实践中遇到的性能问题,只要集中在物理机的数据采集上:
首先是SNMP采集的优化。由于我们开发用的Python语言,在做SNMP处理时,自然而然地找到了Pysnmp这个pure-Python的SNMP实现。但是在测试时发现,Pysnmp这个库可能是由于Python本身并发限制的问题,效率并不能满足我们的要求。解决思路就是底层采集使用C或者其他更高效的实现来做,我们对比选择了Netsnmp这个C的SNMP实现。通过测试,发现Netsnmp在并发处理时,效率远高于Pysnmp。
其次是IPMI采集的优化。IPMI可能是由于协议本身或者BMC芯片采集效率的问题(具体不明),导致数据返回缓慢(分钟级)。IPMI的采集效率问题无法从源头解决,所以我们在实现中做了一些实时性方面的妥协,解决思路就是在IPMI的采集模块中加入缓存,缓存会被定时刷新,同时接受到IPMI采集请求时,会立即返回缓存中的数据。
然后是慢采集的优化。由于网络,目标机性能等原因,会出现一些采集较慢的目标机。这些慢采集我们做了两层处理,首先是在采集任务内,将慢采集做自适应降级处理,这样既能保证慢采集目标的数据可用性,又不会影响采集任务内其他目标机的采集。其次在采集任务间,如果慢采集影响了任务的整体性能,会通过将任务做拆分,迁移处理来保证任务整体的采集效率。
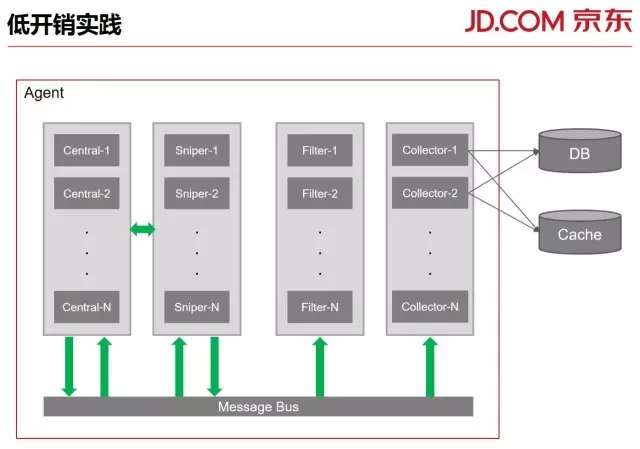
低开销是我们监控系统设计的另外一个原则,就是尽量降低监控系统本身对生产环境资源的损耗。我们把各个组件(Central、Sniper、Filter、Collector)和它们之间交互所需要的消息中间件(RabbitMQ)打包成一个逻辑上的Agent部署在一台物理机或者容器上。
这样做有两个好处,一个是避免了大规模集群环境下,RabbitMQ的性能瓶颈问题。另外一个,除了采集和存储时产生的必要的网络流量,组件之间的数据交互都在机器内部进行,不会流向机器外部,对网络做成额外压力。

主要从三个层面做了高可用的处理:进程存活、服务存活、采集业务存活:
进程存活,保证相关进程存活,进程挂掉时自动重启;
服务存活,保证服务整体可用,部分服务挂掉不影响整体可用行;
采集业务存活,保证采集任务不丢失。
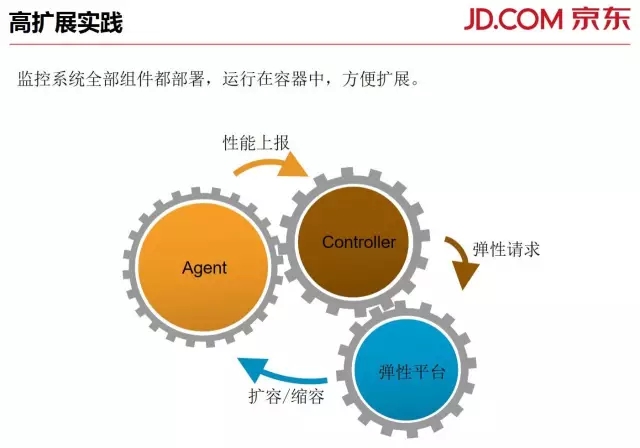
我们把Controller、Agent打包部署在Docker容器中,依托于弹性集群平台,实现自动扩容缩容。
Agent定期向Controller上报自身性能数据,Controller根据设定的阈值,对Agent总体进行统筹规划,调用弹性平台的接口实现扩容缩容。
Q1:如果有新增容器,Agent是手动部署上吗?每个容器上应该都有对应的线上业务,这个Agent是怎么做版本更新的呢?
A1:有容器的发现机制,可以把容器信息自动导入系统中, 然后生成新的采集任务,或者合并到其他采集任务中,由空闲Agent接管。Agent更新我们用Ansible做了一套独立的升级工具。
Q2:消息中间件RabbitMQ有没有进行二次开发?小弟最近遇到一个问题,消费端的ack如果在传输过程中丢失,服务就不再向此消费者发送待消费消息,不知道有没有好的方案解决这个问题?
A2:RabbitMQ我们用的官方原版,没有做二次开发,因为之前使用中也遇到过一些问题。所以我们把Rabbit的两端都圈定在同一机器中,这样能大概率避免一些问题。不过这种做法可能只适用于我们的应用场景,没有普适性。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721