
本期要闻:从DB-Engines近几年的趋势看数据库的变革;Oracle 12cR2发布部分版本;MySQL 5.7.17 GR发布;PostgreSQL将发布10.0;MongoDB 3.4通过行业最严格的分布式数据库测试;Redis最新漏洞和修复……更多资讯请阅读全文。
一、推出DBAplus Newsletter的想法
二、DB-Engines数据库排行榜
三、从DB-Engines近几年的趋势看数据库的变革
四、RDBMS家族
Oracle 12c Release 2率先发布Exadata,SuperCluster版本
Oracle 12c Release 2特性解读(点击下载查看)
MySQL 5.7.17 Group Replication发布
MySQL 5.7新特性解读(点击下载查看)
SQL Server Linux版涨势迅猛
PostgreSQL将发布10.0
DB2 For LUW发布11.1 Mod1 Fix pack1 版本
Greenplum补丁版本发布,Gemfire-Greenplum connector发布
MariaDB ColumnStore发布
五、NoSQL家族
MongoDB 3.4通过行业最严格的分布式数据库测试
Redis最新漏洞和修复
HBase 1.3.0版本发布
Apache Geode 1.1.0版本更新
ClickHouse新秀登场
六、NewSQL家族
TiDB近期发布RC2版本
RethinkDB “死而复生”
七、大数据生态圈
Hadoop发布3.0.0 Alpha 2版本
GPText发布
HAWQ 2.1.1.0版本发布
八、国产数据库概览
GBase UP发布
巨杉数据库SequoiaDB 2.6社区版发布
达梦DM V7.1.5.145发布
OceanBase 1.0版本可申请邀测试用
九、活动预告:MongoDB线下活动
十、感谢名单
温馨提示
为方便阅读,自本期起,Newsletter对RDBMS、NoSQL、NewSQL、大数据、虚拟化、国产数据库等五个板块的内容进行精简,重点呈现,需阅读全文的童鞋可到DBAplus公众号后台回复“newsletter”至社群订阅号下载完整版。
DBAplus Newsletter的主要目的就是向广大技术爱好者提供数据库行业内的一些技术发展趋势,为社区的技术发展提供一个统一的发声平台。为此我们策划了RDBMS、NoSQL、NewSQL、大数据、虚拟化、国产数据库等几个板块。
我们不以商业宣传为目的,不接受任何商业广告宣传,严格审查信息源的可信度和准确性,力争为大家提供一个纯净的技术学习环境,欢迎大家监督指正。
至于Newsletter的发布周期,目前的计划是每两个月左右会做一次跟进,下一期计划时间是2017年4月10日-20日,如果有相关的信息提供请发送至邮箱newsletter@dbaplus.cn。
以下取自2017年2月的数据,具体信息可以参考 http://db-engines.com/en/ranking/,数据仅供参考。
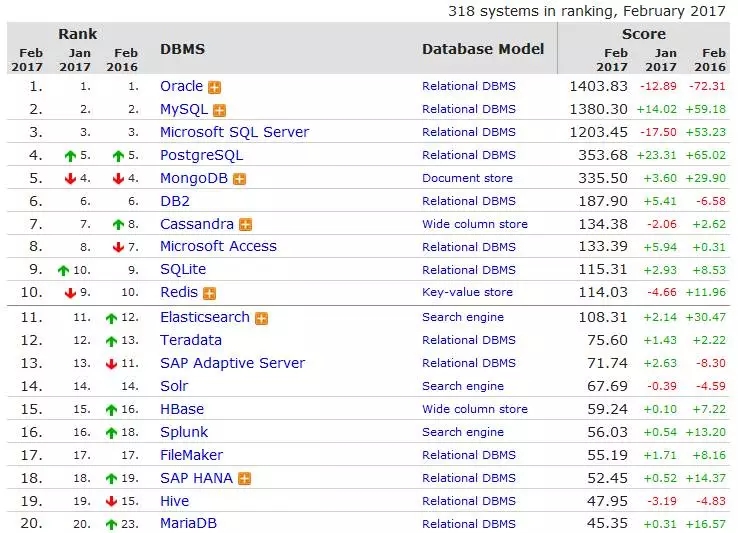
从DB-Engines近几年的趋势看数据库的变革
DB-Engines 是一个中立的数据库流行程度的排行榜,采用的指标包括全网的关键字提及度,Google Trends,Stackoverflow 上的问题和讨论数量,相关的工作职位数量,Twitter 中的关键字提及程度等。基本上不会带有评分者的个人感情色彩,不过由于语言和技术社区的原因,可能不能反映国内的情况,不过总体来说,是一个比较中立的排行系统。其中有个 Trend chart 的功能能看到选定数据库近几年的趋势。
我们先来看看近几年几个最流行的数据库,想必大家也非常熟悉了:Oracle 、MySQL、SQLServer、PostgreSQL。
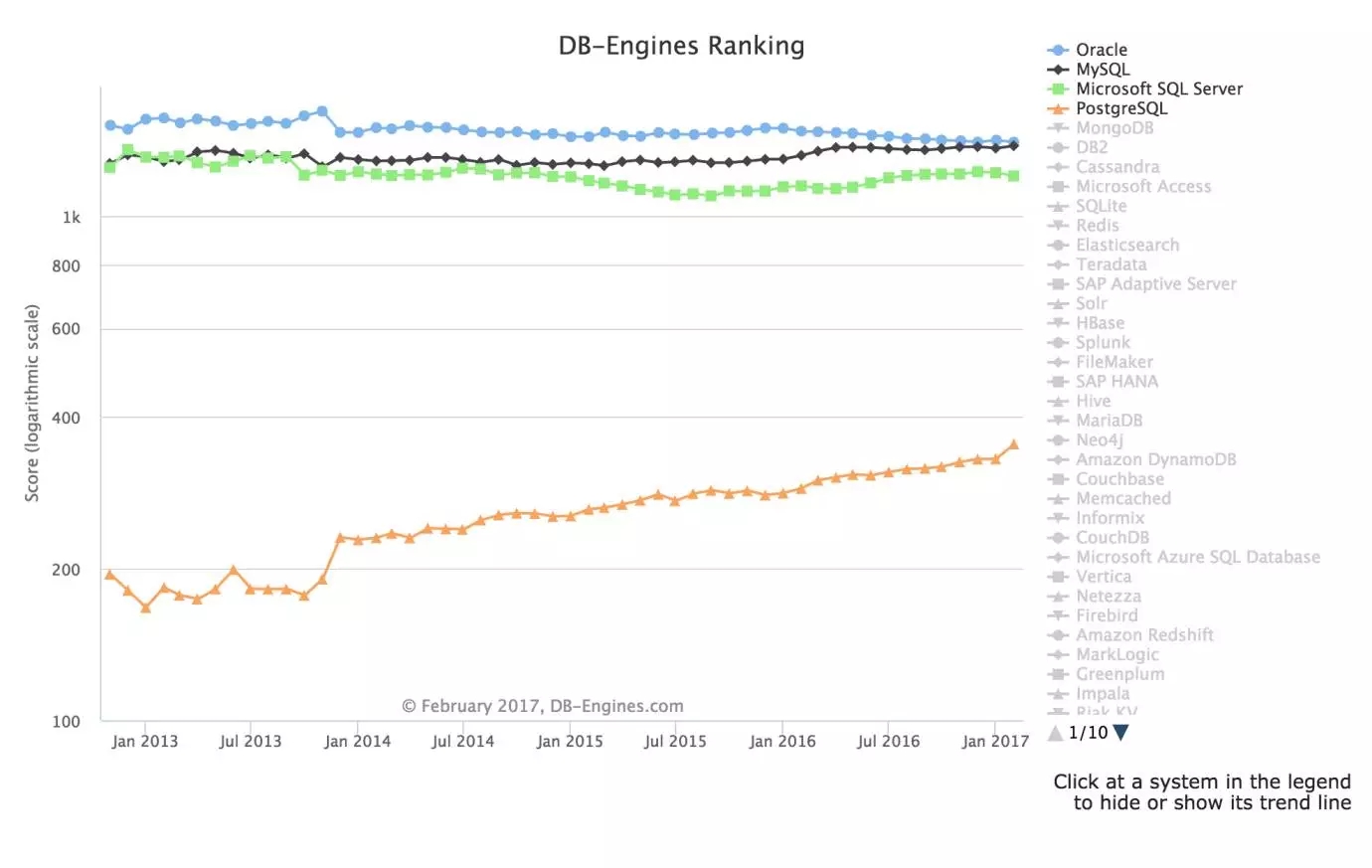
值得注意的是,纵轴的评分,是按照对数作为阶(logarithm scale)的,其实这么看上去第一集团还是 Oracle / MySQL / SQLServer,PG 在快速追赶中,目前离第一集团大概还有 3~4 倍左右的差距,但 PG 作为这几个老牌数据库中斜率比较大的,大概在 2013 年年底有一个跳变,看时间点应该是 PG 9.3 的发布,随后 PG 一直保持了非常稳健的向上发展趋势,这个表现非常符合最近几年 PostgreSQL 社区的快速发展,从 9.0 到去年的 9.6,PG 面向传统企业、互联网、金融、物联网、政企等行业发布了诸多特性,在 SQL 兼容性与时俱进,贴近最新发布的 SQL 标准,从社区发布的性能测试来看,单机 TPS 达到了 180 万的水准。PostgreSQL 正在以自己的方式构建一个庞大的生态体系。这个数据也是比较符合直观感受的。

单独放大一下MySQL和Oracle的趋势,这两个全球最流行的数据库,就有意思了。近两年Oracle在DB-Engines排名上一直在走下坡路,而MySQL一直在稳步的上升,看趋势应该在2017年Q2会迎来交点。
虽然不能代表Oracle不行了,因为Oracle目前仍然是全球企业级数据库市场的王者,但不可否认的是, MySQL近几年在社区的声音几年越来越大:从5.7开始性能和稳定性稳步提升,feature 方面,比如5.7开始支持的JSON built-in functions,到正在Alpha的X-plugin中的 document store 的支持,从最近大热的Group Replication到MyRocks这样更多样的存储引擎。
另外基于MySQL生态的商业公司也越来越多,比如Percona、MariaDB等,生态做得一直蒸蒸日上。反之Oracle在社区发声相比起来就少得多,虽然这么比较可能不太公平,毕竟 MySQL 是个开源数据库,另外这可能也是商业策略的一种(毕竟MySQL严格来说也是O家的)。但长期来看不管是DBA的培养,开发者的培养,MySQL庞大的社区基础是其发展的后劲所在,而且MySQL的野心一定不只于一个简单的RDBMS,从Document store这样的动作来看,应该也是感觉到了MongoDB等NoSQL的压力,希望能扩大自己的版图。
总体来说,我是非常看好MySQL的,庞大的用户基础+开发者社区+Oracle的技术团队,未来一定会更好。

NoSQL也是近几年不可忽视的一股力量,MongoDB从数据和排名上来看,一路领先,而且斜率看上去也很不错,毕竟文档的访问接口 MongoDB 的 Schema-less 的特性确实补足了RDBMS在灵活性上的一些短板。
另外,HBase / C* 这类的NoSQL其实在扩展性和数据量比较大的场景会比 MongoDB 更加合适。但可能是从关注度上来看和 RDBMS 还有距离,应该是由于大多数用户的场景用单机数据库就能搞定吧。
值得注意的是,各类开源的 NoSQL 在 2013 年底和 2014 年初有一次分值的跳涨,具体发生了什么事情?可能是 Hadoop 的版本发布?可能是某些大公司公布了使用案例?我似乎已经回忆不起来了,不过那时确实是 NoSQL 发展的黄金时期。
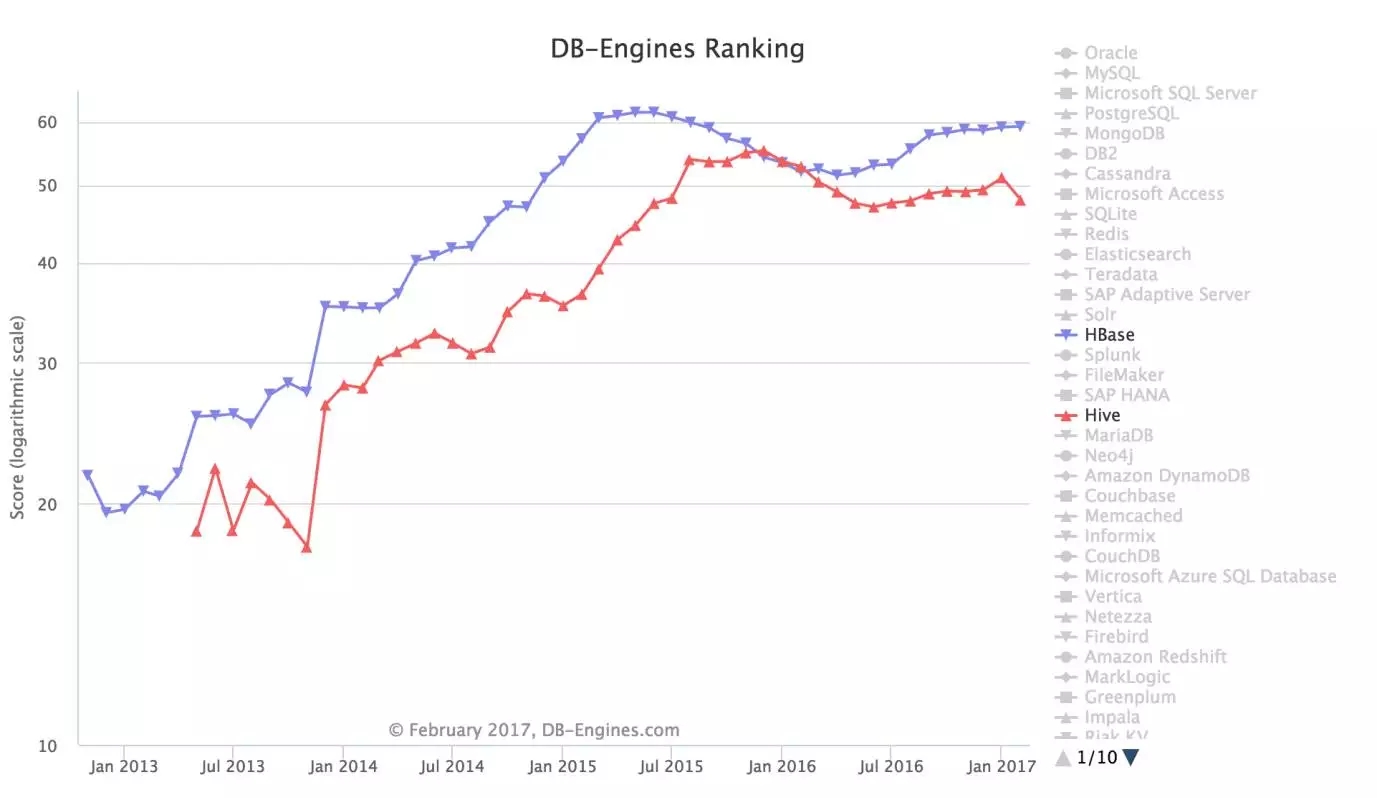
单独看HBase和Hive这两个Hadoop家族的数据库,在经历了从13年到16年初的快速增长后,这两年增长有些乏力,可能是因为大数据存储和分析Hadoop 已经并不是唯一的选择。
从数据库这边来看,从Mongo,C* 到最近的 TiDB/TiKV,都在分食HBase的市场,作为TiDB的维护者,我看到从HBase迁移过来的用户多是因为HBase缺乏足够强大的SQL支持和二级索引等功能。另外,在分析引擎上,过去几乎是唯一选择的Hive也受到SparkSQL、Impala、Presto等新兴查询引擎的挑战。
我认为Hadoop生态目前最坚固的一块磐石是HDFS,如果以后有更好的方案能够兼容Hadoop接口的话,可能Hadoop的地位也会因此受到挑战。
当然,这些粗浅的分析仅仅是通过DB-Engines的趋势做出的解读,现在没有,以后也应该不会有银弹,不会有一个完美的数据库能够解决一切的数据存储问题。只有根据自己的业务特点,选择合适的数据库产品才是正道。
Oracle 12c Release 2率先发布Exadata,SuperCluster版本
12c最期待人心的就是12c Release 2的发布了,近期Oracle更新了MOS文档742060.1,明确指出会在2017年3月15日发布Linux和Solaris的数据库版本。
并在2017年2月14日官方持续更新了文档,Exadata和SuperCluster版本已经率先发布,感兴趣的同学可以尝试下载试用。
对于Oracle新特性的解读,可以点击“阅读原文”下载本期Newsletter完整文档查看,内容由韩锋老师提供。
2016年12月26日MySQL 5.7.17版本发布了 Group Repplication,这是一种基于官方版本通过插件实现复制技术,满足多主写入,更高可用性和容错机制,性能测试结果如下:
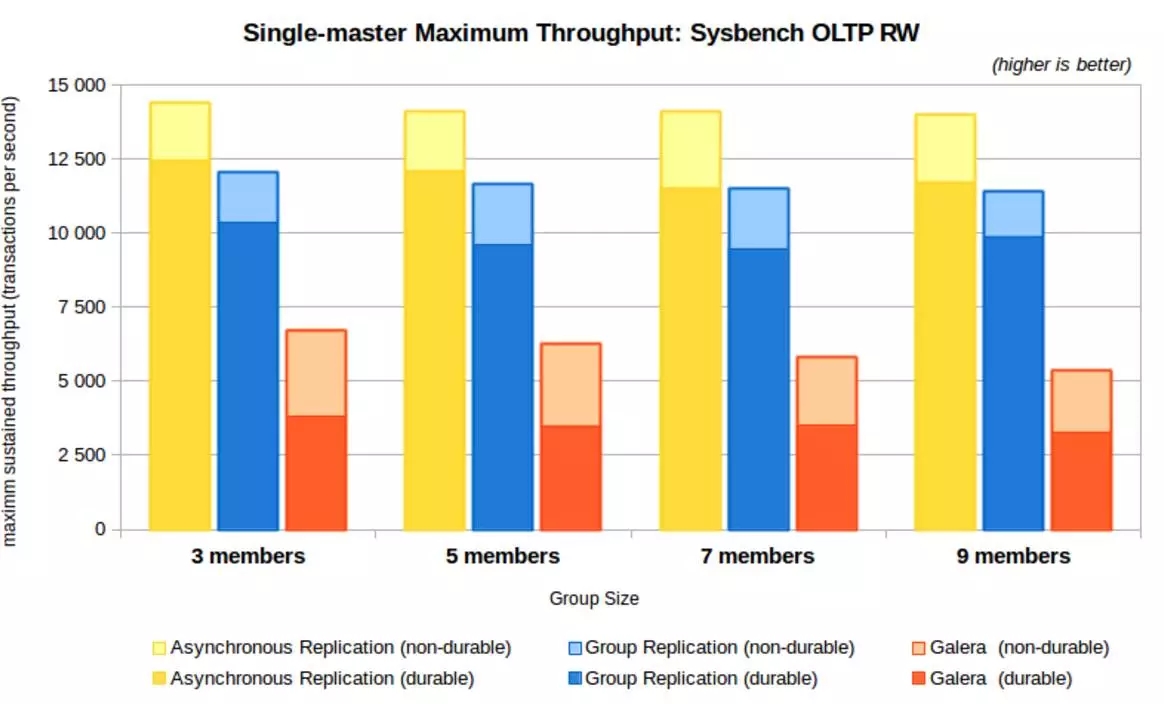
从性能测试结果看,性能还是优于Galera的,接近异步同步。
综合来看,Group Replication可以解决目前MySQL异步复制的众多问题,未来也会有很大的发展。但是目前在运维方面的支持上不够好,比如备份和集群客户端支持上,离实际生产环境大规模应用还是有一段距离。
对于MySQL 5.7的特性解读,可以点击“阅读原文”下载本期Newsletter完整文档查看,内容由杨奇龙老师提供。
微软去年推出了Linux版的SQL Server 2016,这让很多Linux用户都非常高兴,直接促使SQL Server全球份额猛增76.89%(从2016年1月至2017年1月)。处于全球份额第二位的MySQL也上涨了67.03%,只是排在首位的Oracle降幅较为明显,下降了79.36%。
虽然SQL Server目前仍处于第三的位置,但由于涨势迅猛不容小觑。份额的上涨很大程度上归功于微软对于Linux平台的发力。
SQL Server 的前两个版本主要是通过提供新特性提高性能,而 SQL Server 2016 主要是改进本身已有的功能。
PostgreSQL 将发布10.0
PostgreSQL近几年的发展有目共睹,从GIS到物联网、流式计算、多维分析、高并发在线事务处理、服务端编程、任意数据类型的抽象处理、扩展索引方法、GPU运算能力的利用等各个方面体现了PostgreSQL的强大功能和性能。从dbranking的分值也可以看出,PostgreSQL毫无疑问是2016年度发展最快的数据库。
2016年发布的PostgreSQL 9.6新特性还历历在目,比如多核并行计算、针对流式数据的块级索引、同步多副本等等。2017年将要发布10.0,会有更多特性值得期待。
随着PostgreSQL在向量化运算、列存储、动态编译等极致优化的领域的新动作呢,AWS、阿里云等众多云厂商在这个领域也将有新的布局。
DB2 For LUW发布11.1 Mod1 Fix pack1版本
2016年12月15日 DB2 For LUW发布11.1 Mod1 Fix pack1版本,在列式存储方面进行增强。主要在性能提升(概要表特性)及可管理部分(工作负载部分)进行较大改善。
2016年12月,Gemfire-Greenplum connector正式发布,Gemfire-Greenplum connector为Greenplum和Gemfire之间数据的同步和更新提供了便捷而高效的方式,让Gemfire支持的快数据和Greenplum支持的大数据融为一体,也让OLTP应用和OLAP应用有机结合起来。
更多信息请访问官方文档 http://ggc.docs.pivotal.io/。
2017年1月,Greenplum补丁版本4.3.11.1、4.3.11.2和4.3.11.3发布,包含了很多优化和改进。
MariaDB ColumnStore是在MariaDB 10.1基础上移植了InfiniDB 4.6.2构建的大规模并行、高性能、压缩的分布式开源列式存储引擎,类似收费产品Infobrigt。它设计用于大数据离线分析,用来抗衡Hadoop 。官方自称MariaDB ColumnStore是数据仓库的未来,ColumnStore允许存储更多的数据并更快地分析它。
你可以使用标准SQL语句进行查询,支持目前流行的sqlyog/navicat客户端工具连接,对业务方使用没有任何的不便,并且你不需要创建任何索引,不需要修改业务方的复杂SQL(自身就支持复杂的关联查询、聚合、存储过程和用户定义的函数),你唯一要做的就是把数据导入到ColumnStore里,就没你事了。这对一家没有Hadoop工程师的公司来说,MariaDB ColumnStore会是一个更好的替代产品。
MongoDB 3.4 通过行业最严格的分布式数据库测试 - Jepsen 测试
2017年2月7日,Kyle Kingsbury,著名的Jepsen测试的作者,发布了他在MongoDB 3.4版本上做的最新一轮测试。他的结论是:
“MongoDB在最近两年投入大量资源来持续提高其数据安全标准,他们的投入在3.2和3.4版本里已经有了显著的成绩。”
“MongoDB 3.4.1(以及目前的开发版本3.5.1)目前通过了所有Jepsen的测试场景……在网络中断、服务器被隔离和时钟被篡改的情况下, 这些测试结果仍然成立。”
从2013年起,Jepsen已俨然成为行业中一个最为严格的分布式系统测试工具。这个测试结果的发布非常有意义,特别是对国内用户。网上有不少关于数据安全性方面有误导性的文章,这个测试结果可以给Mongo 用户带来不少信心。
根据Jepsen的测试结果,在为MongoDB配置了最高安全级别的读选项和写选项,以及使用默认的复制协议的情况下,MongoDB 3.4表现出了最高级别的数据一致性、准确性和安全性,哪怕是在最极端的错误情况下。
在2015年12月份时, Redis爆出了一个可以利用漏洞获取Redis服务器的root权限,此漏洞暴出来后,Redis作者Antirez表示将会开发“real user”,区分普通用户和admin用户权限,普通用户将会被禁止运行某些命令,如config。事隔一年之后,近期又有网友暴漏了Redis的CSRF漏洞, 不过,这次好在Redis作者在最新发布的3.2.7已经进行了修复,解决方案是对于POST和Host:的关键字进行特殊处理记录日志并断开该链接避免后续Redis合法请求的执行。(bug fixed)
1、Redis流量统计问题以及修复:
由阿里云的同学提交patch修复(相关说明:
https://m.aliyun.com/yunqi/articles/69502?spm=5176.8091938.0.0.xVGKVf )
bug fixed:https://github.com/antirez/redis/pull/3802/files
2、Redis4.2 roadmap也已经推出:
https://gist.github.com/antirez/a3787d538eec3db381a41654e214b31d
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google Bigtable的开源实现, HBase利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为作为协同服务。
Apache HBase于美国时间2017年1月17日发布1.3.0版本,HBase 1.3.0是HBase 1.X版本线中的第三次小版本变更,在该版本中修复了1700多个issues。
Apache Geode 1.1.0版本修改了252个bug,增强了持续集成的测试框架,改善了安全框架相关的实现。主要体现在JsonFormatter功能增强和增加了C/C++本地客户端这两方面。
Yandex在2016年6月15日开源了一个数据分析的数据库,名字叫做ClickHouse。
这个列式存储数据库的跑分要超过很多流行的商业MPP数据库软件,例如Vertica。
它最大的应用来自于Yandex的统计分析服务Yandex.Metrica,每天支持200亿的事件和历史总记录超过13万亿条记录,这些记录都存有原始数据(非聚合数据),随时可以使用SQL查询和分析,生成用户报告。据称Yandex.Metrica为世界上第二大的网站分析平台。
TiDB 近期发布RC2版本
TiDB 是基于Google Spanner & F1实现的分布式NewSQL数据库,目标定位支持100% 的OLTP + 80%的OLAP,除了底层的RocksDB存储引擎之外,分布式SQL解析层、分布式KV存储引擎(TiKV)完全自主设计和研发。
TiDB 是开源且网络接口和语法MySQL兼容的,可以简单理解为一个可以无限水平扩展的MySQL,提供分布式事务、跨节点 JOIN、保证跨数据中心的数据的强一致性(ACID 跨行事务支持)、故障自恢复的高可用,提供更快的查询和写入吞吐;对业务没有任何侵入性,简化开发,利于维护和平滑迁移。
本月底,TiDB 将正式发布 RC2 版
更进一步文档请阅读:https://github.com/pingcap/docs-cn
RethinkDB的开发工作始于2009年7月份,用C++、JavaScript和Bash编写。它采用AGPL开源许可证来发布。最后一个稳定版本是2016年5月2日发布的版本2.3.2。
于2016年10月5日,RethinkDB联合创始人在官网上宣布RethinkDB破产倒闭。其自称已经尽了最大的努力,最终还是无法建立一个可持续的商业模式。该公司关闭后,RethinkDB团队随之搬家,工程团队会加入Stripe Inc.,而Stripe是完全成熟的软件平台和工具包,面向在线支付。
近期RethinkDB项目有了新的动态。Cloud Native Computing基金会(CNCF)宣布它购买了NoSQL分布式文件存储数据库RethinkDB的源代码版权,将授权协议从Affero GPLv3改为Apache v2,并将其捐赠给Linux基金会。
在Linux基金会的支持下,该项目从此有了强大的制度支持及接受捐赠的能力。
Apache于2017年1月20日,发布了Hadoop 3.0.0 Alpha 2版本,此版本是Hadoop 3.0.0的第二个测试版本,相比Alpha 1的测试版本来说,没有太大的变更,仅仅修复了上个版本中的一些BUG和改进了一些功能。
GPText 是Pivotal公司自主研发的内置Greenplum数据库的全文检索和文本分析引擎。具有易用性、分布式、高可用、可扩展、易维护、模块可定制化等特性。对大数据中非结构化的数据检索能提供毫秒级的响应,同时所支持的全文检索种类和语法非常丰富。
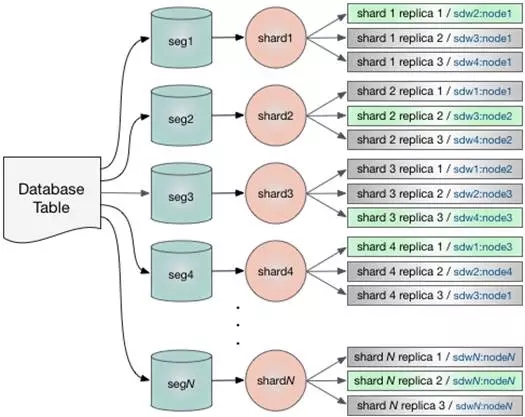
索引数据分布式存放在索引节点上,并复制拷贝提高高可用性。数据索引和检索都通过Greenplum segment 服务器并行实现,支持通用的search,词(term) 相关search,facet聚合search等常见的全文检索场景。
HDB (Apache HAWQ) 2.1.1.0 版本发布
Pivotal HDB 2.1.1.0企业版于2016年12月正式发布,用户可以通过PXF中的HiveORC Profile来访问Hive中存储的ORC格式数据,并且支持投影下推和谓词下推,大大提升了ORC外部表访问的性能。
Apache HAWQ 2.1.0.0已进入投票阶段并即将发布,其中提供了大量的错误修正和改进,包括的模块有:查询优化器,查询执行器,资源管理器,系统容错,内部存储,PXF,管理工具,编译打包等。具体参考780个JIRA:
https://issues.apache.org/jira/secure/ReleaseNote.jspa?projectId=12318826&version=12338900
GBase UP 发布
南大通用统一数据平台系统,简称:GBase UP,它是融合了GBase 8a MPP、GBase 8t、开源Hadoop生态系统的大数据平台产品,兼顾大规模分布式并行数据库集群系统、稳定高效的事务数据库,以及Hadoop生态系统的多种大规模结构化与非结构化数据处理技术,能够适应OLAP、OLTP和NOSQL三种计算模型的业务场景,是构建企业数据平台的重要基础设施。
GBase UP以成熟的GBase 8a MPP商用数据库为基础,扩展出针对Hive & Spark、HBase、GBase 8t的计算和存储引擎,建立引擎之间高效数据交换通道,构建了对外统一,对内可扩展的集群数据库产品。
SequoiaDB巨杉数据库,结合Spark大数据技术,能够满足近线数据服务平台端到端的搭建工作。SequoiaDB提供的分布式框架满足分布式、高可用、高性能、易维护等特性,同时其多维分区、灵活索引、双引擎内核、以及标准SQL支持等特性为企业级近线数据服务平台奠定了最佳的数据存储与计算基础。
SequoiaDB 2.6 社区版已经正式发布,为SequoiaDB 2.0之后首个社区版本,增加更多新功能,欢迎前往下载试用和吐槽。
达梦DM V7.1.5.145发布
达梦数据库管理系统是达梦公司推出的具有完全自主知识产权的高性能数据库管理系统,简称DM。目前产品的最新版本是达梦数据库管理系统7.0版本,简称DM7。
DM7是达梦公司在总结DM系列产品研发与应用经验的基础之上,吸收主流数据库产品的优点,采用类Java的虚拟机技术设计的新一代数据库产品。DM7基于成熟的关系数据模型和标准的接口,是一个跨越多种软硬件平台、具有大数据管理与分析能力、高效稳定的数据库管理系统。目前官网最新的可下载版本是V7.1.5.145。
OceanBase 1.0版本可申请邀测试用
OceanBase是由阿里巴巴/蚂蚁金服集团自主研发的面向云时代的分布式关系数据库,具有可扩展、高可用、高性价比、兼容MySQL语法和协议等核心技术优势。
OceanBase从2010年开始起步,经过六年多的发展,目前产品已经成功应用于蚂蚁金服的交易、支付、账务等核心系统和网商银行等业务系统。2016年双11,支付宝创造了17.5万笔/秒交易峰值和12万笔/秒支付峰值这一业内全新的世界纪录,这其中每一笔订单背后的数据和事务处理,都由OceanBase完成。除了服务阿里巴巴/蚂蚁金服,OceanBase还通过阿里云平台,开始输出到金融、电信、政府、制造等各行各业。

OceanBase 1.0版本已经可以在阿里云官网上可以申请邀测进行试用。
登陆云盘:http://pan.baidu.com/s/1bo2n21p 可下载本期Newsletter完整版。
想快人一步了解更多行业最新动态,除了等下期DBAplus Newsletter出炉以外,还可以参加以下活动:
给DBAplus社群的技术合作社区MongoDB中文社区剧透一下今年的技术活动计划。MongoDB中文社区(mongoing.com)成立于2014年,是大中华区唯一获得官方认可的中文社区。经过志愿者不断的努力,目前已有超过一万的线上线下成员。
2017年社区将持续开启专属于MongoDB的技术交流会,活动贯穿全年,分别于三月杭州、四月深圳、五月北京、六月成都、七月广州、八月台北、九月上海举办线下沙龙,并于十一月举办年终盛典。想报名参与的小伙伴可关注MongoDB中文社区即将发布的具体活动安排。
最后,感谢那些提供宝贵信息和建议的专家朋友,排名不分先后。
上期回顾:《DBAplus Newsletter:这也许是最全的技术圈动态解读》








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721