
在数据库调优过程中,SQL语句往往是导致性能问题的主要原因,而执行计划则是解释SQL语句执行过程的语言,只有充分读懂执行计划才能在数据库性能优化中做到游刃有余。
常见的关系型数据库中,虽然执行计划的表示方法各自不同,但执行原理却大同小异。在我看来,SQL语句的执行过程中总共包含两个关键环节:
读取数据的方式(scan):包含表扫描和索引扫描
表之间如何进行连接(join):包含Nest Loop 、Merge Join、Hash
join及半连接等、多表间的连接顺序选择
只要掌握这两个关键环节,我们就可以迅速识别SQL语句在当前数据库中的执行逻辑,发现执行计划中存在的问题及隐患。由于不同数据库之间对于执行计划的表示方法各不相同。对于DB2数据库,很多人并不能理解执行计划所表达的含义,接下来我们就通过实际案例详细探讨DB2数据库中执行计划的各个要点。
01
读取数据的方式
谈到读取数据就离不开数据库中的物理对象:表及索引。因此谈到数据读取的方式,只需理解表扫描及索引扫描,就能基本把握数据的来源。
02
全表扫描
在DB2 LUW中可以通过四种方式获取语句的执行计划(db2expln工具),虽然工具不同,但展示的内容基本相似,最大的区别就是详细程度。详细程度由大到小排序分别是:。为了方便展示,我们在这里只讨论通过db2expln所展示的执行计划信息。首先我们来看一个db2expln抓取的完整的执行计划。
db2expln展示的信息总共分为三部分,分别是当前SQL 语句,执行计划详细信息及执行计划图示(需添加-g参数才能展示),第一部分是当前采集执行计划的语句(见图1-1):
图1-1
这部分内容基本一目了然,需要注意的就是里面:HV … :HI… 的信息是DB2将参数改写的信息(基本可以忽略)。
接下来我们来看最关键的部分,执行计划的详细信息(见图1-2):

这部分首先包括当前环境的字符集(codepage),下面是根据统计信息评估出的成本及返回行数。在这个例子中执行成本为124470,返回行数为1行。从第6行开始的位置内容比较重要,我们采取逐行解释:


第三部分为执行计划图,我们可以通过执行计划图快速直接地看出SQL语句的执行过程,执行计划图的阅读顺序是从下往上,从左往右,按照编号从大到小的顺序进行阅读。比如在这个例子中,首先看第三步,显示对表进行表扫描操作(TBSCAN),然后对扫描的结果进行group by操作并将最终结果返回,这条SQL语句就执行完毕了。

03
索引扫描
接下来来看个索引扫描的例子,为了快速理解这个执行计划,我们直接先看执行计划图,可以看到这个SQL语句首先读取索引,获取RID后到表里获取其他数据,进行group by后将结果返回。
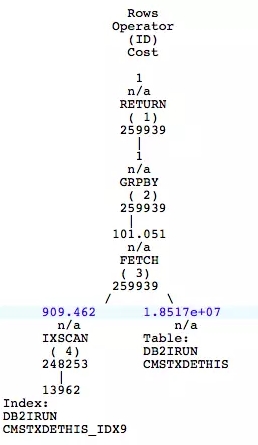
其他部分和上一个例子差不多,就不一一详细介绍了,主要看索引扫描的相关细节。从下面的信息可以看出用到的索引中包含4个字段,但这条SQL只用到了一个字段。其他三个字段都没用使用。如果该表上有其他索引包含这条SQL所使用的更多的字段时,这个索引肯定不是最佳选择。

数据读取的方式还有更多的细节,这里暂时不一一讨论了,但不论对数据采用何种方式读取,最核心的内容还是数据从哪里读取,简单来说就是有没有更好的索引可以替代当前的扫描策略,所以,当我们对SQL语句进行优化时,第一步就是需要考虑当前的读取方式是否足够有效。
04
表连接的方式
接下来我们来谈表之间的连接,写过SQL的童鞋都知道,写SQL时Join方式可以有很多种情况:inner join,left join,right join,full join等,还包括一些子查询,比如exist 或者In等方式。对于星型查询,DB2 10以后还支持ZZJOIN。
05
Nest Loop(NLJOIN)
Nest Loop是最简单的一种连接方式,数据库会根据表中的记录数选择内表及外表,在定义内外表后,首先会对外表进行全表扫描,然后重复扫描内表并与外表中的每一条记录进行匹配,最终返回程序所需的结果集。

因此NLJOIN的总成本大约为外表扫描的成本+外表返回的行数×内表扫描的成本。NLJOIN作为使用场景最多的连接方式,当外表匹配行数较少或内外表行数差距较大时效率较高,但也正因为NLJOIN的运行方式,也经常会发生性能隐患。
06
Merge Join(MSJOIN)
合并连接是为了解决Nest Loop中存在的一些问题所采用的一种连接方式,MSJOIN会将需要连接的两张表进行排序,并将排序后的结果集按照交叉方式匹配,最终返回连接后的结果。
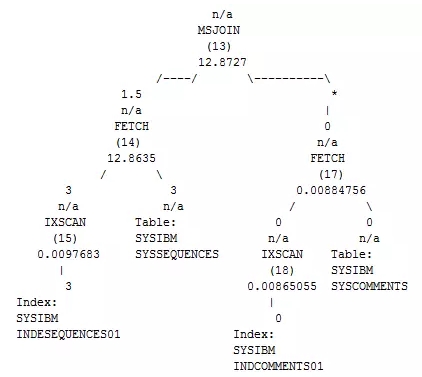
MSJOIN的总成本大约为单次外表扫描的成本+单次内表扫描的成本+排序成本。MSJOIN常见的场景通常是SQL需要返回排序结果,亦或者主外表都比较大的情况,此外MSJOIN只能应用于SQL语句中包含唯一连接谓词的情况,当主外表数量级都比较大,且连接谓词上都存在索引时,MSJOIN的效率较高(避免了排序成本),通常MSJOIN比较稳定,即使统计信息估算错误,也不会导致执行效率出现较大的偏差。
07
Hash join(HSJOIN)
HSJOIN是一种比较高级的连接方式,进行连接前首先会将外表根据连接谓词进行哈希产生哈希表,然后将哈希表与内表进行连接并返回结果。与MSJOIN类似,HSJOIN也只对内外表分别进行一次扫描,同时HSJOIN也支持多连接谓词。在两张大表通过多连接谓词进行连接时效率很高。
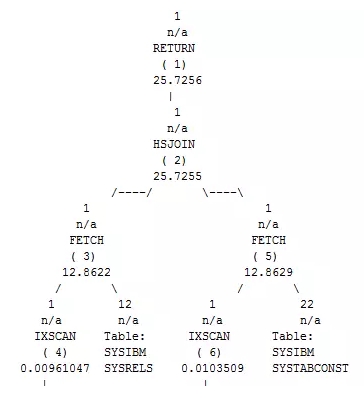
HSJOIN的扫描成本约为内表扫描成本+外表扫描成本。但需要注意的是,生成的哈希表会存放在排序堆中,一旦排序堆内存溢出,会额外产生大量的物理IO,这点需要特别注意。
08
半连接(semi-join)
半连接属于一种比较奇怪的连接方式,在很多资料里并没有将其划分到连接方式中,因为有的时候,从执行计划中根本看不到连接操作符,比如下面这个SQL:
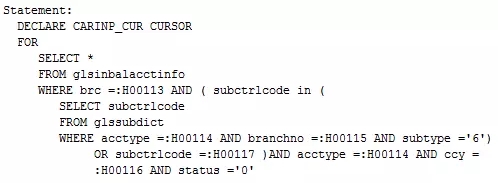
这是一个典型的子查询,我们可以从SQL语句中猜出大概逻辑,首先会读取子查询中的表,然后根据返回的内容与外部表进行匹配并返回结果。但从执行计划图中并不能看到任何关于连接的信息。

执行计划图中并没有显示任何join的信息,只是多个对象进行了fetch,但从文字描述中可以看到更详细的内容。
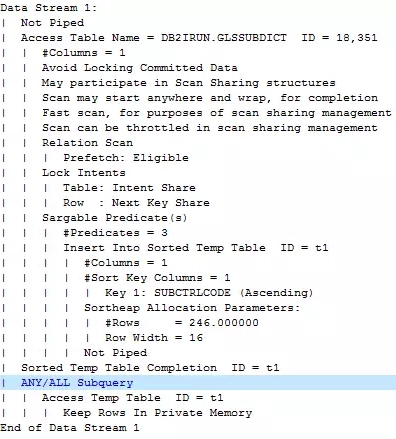
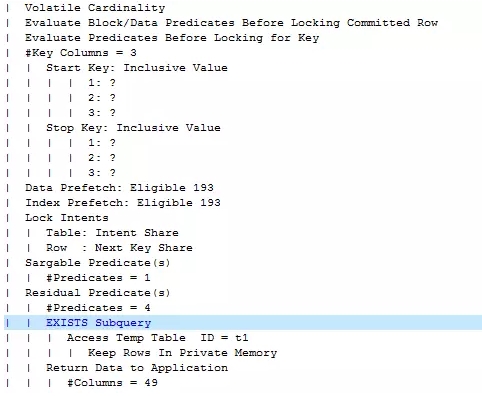
数据流1首先会对内部表进行全表扫描(ANY/ALLSubquery),读取后的结果与外部表进行匹配,匹配到结果后不继续扫描立刻返回结果(EXISTS Subquery)。
09
多表间的连接顺序选择
不论在同一条SQL语句中包含了多少张表连接,在同一时刻只有两张表进行连接,但多表间的连接顺序也是决定性能的主要原因。数据库对于表的顺序的选择,往往根据两个表之间连接后得出的行数进行排序,如果统计信息与实际情况偏差较大,有可能会导致由于连接顺序不当而导致的性能问题。
10
总结
通过对执行计划的解析,我们讲解了SQL执行过程中对于性能影响较大的各个要点,但如何在生产上保持SQL的高效稳定,还需对执行计划进行更深入的理解。下面就这方面解答一些同学们常见的疑问:
Q1:在查询时,有一个驱动表,通常是from后的第一个表,后面一堆左连接右连接,这个驱动表如何选择?对性能有影响么?自己人为该顺序不会影响执行计划?
A1:在数据库中,会根据当前表的情况进行内外表的选择,SQL语句中的写法只能从一定程度上决定连接次序,但不会做连接中内外表的决策。
举个例子,select*from a,(select*from b,c where b.id=c.id)where……,比如这个SQL,在写法中指明了需要先将b c表连接,再与a表连接,但在连接时候的方式以及连接时候内表外表的选择,都由数据库决定。
Q2:关于连接方式的选择,是由连接的两个表和连接的字段是否排序决定的?
A2:这个不绝对,但是会作为选择的因素之一。
Q4:访问某表的access plan改变了,统计信息没变,是什么情况?这是优化器自动调整了吗?可是优化器根据统计信息生成访问计划,按道理应该是不会变的啊?
A4:执行计划的选择会根据数据库参数,统计信息作为参考,但在编译过程中数据库还会收集一些物理信息。比如数据的物理分布可能会对扫描的方式产生影响。
Q5:这个物理信息是什么,是表空间信息吗?
A5:表在物理中存放的情况。
Q6:有什么手段跟踪一个SQL完整的执行过程,包括你说的动态收集物理信息?
A6:可以抓trace或者stack。db2trc,和db2pd –stack。
Q7:老师,db2的优化器是对越复杂的sql支持的越好吗?有这个说法吗?
A7:db2的优化器对复杂SQL的支持在关系型数据库里应该是最好的,但是对于联机交易系统来讲,我觉得SQL的稳定性比较重要。但复杂SQL牵扯到的变化因素太多,任何一个表的统计信息改变都有可能导致SQL性能下降,所以在联机交易系统不太推荐写复杂SQL。
Q8:那我们写sql时该怎么注意呢?NL join类似笛卡尔集,时间复杂度最高,其次是merge。我觉得从sql上避免不了,因为选择了那个列,就基本确定了连接类型。
A8:在编写SQL的时候很难决定用什么连接方式,但有些需要注意的地方,比如避免多张大表连接,这些在开发过程中还是可以办到的。
Q9:hash连接,如果探测表很大,内建表很小,hash的成本显示很高,因为探测表做了表扫描,没有用到索引,这种如何优化,只能减少探测表的返回集吗?
A9:可以在探测表上创建适当索引。
Q10:对表做完统计更新后需要做rbind吗?
A10:这个需要取决于你的应用是静态SQL还是动态SQL。静态SQL的话执行计划在bind的时候保持在数据库中,统计信息更新后建议rebind,但动态的就没必要了。
Q11:通常谓词出现在索引的第一个字段应该就是有效索引,可有时候这个索引存在,但是个复合索引,跑db2advis时却建议在这个谓词上创建新的单一的索引,为什么数据库不用现有的复合?
A11:复合索引并不一定高效,这个需要根据数据分布来判断,如果单一索引的Clusterration非常好(也就是和表存放的顺序匹配度非常高),这样可以用到大量预取操作,性能会比同步读好很多。
Q12:嵌入式C、C++、COBOL的包BND(包括静态SQL),要绑, 用户SP也建议绑定吧?
A12:UDI的成本其实很大程度上和表设计有关。比如在做DML语句的时候发生行溢出和页重组,带来的消耗远大于插入索引。相关信息可以看db2pd -tcb或者snapshot for table。
Q13:请问一下对于表压缩有什么建议?比如要做大表的压缩,有没有一些量化指标供参考,因为有一些表开了压缩批次插入较多记录时候影延长了批次1/3的时间。
A13:对于压缩,需要分析当前数据库的瓶颈在哪。压缩是以cpu为代价降低磁盘io,如果瓶颈在磁盘io上,肯定会有帮助,但如果瓶颈在cpu上只会雪上加霜。
Q14:调整APPENDON呢?有没有量化的一些指标?
A14:这个不是很好量化。对于磁盘io瓶颈,可以先从索引,语句甚至表设计入手。如果都已经调整到很好了但还是存在iO瓶颈,同时CPU使用率又比较低(30-40以下)。可以考虑压缩。
作者介绍:洪烨
【DBA+社群】数据库专家。
曾在IBM担任数据库现场技术支持,为北京移动、北京联通、中国银联、中国银行、中信银行、联想集团、国家气象局、中华联合保险、唐山商业银行等多家企业进行DB2故障诊断、技术支持以及技术培训工作,拥有DB2开发、高级管理以及AIX管理等多项国际认证。
擅长DB2数据库及相关产品的性能调优及故障分析,对DB2技能及实践经验有多年积累。著有《让db2跑得更快》一书。
全球敏捷运维峰会【杭州站】

2016 年4月16日,与你相约杭州,来一场敏捷与运维的美丽邂逅!DBA+社群联合三墩IT人开启全球敏捷运维峰会第一站:杭州站!峰会力邀来自互联网与传统企 业的资深专家,各路大咖齐聚,汇聚500+行业精英,聚焦架构、敏捷、运维三大主线,开启一场专属于IT人的年度之约!
专家阵容:或行业资深派、或著书力作派、或传统转型派、或一线实战派,总有一款是你喜欢!
绝对干货:聚焦架构、敏捷、运维三大主线,共讨传统企业在技术转型过程中的实践与困境、互联网企业在前沿技术方面的应用与心得、技术服务型企业在新老技术之间如何切换与落地,拒绝无营养的广告,绝对干货,精彩不容错过!
连接联动:汇聚社群数百顶级专家人脉,携数万社群成员声势,联合数十家媒体单位,共同打造一场连接敏捷与运维圈子的年度之约!
门票:免费!(限额)
VIP票:199元(限3月20日前)







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721