
作者介绍
蒋健,云趣网络科技联合创始人,11g OCM,多年Oracle设计、管理及实施经验,精通数据库优化,Oracle CBO及并行原理,曾为多个行业的客户的Oracle系统实施小型机到X86跨平台迁移和数据库优化服务。云趣鹰眼监控核心设计和开发者,资深Python Web开发者。
某客户反馈生产库ETL及报表类SQL全部运行不出来,监控告警近期大量SQL语句执行计划发生变更。客户DBA通过对比新旧执行计划发现执行计划变更的SQL大部分都变成了走索引加上NL的方式,而且不止一个SQL出现这种问题,该生产库上几乎所有的AP类型SQL都出现了该问题。问题到我们这边前,客户已经花了数周时间做了好几轮排查,均没有效果。
全库统计信息排查
DBA排查过历史的统计信息,并重新收集了对应schema的统计信息,重新收集相关表、索引的直方图统计信息,部分SQL增加了多列统计信息。每次操作完成后的验证均无效果,之后回退了以上无效操作。
绑定部分SQL执行计划
部分业务过于紧急,约10条SQL临时使用SQLPROFILE绑定了执行计划,针对绑定的SQL有效,然而执行计划发生变更SQL语句数量过多,针对每个SQL分析执行计划并绑定,这完全不现实。
参数排查
排查了系统参数optimizer_index_*相关参数,均为默认值,优化器模式为默认ALL_ROWS,db_file_multiblock_read_count参数设置128,参数无异常变更,后检查包括触发器层面、进程级别,均为无异常参数调整。
由于客户生产上的案例文章中不方便使用真实数据,模拟了以下数据:
create user test identified by test;
grant dba to test;
conn test/test
create table t1 as select * from dba_objects;
create index test.idx1 on test.t1(OBJECT_ID);
execute dbms_stats.gather_table_stats(ownname => 'TEST',tabname => 'T1' ,cascade => true,method_opt => 'for all columns size auto');
update test.t1 set OBJECT_ID=1 where rownum <40000;
commit;
查询数据如下,T1表上有8.7W数据:
SQL>
select count(*) from test.t1 SQL> ;
COUNT(*)
----------
87629
简单模拟的SQL如下,查询OBJECT_ID=1的数据,数据量有4W,差不多一半的数据量,正常情况肯定走全表了,实际情况却走索引。
SQL> set autot trace
alter system flush shared_pool;
select * from test.t1 t where OBJECT_ID=1;SQL>
System altered.
SQL>
39999 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 1483979983
--------------------------------------------------------------------------------
----
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time
|
--------------------------------------------------------------------------------
----
| 0 | SELECT STATEMENT | | 38294 | 3627K| 747 (2)| 00:00:
01 |
| 1 | TABLE ACCESS BY INDEX ROWID| T1 | 38294 | 3627K| 747 (2)| 00:00:
01 |
|* 2 | INDEX RANGE SCAN | IDX1 | 38294 | | 112 (4)| 00:00:
01 |
--------------------------------------------------------------------------------
----
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("OBJECT_ID"=1)
Statistics
----------------------------------------------------------
133 recursive calls
0 db block gets
6227 consistent gets
0 physical reads
0 redo size
4468586 bytes sent via SQL*Net to client
29845 bytes received via SQL*Net from client
2668 SQL*Net roundtrips to/from client
27 sorts (memory)
0 sorts (disk)
39999 rows processed
真实情况中,客户发来了监视报告,10053trace文件,SQLT报告。因为监视报告这里用处不大,没做模拟。
10053trace信息
参数方面确认没什么问题跳过,快速定位到单表访问路径那部分,如下所示,单表路径选择的时候对比了访问索引(cost :746.93),以及访问全表的方式(cost :10050.77),(注:这里人为造出来的数据cost值差异较大,真实场景中相差不是特别大)那么问题在于为什么会有这么大的差异,Card: 38294.13,即预估返回结果集38294,对比实际值39999,可以发现统计信息这块儿,基本准确。
SINGLE TABLE ACCESS PATH
Single Table Cardinality Estimation for T1[T]
Column (#4):
NewDensity:0.000012, OldDensity:0.000012 BktCnt:254, PopBktCnt:111, PopValCnt:1, NDV:47788
Column (#4): OBJECT_ID(
AvgLen: 5 NDV: 47788 Nulls: 1 Density: 0.000012 Min: 1 Max: 190751
Histogram: HtBal #Bkts: 254 UncompBkts: 254 EndPtVals: 144
Table: T1 Alias: T
Card: Original: 87629.000000 Rounded: 38294 Computed: 38294.13 Non Adjusted: 38294.13
Access Path: TableScan
Cost: 10050.77 Resp: 10050.77 Degree: 0
Cost_io: 10033.00 Cost_cpu: 40345028
Resp_io: 10033.00 Resp_cpu: 40345028
Access Path: index (AllEqRange)
Index: IDX1
resc_io: 734.00 resc_cpu: 29353837
ix_sel: 0.437008 ix_sel_with_filters: 0.437008
Cost: 746.93 Resp: 746.93 Degree: 1
Best:: AccessPath: IndexRange
Index: IDX1
Cost: 746.93 Degree: 1 Resp: 746.93 Card: 38294.13 Bytes: 0
线索到这里时,同事考虑到全表扫描COST值基本来源于IO,冒出一个大胆的想法:是否可能数据块儿碎片严重化,极端情况下比如所有不需要的数据分布为每条数据均存于不同的块儿中,而需要的数据则集中于几个需要的块儿。这个脑洞大开的想法马上被他自己的查询证伪了。
SQL> select BLOCKS from dba_segments where segment_name='T1' and owner='TEST';
BLOCKS
----------
1281
SQLT中发现关键信息
基于以往故障经验的猜想都不成立,而现象看上去是Oracle CBO计算执行计划时出了问题,有DBA已经开始认为是Oracle BUG了(当然没找到对应的BUG编号)。在看客户DBA发来的SQLT的报告时,终于在报告中找到了问题的突破口。

上图可以发现客户的系统是收集过系统统计信息的(报告为测试环境抓取的),再看单块读、多块读,MBRC(注测试环境模拟时,单块读、多块读数值差别较大,真实环境差别为十多倍,MBRC为3)均有统计信息,这点很是异常,毕竟看过的绝大部分系统都是没收集过系统统计信息的。
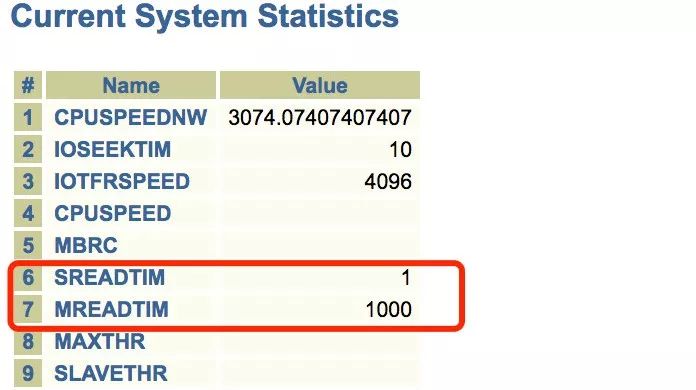
当然其实10053 trace文件中也有系统统计信息,只是这块儿相对关注较少。
问题分析
详细分析前,先回顾下COST算法,参考support oracle文档:How To Calculate CPU Cost(文档 ID 457228.1)。
Cost = (
#SRds * sreadtim +
#MRds * mreadtim +
#CPUCycles / cpuspeed
) / sreadtim
#SRDs - number of single block reads
#MRDs - number of multi block reads
#CPUCycles - number of CPU Cycles
sreadtim - single block read time
mreadtim - multi block read time
cpuspeed - CPU cycles per second
公式总结起来可以归结为cost本质为单块读,获取数据途径为磁盘或内存,内存中的逻辑读取消耗CPU时间除以单块读后,折算成以单位读为单位,磁盘中获取分为单块读(大部分索引访问)或多块读(全表或部分索引访问),多块读时间折算成单块读时间时,需要考虑每次读取块数(优先参考参数_db_file_optimizer_read_count,该隐含参数未设置情况下取db_file_multiblock_read_count,默认配置为8)。
可以验算一下,全表扫描时COST值10033粗略计算方式:1281/128*1000。
而sreadtim,mreadtim在没收集过系统统计信息时是通过公式计算得来的。
SREADTIM = IOSEEKTIM + db_block_size / IOTFRSPEED
MREADTIM = IOSEEKTIM + db_block_size * MBRC / IOTFRSPEED

IOSEEKTIM默认10ms,IOTFRSPEED默认4096字节/ms,推算可得默认值:SREADTIM 12ms, MREADTIM 26ms
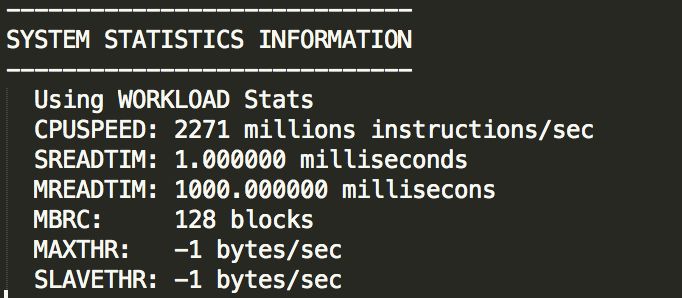
回顾过COST相关的知识后,再来看当前的系统信息SREADTIM 1ms, MREADTIM 1000ms MBRC 128,即:通过单块读的方式读取128个块也只需要128ms,远远小于直接多块读128个块的成本(1000ms),CBO当然会选错。
故障处理
故障处理起来很简单,运行以下语句,清除掉收集的系统统计信息就可以了。
exec dbms_stats.delete_system_stats;
清除完统计信息后,再清除下shared pool中的执行计划,再次解析时,系统正常运行,至此困扰许久的问题终于解决。
追根溯源
为什么收集系统统计信息会产生错误的单块读、多块读值?
这个主要是由于部分物理IO命中存储/操作系统文件缓存引起,如果收集时间短,或是系统空闲可能导致信息非常不准确。
为什么会收集系统统计信息?
默认收集全库统计信息并不会收集系统统计信息,只能运行DBMS_STATS.gather_system_stats手工触发,最终客户DBA通过堡垒机排查发现运维人员存在违规操作,问题源头得以查清。
是否应该收集系统统计信息?
这是一个非常有争议的话题,甚至官方文档的建议随着不同的Oracle版本也在变化。无论参考Oracle的官方文档,还是对比实际值( 实际awr报告中db file sequential read db file scattered read等待事件,大部分值都小于5ms的真实情景),或是参考Exadata以及各种国产一体机出色IO性能的大背景,单块读12ms,多块读26ms这个系统默认值都似乎过时了,应该调整。
事实上影响Oracle优化器的因素非常多,搜集统计信息会引入一个额外的因素,导致系统性能波动。系统性能和扩展性问题更多是因为糟糕的schema设计和schema统计信息没有维护好导致的。在现实情况中,我们没有遇到过通过搜集系统统计信息解决SQL性能问题,倒是遇到过多个案例因为搜集系统统计信息,替换了默认的系统统计信息,从而导致执行计划变差的案例。建议生产中不更新系统统计信息,使用默认的系统统计信息。
性能故障时的排查思路:
决定SQL性能的主要因素为以下四条,SQL性能问题时的排查可做参考:
统计信息;
schema访问路径;
SQL写法;
Oracle版本补丁情况。
能否直接调整系统信息?
附上测试脚本,开始测试时,直接调整SREADTIM、MREADTIM、MBRC值,并不能达到效果,必须有个收集的过程,哪怕如脚本所示实际没采集到数据(注:flush shared pool为危险操作,测试脚本内容不要在生产库使用)。
为什么收集系统统计信息不生效?
收集系统统计信息分为NOWORKLOAD及WORKLOAD两种模式,脚本中gather_system_stats('start')方式为workload模式,该模式下大表读取如果使用直接路径读方式,则无法采集到MBRC值。因为MBRC值必须读进buffer cache中,才会被统计(alter session set “_serial_direct_read”=never; 关闭后测试可获取)。SREADTIM、MREADTIM、MBRC值三个缺少任意一个,收集的系统统计信息均不会生效。
SQL> exec dbms_stats.delete_system_stats;
EXEC DBMS_STATS.gather_system_stats('start');
EXEC DBMS_STATS.gather_system_stats('stop');
EXEC DBMS_STATS.set_system_stats('SREADTIM', 1);
EXEC DBMS_STATS.set_system_stats('MREADTIM', 1000);
--exec dbms_stats.set_system_stats('MBRC',128);
SELECT pname, pval1 FROM sys.aux_stats$ WHERE sname = 'SYSSTATS_MAIN';
set autot trace
alter system flush shared_pool;
select * from test.t1 t where OBJECT_ID=1;
PL/SQL procedure successfully completed.
SQL>
PL/SQL procedure successfully completed.
SQL>
PL/SQL procedure successfully completed.
SQL>
PL/SQL procedure successfully completed.
SQL>
PL/SQL procedure successfully completed.
SQL> SQL>
PNAME PVAL1
------------------------------ ----------
CPUSPEED 2270
CPUSPEEDNW 2270
IOSEEKTIM 10
IOTFRSPEED 4096
MAXTHR
MBRC
MREADTIM 1000
SLAVETHR
SREADTIM 1
9 rows selected.
SQL> SQL>
System altered.
SQL>
39999 rows selected.
Execution Plan
----------------------------------------------------------
Plan hash value: 3617692013
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 38294 | 3627K| 350 (1)| 00:00:05 |
|* 1 | TABLE ACCESS FULL| T1 | 38294 | 3627K| 350 (1)| 00:00:05 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("OBJECT_ID"=1)
Statistics
----------------------------------------------------------
42 recursive calls
0 db block gets
3903 consistent gets
1253 physical reads
0 redo size
1852399 bytes sent via SQL*Net to client
29845 bytes received via SQL*Net from client
2668 SQL*Net roundtrips to/from client
6 sorts (memory)
0 sorts (disk)
39999 rows processed
附执行操作脚本:
exec dbms_stats.delete_system_stats;
EXEC DBMS_STATS.gather_system_stats('start');
EXEC DBMS_STATS.gather_system_stats('stop');
EXEC DBMS_STATS.set_system_stats('SREADTIM', 1);
EXEC DBMS_STATS.set_system_stats('MREADTIM', 1000);
exec dbms_stats.set_system_stats('MBRC',128);
SELECT pname, pval1 FROM sys.aux_stats$ WHERE sname = 'SYSSTATS_MAIN';
set autot trace
alter system flush shared_pool;
select * from test.t1 t where OBJECT_ID=1;
select /*+ full(t ) */ * from test.t1 t where OBJECT_ID=1;
select /*+ index(t idx1) */ * from test.t1 t where OBJECT_ID=1;
select count(*) from test.t1 t where OBJECT_ID=1;
alter system flush shared_pool;
oradebug setmypid
oradebug unlimit
oradebug event 10053 trace name context forever,level 1
select * from test.t1 t where OBJECT_ID=1;
oradebug event 10053 trace name context off
oradebug tracefile_name
参考文档
http://www.oracle.com/technetwork/database/bi-datawarehousing/twp-bp-for-stats-gather-12c-1967354.pdf
https://blogs.oracle.com/optimizer/should-you-gather-system-statistics








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721