
作者介绍
黄浩:从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
《SQL性能优化与批判》是黄浩老师的系列新作,他将从过往在项目技术支持中碰到的诸多案例入手,细化到每一条问题SQL的内在病因,反思每一个案例的背后深思。今天跟大家分享的是第三个案例:报表优化,需要回顾前情的同学请戳这里:案例一、案例二。
一、案例
从游击战到运动战
深圳的九月,天气依旧酷热难当,丝毫没有秋天的凉爽。转眼在I项目组已经呆了近40天了,每天的工作相对充实。但是对整个系统的逻辑结构,甚至实体关系我都一知半解。而这期间的SQL优化基本上都是基于SQL自身,并没有深入到业务逻辑;另一方面,因为项目组没有知识文档,所有的知识都深深装载在几位大咖的脑海中。
这一天,I项目组成立了性能优化专项小组,我就是4人小组中的一员。小组组织架构如下:
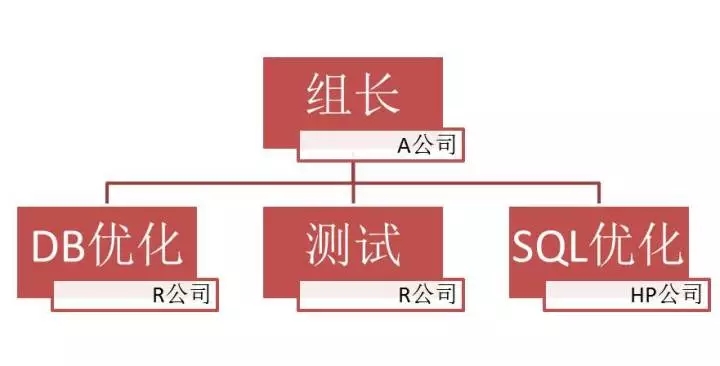
组长是A公司在H公司的一位高级顾问,统筹全局并兼顾Java应用端的性能分析及优化,从另一个项目借调了一位DBA负责DB系统级别的优化与故障诊断,而我负责SQL方面的优化。另一位女孩子则是负责性能测试工作。我们当时管这个架构为4321,即4人3公司2优化(DB和Java)1测试。
小组的工作流程是这样的:以测试驱动优化,同时需要梳理并形成I项目的性能基准。而小组的首期任务就是在1017版本完成一轮性能优化。
从一开始的单打独斗见招拆招,到现在组织规划测试驱动,I项目组的性能优化也开始从化整为零的游击战转为化零为整的运动战。
整体性能状况不容乐观
经过一个星期的集中压力测试,压出来的结果大大出乎我们起初的预估,多达70多项的性能问题。面对如此严峻的性能状况,久经沙场饱尝风霜的组长也长叹:没想到这个运行仅仅1年的系统,其性能状况竟如此的糟糕。
在一个月的时间里要完成70多项的性能优化,这是优化小组不可能完成的任务。在组长的努力下,我们压缩了优化项,在1017版本中只优化非常紧迫的问题,最终筛选了15项,其中就包括报表优化,共有六张报表。由于报表不涉及业务逻辑的维护,是只读性质的,因此由我全权负责,我拿到的清单如下:
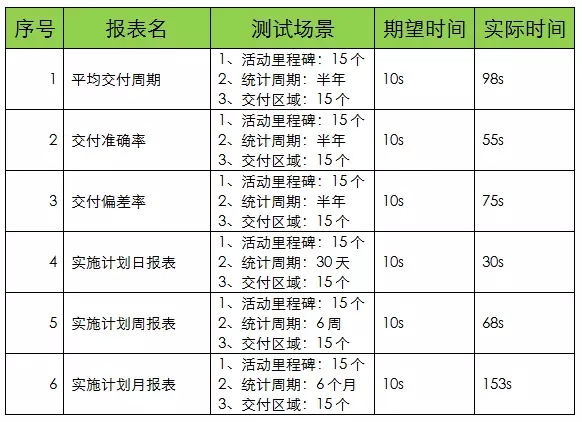
看着这份测试清单,我的心有如15个吊桶打水,七上八下的。
首先,就当前性能现状而言,就够我喝一壶的了。最快的“实施计划日报表”,离预期也有20s的差距,更不用说是相距最大的“实施计划月报表”,足足慢143s。
其次,这个报表清单只有测试内容,没有其它信息,比如对性能优化非常关键的“开发责任人”、“SQL语句”等信息全无。
为此我必须进行如下工作:明确报表责任人—》提炼出报表SQL语句—》分析性能瓶颈—》制定优化方案—》传递开发方案—》验证功能及性能。
作为一名在DW领域从业长达10年之久的老兵,在OLTP系统中遇到OLAP的案例,内心还是有些小激动的;此刻有如沙漠见甘泉,他乡遇故知。
因为前段时间通过SQL优化,我积攒了一定的人缘,所以第一步和第二部进展得还算顺利,尽管大家都忙于0926版本开发,但还是表现出了程序员固有的优良品质:爽朗客气,乐于助人。
而当我拿到平均交付周期报表的SQL时,顿时惊呆并石化,SQL语句洋洋洒洒,眼花缭乱,蔚为壮观:(戳开看大图)

万幸时间充裕
我还是第一次遇到如此复杂的SQL,初步观察了下,里面包含了with、正则表达式、group setting、connect by、orver等。而这也只是6张报表中的一个,其它报表的SQL陆续拿到后,都大同小异,出其的复杂。
望着这6个近乎巨无霸的SQL语句,我心里面也犯起了嘀咕,如同六块磐石压在心头,顿时压力倍增,手足无措。
还是老套路,既然SQL自身晦涩难懂,就自上而下,从尝试着业务侧解读SQL。从业务侧解读SQL需要一个条件:要有充足的时间。而这次优化任务的时间是相对充裕的。
于是我找到了开发人员,通过一番请教后,大致明白了平均交付周期报表的业务功能及SQL结构。这个报表的样式如下:交付区域|分包商|周期|MS1àMS2àMS3à…..-->MSN。

这个报表有如下复杂之处:
1、在同一报表页面需显示单个维度汇总数据,即需要展示所有交付区域、分包商的汇总数据,比如需要展现:
|
区域 |
产品 |
销量 |
|
华南区 |
手机 |
50 |
|
电脑 |
60 |
|
|
手环 |
80 |
|
|
总计 |
190 |
|
|
华北 |
手机 |
80 |
|
电脑 |
0 |
|
|
手环 |
30 |
|
|
总计 |
110 |
|
|
所有区域 |
手机 |
130 |
|
电脑 |
60 |
|
|
手环 |
110 |
|
|
所有区域 |
总计 |
300 |
2、里程碑是动态的,由用户在页面选择。即用户可以选择10个里程碑,也可以选择20个里程碑;
3、周期除了显示页面选择的时间范围外,还需要计算全生命周期的汇总数据。即不能根据页面选择的时间条件过滤数据。比如用户选择查看2015年6月到2015年9月的数据,我们不能将非日期范围的数据过滤掉,因为如果过滤掉了,我们就无法计算“全生命周期”的指标。
4、报表有三个基础维度,即时间周期、交付区域、分包商。这三个维度之间没有必然的关系,因此需要在页面展现任意组合。比如用户选择了2个交付区域,3分分包商,2个周期,那么就需要至少(另外还需要展现汇总数据)展现2*3*2=12条数据:
|
交付区域 |
分包商 |
周期 |
|
华南区 |
分包商1 |
201507 |
|
华南区 |
分包商1 |
201508 |
|
华南区 |
分包商2 |
201507 |
|
华南区 |
分包商2 |
201508 |
|
华南区 |
分包商3 |
201507 |
|
华南区 |
分包商3 |
201508 |
|
东北区 |
分包商1 |
201507 |
|
东北区 |
分包商1 |
201508 |
|
东北区 |
分包商2 |
201507 |
|
东北区 |
分包商2 |
201508 |
|
东北区 |
分包商3 |
201507 |
|
东北区 |
分包商3 |
201508 |
再看下SQL,这个SQL也有几大特点:
使用了大量的with子句,而且是一层套一层,阅读起来非常晦涩难懂,犹如迷宫容易迷失方向;
With子句之间的关系并不清楚,主次不明确。
心里有数,腹中生稿
分析完这个报表后,性能优化方案我基本上有了腹稿。为了更全面,我决定还是先摸摸其它报表的底,以便能制定出一套完整的解决方案。
花了一整天的时间,我把报表逐一了解了一遍,发现无论是表现形式还是SQL代码结构,基本上大同小异,这让我提起的心稍稍放下来了。
第二天一大早,我就开始着手解决方案。因为是结构性的改动,因此在出具正式方案前,我需要简单的验证下新方案的性能,如果新方案比现有方案还要慢,那就是丢人丢到家了,尽管我对新方案有100%的自信,但是最终还得要以事实和数据说话。
简单的模拟,性能果然杠杠的,6s左右就能完成,比预期的10s还要快4s。
轻车熟路,牛刀小试
方案的大致思路如下:
按照DW的思路,将数据归类,即维度数据及事实数据。在该报表中,交付区域、分包商、周期,及里程碑都是维度数据,里程碑间的间隔天数是事实数据,也叫指标。
维度数据与事实数据分开构建,构建完后,再将两个数据合并,得到报表数据;
在1、2的指导思想下,将原SQL进行拆解。将分包商、里程碑、交付区域及里程碑时间对一个的SQL抽离出来,并将执行得到的数据写入到对应的临时表中。最终将这些临时表关联起来,通过聚合等方式得到最终的报表数据
根据上述思路,大致方案如下:

其它报表的优化方案也是依葫芦画瓢,一整天下来,六个报表的优化方案全都制定完成。后续的开发测试就顺利得多了。
二、心得
一口吃不下整个披萨
这次SQL优化效果明显,版本上线后,得到了I项目组的书面表扬,我也因此在项目上“名声鹊起”,SQL性能优化在众人眼里变得神秘起来,都以为这是化腐朽为神奇的大作,其实这只是外行看热闹、内行看门道而已。
事后,与负责报表模块的SE闲聊,在谈及到这次的优化方案时,他表示了自己的疑惑:
“你之前给我们优化SQL的方案我都能理解,比如加索引、等价改写、用HINT。但是这次的方案确实不能理解。”
“对哪个地方有疑惑呢?”
“我看这次的优化,其实SQL并没有改动,只是把原来的一个SQL拆分了好几个SQL。为什么拆解了就快了呢?一方面,照理拆成多个SQL后,还要写入临时表,又从临时表把数据拿出来,步骤多了,应该更慢才对呀。另一方面,数据还是那么多的数据,SQL还是哪些SQL,为何拼在一起执行就慢了呢?”
“那你知道为什么披萨端上桌的时候都是分好块的吗?”
“为了方便吃呀,因为一口吃不下整个披萨。”








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721