
作者介绍
黄浩:从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
前言
《SQL性能优化与批判》是黄浩老师的系列新作,他将从过往在项目技术支持中碰到的诸多案例入手,细化到每一条问题SQL的内在病因,反思每一个案例的背后深思,抽丝剥茧,层层深入。今天跟大家分享的是第一个案例——WM_CONCAT优化,据说这是一次凭借技术+经验+运气三重加成才得以解决的案例,are you ready?![]()
一、案例
公元2015年7月20日,天气还是一如既往的炙热,徐徐海风也吹不散身上的热量。在经过近一个小时的班车加徒步,正式开启了我在H公司I项目技术支持的第一天。因为信息安全的缘故,第一次进入项目现场的外协人员需要办理接待电子流。因为是非研发区域,倒也快捷,经过两重关卡后,顺利进入到项目现场。妈呀,一个足球场般大小的办公场地,一排排的办公桌和电脑进入有序,但桌面上的办公什品却凌乱狼藉。而座位跟座位之间没有任何的遮挡。当时已经九点多,基本上座无虚席,虽然开着空调,仍然能感觉到一股由电脑散发出来的参杂这铁锈及灰尘味的热气,以及由此带来的压抑感。
在与现场同事简短的寒暄后,我便立马投入到工作——当然是交接工作。与同事的沟通中,获取了如下信息:
这位同事来这个项目不足两周;
离职的原因是适应不了外包的工作方式;
项目组性能优化工作开展很困难,项目组在这方面的投入不够,重视度也不够。
综合起来就是一个字:坑、巨坑。原本当心我主观上的能力问题会影响到工作,没想到客观环境也是如此糟糕,我的心情跌倒了冰点。
明天是这位同事在项目组的last day,所以交接工作必须在今天内完成。好在同事进项目不久,还没有接触到太多的工作内容,手头上就一个在优化的SQL。因为这个SQL的优化已经持续了几天时间,所以到目前显得有些紧迫:该SQL的优化被安排在周六上线,因此必须在要周三前给出优化方案。离周三只有不到2天的时间了而目前的优化进度还停留在问题定位阶段,还不确定问题处在哪里?换句话说,不是工作交接,而是从零开始。
我在同事的交接文档中找到了问题SQL,代码如下:

战战兢兢,如履薄冰
没有任何的注释,代码中的表呀,字段呀什么的,我一个也不认识,唯一亲切的就是select from where join group这些被标绿的SQL关键字。
“这个SQL有什么性能症状?”
“跑起来很慢。”
“慢到什么程度?”
“大概需要半个多小时才能跑完。”
“数据量很大吗?”
“可能吧,我还没有执行过,只是听开发人员这么说的。”
看来我不能从这位同事这里得到更多有价值的信息了。
按下F5查看执行计划:
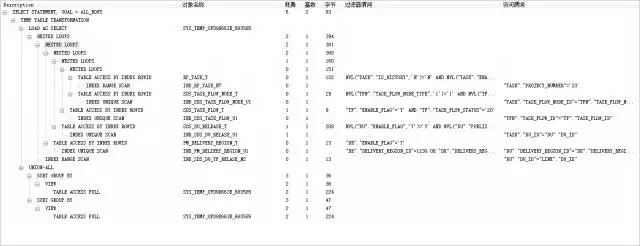
执行计划中,表访问方式基本上都是index scan,而且也并无大成本的操作。奇怪了,问题处在哪里呢?又回到SQL窗口,按下F8,果然只见时间过,不见数据出。
在长期与SQL相伴的日子里,我养成了一个习惯,喜欢在边看着Oracle执行,一边分析代码,大有“我忙着分析,你也别闲着偷懒”的“小人嘴脸”。
这个SQL有两个部分,第一部分是用with封装了一个结果集,第二部分是对第一部分的结果集进行group by处理。根据过往经验,我将SQL复制到了另一个SQL窗口,选中with子句单独执行,秒出呀。
排除了子查询的性能嫌疑,那么很显然问题是出在第二部分的SQL。第二部分SQL包含了group by,难道是group by产生了性能问题。要知道,GROUP BY等聚合操作的性能对数据量是及其敏感的。难道是with子查询的数据量非常大?
我赶紧count了第一部分SQL的结果集,显示不到20万数据。那就不应该呀,20万数据做group by也不至于慢成“蜗牛”呀。
继续分析第二部分SQL代码,在select子句中,惊现wm_concat函数。此时,我还是有些小激动的,因为在之前也遇到过由于wm_concat引发的性能问题。为了验证判断,我将wm_concat注释掉,F8运行,果然飞快,不到1s就出结果。
至此,通过排除法,病因是找到了:由wm_concat引发了性能问题。
顺藤摸瓜,顺手牵羊
原因已经找到,那么对症又该如何下药呢?显然,从SQL功能上,wm_concat是必须的,我也尝试过用listagg来替代wm_concat,但是会因超过4000字符而报错。其实wm_concat函数之所以慢,就是因为以task_name为维度需要拼凑的数据量太大导致的。难道就无解了吗?
我转念一想,为什么要用wm_concat函数?应用程序在拿到这个字段后做什么用呢?在前端页面显示吗?这种显示是没有多大意义的,因为wm_concat的结果可能非常大,根本就显示不了。既然显示不完整,那么为什么又要从DB中获取完整的内容呢?
带着这些疑惑,我与SQL开发人员进行了沟通,原来,应用程序拿到这个SQL的数据后,并不是在前端页面展现,而是在应用程序中继续加工处理,在经过若干复杂的逻辑处理后,以另一种形式在页面展现。
此时,多年的从业经验告诉我:既然可以用Java来实现的业务逻辑,那么肯定也能在DB中通过SQL来实现,这样就可以避开wm_concat函数。于是我决心深入了解业务功能,希望能从业务方案上有所突破。这样就形成了一个初步的工作计划:了解整体业务功能及逻辑-->了解应用程序处理逻辑-->改写SQL语句-->功能性测试-->性能轮回调整。
在大约两个小时的一对一讲解后,我基本上掌握了整体业务功能及逻辑、应用技术架构及处理逻辑。这个其实是一个报表展现功能,是按区域、里程碑展现两个相邻里程碑之间的时间间隔,包括计划间隔时间与实际间隔天数(平均)。报表格式大致如下:

在DB中,里程碑的计划与实际时间是存在二维表中,结构示意如下:

在这里,就存在一个行列转换的问题,即将TASK_NAME从以行存储转换成以列展现。为了实现这种结构转换,当时的架构设计如下:
通过SQL从DB获取每个里程碑、交付区域的plan_start_time、plan_end_time、actural_start_time、actural_end_time及du集合,即sql中的wm_concat拼凑后的结果。
Java应用程序拿到这个结果后,循环结果集,并依次分解由wm_concat拼凑的内容:
计算每一个里程碑内DU的平均时间间隔;
判断里程碑的前后置关系;
计算前后置里程碑间的天数间隔;
最终将计算结果展现在前端页面。
水到渠成,一战而定
从上述描述中,我们可以提炼出如下信息:
WM_CONCAT拼凑的内容只是过渡的,在Java中还需要依次分解;
Java处理的几个步骤完全可以由SQL来实现。这样就可以省却以下几个“麻烦”:
省却了大量数据从DB传输到JAVA服务器的成本开销;
可以顺理成章的拔掉wm_concat这根刺
那么,如果用SQL来实现上述逻辑功能,存在两个难点,其一是如何判断里程碑(task_name)前后置关系,其二是计算前后只里程碑的时间差。
进一步分析后发现,程碑(task_name)前后置关系可以通过SQL来获取,而在时间间隔的计算上,可以通过lead窗口分析函数获取后置时间,然后相减即可。
改造后的SQL如下:
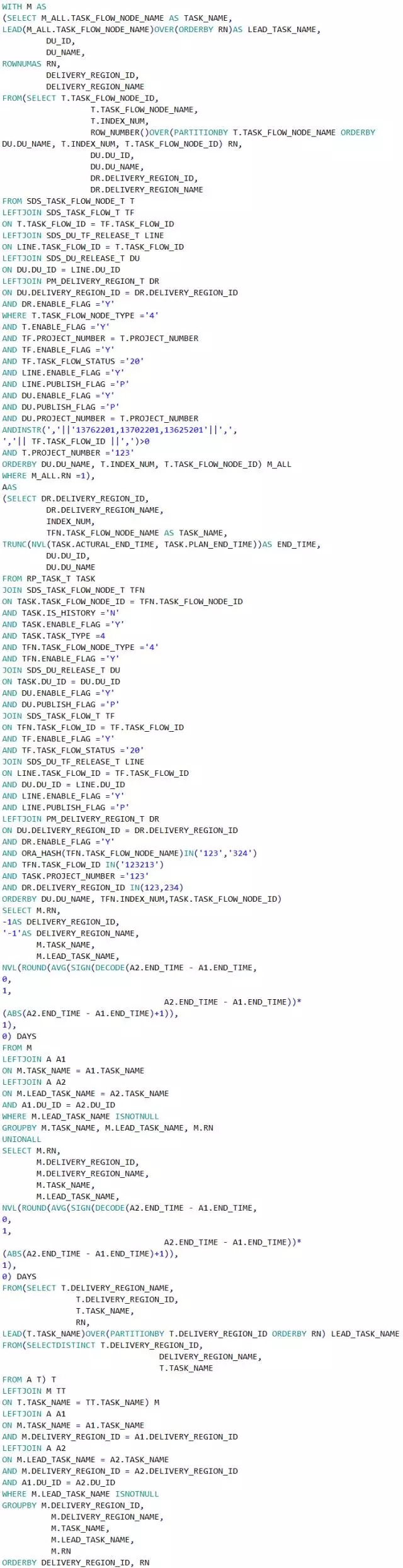
将SQL在DB中运行,不到3秒就执行完成。
二、心得
心有余悸,学无止境
值得一提的是,这个SQL并非一蹴而就的,从第一次改写,到最终上线,经历了好几个版本,但整体结构并没有变动,只是对某些特殊场景做了调整。
来项目的第一个SQL优化就这样跌跌撞撞歪打正着的完成了。由于时间紧迫,整个过程都是绷紧了神经。现在回想起来,即时庆幸又是后怕,庆幸的是问题得到了及时解决;后怕的是,当时可谓是不知者无畏,完全是在不熟悉环境,不熟悉利害关系的情况下解决了问题。如果放在几个月后,我想一定没有当时的勇气和决心来完成这件事情。
回过头来看,这起由wm_concat引发的性能事件还是给了我们很多的启发:

SQL优化并不是孤立的,也就是说并不是所有的SQL本身都存在优化的空间。当SQL本身无法优化的时候,或者优化的空间不足以满足用户需求时,就需要从全局需求突破,尝试着按另一种方式得到结果:殊途同归讲的不就是这个道理吗?正所谓山重水复疑无路,柳暗花明又一村,关键在于你是否愿意主动寻求和突破。

SQL优化并不需要多么高深的知识和高级的技术,SQL优化也并不那么神秘,一点点技术,一点点经验,再加上一点点运气就足够了。

这里说的技术是SQL技术。SQL语言我认为是除汇编外所有语言中最神奇、最简单、最具艺术化的语言。
说简单,就select查询而言,就select from where and or group order等屈指可数的几个关键字,拿SQL而言也就select、update、delete、insert四种功能。而且通俗易懂。
说神奇,因为就这些关键字,无需排列组合,便可以千变万化。在当今的信息化大时代,无外乎就是增删改查;大千世界,芸芸众生,概莫能外。就拿人类自身来说,其终极哲学就是:生老病死,出生就是insert,岁月催人老就是update,众里寻他千百度就是select,荣登极乐就是 delete。
说艺术化,简单而不简约,这就是艺术,能以数个关键字撑起世间万物的起起落落,这就是艺术。
这里说的掌握SQL技术,不仅仅是掌握这几个关键字,用这几个关键字变幻出种种结果,更是要掌握是如何通过这几个关键字来实现这种艺术化的效果。

经验这东西是美妙的,一旦你拥有了某个知识点的经验,下次再遇到时,你会不费吹灰之力就能解决了。比如这次的wm_concat函数,我相信,之前的同事没有定位出问题所在,就是他没有遇到过wm_concat这个函数。所以总结经验是绝对正确的,虽然经验并不一定有用得上的机会。

所学的一点点知识和积累的一点点经验恰好被用上了,这就是运气。因此运气也是辩证的,表面上是因为运气解决了这个问题,实则不然,如果没有那么一点点知识和经验,也不会这么顺利的解决。可见偶然中也有必然。
三、批判
7月25日周末上线,周一一大早,开发兄弟像报喜一样告诉我,优化效果明显,用户非常满意。看着他稚嫩中略带青涩的笑脸,我也长舒一口气,毕竟这是我的第一个优化案例。
“黄工,你是怎么知道可以这样处理的?”
面对他的这个问题,我一时哑口,该如何回答呢?
“那你当初为什么要将SQL返回中间结果集,然后又在java中做逻辑处理呢?”
“一方面,我们的架构规范就是这样的,要求尽量在java中完成逻辑处理,减少DB的负载;另一方面,我也写不出这么复杂的SQL,说实话,你给我的SQL我到现在还没有看明白。”
原来如此,我就告诉他:
“在二维关系的系统里面,java能处理的二维数据,在SQL中都能实现”
“哦”
“对了,你是怎么选择wm_concat这个函数的?”我知道这个函数很少用,也是Oracle公司未公开的内部函数。
“我是在网上查到的资料,看到这个函数可以实现功能,就拿来用了,没想到会带来这么大的性能问题。”
看得出来,他仍然保持了学生意气,有些自责,他好像又想起了什么来,赶紧补充说“因为时间太紧迫了,现在是敏捷开发,每两周一个版本,如果时间充裕的话,我想我也能通过查资料把这个SQL写出来的。”
他说着有些激动,但事实上他是认真的,也真的做到了。在后来的开发过程中,他写出了连我都写不出来的复杂SQL。
通过与他的对话,我大致可以勾画出这个项目的一些基本元素:敏捷开发,双周迭代,无开发型DBA,重Java轻SQL。这些是国内大多数项目的通病,本来是见怪不怪,但是出现在世界500强,国内IT软件天堂的大公司,还是让我有些意外,更让人感到后脊凉凉的。
敏捷开发要求快速交付,功能优先性能,急功近利;偌大的一个企业级平台项目,居然没有匹配一个专职的开发DBA,SQL的质量令人担忧,而重Java轻SQL在信息管理系统中是一个大忌,会暗藏很多性能风险,这一些都是性能的催化剂,这意味着我接下来的道路势必坎坷曲折、荆棘丛生。
- AND-
更多数据库优化干货
尽在全球敏捷运维峰会北京站!
9月15日 大牛亲授绝技 就差你了

抢座链接:
https://www.bagevent.com/event/643565#website_moduleId_60229







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721