
一、DB-Engines数据库排行榜
二、数据库排行榜深度解读
三、RDBMS家族
MySQL发布高可用方案InnoDB Cluster
Percona发布MySQL 5.7.18-15版本
MariaDB发布10.2.6版本
SQL Server发布2017 CTP2.1版本
DB2发布LUW 11.1 mod1 fp1版本
PostgreSQL发布10 beta1版本
Greenplum发布5.0 Beta版本
SQLite发布3.19版本
四、NoSQL家族
MongoDB发布Stitch Backend as a Service
Redis发布机器学习应用模块Redis-ML
本期新秀:ArangoDB发布3.2 beta版本
五、NewSQL家族
TiDB结合Ansible简化集群部署,即将推出TiSpark
本期新秀:InfluxDB发布V1.2.4版本
六、大数据生态圈
Hadoop发布第三个测试版本
Druid发布10.0版本
SnappyData发布
GPText 2.1版本发布
七、国产数据库概览
GBase 8t、8s发布最新版本
达梦数据库发布最新版本V7.1.5.186
人大金仓发布最新版本V3.1.2
OceanBase发布1.4.2版本
星瑞格数据库发布12.10 FC 8版本
八、推出DBAplus Newsletter的想法
九、感谢名单
提示:登录云盘http://pan.baidu.com/s/1qYfSDLa可下载本期Newsletter。
DB-Engines数据库排行榜
以下取自2017年6月的数据,具体信息可以参考http://db-engines.com/en/ranking/,数据仅供参考。
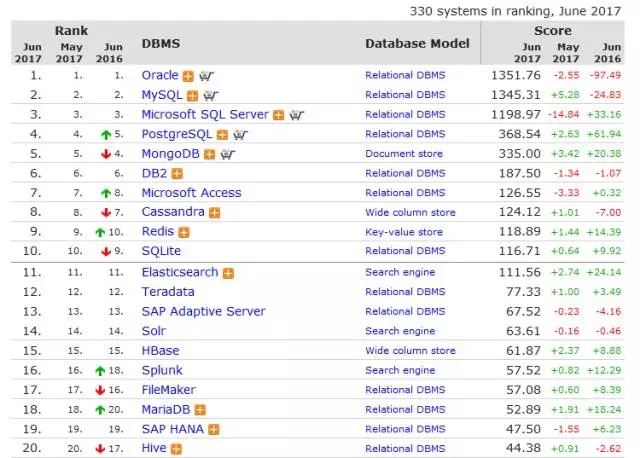
DB-Engines排名的数据依据5个不同的因素:
Google以及Bing搜索引擎的关键字搜索数量
Google Trends的搜索数量
Indeed网站中的职位搜索量
LinkedIn中提到关键字的个人资料数
Stackoverflow上相关的问题和关注者数
本期值得一提的是Redis超SQLite成为第9名,虽然相对第10名优势不到1分。
数据库排行榜深度解读
去O的浪潮并没有扑灭,Oracle和MySQL的分值之差只有6分。从2016年6月以来,Oracle数据库的分值减少了近100分,微软的MSSQL数据库、开源的PG和MongoDB增长之和115分。
云计算的时代已然到来,Oracle数据库本身作为传统关系型数据库的老大,越来越受到威胁是必然的事情,但6月22日Oracle公司公布其第四财季净利32.3亿美元,并且自2014财年以来首次实现了年度盈利和营收增长,股价大涨逾11%。这与分值形成反差。这个反差的主要成因与DB-engines分值的6大指标中的3个(在Google/Bing/Yandex上被提到的次数、Google Trends被搜索的频率、Stack OverFlow等IT网站被讨论的频率)有关,Oracle数据库被包进PaaS解决方案,所以热度降低实属必然。
MySQL数据库的分值一再上涨,大有盖过Oracle数据库之势,我认为也是极有可能的。这个突破点可能会到MySQL 8.0正式GA的时候,倒序索引以及MySQL Sharding的逐渐成熟,势必会引发更多的MySQL使用者。类似DBAplus社群这样的专业社区组织,纷纷增加的各种开源数据库峰会,在一定程度上也推动了它们分值的上涨。
国内云计算企业的背后支持,使PostgreSQL社区走在前列。而相比之下,MSSQL是一个例外,没有一个专业的社区组织,微软自己似乎也不太在乎它的生态,但抵不住它庞大的使用量基数,让它稳稳占据老三的位置,而且分值还在一路攀升。
MongoDB则跟前两类都不同,它先是作为一家企业存在,而后再开源,一度在2016年冲到了DB-engines排行榜第四位。作为一家创业10年的数据库厂商,MongoDB是相当年轻,也是相当成功的,目前3000多个客户,800多个员工,估值几十亿美元。目前MongoDB的社区是靠MongoDB公司主力去推动的。在2017年5月21日,DBAplus社群在上海组织了一场MongoDB的线下沙龙,国内TOP4的云服务商大咖都来了,也谈到MongoDB在中国的前景,以及跟这些云服务商合作与竞争关系。MongoDB是否在未来一年,奋起直追再冲上第四的位置,还是在第五的位置匍匐前行,取决于MongoDB是否放开胸怀。
作为大型企业的核心生产数据库,选择国外数据库的话,基本上只会在上述5种里选择。其它数据库,暂时还只能在替补梯队里。
值得欣喜的是,国产数据库这两年不仅在市场上攻城略池,在版本发布上进度也快了很多。下一期我们来专门点评一下国产数据库吧。
一、RDBMS家族
MySQL发布高可用方案InnoDB Cluster
2017年4月中旬,MySQL官方发布了InnoDB Cluster的GA版本,InnoDB Cluster是MySQL的一套完整的、全栈的高可用解决方案。
MySQL InnoDB Cluster由下面三个不同产品和技术组成,它包含MySQL Shell、MySQL Router、MySQL Group Replication。
其中MySQL Shell通过内置的AdminAPI来创建和管理整个InnoDB集群。MySQL Router 2.1+确保客户端请求是负载均衡的,在任何数据库故障的情况下,都会传输到正确的服务器。
而MySQL Group Replication是近期发布的一个重大特性,通过Group Replication来将数据复制到集群的所有成员,同时提供容错、自动故障转移和弹性扩展等重要特性。

Percona发布MySQL 5.7.18-15版本
2017年5月26日,Percona发布了MySQL5.7.18-15版本,可以在Percona官网下载,也可以通过Docker站点下载:https://hub.docker.com/r/percona/percona-server/
该版本基于MySQL 5.7.18,包含一些bug修复,5.7.18-15是Percona分支的最新版本。修复的bug信息如下:
The server would crash when querying partitioning table with a single partition. Bug fixed #1657941 (upstream #76418).
Running a query on InnoDB table with ngram full-text parser and a LIMIT clause could lead to a server crash. Bug fixed #1679025 (upstream #85835)
MariaDB发布10.2.6版本
MariaDB 10.2是目前稳定的版本。 它是MariaDB 10.1的演进,具有几个亮点的全新功能,并具有MySQL 5.6和5.7的后端和重新实现的功能。
需要注意的是Percona XtraBackup(从2.4开始)将不能与MariaDB 10.2(和MariaDB 10.1)压缩一起使用。 但是,MariaDB的分支机构MariaDB Backup可以进行压缩。它将包含在未来版本的MariaDB 10.2中。
具体信息可参见:https://mariadb.com/kb/en/mariadb/mariadb-1026-release-notes/
SQL Server发布2017 CTP2.1版本
微软去年宣布将发布SQL Server on Linux版本,并在2017年年中推出正式版。从今年5月份发布的SQL Server2017 CTP2.1版本来看,SQL Server2017的开发已经接近尾声,估计7月份会推出正式版。
在5月份发布的SQL Server2017 CTP2.1版本中,微软基本上已经将传统四大件移植到其它非Windows平台(SSIS、SSRS、存储引擎、SSAS),在CTP2.1版本中还包括了两个新工具:
mssql-scripter tool :快速生成针对数据库对象的create和insert语句。
DBFS tool:更容易在Linux上通过DMV监控SQL Server,通过读取文件来获取SQL Server的数据。
可以看到SQL Server2017不是简单地将SQL Server 2016移植到非Windows平台,还增加了一些SQL Server 2016 SP1不具备的新特性。例如:
高可用方面引入了Read-scale可用性组;
R、python等机器学习方面功能;
支持Linux下Docker引擎。
DB2发布LUW 11.1 mod1 fp1版本
DB2在V11版本与之前版本并无太大改善,最新推出的11.1 mod1 fp1只是侧重点更偏向于Share Nothing的集群架构上的bug进行了修复,但与之同时,IBM也在推进基于DB2内核的私有云解决方案dashDB local。
dashDB Local是一个以Docker容器形式交付的配置数据仓库,同时dashDB支持MPP分布式架构,以便带来更高效的数据分析,并且可以与Oracle、Netezza等数据库兼容。
但是根据官网的描述,并没有从dashDB local上发现过多的特征和亮点,并且dashDB local和DB2在功能上存在很大程度上的重叠,两条独立的产品路线有可能会让用户感到迷惑。
PostgreSQL发布10 beta1版本
2017年5月18日,PostgreSQL发布10 beta1版本,新版本将支持逻辑订阅、分区表、quorum based多副本同步复制、表分区、协议级多机failover、多列统计信息、sharding增强(聚合下推)、多核并行增强(索引扫描、位图扫描、merge JOIN等)、安全增强(SCRAM认证模块)等。非常值得期待。详见:https://www.postgresql.org/docs/devel/static/release-10.html
PostgreSQL积分连续数月增长,同比去年增长61.94分。
CrunchyData开源PostgreSQL中间件,详见:
ZomboDB开源,整合ElasticSearch作为PostgreSQL的搜索引擎,详见 :
Greenplum发布5.0 Beta版本
相对于之前的Alpha版本,beta版最大的更新是支持了4.x中所有的扩展组件,也包括很多的bug修复和功能的增强,完整的Release Notes后面有介绍。Beta版本的发布意味着Greenplum 5.0正式版中的全部计划的功能都已经基本完成,更意味着正式版很快就会发布。
下面对Beta版的主要功能做一个大致的介绍:

Greenplum支持PostgreSQL 8.3的完整功能以及某持PostgreSQL高版本的功能,相对Greenplum4.x,主要增加的功能如下:
‘Order by’可以支持NULL first或NULL last;
支持新的数据类型及相关函数:Json、UUID、ENUM;
Postgres 9.1中的XML类型的操作函数;
支持任意复杂和组合类型的数组;
支持PostgreSQL 9.1的Extension功能;
重新实现了ANALYSE函数提升了性能;
支持dblink扩展;
支持pgcrypto扩展;
gprestore支持了CASTs;
增强的session状态监控;
管理脚本和pl/python支持了python2.7;
默认启用ORCA优化器;
备份支持Veritas NetBackup 7.7.3;
内置Partner connector支持;
支持Binary COPY;
COPY命令支持直接将文件生成在Segment节点。
Greenplum不仅仅是一个MPP的数据库,它还提供了丰富的扩展组件来满足各种各样的数据分析和处理的要求,比如扩展的存储过程语言PL/Language、文本分析工具GPTEXT、基于浏览器的图形化管理工具GPCC、用于机器学习的算法库Madlib和处理地理信息的PostGIS等。支持的模块包括:
PL/Language: PL/Java, PL/Perl, PL/R, PL/Perl
Madlib 1.11
PostGIS 2.1.5
Client/Loaders tools 5.0.0
Greenplum Command Center 3.2.2
Greenplum Gemfire Connector
Greenplum 5.0 Beta企业版的支持平台:
Red Hat Enterprise Linux 64-bit 6.x/7.x
CentOS 64-bit 6.x/7.x
SuSE Linux Enterprise Server 64-bit 11 SP4
获取Greenplum 5.0 Beta:
官方的Greenplum安装包可以从Pivotal Network官方网站获取,文档在Pivotal Documentation可以找到,代码在Github上,中文开发者blog在这里,用户的讨论组为greenplum-user,开发讨论组为greenplum-dev。欢迎大家使用,反馈以及贡献代码。
SQLite发布3.19版本
SQLite在5月的版本更新比上月频繁。分别在5月的22日、24日和25日发布了3.19.0、3.19.1和3.19.2版本。
3.19.0版本为定期维护版本,此版本中对查询的执行计划进行了多方面的优化,并且修复了6个漏洞(详情参考:http://sqlite.org/releaselog/3_19_0.html)。还有一些奇怪的bug。如果你使用之前的版本没有遇到问题,则不需要升级。
3.19.1版本修复了2.19.0中查询优化器中暴露的一些bug。从3.19.0版本开始,左连接运算符右侧的子查询和视图有时会进行扁平化处理。新优化器在开发者提供的所有案例和其他各种案例中工作良好,但是3.19.0发布上线之后,有些用户发现在某些场景中,优化会失败。标号cad1ab4cb7b0fc344中包含有相关示例。
由于近期版本在左连接扁平化优化过程中存在很多问题,所以随机发布了3.19.2版本,该版本解决了前两个版本中发现的所有问题。
二、NoSQL家族
MongoDB发布Stitch Backend as a Service
MongoDB的年度开发者大会MongoDB World最近在美国芝加哥举行。一个好的开发者大会与新产品的发布密不可分。MongoDB利用今天的主题演讲发布了两个新产品,一个是MongoDB的云托管服务Atlas正式支持微软Azure和谷歌的GCP云平台,另一个是与Atlas一样棒的新产品:Stitch,它是一个基于MongoDB数据库之上的全新后端服务(Backend as a Service)工具。Stitch可以帮助开发人员整合不同的第三方服务,以及Mongo图表,一个新的类似于Tableau-like的商业智能服务。
在许多方面,Stitch标志着MongoDB首次涉足到其核心数据库服务之外的业务。MongoDB首席技术官和联合创始人Eliot Horiwitz告诉我,MongoDB的开发团队意识到MongoDB的大多数用户编写的应用程序会使用很多第三方服务的组合。Stitch允许开发人员连接到这些外部服务和并轻松把数据从API服务拉回到Mongo的同名数据库里然后进行数据访问。理想情况下,这意味着开发人员不需要构建自己的安全和隐私控制。例如,他们可以用这些服务来专注于构建而非整合他们的应用程序。
Stitch目前支持Google、Facebook、AWS、Twilio、Slack、MailGun和PubNow等服务的集成。但是正如Horowitz所强调的,开发者们也可以十分容易地将Stitch和其他提供REST API的服务结合起来。
Stitch现在处于公测阶段,MongoDB Atlas用户可以免费开始试用。Stitch的定价目前是基于开发人员需要传输的数据量而定。一旦Stitch问世,MongoDB用户将在一个类似于Atlas的价格模型下使用其服务。中国的用户不用担心,虽然目前Atlas尚未在大陆开展业务,Stitch将为有一个本地版本供非云用户试用。Mongo开发者,让我们拭目以待吧!
Redis发布机器学习应用模块Redis-ML
机器学习的世界
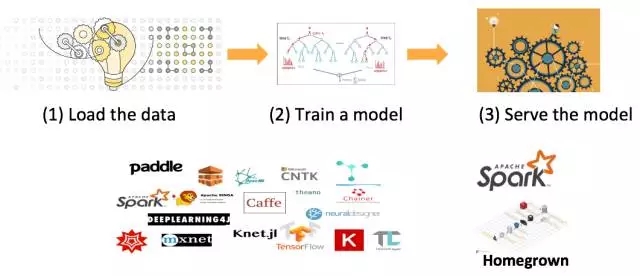
传统的基于Spark-ML机器学习的生命周期

基于ML模型的服务挑战:
ML变得非常流行,但是Models却变得很大,很复杂;
需要以更快的速度去分发/部署它们;
速度和大小方面不能很好的扩展,需要保持他们在集群中的一致性以及使得他们持久化;
可靠的服务很难做到 – 需要确保服务的可靠性;
比较昂贵 – 需要投入更多的硬件资源和人力成本。
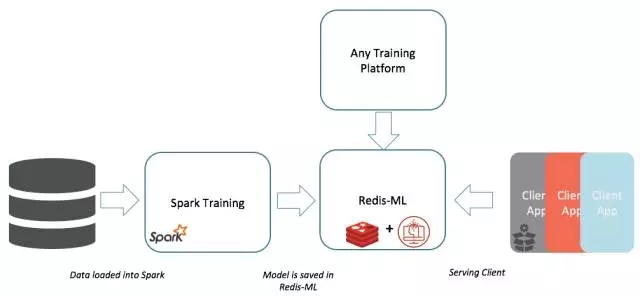
以“热模式”存储机器训练输出
直接在Redis中进行评估
轻松整合现有的C/C++ ML lib库
可以在运行过程中进行调整
享有Redis的高性能,可扩展性和HA
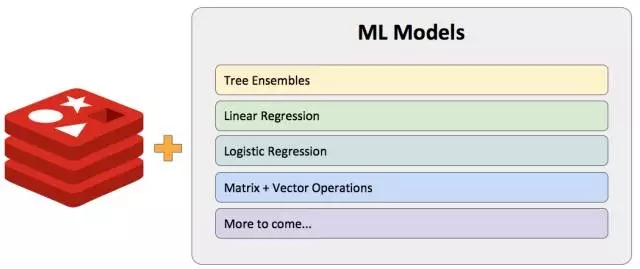
一个决策树集合
支持分类和回归
分离节点
按类别(例如:day == “sunday”)
按数值(例如:age < 43)
决策是由大多数决策树所决定的
欲了解Redis-ML更多信息,可点击查看DBAplus社群文章:《【独家】用Redis-ML模块实现实时机器学习!》
本期新秀:ArangoDB发布3.2 beta版本
ArangoDB是一个开源的分布式原生多模型数据库(Apache 2 license)。其Vision是:利用一个引擎,一个query语法,一项数据库技术,以及多个数据模型,来最大力度满足项目的灵活性,简化技术堆栈,简化数据库运维,降低运营成本。Github:https://github.com/arangodb/arangodb


ArangoDB从第一行代码开始就是按照多模型数据库来设计编写,可以根据业务需求灵活地为数据建立模型,ArangoDB支持graph图,document 文档和key-value三种数据存储模型。这三种数据模型的操作都基于同一个引擎,并使用统一的query语法- AQL 。
而且用户也可以在单次查询过程中混合使用多种模型,在执行查询过程时,无需在不同数据模型间相互“切换”,也不需要执行数据传输过程,并且这三种数据模型均支持水平扩展,这使得ArangoDB在速度和性能方面与其他数据库相比具有极大优势,因此适用于高性能领域需求。
AQL- ArangoDB查询语言(ArangoDB Query Language),是一种类似于编码的声明式查询语言。如果你了解SQL,就能够对AQL清晰直观的语法轻松上手。不再需要在多种数据库技术之间互相切换,ArangoDB让你只维护一个数据库,一个查询语言,来满足各种各样不同的需求。请查阅SQL/AQL的对比。以下是AQL的特殊性能:
Joins
Graph Traversals
Aggregations
Complex, powerful and convenient queries
Multi-collection and multi-document queries with transactional semantics (single instance)
Single document transactions (cluster)
Geo-spatial queries
Schemaless querying
Extensible via user-defined functions

SmartGraphs
SmartGraphs提供社区版本之外的更多高级性能, 以及在处理大型分布式图任务时几乎接近单台机器的更快的查询时间。阅读更多https://www.arangodb.com/why-arangodb/arangodb-enterprise/
增强加密支持
Auditing
企业级版本下载:download ArangoDB Enterprise Edition

社区版新特性
融合RocksDB存储引擎
Pregal分布式图形处理
有容错机制的Foxx在集群模式下根据您的需求扩展数据库
Geo-cursor,根据“距离”分类数据信息
Arangoexport数据导出
企业级版新特性
SatelliteCollections
使用SatelliteCollections可以将集合定义为集群,并将集合复制到每台计算机。ArangoDB查询优化器知道每个分片所在的位置,并将请求发送到所涉及的DBServers,然后本地执行查询。使用这种方法,可以避免在分片集合的连接操作期间的网络跳数,并且响应时间可以接近于单个实例的响应时间。
具体实例请参阅:
https://docs.arangodb.com/3.2/Manual/Administration/Replication/Synchronous/Satellites.html
加强版LDAP
闲时数据加密
3.2 beta企业级版本下载:https://www.arangodb.com/download-technical-preview-enterprise/
三、NewSQL家族
TiDB结合Ansible简化集群部署,即将推出TiSpark
TiDB是一款定位于在线事务处理/在线分析处理(HTAP: Hybrid Transactional/Analytical Processing)的融合型数据库产品,模型参考了Google最新的分布式数据库F1/Spanner。除了底层的RocksDB存储引擎之外,分布式SQL层、分布式KV存储引擎(TiKV)完全自主设计和研发。
TiDB完全开源,兼容MySQL协议和语法,可以简单理解为一个可以无限水平扩展的 MySQL,并且提供分布式事务、跨节点JOIN、吞吐和存储容量水平扩展、故障自恢复、高可用等优异的特性;对业务没有任何侵入性,简化开发,利于维护和平滑迁移。

日前,TiDB-Ansible已正式在GitHub上开源。Ansible是一款分布式集群配置管理工具。TiDB-Ansible提供了一套ansible-playbook脚本,专门用于安装部署TiDB集群,以及完成相关的配置。使用TiDB-Ansible可以快速部署一个完整的TiDB集群以及配套的运维监控工具(包括 PD、TiDB、TiKV 和集群监控模块)。
本部署工具具有如下特性:
通过配置文件定义集群拓扑,一键完成部署工作:
初始化集群
系统参数检查
性能检查
获取最新代码
部署核心服务
部署运维监控模块
集群启停控制
系统扩容
滚动升级
数据清理
TiSpark是Spark和TiDB结合的产物,使Spark能无缝对接TiDB,并提供原生SparkSQL所没有的优化支持,结合Spark生态圈原有的成员,TiSpark将在同一平台提供超越SQL界限的多种Workload支持,让大数据分析无需复杂数据搬运。
除了标准的Spark DataSource接口的功能之外,TiSpark通过扩展SparkSQL本身的Planner和优化器深度对接TiKV(TiDB 存储层),调整并切分查询计划,使SparkSQL得以支持聚合下推,索引读取,KeyRange下推和基于代价的优化等,从而更聪明地处理数据。而TiSpark对Spark的扩展是无侵入的,让用户可以通过第三方扩展包方式使用,无需更新现有Spark环境。
预计7月底,TiSpark将正式上线。
更进一步文档请阅读:https://github.com/pingcap/docs-cn
本期新秀:InfluxDB发布V1.2.4版本
InfluxDB是用Go语言写的,专为时间序列数据持久化所开发,由于使用Go语言,所以各平台基本都支持,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展。它有三大特性:
Time Series(时间序列):你可以使用与时间有关的相关函数(如最大,最小,求和等);
Metrics(度量):你可以实时对大量数据进行计算;
Eevents(事件):它支持任意的事件数据。

InfluxDB的发布更新相对频繁,可见社区的关注度和热度。
2017年3月8日发布了V1.2.1版本,3月14日发布了V1.2.2版本,4月17日发布了V1.2.3版本,5月8日发布了V1.2.4版本,还有两个大版本V1.3,V1.4暂未发布,其中V1.3修复了大量的bug,加入了更多的特性。
四、大数据生态圈
Hadoop发布第三个测试版本
2017年5月26日,Apache基金会发布了Hadoop 3.0.0后的又一个Alpha测试版本,这是继2016年9月Hadoop 3.0.0版本第一个测试版本以来的第三个测试版本,是3.0版本线中涉及到安全相关的一个版本,它修复了Alpha2版本以来的一些安全漏洞。用户如果在使用3.0的Alpha1或者Alpha2版本的话,推荐升级到Alpha3版本。
不过需要注意的是,由于是Alpha测试版本,不能够保证运行的质量,以及API的稳定性。所以不建议在立即投入到生产环境中使用。
3.0.0版本的主要更新:
中文内容详见DBAplus Newsletter 2月版。
此次更新主要分成四个部分:
Alpha3版本更新的主要内容如下:
主要涉及了两个安全相关的问题:
YARN-6278 Enforce to use correct node and npm version in new YARN-UI build
https://issues.apache.org/jira/browse/YARN-6278
在新版本的yarn的web UI中,强制使用正确的node和npm的版本。
YARN-6336 Jenkins report YARN new UI build failure
https://issues.apache.org/jira/browse/YARN-6336
在yarn新UI中Jenkins report报错的修复。
HDB (Apache HAWQ) 2.2.0.0版本发布
Pivotal HDB 2.2.0.0企业版于2017年4月正式发布,该版本引入了对Apache Ranger的支持。Apache Ranger可以让用户以统一的接口来管理包括HAWQ在内的Hadoop生态产品的用户授权/审计等操作。基于HAWQ Ranger REST插件,HDB提供了HAWQ和Ranger之间的策略管理集成,让管理员可以方便地通过Ranger来管理不同用户对HAWQ资源的访问权限。
另外该版本中还包含其它的一些重要更新:
PXF开始全面支持ORC文件格式。
Pivotal HDB开始提供RHEL7/CentOS7平台的支持。
在上一个版本基础上进行了77个错误修正和改进。
Druid发布10.0版本
Druid0.10.0包含来自40多位贡献者的100多项性能和稳定性改进以及bug修复。主要的新特性包括内置的SQL层、数值类型维度、Kerberos认证扩展、Index Task的改进、新的“like”过滤器、大列的存储、支持Coordinator和Overlord合并成一个服务、默认参数的性能提升以及8个新扩展。

Druid新增加了使用Apache Calcite驱动的内置SQL层,提供了JDBC和HTTP POST两种方式的SQL API。JDBC方式使开发者轻松地集成已有的应用,但这一版本并不是支持所有的SQL特性,并计划在以后的版本中支持更多的SQL特性。
使用SQL功能,必须先在配置文件中设置druid.sql.enable=true,详细文档参见http://druid.io/docs/0.10.0/querying/sql.html
Druid在查询和数据摄入阶段中支持数值类型维度,用户可以将long和float类型的列作为维度摄入(例如开启rollup以后,在数据摄入阶段把数值类型的列当作分组的key而不是Aggregator)。此外Druid查询可以把任意数值类型的列当成过滤条件或者分组查询的依据。
数值类型和字符类型的列之间有一个性能的权衡,数值类型列在分组聚合(group by查询)要比字符类型列要快,但数值类型列没有索引,所以在fitler过程要比字符类型列要慢。

Druid增加Kerberos认证的扩展,使用户更加轻松使用开启Kerberos认证的Hadoop。
Index Task的改进
Index Task(非使用Hadoop的离线任务)为了提升性能进行了重写,特别针对跨越多个时段生成多个shard的任务,intervals可以自动设定而不再必须设定。但是设定了intervals和numShards可以减少数据摄入的时间。
此外,增加了“appendToExisting”设置允许在当前版本上增加shard,而不是创建版本的Segment覆盖先前版本的。
Druid增加了SQL“like”方式的过滤器,例如 foo like 'boo%'。其实现的性能通常情况下比regx filter性能好,因此建议尽可能地使用like而不是regx。经过实践发现,like过滤器下的前缀过滤,类似foo%,其性能显著地比等价的regx过滤器下的^foo%好。
Druid增加了单个大小超过2G的列存储支持。该特性通常不是必需的,因为在官方文档中推荐Segment的大小为500M~1G。但在某些场景下有用,例如某个列的大小明显大于其他(例如大的sketches)。
该特性对druid内置的列不需要任何配置就可以使用,假设开发自定义的Metric,重写ComplexMetricSerde的getSerialize方法以便开启该特性。
把Overlord合并到Coordinator,可以简化Druid的部署。为此,在coordinator的配置文件中设置druid.coordinator.asOverlord.enabled and druid.coordinator.asOverlord.overlordService成相应的值,然后关掉overlord。
该特性目前是实验性,默认关闭,但考虑在未来的版本中把它作为默认。
在这次的发布版本中修改了两项默认配置以便提升性能:
buildV9Directly,该项配置在0.9.2版本引入,将其默认开启。它可以提升索引的性能,直接构建v9版本,而不是先构建v8然后再转成v9。如有需要,设置成false关闭该功能。
V2 GroupBy查询引擎也是在0.9.2版本引入,将其默认设置为v2。新的查询引擎在查询性能和内存管理方面有改进提升。如果继续想使用老的引擎的话,可以把runtime配置中druid.groupBy.query.defaultStrategy,或者获取查询上下文中的groupByStrategy修改为v1。前者适用所有的查询,后者只适用当前查询。
完整文档详见https://github.com/druid-io/druid/releases/druid-0.10.0
SnappyData发布
GemFire全面升级版本Snappy面世。Snappy将Apache Spark与内存数据库融合,以提供能够在单个集群中处理流,事务和交互式分析的数据引擎。
Snappy是混合工作负载应用程序的高性能内存数据平台。基于Apache Spark,SnappyData为单个集群中的流媒体,事务,机器学习和SQL Analytics提供统一的编程模型。SnappyData将实时数据源与具有Spark连接器的外部数据源进行统一。
SnappyData的环境也比较适合尝试使用Apache Spark新特性。比如Spark 2.0将在今年发布,届时将重构内存管理和流系统,拉取流数据将更加简单。
SnappyData整体架构如下:
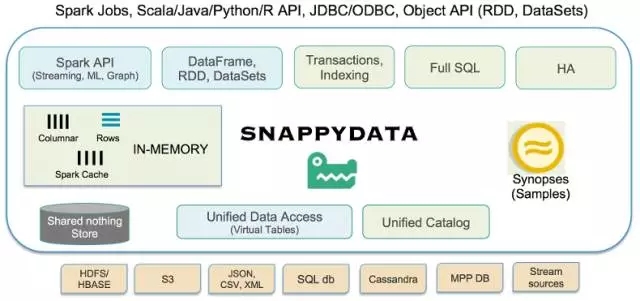

Spark的数据源往往是外部的,比如hdfs.为了更好的响应时间查询不变的数据集,Spark建议将外部数据源中的数据缓存为Spark中的缓存表。
在存储和取回数据方面,SnappyData使用了一个分布式的数据存储,叫做Snappy-Store,起源于GemFire的技术。它要么使用自己的数据存储,要么使用一种异步的回写式高速缓冲存储器连接另一个数据库,比如Hadoop或者HDFS。这意味着,原来的数据可以直接使用SnappyData,而不需要一些正式的数据迁移操作。
优化体现在:
SnappyData的存储层现在允许分区表的并置。
支持计划缓存,以避免查询解析、分析、优化、策略和准备阶段。
列级别统计信息的增强功能允许基于所述范围的批处理。从而大大提升了对这些查询的时间序列数据。
添加了替代哈希聚合和散列连接运算符,它们已经针对SnappyData存储进行了精细优化,以充分利用存储布局与矢量化,字典编码,提供了比Spark的默认实现更多的性能优势。
添加了一个有效的集合版本的Kryo serializer,现在默认使用数据,关闭和较低级别的netty消息。这与前面提到的改进一起,大大减少了短期任务的总体延迟(从近100ms到几ms)。这些还可以减少驱动程序消耗的CPU,从而增强任务的并发性,特别是更短的任务。
Snappy通过与Spark的无缝衔接,可以与不同的数据来源(如Parquet、Hive、JSON / XML文档数据库、NoSQL数据库、关系数据库、流源和文本文件)之间提供高效的加载和同步。
经过测试,SnappyData的性能超过了Apache Spark 12-20倍。
它使用了Apache Spark的内存数据分析引擎,在静态数据和流数据中实时分析SQL。
存储和取回数据方面,SnappyData使用了一个分布式的数据存储,叫做Snappy-Store,起源于GemFire的技术。
SnappyData的核抽象与心编程Spark相同。它将所有数据公开为Spark DataSet或DataFrame(Spark's Resilient Distributed DataSet)。使用这个简单的扩展,Spark可以捕获以前需要单独引擎的各种处理工作负载,包括SQL,流式处理,机器学习和图形处理。
与Spark开发的一致性有几个重要的好处。首先,应用程序由于使用统一的API而更容易开发。第二,组合处理任务更有效;而先前的系统需要将数据写入存储器以将其传递给另一个引擎,Spark可以通常在内存中的相同数据上运行多种功能。
与Spark兼容100% : 使用SnappyData作为数据库,还可以使用任何Spark API --ML,Graph等。
内存中的行和列存储:运行存储在Spark执行程序或其自己的进程空间中的存储(即计算集群和数据集群)。
SQL标准合规性:Spark SQL +几个SQL扩展:DML,DDL,索引,约束。
用于流处理的基于SQL的扩展:使用本机Spark流,DataFrame API或声明式指定流以及您希望处理的流。在并行处理时,您不需要学习Spark API来处理流处理或其细微之处。
不唯一的SQL:使用SQL数据库或使用JSON或甚至任意的应用程序对象。本质上,任何Spark RDD / DataSet也可以持久保存在SnappyData表(类型系统与Spark DataFrames相同)中。
使用概要数据引擎(SDE)的交互式分析:我们通过数据结构(如计数最小草图和分层抽样)介绍多个简介技术,以显着减少内存空间需求,并为分析查询提供真正的交互式速度。这些结构可以由几乎没有统计学背景的开发人员创建和管理,并且可以对运行查询的SQL开发人员完全透明。错误估计器也与简单的机制集成,通过内置的SQL函数来获取错误。
在Spark中对数据进行突变,处理:可以使用SQL在表中插入,更新,删除数据。我们还提供Spark的上下文的扩展,以便您可以在Spark程序中更改数据。SnappyData中的任何表都可视为DataFrames,而无需维护数据的多个副本:在Spark中缓存的RDD,然后在数据存储中单独存储。
优化 - 索引:您可以对RowStore和GemFire SQL优化器进行索引,该优化器会在可用时自动使用内存中的索引。
优化 - 并置:SnappyData实现了几个优化,以提高数据的局部性,并避免对分区数据集上的查询进行混洗数据。所有相关数据可以使用声明式自定义分区策略进行并置(例如,普通共享业务密钥)。当表不能共享公共密钥时,引用数据表可以被建模为复制表。副本总是一致的。
高可用性不仅仅是容错:数据可以立即复制(一次一个或一次一个批处理)到集群中的其他节点。它与基于会员的分布式系统深入集成,以检测和处理故障,即时为HA提供应用程序。
耐用性和恢复性:数据也可以在磁盘上进行管理并自动恢复。用于备份和还原的实用程序是捆绑的。
Data Sources API提供了一种用于在Spark SQL中访问结构化数据的可插拔机制。数据源不仅仅是将数据转换成Spark的简单管道。此API提供的紧密优化器集成意味着在许多情况下,过滤和列处理可以一直推送到数据源。这种集成优化可以大大减少需要处理的数据量,从而可以显着加快处理速度。
Data Sources API的另一个优势在于,它可以让用户以Spark支持的所有语言操作数据,无论数据来源如何。例如,在Scala中实现的数据源可以由pySpark用户使用,无需任何额外的工作。此外,Spark SQL可以使用单一界面轻松加入来自不同数据源的数据。
GPText 2.1版本发布
GPText 是Pivotal公司自主研发的内置Greenplum数据库的全文检索和文本分析引擎。具有易用性,分布式,高可用,可扩展,易维护,模块可定制化等特性。对大数据中非结构化的数据检索能提供毫秒级的响应,同时所支持的全文检索种类和语法非常丰富。
索引数据分布式存放在索引节点上,并复制拷贝提高高可用性。数据索引和检索都通过Greenplum segment 服务器并行实现,支持通用的search,词(term) 相关search,facet聚合search等常见的全文检索场景。
在最新的GPText 2.1 的发布中,我们主要包含了以下更新:
针对Greenplum数据库中分区表(Partition Table)进行了优化。用户不需要为每个分区子表建立各自对应的GPText的索引,而可以共享同一个索引,从而避免了索引过多占用太多的内存资源。检索的时候,用户可以针对特定分区表的集合进行高效检索。同时提供了partition_status和相关的管理脚本对分区表的索引进行支持。
提供了自动化升级工具gptext-upgrade。让用户可以做到一键升级,如果升级过程发生了中断,用户可以重新允许升级程序即可。升级程序会自动检测上次升级的断点,并从断点处重新执行。除此之外,在安装过程中,如果检测到旧版GPText存在,用户也可以选择直接升级。
五、国产数据库概览
GBase 8t、8s发布最新版本
GBase 8t近日发布最新版本V8.7,以下是新功能一览:
(更多内容可参考官网及社区http://www.gbase.cn;http://www.informixchina.net/club/;)
动态共享内存技术
虚处理器技术
磁盘技术

HDR (High availability Data Replication, 高可用性数据复制)
RSS (Remote Standalone Secondary, 远程实时容灾)
SDS (Shared Disk Servers, 共享磁盘数据库集群)
ER (Enterprise Replication, 企业级复制)
监控运行状况
管理高可用功能
日志查看
性能分析
服务器管理
时间序列
内存加速
空间数据库
GBase 8s近日发布最新版本V8.4,以下是新功能一览:
(更多内容可参考官网及社区http://www.gbase.cn;)
完全达到国标(GB/T 20273—2006 信息安全技术 数据库管理系统安全技术要求)第四级的安全模型和安全要求(已通过公安部的等级评测)
监控运行状况
管理高可用功能
日志查看
性能分析
服务器管理
达梦数据库发布最新版本V7.1.5.186
达梦数据库管理系统7.0版本,简称DM7,是采用类Java的虚拟机技术设计的新一代数据库产品。DM7基于成熟的关系数据模型和标准的接口,是一个跨越多种软硬件平台、具有大数据管理与分析能力、高效稳定的数据库管理系统。目前官网最新的可下载版本是V7.1.5.186,近期主要更新包括:
增加操作ASM文件系统的jni接口
改造HUGE表插入功能,大幅提升HUGE表插入性能
支持QT4.X和5.X,可以基于QT直接访问DM7
dmPython驱动支持django的SQL参数占位符
dmfldr语法上支持多字节、十六进制的分隔符和封闭符
扩充并行执行计划适用范围
故障重启redo性能优化
层次查询性能优化
系统视图性能优化
优化distinct操作性能
支持to_char日期时间类型批量优化
提升FAGR操作符并发性能
提升获取分区表模板信息的性能
完善统计信息,使得统计信息更加精确
修复部分已知缺陷
人大金仓发布最新版本V3.1.2
人大金仓新近推出的分析型数据库KingbaseAnalyticsDB(以下简称:KADB)产品,包含大规模并行计算技术和数据库技术最新的研发成果:包括无共享、大规模并行处理技术(MPP)、按列存储数据库、数据库内压缩、MapReduce、在线扩容、多级容错等特点。
KADB提供多种高级语言接口,方便外部应用服务访问,拥有良好的用户交互界面以及检测界面,简单易用,方便管理。
最新版本发布做了如下增强,旨在提高系统的可用性,以及覆盖更多应用场景:
审计功能支持:数据库可以对用户的操作进行审计,同时也提供了SQL命令对审计事件进行配置。数据库会自动将用户的操作事件进入到系统里,审计员可以在合适的时候对审计记录进行查询,确认是否有潜在威胁。
加密支持:数据库提供了SQL命令接口,用户可以通过这些接口定义和扩展数据库所能支持的加密算法。增强了系统的扩展性。
集群在线扩展:KADB数据库增强了数据库扩展功能,在系统处理能力不足的,并且不中当前业务的情况下,对集群数据库进行扩展。
MADlib和R支持:用户可以直接在数据库层面进行统计分析。
与Hadoop交互:KADB数据库可以直接访问Hadoop的数据。
OceanBase发布1.4.2版本
OceanBase 发布1.4.2版本,功能持续完善,性能进一步提升。
实现了转储功能,解决了大量数据导入或更新过程中内存不足的问题。在未实现转储功能前,只能通过每日合并来释放内存,对数据库服务有一定的影响。开启转储功能后,单个ObServer可根据自身的内存使用情况,将memtable中的一个或者多个分区转储到持久化存储中,无需考虑转储的分区是主还是备、也无需考虑主备之间的同步,系统可维护性进一步增强。
层次查询功能。Oracle同款的层次查询功能,在新版本的OceanBase上也可以使用了,进一步简化了Oracle应用迁移到OceanBase的过程。
并行索引创建技术。在单个分区内,也可以并行创建索引了,索引创建时间缩短到原先的近1/4,再也不用因为建索引慢影响每日合并的速度了。
批量数据插入的性能提升一倍。有效提升了大量数据装载的效率和用户体验。
常用表达式编译执行,性能提升10倍。目前编译执行支持add/equal/and/case when等常规表达式,正持续增加支持的表达式和数据类型种类。
星瑞格数据库发布12.10 FC 8版本
星瑞格数据库于近期正式发布SinoDB 12.10 FC 8版本,在最新的12.10 FC 8 release版本中,SinoDB重点针对万物互联物联网应用场景下,数据库的技术支撑特性进行了优化和整合,将适合边缘计算的嵌入式特性、时间序列特性、NoSQL支持特性进行加强,发布的SinoDB 12.10 FC8版本数据库能够满足物联网中所有对数据库的要求。我们知道,ARM在智能手机占有超过95%的市场份额,在平板电脑、机顶盒、网络等各种设备中占有主导性的市场份额。SinoDB支持ARM,是ARM设备中唯一嵌入的企业级数据库。
此外,SinoDB小身材大实用,内存需求小,适合安装在物联网的许多设备中;每千兆字节可以保存上百万的记录;作为一款混合数据库,SinoDB在同一数据库中同时支持JSON/BSON和SQL应用;对时间序列(Time Series)和空间地理(Spatial/GIS)数据提供专门的高性能支持,每秒钟持续加载上百万条记录,分析速度比其它数据库快一个数量级。
SinoDB 12.10 FC 8物联网特性

SinoDB提供基于ARM设备的嵌入式版本,提早布局物联网。
较小的安装包大小(小于100M)以及对运行内存要求不高,可以满足大部分边缘端设备的条件。
高压缩能力减少存储空间。
提供的分析功能可以助力边缘计算实现。
特别支持物联网的时序数据,并提供SQL和NOSQL的应用接口以应对多种多样的应用需求。
不管在ARM设备上还是在服务器端都提供企业级的能力和服务。
过滤或者聚合传感器数据。
本地处理以及现场决策。
降低处理时延,减少云平台网络带宽以及存储成本。
80%的简单操作可以本地完成。
更安全地完成实时计算。
动态数据实时分析。
部署工具支持:为完成配置和调优的SinoDB数据库以及实例创建镜像,然后简单的复制部署到其他环境中。
SQL Admin API:应用程序可以通过SQL接口来执行DBA的任务,可以通过编程的方式自主调控数据库。
预定义的DB定时任务:可以用来完成重要的DBA任务,比如自动统计信息评估和刷新。
预先设置的事件告警:极大地减少了应用程序去监控系统状况的开销,并能够对相应的事件做出响应。
时间序列介绍
众多的系统产生大量时间特性数据:
数据按时间有序排列。
例如股票交易、智能电表、网络设备、智能设备等。
时间序列数据的特点:
数据是依时间轴变化的,数据具有时间先后顺序。
需要对数据按时间维度进行查询和分析。
单个设备所有的数据存储在一行中,数据在行末尾进行追加(append)。
数据无需索引, 只需在设备ID字段上创建索引。
按设备ID进行聚集存储在磁盘上,同时按时间顺序进行管理。
设备ID只需存储一次,而不是每一个记录都存储设备ID。
磁盘上不存储时间戳(Timestamps),而是时间序列的相对偏移位置值。
数据缺失点使用占位符标记。
更少的存储空间。
比传统的存储方式减少2/3的空间。
更快的执行效率。
独特的存储优化技术提高了单位内存中的数据量,进而提高了执行效率。
专门定制的传感器数据流自动装载。
自动定期装载传感器数据并执行分析和聚合算法。
同时支持SQL和NOSQL的数据存储。
支持REST/ODBC/JDBC/JSON 等应用接口。
预定义了100多个时序数据处理函数。
更便利地让应用构建自己的数据分析逻辑。
NoSQL - Not Only SQL
什么是NoSQL
NoSQL,指的是非关系型的数据库。是对不同于传统的关系型数据库的数据库管理 系统的统称。NoSQL用于超大规模数据的存储。这些类型的数据存储不需要固定的 模式,无需多余操作就可以横向扩展。
为什么使用NoSQL
用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍 的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了,NoSQL数据库的发展也却能很好的处理这些大的数据。
RDBMS vs NoSQL
|
RDBMS |
NOSQL |
|
|
数据格式 |
高度组织化结构化数据 |
没有预定义的模式 |
|
查询语言 |
结构化查询语言(SQL) |
没有声明性查询语言 |
|
存储方式 |
数据和关系都存储在单独的表中 |
键 - 值对存储,列存储,文档存储,图形数据库 |
|
一致性 |
严格的一致性 |
最终一致性,而非ACID属性 |
SinoDB可以同时在同一个数据库中处理结构化和非结构化数据产品。
将你设备的元数据存储为JSON(例如:制造业)。
将设备的历史数据存储为时间序列数据(例如:温度)。
SinoDB同时处理结构化和非结构化数据。
允许SQL应用访问非结构化数据,允许Mongo应用访问结构化数据。
结构化和非结构化数据可以同时在一个查询中应用。
“展示由制造商X制造的传感器在1月1日到2月1日的所有温度数据”。
REST客户端可以发送任何程序的HTTP请求来访问SinoDB的数据。
开发者可以使用MongoDB驱动编写MongoDB应用访问数据。
支持SQLI、DRDA 协议、NoSQL与SQL的互译,可以访问关系型表、MongoDB集合以及时间序列数据。
推出DBAplus Newsletter的想法
DBAplus Newsletter旨在向广大技术爱好者提供数据库行业的最新技术发展趋势,为社区的技术发展提供一个统一的发声平台。为此,我们策划了RDBMS、NoSQL、NewSQL、大数据、虚拟化、国产数据库等几个版块。
我们不以商业宣传为目的,不接受任何商业广告宣传,严格审查信息源的可信度和准确性,力争为大家提供一个纯净的技术学习环境,欢迎大家监督指正。
至于Newsletter发布的周期,目前计划是每两个月左右会做一次跟进,下期计划时间是2017年8月14日~8月25日,如果有相关的信息提供请发送至邮箱:newsletter@dbaplus.cn ,或扫描以下二维码填表申请加入“Newsletter信息征集群”。

↑ 扫码填写申请表 ↑
通过审核后群秘邀你入群
感谢名单
最后要感谢那些提供宝贵信息和建议的专家朋友,排名不分先后。










如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721