
作者介绍
陈华军,苏宁云商IT总部资深技术经理,从事数据库服务相关的开发和维护工作,之前曾长期从事富士通关系数据库的开发,PostgreSQL中国用户会核心成员,熟悉PostgreSQL和MySQL。
前言
GTID(Global Transaction ID)是MySQL5.6引入的功能,可以在集群全局范围标识事务,用于取代过去通过binlog文件偏移量定位复制位置的传统方式。借助GTID,在发生主备切换的情况下,MySQL的其它Slave可以自动在新主上找到正确的复制位置,这大大简化了复杂复制拓扑下集群的维护,也减少了人为设置复制位置发生误操作的风险。另外,基于GTID的复制可以忽略已经执行过的事务,减少了数据发生不一致的风险。
GTID虽好,要想运用自如还需充分了解其原理与特性,特别要注意与传统的基于binlog文件偏移量复制方式不一样的地方。本文概述了关于GTID的几个常见问题,希望能对理解和使用基于GTID的复制有所帮助。
GTID长什么样
根据官方文档定义,GTID由source_id加transaction_id构成。
GTID = source_id:transaction_id
上面的source_id指示发起事务的MySQL实例,值为该实例的server_uuid。server_uuid由MySQL在第一次启动时自动生成并被持久化到auto.cnf文件里,transaction_id是MySQL实例上执行的事务序号,从1开始递增。 例如:
e6954592-8dba-11e6-af0e-fa163e1cf111:1
一组连续的事务可以用'-'连接的事务序号范围表示。例如
e6954592-8dba-11e6-af0e-fa163e1cf111:1-5
更一般的情况是GTID的集合。GTID集合可以包含来自多个source_id的事务,它们之间用逗号分隔;如果来自同一source_id的事务序号有多个范围区间,各组范围之间用冒号分隔,例如:
e6954592-8dba-11e6-af0e-fa163e1cf111:1-5:11-18,
e6954592-8dba-11e6-af0e-fa163e1cf3f2:1-27
即,GTID集合拥有如下的形式定义:
gtid_set:
uuid_set [, uuid_set] ...
| ''
uuid_set:
uuid:interval[:interval]...
uuid:
hhhhhhhh-hhhh-hhhh-hhhh-hhhhhhhhhhhh
h:
[0-9|A-F]
interval:
n[-n]
(n >= 1)
如何查看GTID
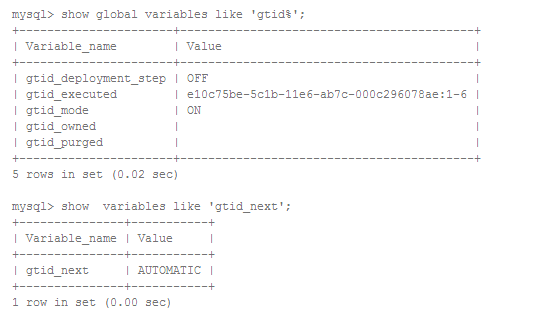
可以通过MySQL的几个变量查看相关的GTID信息。
gtid_executed
在当前实例上执行过的GTID集合; 实际上包含了所有记录到binlog中的事务。所以,设置set sql_log_bin=0后执行的事务不会生成binlog 事件,也不会被记录到gtid_executed中。执行RESET MASTER可以将该变量置空。
gtid_purged
binlog不可能永远驻留在服务上,需要定期进行清理(通过expire_logs_days可以控制定期清理间隔),否则迟早它会把磁盘用尽。gtid_purged用于记录已经被清除了的binlog事务集合,它是gtid_executed的子集。只有gtid_executed为空时才能手动设置该变量,此时会同时更新gtid_executed为和gtid_purged相同的值。gtid_executed为空意味着要么之前没有启动过基于GTID的复制,要么执行过RESET MASTER。执行RESET MASTER时同样也会把gtid_purged置空,即始终保持gtid_purged是gtid_executed的子集。
gtid_next
会话级变量,指示如何产生下一个GTID。可能的取值如下:
1)AUTOMATIC:
自动生成下一个GTID,实现上是分配一个当前实例上尚未执行过的序号最小的GTID。
2)ANONYMOUS:
设置后执行事务不会产生GTID。
3)显式指定的GTID:
可以指定任意形式合法的GTID值,但不能是当前gtid_executed中的已经包含的GTID,否则,下次执行事务时会报错。
这些变量可以通过show命令查看,比如:
如何产生GTID
GTID的生成受gtid_next控制。 在Master上,gtid_next是默认的AUTOMATIC,即在每次事务提交时自动生成新的GTID。它从当前已执行的GTID集合(即gtid_executed)中,找一个大于0的未使用的最小值作为下个事务GTID。同时在binlog的实际的更新事务事件前面插入一条set gtid_next事件。
以下是一条insert语句生成的binlog记录:
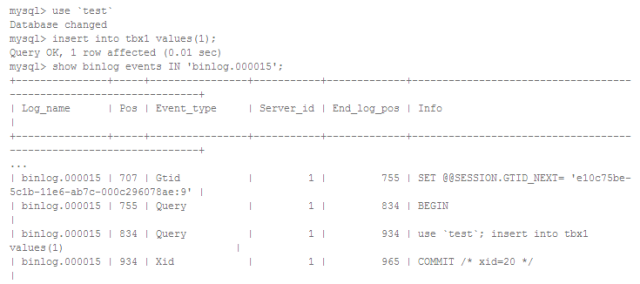
在Slave上回放主库的binlog时,先执行set gtid_next ...,然后再执行真正的insert语句,确保在主和备上这条insert对应于相同的GTID。
一般情况下,GTID集合是连续的,但使用多线程复制(MTS)以及通过gtid_next进行人工干预时会导致gtid空洞。比如下面这样:
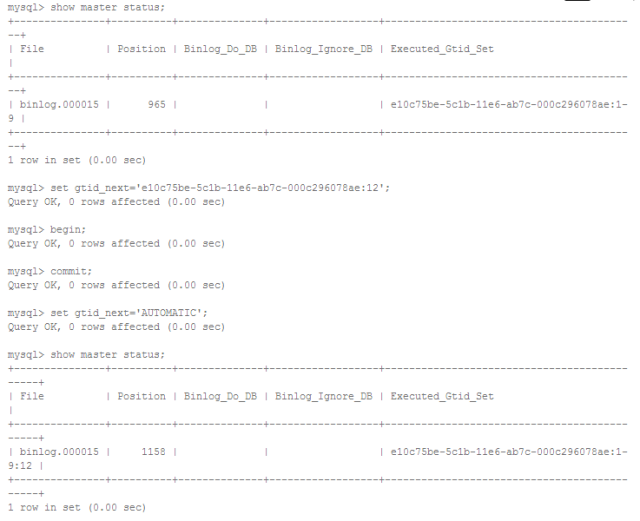
继续执行事务,MySQL会分配一个最小的未使用GTID,也就是从出现空洞的地方分配GTID,最终会把空洞填上。

这意味着严格来说我们即不能假设GTID集合是连续的,也不能假定GTID序号大的事务在GTID序号小的事务之后执行,事务的顺序应由事务记录在binlog中的先后顺序决定。
GTID的持久化
GTID相关的信息存储在binlog文件中,为此MySQL5.6新增了下面2个binlog事件。
Previous_gtids_log_event 在每个binlog文件的开头部分,记录在该binlog文件之前已执行的GTID集合。
Gtid_log_event 即前面看到的set gtid_next ...,它出现在每个事务的前面,表明下一个事务的gtid。
示例如下:

MySQL服务器启动时,通过读binlog文件,初始化gtid_executed和gtid_purged,使它们的值能和上次MySQL运行时一致。
gtid_executed被设置为最新的binlog文件中Previous_gtids_log_event和所有Gtid_log_event的并集。
gtid_purged为最老的binlog文件中Previous_gtids_log_event。
由于这两个重要的变量值记录在binlog中,所以开启gtid_mode时必须同时在主库上开启log_bin在备库上开启log_slave_updates。
但是,在MySQL5.7中没有这个限制。MySQL5.7中,新增加一个系统表mysql.gtid_executed用于持久化已执行的GTID集合。当主库上没有开启log_bin或在备库上没有开启log_slave_updates时,mysql.gtid_executed会跟用户事务一起每次更新。否则只在binlog日志发生rotation时更新mysql.gtid_executed。
如何配置基于GTID的复制
MySQL服务器的my.cnf配置文件中增加GTID相关的参数
log_bin = /mysql/binlog/mysql_bin
log_slave_updates = true
gtid_mode = ON
enforce_gtid_consistency = true
relay_log_info_repository = TABLE
relay_log_recovery = ON
然后在Slave上指定MASTER_AUTO_POSITION = 1执行CHANGE MASTER TO即可。比如:
CHANGE MASTER TO MASTER_HOST='node1',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_AUTO_POSITION=1;
基于GTID的复制如何工作
在MASTER_AUTO_POSITION = 1的情况下 ,MySQL会使用 COM_BINLOG_DUMP_GTID 协议进行复制。过程如下:
备库发起复制连接时,将自己的已接受和已执行的gtids的并集(后面称为slave_gtid_executed)发送给主库。即下面的集合:
UNION(@@global.gtid_executed, Retrieved_gtid_set - last_received_GTID)
主库将自己的gtid_executed与slave_gtid_executed的差集的binlog发送给Slave。主库的binlog dump过程如下:
检查slave_gtid_executed是否是主库gtid_executed的子集,如否那么主备数据可能不一致,报错。
检查主库的purged_executed是否是slave_gtid_executed的子集,如否代表缺失备库需要的binlog,报错
从最后一个Binlog开始扫描,获取文件头部的PREVIOUS_GTIDS_LOG_EVENT,如果它是slave_gtid_executed的子集,则这是需要发送给Slave的第一个binlog文件,否则继续向前扫描。
从第3步找到的binlog文件的开头读取binlog记录,判断binlog记录是否已被包含在slave_gtid_executed中,如果已包含跳过不发送。
从上面的过程可知,在指定MASTER_AUTO_POSITION = 1时,Master发送哪些binlog记录给Slave,取决于Slave的gtid_executed和Retrieved_Gtid_Set以及Master的gtid_executed,和relay_log_info以及master_log_info中保存的复制位点没有关系。
如何修复复制错误
在基于GTID的复制拓扑中,要想修复Slave的SQL线程错误,过去的SQL_SLAVE_SKIP_COUNTER方式不再适用。需要通过设置gtid_next或gtid_purged完成,当然前提是已经确保主从数据一致,仅仅需要跳过复制错误让复制继续下去。比如下面的场景:
在从库上创建表tb1
mysql> set sql_log_bin=0;
Query OK, 0 rows affected (0.00 sec)
mysql> create table tb1(id int primary key,c1 int);
Query OK, 0 rows affected (1.06 sec)
mysql> set sql_log_bin=1;
Query OK, 0 rows affected (0.00 sec)
在主库上创建表tb1:
mysql> create table tb1(id int primary key,c1 int);
Query OK, 0 rows affected (1.06 sec)
由于从库上这个表已经存在,从库的复制SQL线程出错停止。

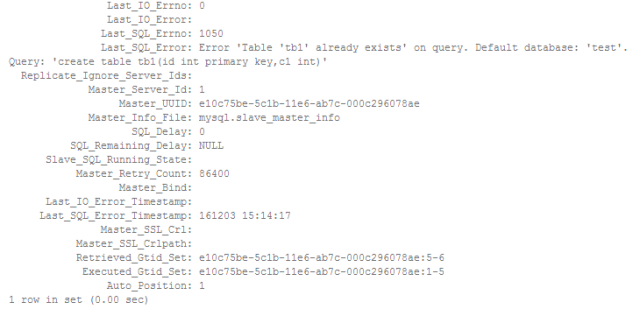
上面的输出可以知道,从库已经执行过的事务是'e10c75be-5c1b-11e6-ab7c-000c296078ae:1-5',执行出错的事务是'e10c75be-5c1b-11e6-ab7c-000c296078ae:6',当前主备的数据其实是一致的,可以通过设置gtid_next跳过这个出错的事务。
在从库上执行以下SQL:
mysql> set gtid_next='e10c75be-5c1b-11e6-ab7c-000c296078ae:6';
Query OK, 0 rows affected (0.00 sec)
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> set gtid_next='AUTOMATIC';
Query OK, 0 rows affected (0.00 sec)
mysql> start slave;
Query OK, 0 rows affected (0.02 sec)
设置gtid_next的方法一次只能跳过一个事务,要批量的跳过事务可以通过设置gtid_purged完成。假设下面的场景:
主库上已执行的事务
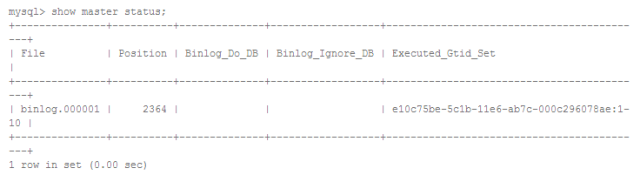
从库上已执行的事务
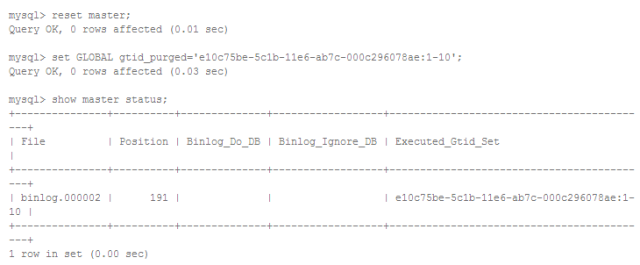
假设经过修复从库已经和主库的数据一致了,但由于复制错误Slave的SQL线程依然处于停止状态。现在可以通过把从库的gtid_purged设置为和主库的gtid_executed一样跳过不一致的GTID使复制继续下去,步骤如下。
在从库上执行
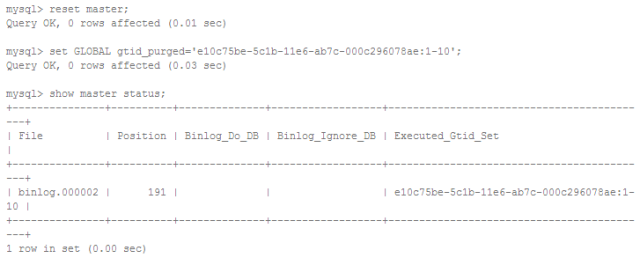
此时从库的Executed_Gtid_Set已经包含了主库上'1-10'的事务,再开启复制会从后面的事务开始执行,就不会出错了。
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)
使用gtid_next和gtid_purged修复复制错误的前提是,跳过那些事务后仍可以确保主备数据一致。如果做不到,就要考虑pt-table-sync或者拉备份的方式了。
GTID与备份恢复
在做备份恢复的时候,有时需要恢复出来的MySQL实例可以作为Slave连上原来的主库继续复制,这就要求从备份恢复出来的MySQL实例拥有和数据一致的gtid_executed值。这也是通过设置gtid_purged实现的,下面看下mysqldump做备份的例子。
通过mysqldump做一个全量备份:
[root@node1 ~]# mysqldump --all-databases --single-transaction --routines --events --host=127.0.0.1 --port=3306 --user=root > dump.sql
生成的dump.sql文件里包含了设置gtid_purged的语句
SET @MYSQLDUMP_TEMP_LOG_BIN = @@SESSION.SQL_LOG_BIN;
SET @@SESSION.SQL_LOG_BIN= 0;
...
SET @@GLOBAL.GTID_PURGED='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10';
...
SET @@SESSION.SQL_LOG_BIN = @MYSQLDUMP_TEMP_LOG_BIN;
恢复数据前需要先通过reset master清空gtid_executed变量
[root@node2 ~]# mysql -h127.1 -e 'reset master'
[root@node2 ~]# mysql -h127.1 <dump.sql
否则执行设置GTID_PURGED的SQL时会报下面的错误
ERROR 1840 (HY000) at line 24: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty.
此时恢复出的MySQL实例的GTID_EXECUTED和备份时点一致:
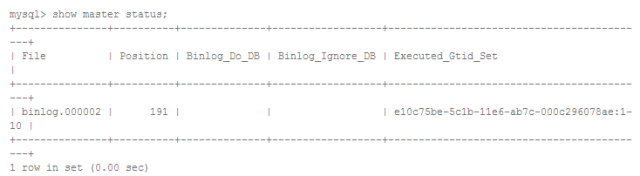
由于恢复出的MySQL实例已经被设置了正确的GTID_EXECUTED,以master_auto_postion = 1的方式CHANGE MASTER到原来的主节点即可开始复制。
CHANGE MASTER TO MASTER_HOST='node1', MASTER_USER='repl', MASTER_PASSWORD='repl', MASTER_AUTO_POSITION = 1
如果不希望备份文件中生成设置GTID_PURGED的SQL,可以给mysqldump传入--set-gtid-purged=OFF关闭。
2、通过Xtrabackup进行备份
相比mysqldump,Xtrabackup是效率更高并且被广泛使用的备份方式。使用Xtrabackup进行备份的举例如下。
通过Xtrabackup创一个全量备份(可以在Slave上创建备份,以避免对主库的性能冲击)
innobackupex --defaults-file=/etc/my.cnf --host=127.1 --user=root --password=mysql --no-timestamp --safe-slave-backup --slave-info /mysql/bak
应用日志
innobackupex --apply-log /mysql/bak
查看备份目录中的xtrabackup_binlog_info文件可以找到备份时已经执行过的gtids
[root@node2 ~]# cat /mysql/bak/xtrabackup_binlog_info
mysql_bin.000001 191 e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10
由于备份时添加了”--slave-info”选项并且从Slave节点拉取的备份,所以会生成xtrabackup_slave_info文件,也可以从这个文件里查找建立复制的SQL语句。
[root@node2 ~]# cat /mysql/bak/xtrabackup_slave_info
SET GLOBAL gtid_purged='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10';
CHANGE MASTER TO MASTER_AUTO_POSITION=1
将备份文件传送到新的节点node3的/mysql/bak目录并恢复(如果直接把备份传输到数据目录了,这一步可以省略)。
[root@node3 ~]# innobackupex --defaults-file=/etc/my.cnf --copy-back /mysql/bak
启动MySQL。
[root@node3 ~]# mysqld --defaults-file=/home/mysql/etc/my.cnf --skip-slave-start &
如果是从Slave拉的备份,一定不能直接开启Slave复制,这时的gtid_executed是错误的。需要手动设置gtid_purged后再start slave
MASTER_HOST='node1',MASTER_USER='repl',MASTER_PASSWORD='repl',MASTER_AUTO_POSITION=1;
start slave;
GTID与MHA
MHA是被广泛使用MySQL HA组件,MHA 0.56以后支持基于GTID的复制。 MHA在failover时会自动判断是否是GTID based failover,需要满足下面3个条件即为GTID based failover
所有节点gtid_mode=1
所有节点Executed_Gtid_Set不为空
至少一个节点Auto_Position=1
和之前的基于binlog文件位置的复制相比,基于GTID复制下,MHA在故障切换时的变化主要如下:
基于binlog文件位置的复制
在Master宕机后会尝试从Master上拷贝binlog日志进行补偿
如果候选Master不拥有最新的relay log,会从拥有最新relay log的Slave上生成差异的binlog传送到候选Master并实施补偿
新Master的日志补偿完成后,同样采用应用差异binlog的方式将其它Slave和新Master同步后再change master到新Master
基于GTID的复制
如果候选Master不拥有最新的relay log,让候选Master连上拥有最新relay log的Salve进行补偿。
尝试从binlog server上拉取缺失的binlog并应用
新Master的数据同步到最新后,让其它的Slave连上新Master并等待数据完成同步。并且可以给masterha_master_switch传入--wait_until_gtid_in_sync=1参数使其不等其它Slave完成数据同步,以加快切换速度。
GTID模式下MHA不会尝试从旧Master上拷贝binlog日志进行补偿,所以在MySQL进程crash而OS仍然健康的情况下,应尽量不要做主备切换而是原地重启MySQL,除非有其它能确保切换后不丢数据的措施。
在GTID模式下MHA支持在复制拓扑中增加一个或多个binlog server起到日志补偿的作用,非GTID模式下即使配置了binlog server也会被MHA忽略。
日志补偿可以说是MHA中最复杂也最精华的部分,有了GTID后故障切换变得更简单了,不再需要原本复杂的binlog日志解析和补偿。所以Oracle官方推出了只支持GTID复制的切换工具mysqlfailover,在GTID的帮助下,我们有更多靠谱的HA工具可以选择。
GTID与crash safe salve
crash safe slave是MySQL 5.6提供的功能,意思是说在slave crash后,把slave重新拉起来可以继续从Master进行复制,不会出现复制错误也不会出现数据不一致。
1、基于binlog文件位置的复制
在基于binlog文件位置的复制下,要保证crash safe slave,配置下面的参数即可。
relay_log_info_repository = TABLE
relay_log_recovery = ON
这样可行的原因是,relay_log_info_repository = TABLE时,apply event和更新relay_log_info表的操作被包含在同一个事务里,innodb要么让它们同时生效,要么同时不生效,保证位点信息和已经应用的事务精确匹配。同时relay_log_recovery = ON时,会抛弃master_log_info中记录的复制位点,根据relay_log_info的执行位置重新从Master获取binlog,这就回避了由于未同步刷盘导致的binlog文件接受位置和实际不一致以及relay log文件被截断的问题。
在同时使用MTS(multi-threaded slave)时,为保证crash safe slave基于binlog文件位置的复制还需要设置sync_relay_log=1,因为MySQL在Crash恢复时必须先通过读取relay log补齐MTS导致的事务空洞。
2、基于GTID的复制
上面的设置并不适用于基于GTID的复制。在基于GTID的复制下,crash的Slave重启后,从binlog中解析的gtid_executed决定了要apply哪些binlog记录,所以binlog必须和innodb存储引擎的数据保持一致。要做到这一点,需要把sync_binlog和innodb_flush_log_at_trx_commit都设置为1,即所谓的"双1"。
另外MySQL启动时,会从relay log文件中获取已接收的GTIDs并更新Retrieved_Gtid_Set。由于relay log文件可能不完整,所以需要抛弃已接收的relay log文件。因此relay_log_recovery = ON也是必须的。
这样,对于基于GTID的复制,保证crash safe slave的设置就是下面这样。
sync_binlog = 1
innodb_flush_log_at_trx_commit = 1
relay_log_recovery = ON
关于如何设置以确保crash safe slave,官方文档有明确记载,见 17.3.2 Handling an Unexpected Halt of a Replication Slave。
但是其中关于GTID的记载中存在笔误,将relay_log_recovery=1写成了relay_log_recovery=0 (#83711)。同时也没有提到必须设置"双1",但是"双1"是必要的,否则crash的Slave重启后,可能会重复应用binlog event也可能会遗漏应用binlog event(#70659)。其中遗漏应用binlog event的情况更可怕,因为Slave在不触发SQL错误的情况下就默默的和Master不一致了。
3、设置"双1"对性能的影响
出于安全考虑,强烈推荐设置"双1"。"双1"会增大每个事务的RT,但得益于MySQL的组提交机制,高并发下"双1"对系统整体tps的影响在可接受范围内。
sysbench oltp.lua 10张表每张表100w记录(qps/并发数)
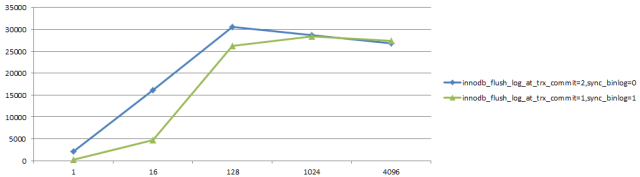
对更新同一行这样无法有效并行的场景,"双1"对性能的影响非常大。
sysbench update_non_index.lua 1张表1条记录(qps/并发数)

对不能有效并行的Slave replay,存在同样的问题。
通过指定tx-rate执行sysbench的update_non_index.lua脚本压测30秒,完成后检查主备延迟。
可以发现在Slave被配置为"双1"的情况下,延迟非常严重,1000以上的QPS就会出现延迟,非"双1"下QPS到5000以上才会出现延迟(主库配置为"双1")。
sysbench update_non_index.lua 1张表100w条记录 128并发(延迟/qps)

以上测试环境是Percona Server 5.6运行在配置HDD的8 core虚机,由于测试结果和系统IO能力有很大关系,仅供参考。
4、如何在非"双1"下保证crash safe slave
如果是MySQL 5.7可以关闭log_slave_updates,这样MySQL会将已执行的GTIDs实时记录到系统表mysql.gtid_executed中,mysql.gtid_executed是和用户事务一起提交的,因此可以保证和实际的数据一致。
log_slave_updates = OFF
relay_log_recovery = ON
如果是MySQL 5.6可以采用如下变通的方式。
按照基于binlog文件复制时crash safe slave的要求设置relay_log_info_repository = TABLE
relay_log_info_repository = TABLE
relay_log_recovery = ON
在Slave crash后,根据relay_log_info_repository设置相应的gitd_purged再开启复制,步骤如下。
1.启动MySQL,但不开启复制
mysqld --skip-slave-start
2.在Slave上修改为基于binlog文件位置的复制
3.启动slave IO线程
这里不能启动SQL线程,如果接受到的GTID已经在Slave的gtid_executed里了,会被Slave skip掉。
4.检查binlog传输的开始位置(即Retrieved_Gtid_Set的值)
假设输出的Retrieved_Gtid_Set值为e10c75be-5c1b-11e6-ab7c-000c296078ae:7-10
5.在Master上检查gtid_executed
假设输出的Executed_Gtid_Set值为e10c75be-5c1b-11e6-ab7c-000c296078ae:1-10
6.在Slave上设置gitd_purged为binlog传输位置的前面的GTID的集合
reset master;
set global gitd_purged='e10c75be-5c1b-11e6-ab7c-000c296078ae:1-6';
7.修改回auto position的复制
8.启动slave SQL线程
但是,这种变通的方法不适合多线程复制。因为多线程复制可能产生gtid gap和Gap-free low-watermark position,这会导致Salve上重复apply已经apply过的event。后果就是数据不一致或者复制中断,除非设置binlog格式为row模式并且slave_exec_mode=IDEMPOTENT,slave_exec_mode=IDEMPOTENT允许Slave回放binlog时忽略重复键和找不到键的错误,使得binlog回放具有幂等性,但这也意味着如果真的出现了主备数据不一致也会被它忽略。
5、MTS下特有的问题
在同时使用MTS(slave_parallel_workers > 1)时,即使按上面crash safe slave的要求设置了基于GTID的复制,Slave crash后再重启还是会导致复制中断。
通过强制杀掉MySQL所在虚机的方式模拟Slave宕机,然后再启动MySQL,MySQL日志中有如下错误消息:

启动slave时也会报错
mysql> start slave;
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
出现这种现象的原因在于,relay_log_recovery=1 且 slave_parallel_workers>1的情况下,mysql启动时会进入MTS Group恢复流程,即读取relay log,尝试填补由于多线程复制导致的gap。然后relay log文件由于不是实时刷新的,在relay log文件中找不到gap对应的relay log记录(覆盖了gap的relay log起始和结束位置分别被称为低水位和高水位,低水位点即slave_relay_log_info.Relay_log_pos的值)就会报这个错。
实际上,在GTID模式下,slave在apply event的时候可以跳过重复事件,所以可以安全的从低水位点应用日志,没必要解析relay log文件。 这看上去是一个bug,于是提交了一个bug报告#83713,目前还没有收到回复。
作为回避方法,可以通过清除relay log文件,跳过这个错误。执行步骤如下:
reset slave;
change master to MASTER_AUTO_POSITION = 1
start slave;
在这里,单纯的调reset slave不能把状态清理干净,内部的Relay_log_info.inited标志位仍然处于未被初始化状态,此时调用start slave仍然会失败。因此需要补一刀change master。
6、Master的crash safe
前面一直在讲crash safe slave,Master的crash safe同样重要。 要想Master保持crash safe需要按下面的参数进行设置,否则不仅会丢失事务,gtid_executed还可能和实际的innodb存储引擎中的数据不一致。
sync_binlog = 1
innodb_flush_log_at_trx_commit = 1
在Master配置为"双1"的情况下,Master crash后,如果没有发生failover,可以继续作为Master。 如果发生了failover,可以检查旧Master和新Master上由旧Master执行的事务集合是否一致。
show master status
如果一致,可以按MASTER_AUTO_POSITION = 1的方式将旧Master作为Slave和新Master建立复制关系。否则,考虑做事务补偿或从新Master上拉取备份进行恢复。
在Master配置不是"双1"的情况下,在Master crash后由于难以准确知道旧Master上究竟执行了哪些事务,安全的做法是实施主备切换,并从新Master上拉取备份,把旧Master作为新Master的Slave进行恢复。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721