
作者介绍
高强,DBAplus社群联合发起人,开源技术专家。擅长MySQL、PostgreSQL等产品的实施、运维和故障处理。曾参与多个省级政府单位项目的实施和运维工作,具有丰富的运维经验。
关于MySQL主从复制
复制技术顾名思义,就是通过数据库的复制技术以一份数据为主,复制成另一份存放,数据来源的那一份做为主库,存放复制数据的的称为从库。MySQL的复制方案有很多,比如主从复制、半同步复制、多主还有主主复制等。基本都是是通过把主库的操作写入二进制日志,将二进制日志传送到从库并且重演日志中记录的操作跟进主库状态以便达到在从库数据同步的效果。
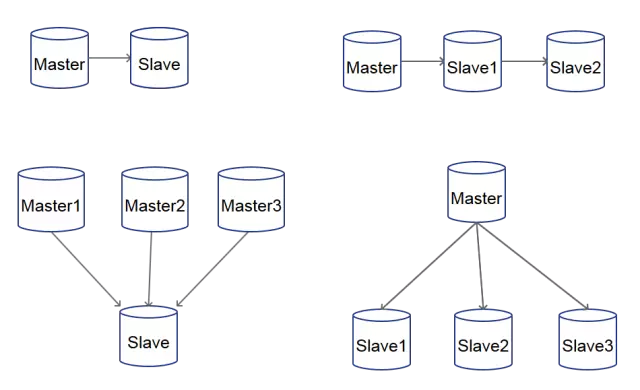
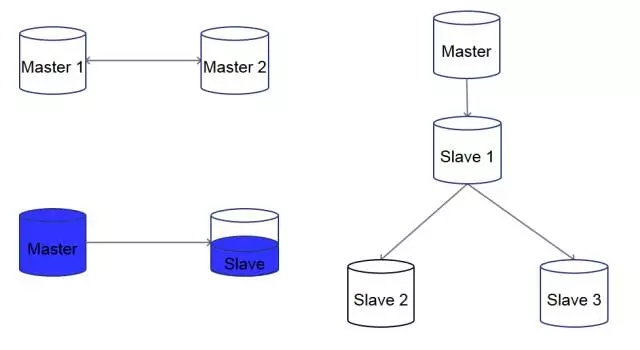
其中,主从复制可以变换、扩展出很多的组合方法,比如多源复制(多台master将数据发送到1台数据库)、1主多从或者还有从服务器再延伸出从服务器。
下面列举一些数据库主从复制架构:
注:主库为Master(1,2,..,N),从库为Slave(1,2,...,N)。
主从复制有如下一些优势:
分担负载:对业务进行读写分离,减轻主库I/O负载,将部分压力分担到从库上,缩短客户查询响应时间。
增加健壮性:在主库出现问题时,可通过多种方案将从库设置为主库,替换主库支撑业务,缩短停机窗口。
有利备份:在从库上备份,即不影响主库的事务,也不影响主库性能和磁盘空间。
查询分析:从库可以作为统计、报表等数据分析工作所使用的的OLAP库。
异地备份:将从库放置在异地可作为异地数据同步备份所用。
从MySQL的5.7版本开始支持多源主从复制技术(Multi-Source Replication),就是将多个数据库(Master)的数据集中发送到1台从库(Slave)上,该技术也具有刚才上文提到的主从复制的优势,除了这些,它的独特性还在于:
汇聚数据:尤其是在分库分表的一些场景中,数据集中统计分析操作可以在1台从库服务器上实现。
节省成本:数据集中存放可避免服务器等软硬件资源浪费,5.7之前1主1从或者1主多从的方案需要为每个主机都安置一台备机;5.7推出多源复制之后,可以将多个从库进行合并,至于是合并存放在高端还是低端服务器上,取决于分析、统计等业务在整体业务中的优先级、繁忙程度等因素。
集中备份:方便在一台服务器备份所有已收到的数据库数据。
异地灾备:将从库放在距离远的地方,可用于异地备份项目。
基本的1主1从复制实现过程
下面咱们先循序渐进简单了解一下基本的1主1从(1 master,1 slave)复制的实现过程:
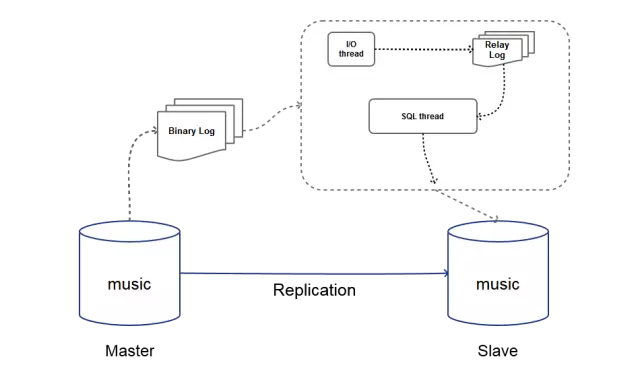
图中Master为主库的主机名,Slave为从库主机名。同步的数据库名为Music。从库接收主库(binlog dump线程)发过来的Binary Log,通过从库的I/O线程(I/O thread)将日志写入从库的Relay Log中,然后通过SQL线程(SQL thread)将日志的内容应用到从库中。
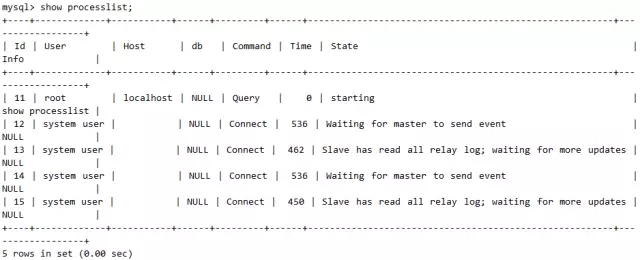
在从库上通过命令可以看到2个必备进程(I/O thread和SQL thread)在待命状态,线程状态如下:

线程的功能主要通过state字段确认:
I/O线程:
Waiting for master to send event
SQL(Coordinator)线程:
Slave has read all relay log; waiting for more updates
开启并发后还会有以下线程:
Worker线程:
Waiting for an event from Coordinator
多源复制的实现与1主1从的类似,都是发送二进制日志再重演,但是在SQL线程(SQL thread)上有略微区别,会为每个主库实例提供一套SQL和IO线程:
配置多源复制的操作方法
多源复制的配置比较简单:
stop slave;
SET GLOBAL master_info_repository = 'TABLE';
SET GLOBAL relay_log_info_repository = 'TABLE';
change master to master_host='192.168.5.160',master_user='slave1',master_password='gaoqiang' for channel 'master1';
change master to master_host='192.168.5.163',master_user='slave1',master_password='gaoqiang' for channel 'master2';
start slave;

图中使用了2个主库:music和habit,假设music存放音乐的歌手、名称和其他信息,habit保存了用户的偶像、最喜欢的歌、常听的歌、播放高峰时间段和地理位置信息的话,汇聚到从库便可即实现了经济实惠的从库端分库合并又实现了统一做用户行为分析,还可以用一条mysqldump命令加个--all-databases参数全部导出做备份。
考虑到多源复制运行过程中,一台从库要接受多方的数据,相比压力会比单库复制有所提升,因此需要优化一下从库配置,从而提升从库执行效率。
性能提升利器——并行复制
接下来要说的就是:性能提升利器——并行复制。为了提高SQL线程(SQL thread)的执行效率,减少主库与从库之间的延迟,MySQL提供了并行复制的特性,可以将事务在从库上多线程并发的回放应用,从而达到加速同步速度的效果。
需要注意的是,使用过程中还是有一些问题需要稍加留意,如果设置不当,反而可能会画蛇添足。
就拿性能来说,并不是并发开的越高越好,并发开的过高和过低,都可能带来负面性能影响,比如引起Coordinator的判断、分发等处理过程开销升高,使用Sysbench进行压力测试的过程中,该开销升高症状体现在CPU消耗高。可能在不同的环境和业务场景下都会有相应的反应,需要量体裁衣、因地制宜。
下图为1主1从SQL线程并行复制回放过程:
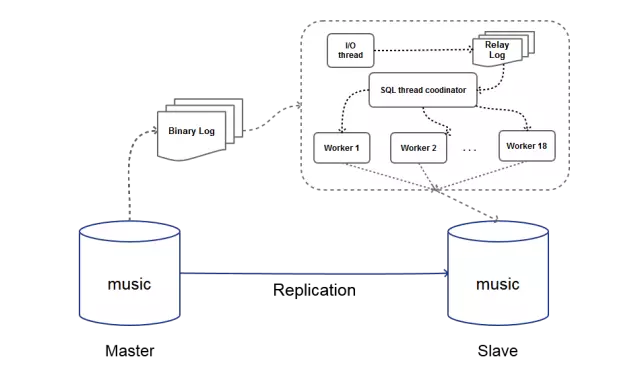
图2中,SQL线程(SQL thread)由原来的1个,分裂变成了1个Coordinator和N个worker。Coordinator主要用来分发工作给不同的worker,并且在必要时自己也进行重演操作。图中分了18个并行,即18个worker并行工作。他们负责并行的将日志中可以划分成一组的事务进行并行回放。
在把事务应用到从库的时候,根据binary log中last_committed(需设置并行类型为logical clock)的值判断是否可以放在一组进行并行回放,如果取值相同,便并行执行。
日志信息:

从日志中看到,数据库已经开启了GTID(全局事务标识)功能,此功能是5.6版本出现的,可以保证每个提交的事务都会有一个全局唯一的编号,日志中也可看到GTID信息。
多源复制开启并发后的架构图:

开启并行复制操作的方法对于1主和多源是一样的:
stop slave;
SET GLOBAL SLAVE_PARALLEL_TYPE='LOGICAL_CLOCK';
SET GLOBAL SLAVE_PARALLEL_WORKERS=30;
start slave;
验证配置生效:

用show processlist命令会看到会出现多个coordinator线程和每个co线程所分配的30个worker线程,总共60多个线程。(由于worker阵容太庞大,超占篇幅,就不在此展示了)
为什么选择并行度为30,原因是从1主1从的测试中发现该并行度在本次测试环境中磁盘资源利用率略高于其他场景,CPU消耗相对比较低,内存消耗差别不大,总体效率最高,执行时间最短。
1主1从复制时Slave数据库的CPU性能状态特征:
CPU性能统计:
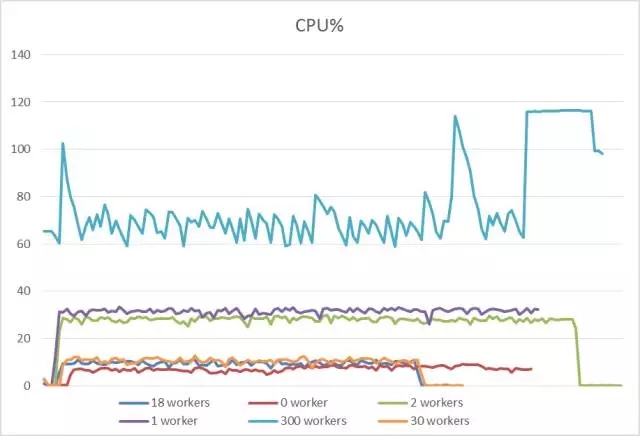
从图中可以看到,在本次测试环境中,CPU状态最好的是并发度为18和30的时候,并发度为300的时候CPU反而消耗明显;并发为2的时候cpu消耗高,并且处理时间更耗时;并发为0的时候,其实等于不并发,CPU利用率不高,耗时也较长;值得关注的是,并发度设置为1的时候,即使只有1个worker,但是毕竟是并发模式,此时同样在消耗coordinator的资源,并且此时coordinator也参与了重演操作,相当于2个线程进行重演,因此与并发度设置为2很接近,所以务必注意如果想关闭并发一定要设置为0,而不是1。
接下来进行多源复制的压力测试与性能监控:
多源复制的压力测试使用了Sysbench对2台主库(master和master1)一起加压,同时对从库slave进行性能监控。(3个数据库所在的服务器配置完全相同)
测试语句:

参数说明:
OLTP场景
Innodb引擎
对5张表操作
每数据库1万个操作请求(一共2万个操作请求)
混合读写
每数据库100并发
每表20万条数据
考虑到30并发度的资源利用相对充分、执行效率相对较高的测试结果,在从库开启30个SQL线程并行后进行测试,并将从库的监控数据进行统计做成可视化曲线图进行分析。
从下面3张测试后生成的曲线图可以看到,对于从主库发过来的2万个请求,并行执行的完成时间(横轴为时间)比单线程更短,资源利用率更高,执行效率更高。
CPU使用率:
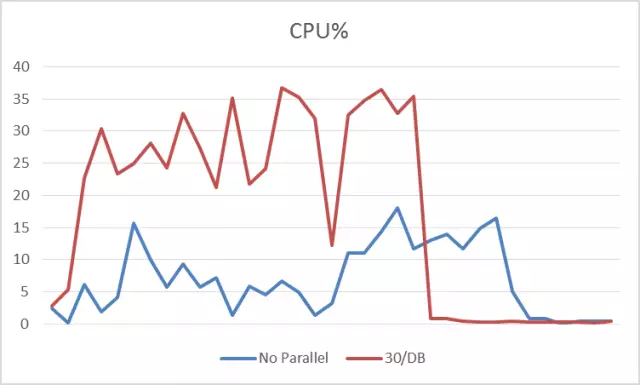
从图中可看到,开启并行之后,CPU的利用率比之前有所升高,负载还OK,最高36%左右,利用较单线程更充分,操作完成时间更早(曲线最先恢复下降到0)。
Disk Write KB/s
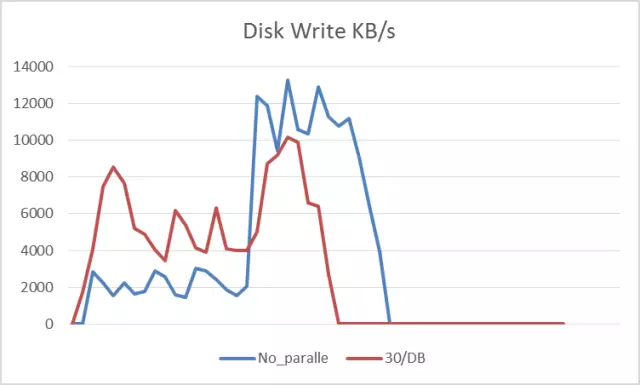
硬盘使用率从图中看出,并行SQL线程relay过程相对比较平稳,未出现明显抖动,并且30并发的曲线最早归零,结束操作。
Free Memory 剩余内存:
内存使用差不太多。
由此可见,多源复制在合理的开启并行之后,有助于提高复制效率,缩短数据的延迟。
小结
总体说来,MySQL的多源复制提供了更经济、方便和安全的数据库环境。如有感兴趣的朋友,欢迎留言一起交流,模拟业务场景进行测试、提出测试建议、更正错误和共同研究都是非常欢迎的,希望与大家互助共进!








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721