
刈刀(程君杰),曾就职于阿里巴巴移动事业部,数据技术专家。主要负责业务数据分析挖掘系统架构和设计,包括大规模数据采集、分析处理、数据挖掘、数据可视化、高性能数据服务等。
在移动互联网迅速发展的今天,信息量爆发性增长,人们获取信息的途径越来越多,如何从大量的信息中获取我们想要的内容,成为了推荐系统研究的重点。 随着大数据产业的不断壮大,推荐系统在企业也越来越重要,从亚马逊的“猜您喜欢”,到阿里双十一手机淘宝的“千人千面”,无一不彰显着推荐系统至关重要的作用。
相比之下, 消息推送作为传递信息的一种重要的手段,能够有效地提高活跃度,被各大App厂商广泛使用,本应有很大的发展。 但是由于终端上应用越来越多,每天各大App推送的信息也越来越庞大,加上信息都是千篇一律,没有新意, 不但不能起到响应的作用, 反而会引起用户强烈的反感,用户收到的推送信息,基本都会忽略, 删除,甚至完全限制推送。
随着推荐系统的成熟,将其应用于推送变成了可能, 通过推荐系统寻找用户关注的焦点,精准定位用户兴趣,从而推送用户感兴趣的内容,达到提升推送的效果。
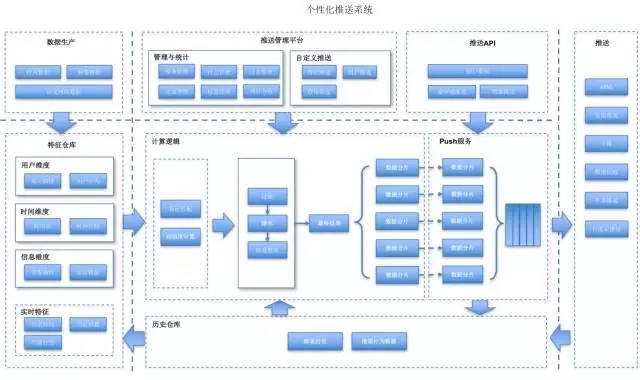
个性化推送的核心思想,是将推荐系统与推送系统结合,用推荐系统提取用户感兴趣的内容给用户推送,提高用户对推送消息的点击率,提升推送效果。
从个性化推送架构图上可以看出,个性化推送系统,核心组件有三层:数据层、计算逻辑层和推送服务层。
基础数据层 是个性化推送的基础, 通过数据,将用户与信息相关联,通过特征,将用户与用户相区分,从而达到千人千面的效果。
计算逻辑层 是个性化推送的核心,通过特征匹配等相关的逻辑运算,将用户和信息做关联,筛选更适合的数据,计算逻辑直接影响到个性化推送的准确度。
推送服务层 是个性化推送与用户交互的通道。推送服务,间接地影响到个性化推送的到达率,影响着推送的效果。
推荐系统的基本任务是联系用户和内容,解决信息过载的问题。 想要做到用户和内容更大程度的匹配, 就必须去深入了解用户和信息。 在这里,我们将数据分为三个维度, 方便对用于,信息的把握。
用户维度数据
信息维度数据
时间维度数据
用户维度数据,是用来描述用户的特征数据。 了解用户,一般从用户标签属性和用户行为属性两个层面入手。
用户标签属性是用来描述用户的静态特征属性,如用户的性别,年龄,喜好,出行偏好,住址等。
用户行为数据,简单来说就是用户的行为日志,用户在互联网上的任何行为,都会产生日志, 比如用户浏览了哪个网站,用户搜索了哪个名词,用户点击了哪个广告,用户播放了哪个视频等等,都属于用户行为数据。 用户行为常被分为两类,显性反馈行为和隐性反馈行为。显性反馈行为是指用户明确表示物品喜好的行为, 如常见的评分,点赞等。 隐性反馈行为是指那些不能明确反映用户喜好的行为。常见的有页面浏览的行为。 用户浏览一个页面,不代表用户一定喜欢这个页面展现的物品,很有可能只是因为这个页面在首页,用户更容易点击而已。
对收集的用户特征做融合,根据不同的方向,对用户特征库做划分, 方便之后的使用。
我们整理了用户常见的一些特征指标,如下:

所属的行业不同,所关注的用户特征也不同,不同的行业,会对用户在某一方面有更细致的特征描述。
从原始的用户行为数据,用户标签数据,以及其它第三方的数据中,提取我们所要关注的特征值,形成特征向量,为后续信息筛选做准备。
信息维度数据,用于描述信息的特征属性。 不同种类的消息内容,用不同的特征指标来标识。

上述的三个类似,列举了舞蹈,视频,音乐三个类型内容所关注的特征。 更细、更准确的特征描述,有利于我们更加准确地去匹配内容。
时间维度数据,就是与时间相关的用户特征和信息特征。 如用户当前在中关村, 中关村某店未来三小时有抢购活动等。 在使用这些特征的时候,一定要注意其时效性。
我们准备好了用户和内容之后,接下来要做的就是连接用户和内容。 推荐系统连接用户和内容的方式有三种:
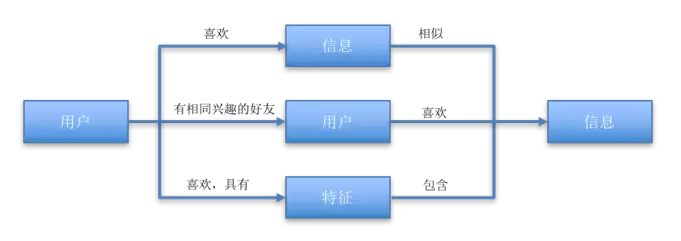
用户信息匹配:用户喜欢某些特征的内容,如果信息里包含了这些特征,则认为该内容是用户最有可能感兴趣的内容;
信息匹配:利用用户之前喜欢的内容,寻找与这些内容相似的内容,视为用户最有可能感兴趣的内容;
用户匹配:根据用户特征寻找相似的用户,将相似用户所感兴趣的内容视为该用户最有可能感兴趣的内容;
用户信息匹配,是直接通过用户特征和信息特征做匹配,筛选出用户感兴趣的内容,这种方式计算方式简单,直接了当,但是覆盖面比较窄,能够完全匹配上的内容占很少一部分,为了扩大召回, 将大部分特征相匹配的信息也筛选出来,视为用户最感兴趣的内容。 信息匹配和用户匹配,则是典型的协同过滤,更多是计算相似度,信息匹配计算内容的相似度,用户匹配则是计算用户的相似度, 于是用户和信息的连接问题转化为了计算相似度的问题。
常用的计算相似度的算法有以下几种:
殴氏距离或者曼哈顿距离
余弦相似度
皮尔逊相关系数
两个n维向量的殴氏距离计算公式如下:

两个n维向量的曼哈顿距离计算公式如下:
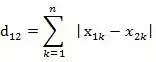
两个n维向量的余弦系数如下:
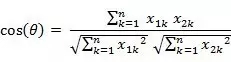
两个n维向量的皮尔逊系数如下:

这里不再赘述各个公式的由来以及推倒,有兴趣大家可以自行查找相关文章。 一般的,如果数据比较稠密,而且属性值大小都比较重要,则采用殴氏距离或者曼哈顿距离,如果数据稀疏,考虑使用余弦距离,如数据受到分数贬值的影响(及不同的类型采用不同的评分),则使用皮尔逊相关系数。
经过特征匹配和若干轮的相似度计算后,我们拿到了一个初步的用户信息匹配结果集, 接下来我们会对结果集做进一步的处理。
过滤:主要是根据推送的历史,将之前推送过的信息过滤掉,同时,我们会根据实际情况,将不满足要求,或者质量比较差的信息过滤掉
排名:主要是拟定推送信息的优先级, 一般按照新颖性,多样性和用户反馈等规则来做排序,新颖性保证了尽量给用户推送他们不知道的,长尾的信息,多样性保证用户可以获取更广的内容,而用户反馈则通过收集用户真实的意愿(如通过用户对推送内容的打开,关闭操作反应用户的喜好)实现更优的排序。
信息整理:选择最优内容,形成消息,进行推送
这只是简单介绍了一下数据处理和匹配的逻辑,在具体的实现过程中,需要考虑特征权重的问题, 特征权重对特征匹配,结果排序等影响较大。
推送服务,作为个性化消息的出口, 根据客户端的种类,也被分为了Apple和Android两大体系。 Apple系推送服务统一将推送信息送入apns,由apns负责后续推送工作。 Android则通过后台守护进程,和推送服务建立联系后获取推送内容。 目前行业内有很多开放的推送服务,如umeng推送,信鸽推送,个推等,基本上都是对上述功能的封装。 一些开源推送服务,如umeng, 由于背靠阿里,和所有阿里系应用共享推送数据通道(也就是后台的守护进程), 大大提高了消息的到达率。
个性化推送,在推送的内容和时机上都是离散的,所以很难做到批量推送,这就对推送服务的设计和性能提出了比较高的要求。 我们推送服务做了如下改进:
数据局部聚合:将相同消息内容的推送放在一起, 这样就可以做局部的批量推送,增加服务吞吐
数据分片:将不同消息内容的推送分割为不同的数据片, 不同的数据片可以并行推送, 提高推送效率
守护线程:每台服务实例都保留一个守护线程,用于监控推送过程,确保推送有且仅有一次送达
在个性化推送的基础上,借助于LBS,我们完成一个新的推送场景的尝试,这就是基于用户位置的实效性个性化推送推送。 当你步入中关村商圈,那里的新中关购物中心正在搞活动,其中耐克正在打折,从你的用户特征可以看出,你是个运动达人,最近在某电商网站上浏览了多次运动鞋, 这个时候,我们为你推送了耐克打折的这个消息, 这就是一个典型的基于位置的个性化推送场景。
通过定位服务获取用户的实时位置数据,通过计算,获取与参照物的位置关系,结合上述的个性化推送,为用户推送该参照物范围内用户感兴趣的内容。 一般的,通过空间索引,来提高计算地理位置关系的性能,空间索引分为两类:
网状索引, 如geohash等
树状索引, 如R树,四差树等
可以根据时间的场景来选择不同的空间索引。
相关专题:
◆ 近期热文 ◆
◆ 近期活动 ◆
Gdevops全球敏捷运维峰会上海站

峰会官网:www.gdevops.com









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721