
过去的几十年,这条定律一直被誉为芯片行业的圣经。不过这两年,随着芯片越做越小,现在芯片已经都几纳米了,大家也开始怀疑这条定律是否还能一直持续下去,毕竟芯片再变小的空间不大了。
不过大模型的爆火,让大家重新看到了希望,似乎摩尔定律还能持续下去。因为大模型开始把算力、算法、数据进行深度结合。这也预示着在未来,数据将成为企业最宝贵的资产。
过去几年,各大企业都建设了大数据、数据湖。但仅仅是把这些数据存储起来,不但无法高效使用,还浪费了大量的存储空间。如何有效利用这些数据,一直是众多企业面临的挑战。现在,通过大模型,这一现状即将面临改变。
大模型?不是需要联网吗?大多数企业的生产环境都与互联网隔离,大模型又能做什么?
不用担心,通过RAG(检索增强生成)搭载离线大模型,现在可以把所有的运维文档、设计文档结合大模型技术,快速构建为本地知识库。让实习生也可以秒变老司机。
就比如一直以来的运维问题,当发生生产事件,大多数人都经历过问题定位事件长,或者一线人员不熟悉系统,无法及时处理事件等诸多问题。
RAG需要经历两个流程,首先是准备动作,将文档通过加载,切分,嵌入等动作,最终存储在向量数据库中。
也就是把文本、图像、音频等半结构化、非结构化数据,通过向量模型,转化成一个个类似坐标似的向量值。
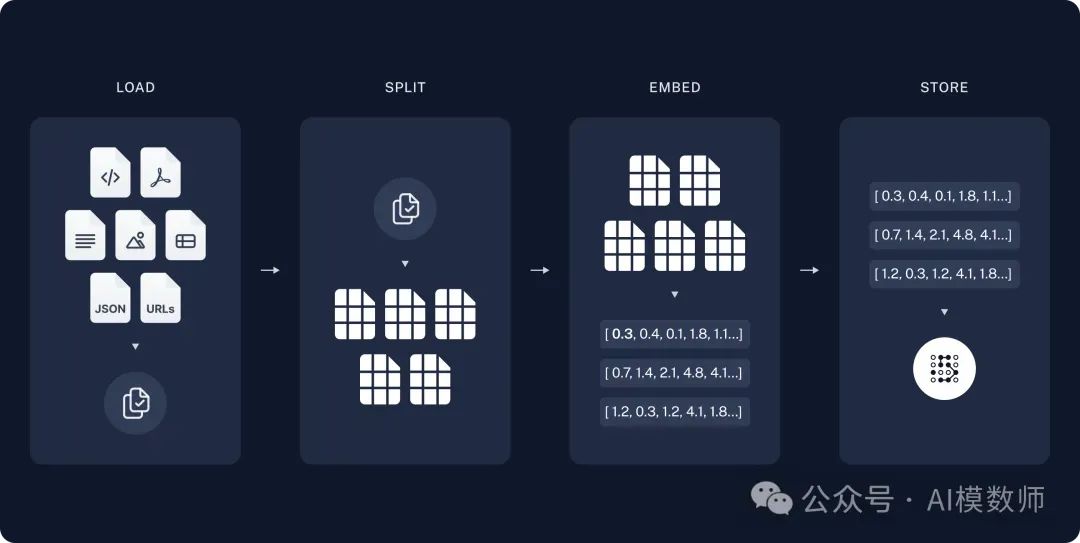
通过LangChain框架可以快速实现以上逻辑,先是加载文档:
from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://docs.smith.langchain.com/user_guide")docs = loader.load()
再按照每1000字符的粒度,将文档切分。
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)splits = text_splitter.split_documents(docs)
然后通过嵌入模型(这里用到的是OpenAI提供的嵌入模型),把文档存入Chroma向量数据库中。至此,文档的相关信息就已经存储到了向量数据库中。
from langchain_openai import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
向量是一种类似坐标的数据格式,就好像我们在中学地理课上学的经纬度,比如 [ 东经72° ,北纬37° ] ,就代表了地图上的一个具体的位置。
通过嵌入模型,就会把文档变成类似于坐标的形式存储,就能得到向量A。
当需要查询的时候,这时候就需要触发查询的逻辑:首先会将用户提出的问题,以同样进行嵌入模型进行向量化,得到用户问题的坐标B。
再将用户问题的坐标B,与向量数据库里面的向量A做比对,找到最近的坐标。再4将找到的内容和问题统一丢给大模型,通过提示词组装成最终的答案。
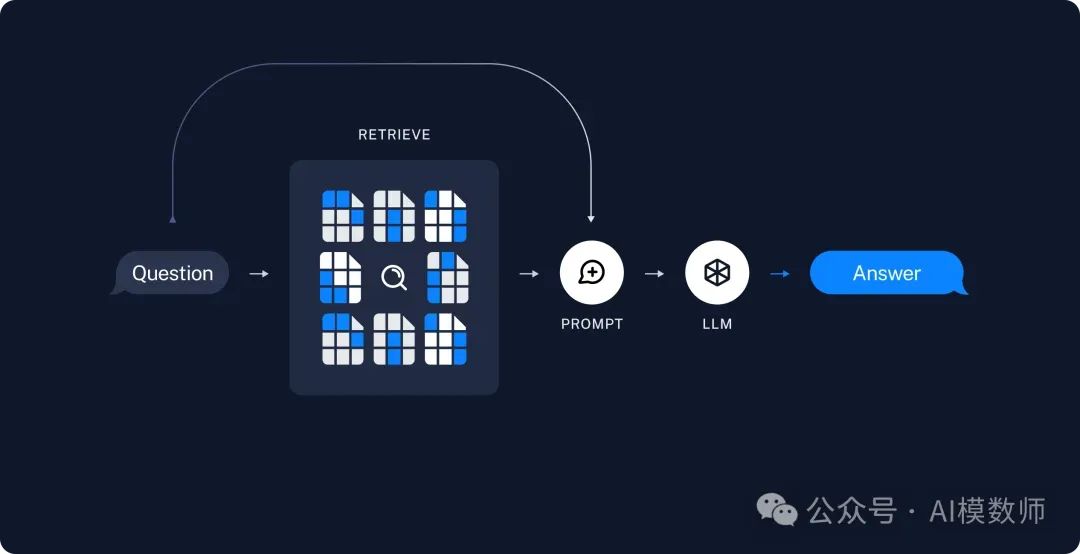
LangChain里检索的流程主要代码实现如下,
# Retrieve and generate using the relevant snippets of the blog.retriever = vectorstore.as_retriever()prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):return "\n\n".join(doc.page_content for doc in docs)rag_chain = ({"context": retriever | format_docs, "question": RunnablePassthrough()}| prompt| llm| StrOutputParser())
为什么要把问题和文档通过转换成向量这么麻烦的方式进行检索?
主要是在人类语言中,不同的语言可能表达相似的含义,比如 “今天有点冷” 和 “今天冻死了” 的含义相近,但是基本没有相同的文字出现。
但是如果转换成坐标,这两句话的坐标就会很接近。
通过大模型结合RAG,已经可以快速形成知识库,提取既往经验,优化企业运维流程,快速分析处理问题。
而在其他领域,详细大模型结合RAG不仅能够提升企业运维效率,降低成本,还能够增强企业的市场竞争力,成为企业数字化转型的重要一环。
在当今数据的海洋中,大模型将是企业的航标,引领着企业智能化的航向,驶向效率与安全的彼岸。
你准备好迎接大模型带来的运维革命了吗?








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721