
本文将分享一个Flink多维实时分析项目,也是最近正在做的,觉得比较有价值,记录一下,防止以后再次踩坑。主要涉及到的知识有 EventTime 和 ProcessTime 的使用、WaterMark 的使用、大数据量(一秒300MB)下维表 Join 的方案、定时器的使用、Flink DataStream 和 Flink Sql 的使用、Flink 任务调优等,干货多多!
一、需求背景
按照国际惯例,先说一下需求吧,由于需求涉及的维度比较多,实际情况比较复杂,这里就以最简单的一个维度来说吧,便于理解。
① 主数据来源于 kafka
② 维度数据来自于 Hive
① kafka 数据
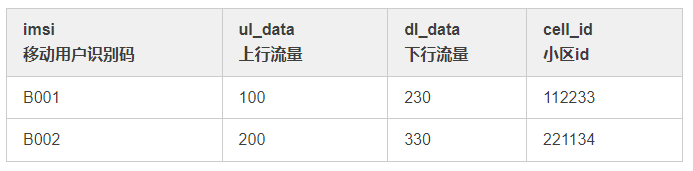
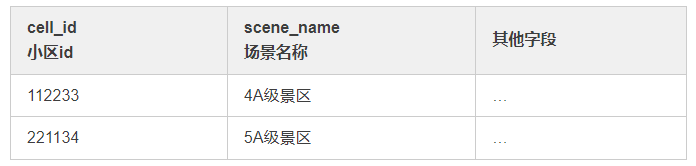
② 小区维表
要求每5分钟统计一次用户数和流量(上行流量 + 下行流量),维度为scene_name,要求结果如下表:
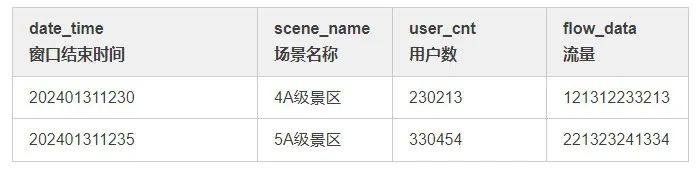
从以上信息可以得出,这个需求的意图是:用 kafka 数据作为主流,关联小区维表,根据场景维度分组,计算 uv 和 flow_data。
需要注意的一点是维表会不定期更新,并不是一成不变的。
二、实现过程
拿到这个需求,首先想到的就是使用 look up join 维表,直接一个 SQL 就完事,然而过程并不像我们预料的这么简单。
由于项目历史问题,本次使用的Flink 版本为1.10,本次将分别使用 EventTime 和 ProcessingTime 两种时间语义来完成这个需求。
首先考虑使用 Flink SQL 基于 EventTime 来做这个需求,由于维表存在于 Hive 中,这里直接查询 Presto,效率会比较高,维表关联使用的是 AsyncDataStream.unorderedWait 异步 join,用 Redis 做缓存,大体代码如下:
public static void main(String[] args) throws Exception {// 设置时间语义为processTimeenv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);FlinkKafkaConsumer<String> fkc = KafkaUtil.getKafkaSource(source_topic, "source_group");// 读取kafka数据流SingleOutputStreamOperator<String> sourceDs = env.addSource(fkc).name(source_topic + "_source");// 解析kafka数据SingleOutputStreamOperator<SourceDpiHttp> mapDs = sourceDs.flatMap(new MultipleMessageParser(net_type)).name("multiple_message_parser");// 关联小区场景维度表SingleOutputStreamOperator<SourceDpiHttp> cellDimDs = AsyncDataStream.unorderedWait(mapDs, new DimAsyncFunction<SourceDpiHttp>(DataSourceType.PRESTO.name(), DIM_GZDP_XUNQI_CELL) {("unchecked")public Tuple2<String, String>[] getJoinCondition(SourceDpiHttp obj) {Tuple2<String, String> tuple2 = Tuple2.of("id", String.valueOf(obj.getCellId()));return new Tuple2[]{tuple2};}public void join(SourceDpiHttp model, JSONObject dimInfo) {model.setSceneName(dimInfo.getString("scene_name"));model.setCellName(dimInfo.getString("cell_name"));model.setCellType(dimInfo.getString("cell_type"));}}, 60, TimeUnit.SECONDS).name("cell_dim_join");// 设置waterMark时间字段和窗口大小// 此处使用当前时间作为eventTimeSingleOutputStreamOperator<SourceDpiHttp> wmStream = cellDimDs.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<SourceDpiHttp>() {private Long currentMaxTimestamp = 0L;public Watermark getCurrentWatermark() {// 最大允许的消息延迟是0秒Long maxOutOfOrderNess = 0L;return new Watermark(currentMaxTimestamp - maxOutOfOrderNess);}public long extractTimestamp(SourceDpiHttp item, long l) {long timestamp = 0;currentMaxTimestamp = Math.max(item.getEndTime(), currentMaxTimestamp);return timestamp;}}).name("window_setting");// 将流转换为tableTable table = tableEnv.fromDataStream(wmStream, "imsi,ulData,dlData,localCity,roamingType,cellId,cellName,sceneName,cellType,regionName,netType,rowtime.rowtime");// 计算场景维度String scene_sql = "select \n" +" TUMBLE_START(rowtime, INTERVAL '" + window_size + "' SECOND) AS windowStart, \n" +" netType, " +" '' as dateTime,\n" +" sceneName,\n" +" count(distinct imsi) as userCnt,\n" +" (sum(dlData)+sum(ulData)) as flowData\n" +"from " + table + "\n" +"GROUP BY \n" +" TUMBLE(rowtime, INTERVAL '" + window_size + "' SECOND), \n" +" netType,\n" +" sceneName\n";Table result_scene = tableEnv.sqlQuery(scene_sql);// 类型转换映射TypeInformation<CaSceneResult> sceneTypes = new TypeHint<CaSceneResult>() {}.getTypeInfo();// 将table转换为流并输出结果到kafkaSingleOutputStreamOperator<String> sceneMapDs = tableEnv.toAppendStream(result_scene, sceneTypes).map(new SceneDateTimeParser()).name(sinkTopic_scene + "_transfer");sceneMapDs.addSink(KafkaUtil.getKafkaSink(sinkTopic_scene)).name(sinkTopic_cell + "_sink");env.execute("main_cell_job");}
这种方案看似很合理,其实存在一些问题:
① 由于是异步 join,需要数据源支持异步操作,如果不支持需要用使用多线程模拟异步操作,如果操作不当会出现并发问题以及对资源的滥用。
② 会对 presto 造成很大的压力。
③ 上线会发现时区有问题,而且不是差8小时,很是疑惑。如果差8小时,可以在分配 waterMark 的时候主动加上8小时,不过不赞成这种做法,这种是没有科学依据的,可能跟 Flink 版本有关系吧,在 Flink 社区也有人提到过这个问题,目前貌似并没有好的解决办法。
于是出现了第二种方案:
这种方案也是采用了 Flink SQL 来实现,这种和第一种一样,也存在时区的问题。
唯一的区别就是将 Presto 数据转为广播流,定时广播到子任务中。
这里就不贴代码了,基本没有解决上述提到的问题,仅仅作为 join 的一种方案吧,也算是练了个手。
单独写一个程序,定时去将 Presto 的数据读取到 Redis 中,在 FlatMap 阶段,直接查询 Redis 做维表关联,并且还做了一层 Guava 缓存。
这种方案解决了 Presto 压力大的问题。因为这里仍然用的是 Flink SQL,因此时区问题仍然没有得到解决。
为了解决时区问题,放弃了 Flink SQL 的写法,而是改用 DataStream,自己写代码来实现聚合指标,这次仍然使用的是 EventTime,大概代码如下:
public static void main(String[] args) throws Exception {// 设置时间语义为eventTimeenv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);FlinkKafkaConsumer<String> fkc = KafkaUtil.getKafkaSource(source_topic, consumerGroup);// 读取kafka数据流SingleOutputStreamOperator<String> sourceDs = env.addSource(fkc).name(source_topic + "_source").setParallelism(parallelism);// 解析kafka数据SingleOutputStreamOperator<SourceDpiHttp> mapDs = sourceDs.flatMap(new MultipleMessageParser()).setParallelism(parallelism).name("multiple_message_parser");// 设置waterMark时间字段和窗口大小SingleOutputStreamOperator<SourceDpiHttp> wmStream = mapDs.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<SourceDpiHttp>() {private Long currentMaxTimestamp = 0L;public Watermark getCurrentWatermark() {// 最大允许的消息延迟是0秒Long maxOutOfOrderNess = waterMark * 1000;return new Watermark(currentMaxTimestamp - maxOutOfOrderNess);}public long extractTimestamp(SourceDpiHttp item, long l) {long timestamp = item.getEndTime();currentMaxTimestamp = Math.max(timestamp, currentMaxTimestamp);return timestamp;}}).name("water_mark");// 计算场景维度SingleOutputStreamOperator<String> sceneResultStream = wmStream..keyBy((KeySelector<SourceDpiHttp, String>) SourceDpiHttp::getSceneName).window(TumblingEventTimeWindows.of(Time.minutes(5))).process(new ProcessWindowFunction<SourceDpiHttp, String, String, TimeWindow>() {public void process(String sceneKey, ProcessWindowFunction<SourceDpiHttp, String, String, TimeWindow>.Context context, Iterable<SourceDpiHttp> iterable, Collector<String> collector) throws Exception {try {long flowData = 0;Set<String> uvSet = new HashSet<>();long windowEnd = context.window().getEnd();for (SourceDpiHttp sourceDpiHttp : iterable) {flowData += (sourceDpiHttp.getDlData() + sourceDpiHttp.getUlData());uvSet.add(sourceDpiHttp.getImsi());}CaSceneResult result = new CaSceneResult();result.setDateTime(new SimpleDateFormat("yyyyMMddHHmm").format(windowEnd));result.setNetType(netType);result.setSceneName(sceneKey);result.setUserCnt((long) uvSet.size());result.setFlowData(flowData);collector.collect(JSON.toJSONString(result));} catch (Exception e) {logger.error("场景维度计算出错:", e);}}});sceneResultStream.addSink(KafkaUtil.getKafkaSink(sinkTopic)).name(sinkTopic + "_sink").setParallelism(sinkParallelism);env.execute("main_cell_job");}
这种方式既解决了 Presto 的压力,也解决了时区的问题(因为没有使用Flink SQL了,也就不存在时区的问题了)。
这种方案没有使用窗口,而是使用了定时器来实现5分钟数据统计,想象是美好的,现实是残酷的,这里忘记了在使用定时器时,其实是对每一个元素都设置了一个5分钟的定时,导致数据并不是按照我们预期的那样每5分钟统计一次,这里仅仅贴出定时器的代码吧,这个场景不适用于定时器,仅仅作为学习吧。
public class SceneKeyedProcessFunction extends KeyedProcessFunction<String, SourceDpiHttp, String> {private static final Logger logger = LoggerFactory.getLogger(SceneKeyedProcessFunction.class);private transient ValueState<Long> flowDataState;private transient ValueState<List<String>> userCntState;private transient ValueState<Boolean> timerRegisteredState;private final String netType;private final Integer windowSize;public SceneKeyedProcessFunction(String netType, Integer windowSize) {this.netType = netType;this.windowSize = windowSize;}public void open(Configuration parameters) throws Exception {flowDataState = getRuntimeContext().getState(new ValueStateDescriptor<>("flowData", Types.LONG));userCntState = getRuntimeContext().getState(new ValueStateDescriptor<>("userCnt", Types.LIST(Types.STRING)));timerRegisteredState = getRuntimeContext().getState(new ValueStateDescriptor<>("timerRegistered", Types.BOOLEAN));}public void processElement(SourceDpiHttp sourceDpiHttp, KeyedProcessFunction<String, SourceDpiHttp, String>.Context ctx, Collector<String> out) throws Exception {try {Long flowData = flowDataState.value();List<String> userCnt = userCntState.value();// 如果窗口内数据的和为null,表示第一次处理,初始化为0if (flowData == null) {flowData = 0L;}if (ObjectUtils.isEmpty(userCnt)) {userCnt = new ArrayList<>();}userCnt.add(sourceDpiHttp.getImsi());userCntState.update(userCnt);if (!"VOLTE".equalsIgnoreCase(netType)&& ObjectUtils.isNotEmpty(sourceDpiHttp.getDlData())&& ObjectUtils.isNotEmpty(sourceDpiHttp.getUlData())) {// 更新窗口内数据的和flowData += (sourceDpiHttp.getDlData() + sourceDpiHttp.getUlData());flowDataState.update(flowData);}// 注册5分钟后的定时器Boolean timerRegistered = timerRegisteredState.value();if (timerRegistered == null || !timerRegistered) {ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + windowSize * 60 * 1000);timerRegisteredState.update(true);}} catch (Exception e) {logger.error("小区维度计算出错:{}", e, e);}}public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {String sceneKey = ctx.getCurrentKey();Long flowData = flowDataState.value();Set<String> userCnt = new HashSet<>();if (ObjectUtils.isNotEmpty(userCntState) && ObjectUtils.isNotEmpty(userCntState.value())) {userCnt = new HashSet<>(userCntState.value());}CaSceneResult result = new CaSceneResult();result.setDateTime(new SimpleDateFormat("yyyyMMddHHmm").format(timestamp));result.setNetType(netType);result.setSceneName(sceneKey);result.setUserCnt((long) userCnt.size());result.setFlowData(flowData);// 输出统计数据out.collect(JSON.toJSONString(result));// 清除当前状态clearState();ctx.timerService().deleteProcessingTimeTimer(timestamp);timerRegisteredState.update(false);}public void close() throws Exception {super.close();}public void clearState() {if (Objects.nonNull(flowDataState)) {flowDataState.clear();}if (Objects.nonNull(userCntState)) {userCntState.clear();}}}
这里直接使用 ProcessTime 对应的滑动窗口实现,大体代码如下:
public static void main() throws Exception {// 设置时间语义为processTimeenv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);FlinkKafkaConsumer<String> fkc = KafkaUtil.getKafkaSource(source_topic, consumerGroup);// 读取kafka数据流SingleOutputStreamOperator<String> sourceDs = env.addSource(fkc).name(source_topic + "_source").setParallelism(parallelism);// 解析kafka数据SingleOutputStreamOperator<SourceDpiHttp> mapDs = sourceDs.flatMap(new MultipleMessageParser()).setParallelism(parallelism).name("multiple_message_parser");// 计算场景维度SingleOutputStreamOperator<String> sceneResultStream = mapDs.filter((FilterFunction<SourceDpiHttp>) item -> ObjectUtils.isNotEmpty(item.getSceneName()) && !"000000".equals(item.getSceneName())).keyBy((KeySelector<SourceDpiHttp, String>) SourceDpiHttp::getSceneName).window(TumblingProcessingTimeWindows.of(Time.minutes(windowSize))).apply(new WindowFunction<SourceDpiHttp, String, String, TimeWindow>() {public void apply(String sceneKey, TimeWindow window, Iterable<SourceDpiHttp> input, Collector<String> out) throws Exception {try {long flowData = 0;Set<String> uvSet = new HashSet<>();long windowEnd = window.getEnd();for (SourceDpiHttp sourceDpiHttp : input) {flowData += (sourceDpiHttp.getDlData() + sourceDpiHttp.getUlData());uvSet.add(sourceDpiHttp.getImsi());}CaSceneResult result = new CaSceneResult();result.setDateTime(new SimpleDateFormat("yyyyMMddHHmm").format(windowEnd));result.setNetType(netType);result.setSceneName(sceneKey);result.setUserCnt((long) uvSet.size());result.setFlowData(flowData);out.collect(JSON.toJSONString(result));} catch (Exception e) {logger.error("场景维度计算出错:", e);}}});sceneResultStream.addSink(KafkaUtil.getKafkaSink(sink_kafka_server, sinkTopic_scene)).name(sinkTopic_scene + "_sink").setParallelism(sinkParallelism);env.execute("main_cell_job");}
三、调优部分
通过之前的分析,最终方案4和方案6是满足要求的,接下来要做的工作就是调优了,毕竟代码写完了,还得保证正常运行起来。总结一下,调优大概分为这几部分:
由于数据量比较大,1秒钟 300MB 左右的数据,所以直接禁用了 checkpoint,因为数据源是 kafka,所以任务异常重启时会继续消费上次的 offset,所以去掉会提升一部分性能。
当网络原因等异常因素参与进来时,我们很难保障自己的程序能够稳定运行,万一程序异常重启了,不能让他直接挂掉,除非你有很强的监控,挂了立马能感知到,所以设置合理的任务重启策略是很重要的。
针对不同的算子,设置不同的并行度,比如开窗,做ETL都是比较耗时的操作,可以将并行度设置大一点,source并行度可以设置和kafka分区数一致或者一半,sink并行度可以设置小一点,因为聚合之后,数据量会很小,不需要太大的并行度。
当然并行度的调整也可以参考 Flink 的反压情况。
适当的增加 task manager 内存是很有必要的,不然可能数据量大的时候很容易造成 OOM,同时也要调整 slot 的数量,充分利用 task manager 的并行能力。
如果使用了 EventTime,可以适当的调整乱序大小,防止数据丢失。
适当的调整 kafka consumer 参数,比如拉取的批次大小,拉取的数据量大小。
四、写在最后
本篇文章通过实际操作 Flink,介绍了 Flink 的一些核心功能的用法,其中也踩了不少坑,当然踩得坑不仅仅是文中提到的,实际遇到的问题很多,一时想不起来了,但是只要耐心,一定能解决的,比如 kafka 分区坏了,数据为啥少了等问题。
总之,一定要看日志,不能靠瞎猜。当然了,他人的指点和帮助也很重要,遇到解决不了的问题要勇于向他人请教。
如果你看完本文还有问题的话,欢迎随时评论区交流。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721