
什么是数据服务化
大数据开发的主要流程分为数据集成、数据开发、数据生产和数据回流四个阶段。
数据集成打通了业务系统数据进入大数据环境的通道,通常包含周期性导入离线表、实时采集并清洗导入离线表和实时写入对应数据源三种方式,当前滴滴内部同步中心平台已经提供了MySQL、Oracle、MongoDB、Publiclog等多种数据源的数据采集能力;
数据开发/生产,用户可以构建实时、离线两种数据仓库,并基于SQL、Native、Shell等多种任务方式下的数据建模;
数据回流通过将离线数据导入OLAP、RDBMS等,以提升访问性能,下游服务直接访问该数据源进行数据分析、数据可视化。
滴滴内部的数据梦工厂,就是提供一站式数据开发、生产的解决方案,核心关注的是数据开发、生产环节中的效率、安全和稳定性。
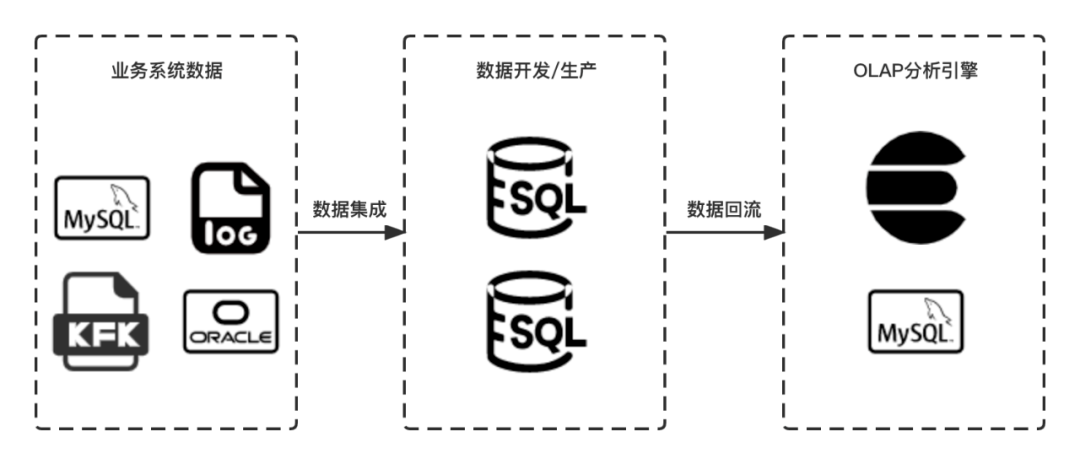
数据开发流程
为了体系地将数据交付用户,我们构建的是一站式的数据消费平台,包含了数易、数据智能问答机器人、异动分析等通用数据消费产品,和横向沉淀的内容产品北极星、集团展厅。一站式消费平台需要通过查询结构化、标准化的数据来提供可视化、分析能力。
从数据消费产品的技术架构中,对查询性能有一定要求,会根据查询的方式回流到合适的多维分析存储引擎,最为常见的是MySQL、ClickHouse、Druid和StarRocks。因此,对多维分析存储引擎的查询收口、扩展计算能力扩展、性能优化实施和查询稳定性保障等,对于消费类数据产品来说都是公共、通用能力。
此外,对于其他个性化数据产品、运营平台、B端/C端产品来说,都是亟需的数据访问能力。这也是数据中台建设,对于数据访问能力统一化的核心问题:数据服务化能力。
对于该项能力建设,我们也不是一蹴而就的,主要分为三个阶段。
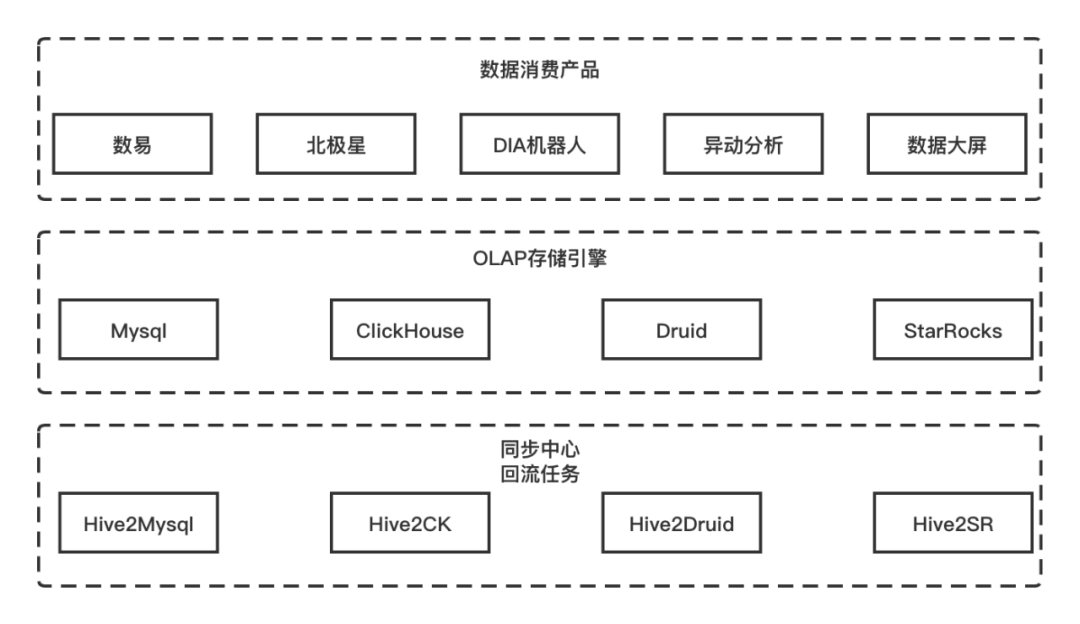
数据消费产品技术架构示意
阶段一:建设同步中心数据回流能力
2019年滴滴发起了数据体系2.0建设,作为核心产出的数据梦工厂,其第一阶段目标是建设一站式的数据开发、生产平台,关键节点以同步中心的一站式建设完毕为里程碑。
同步中心通过自动化流程的建设,结束了通过提工单的方式,来人工构建数据源间同步任务的历史,其核心产出是数据进入Hive链路的自主管理能力建设。另外,我们新建了Hive回流到MySQL、ClickHouse、Druid、Hbase和ES链路,使得数据回流完成平台化建设。
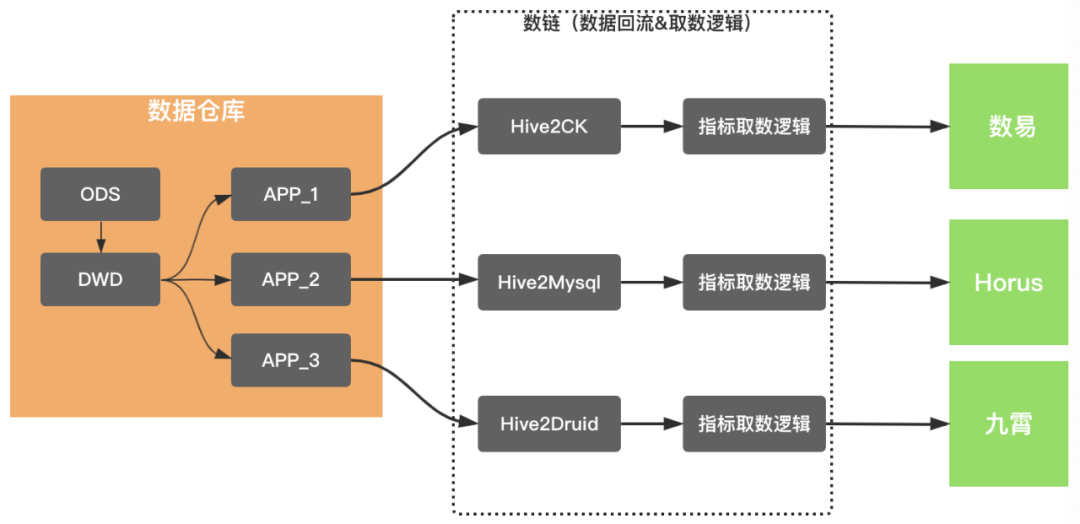
基于数据回流实现的数据服务化能力,使得服务分、北极星和数易等相关场景得以系统化覆盖。核心解决了业务直接访问大数据环境的性能问题,以数易为例,通过数据回流到ClickHouse,使数据查询性能P90从5s下降到2s以内,这样的性能提升使数易的用户体验有质的提升。这个阶段的数据产品的基本架构,尤其是查询侧,类似于下图所示,都抽象出来了数据回流和取数逻辑两个模块。
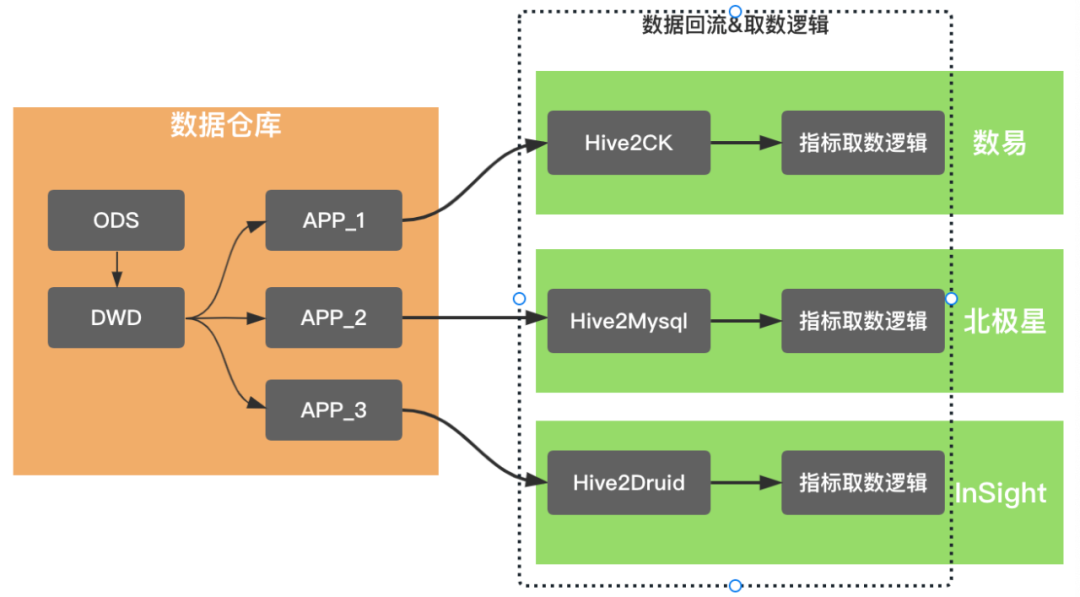
数据回流实现数据导出到多维分析存储引擎,并沉淀有任务的管理和运维能力,这些数据产品均深度打通了数据梦工厂,基于数据梦工厂强大的离线任务运维能力保障数据的产出。
取数逻辑维护着具体的查询逻辑,除了北极星,其他两款产品均衍生出了基于查询抽象的中间件,例如InSight的QE(QueryEngine)、数易的查询中心。数据回流和取数逻辑,是数据产品的核心能力,也是建设成本极高的模块。所以,这个阶段,类似于数据智能问答机器人、数据门户、复杂表格等产品,采用了基于数易数据集的查询、加速能力,以快速验证产品。
阶段二:建设数链平台,统一数据服务化
阶段一提供了数据回流在线存储能力,提升了相关系统调用性能,为数据产品发展做出了阶段性贡献。随着业务发展,数据表数量提升,取数逻辑隔离沉淀在不同系统问题凸显出来,管理成本不断提升。
为了提升取数性能,除了加速到多维分析存储引擎之外,还需要对数据进行高度聚合,构建数据量较少的APP层。APP层表和业务需求有着强相关性,因此,需求的变化常常导致需要变更APP表支持业务。阶段一中,取数逻辑场景散落在不同的系统内部,APP表变更将是比较大的工作量,包含了不同看板的数据源切换,看板质量的再次验收,过程十分繁杂。
数据回流和取数逻辑在不同的数据产品内进行重复建设,也增加了数据产品构建的效率。为了提升效率,内部产品基本都依赖数易数据集进行建设,例如数据智能问答机器人、复杂表格。
但这不是最优的解决方案,问题主要体现在:
基于数易数据集,加速、限流、隔离等措施建设都非常复杂、庞杂。尤其,数易数据集加速方式分成一级的SQL任务加速、二级ClickHouse加速,形式固化。
数易的查询都是基于MPP建设,对于相对高的并发查询、点查很难支撑。
运维保障能力较弱,加速任务都由平台代持,用户感知较弱,且无法运维。
数易数据集是数易的强依赖,剥离建设服务化能力难度较大,当时对于数易来说也不是第一优先级考虑的事情。
综上所述,构建一个统一的数据服务化平台,有着较强的业务收益。从2021年初开始,数链平台应运而生,其基本思路在于对加速链路、查询逻辑进行统一管理,并提供统一、完备的查询网关。
数链的基本能力在于:
多样化的数据源:支持ES、MySQL、ClickHouse、Hbase、Druid等数据源的访问;
多场景的数据访问:支持key/value键值对的高并发查询、支持复杂的多维分析和支持数据下载能力;
统一的接入标准:统一的访问网关、统一数据访问协议、统一的数据运维和统一的API管理能力;
数据安全管控:支持对敏感数据访问的审计,数据下载外发管控能力。
数链平台构建之后,数据API构建时间从天级别下降到分钟级别,实现了白屏化API建设能力。当前,数链的API数量已经超过4000,周活API数量也超过了1600,服务了200多个应用,覆盖了所有的业务线,达成既定建设目标。
阶段三:建设数链标准指标服务化
通过阶段二的平台建设,收益的数据产品主要是监控、看板、门户、运营系统和安全相关系统。这些系统主要看中数链构建API的效率,API业务逻辑的管理能力和API的运维能力。但是,数易、北极星等早期建设,有相关能力闭环的产品,很难找到接入数链的突破口,或者说收益很难看到。
当前,大数据中指标交付,长期通过Hive表和沉淀在指标管理工具的指标描述来交付,也就是说,数仓会提供给业务方一张Hive表,和描述性的取值逻辑。业务方通过Hive表构建看板、临时取数时,需要反复校验取数逻辑,效率比较低下。同时,同一个指标常常在北极星、数易等产品展示,最为尴尬的是常常出现数值的不一致,也就是指标消费的一致性问题凸显。
指标管理工具是根据指标管理方法论,构建的指标、维度元数据管理系统。为了录入指标、维度,数据团队花费非常大的成本。指标管理工具仅仅提供指标录入和检索能力,指标规范性建设只能依赖于自上而下的管理,无法有效自运转。对于指标一致性,只能是确保指标来自一个来源,并且交付方式不能是Hive表,而是指标本身,指标需要提供直接消费能力。
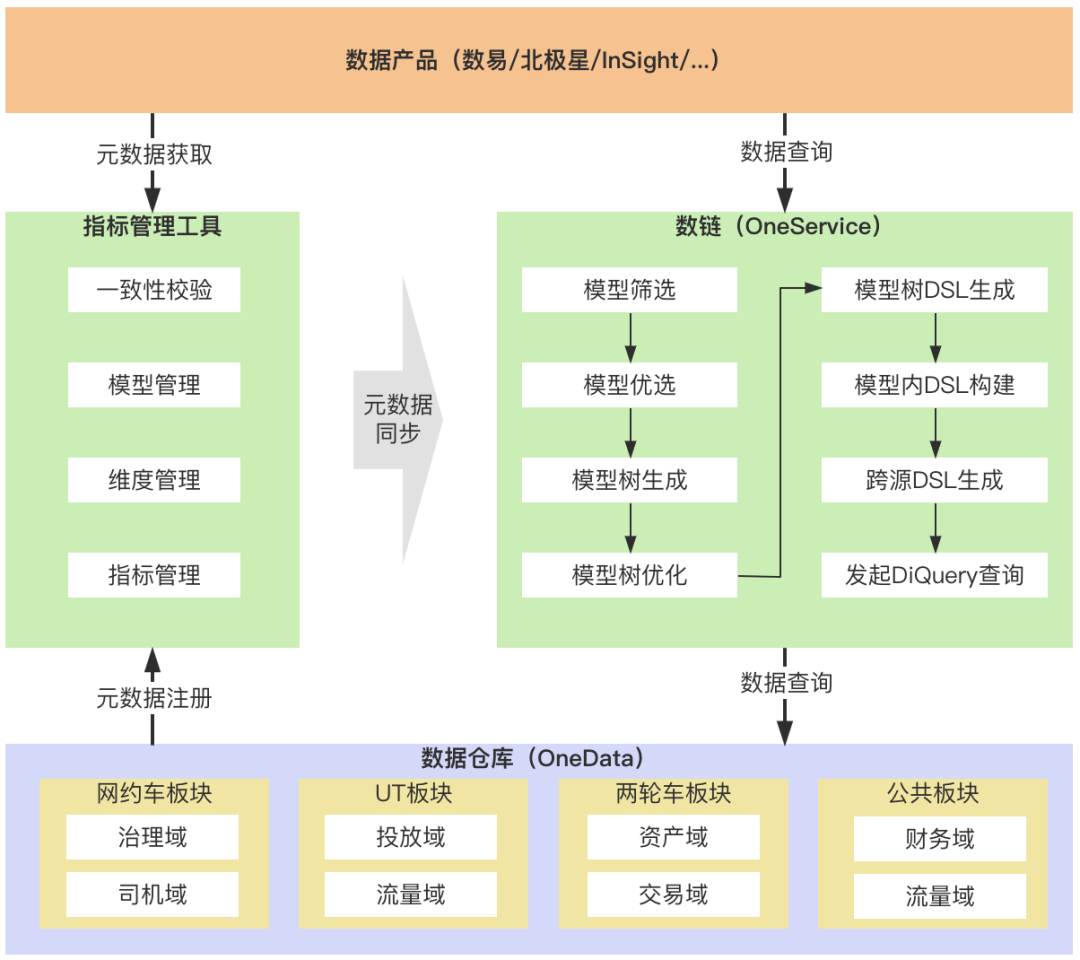
第二阶段服务化建设的困境,北极星、数易指标消费的二义性问题,以及指标管理工具的本身困局,标准指标服务化建设应运而生。基本思路如图所示,一个是指标管理工具提供模型管理,把指标和物理表进行关联,另外,就是数链提供统一的消费网关,让数易、北极星等数据产品打通这个消费渠道。
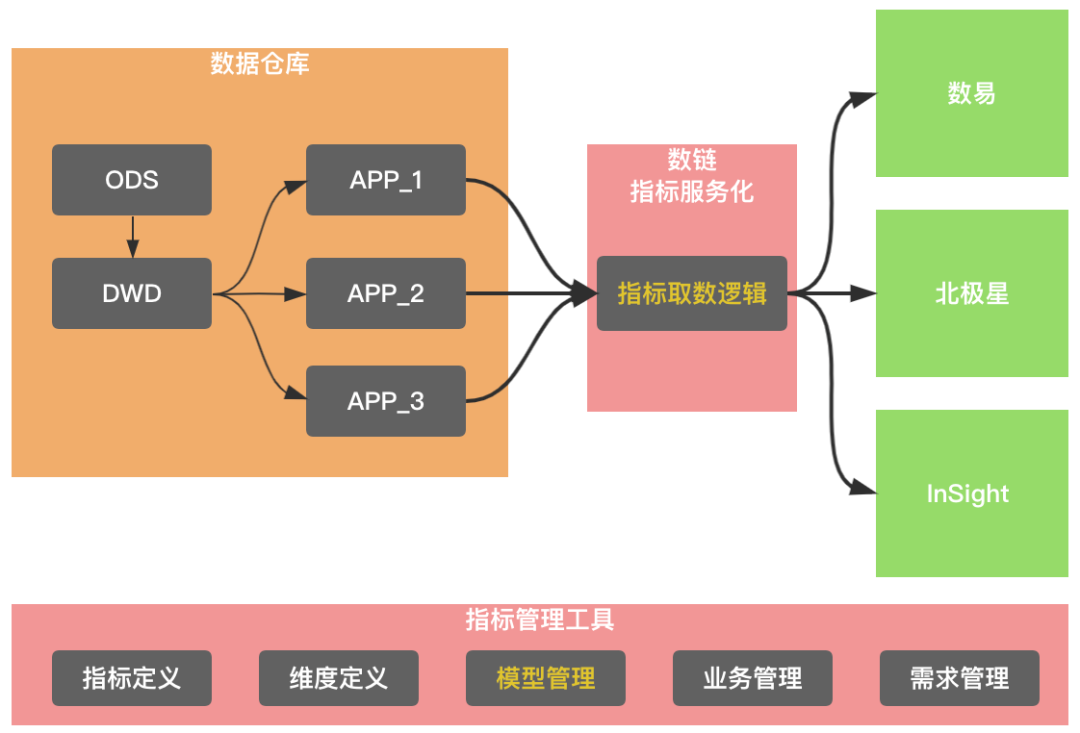
标准指标服务化建设,元数据管理需要扩展指标、维度的表达能力,并通过逻辑模型去关联指标、维度和具体物理表的具体字段。为了简化下游消费逻辑,标准指标服务化需要提供一定的自动化取数逻辑能力。通常一个指标会在不同的物理表中实现,通过不同物理表间指标实现的一致性校验,有效避免指标的二义性。
标准指标服务化最为关键的元数据:指标、维度和逻辑模型。下面依次进行介绍。
1)指标
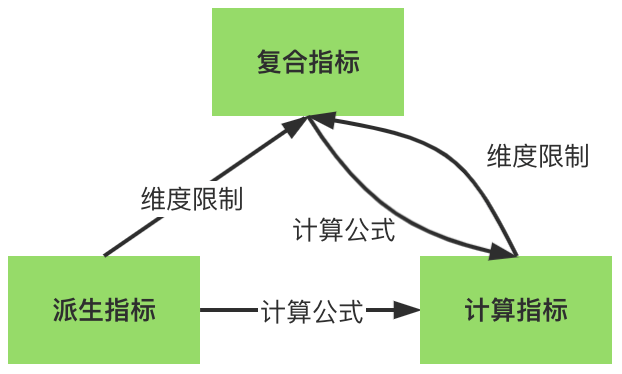
指标管理方法论主要介绍为了提升指标表达语义能力,引入的计算指标和复合指标。派生指标是指物理表(Hive/Starrocks/ClickHouse)开发后可以直接对外服务的指标,也就是一定物化在物理表上对应字段的指标。计算指标是根据已注册派生指标计算生成的指标,可以不物化到物理表上对应字段的指标,当前计算方式只支持加减乘除四则运算。
例如,应答后取消率=应答后取消订单量/当日应答订单量。复合指标是指已注册派生复合维度生成的指标,可以不物化到物理表上对应字段的指标,例如,“网花出GMV”是根据指标“含openapi含扫码付GMV”,复合维度“订单聚合业务线”,维值为“网+出+花”生成的。如下图所示,复合指标和计算指标可以相互嵌套,当前复合指标在嵌套链中最多只能出现一次。
2)纬度
纬度类型,当前构建了四种:
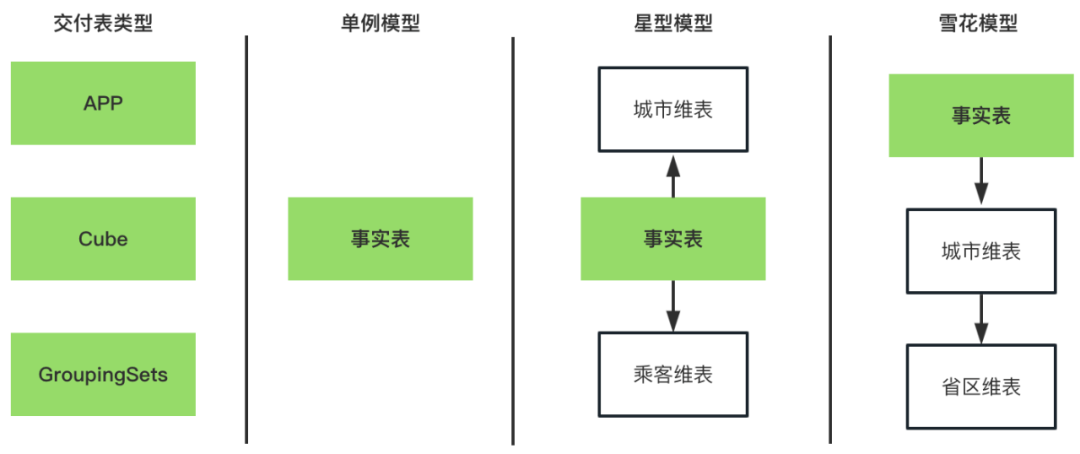
维表维度:独立的维表,维表会有唯一主键,以及其他属性信息。维表维度可以构建数仓的星形模型。如果还有存在外键,则可以构建多层维表依赖的雪花模型。例如,城市维表维度 whole_dw.dim_city。
枚举维度:key/value 键值对,键值对集中管理。例如:性别维度,对应的键值对男(M)/女(F)。
退化维度:维度逻辑无法集中管理,在不同物理表有着不同的实现,但表示的是同一个维度。例如,北极星的业务线维度,不同板块下的业务线id转换到北极星的业务线id有着不一样的转换逻辑,需要在具体实现中确定。
衍生维度:与退化维度不一样的情况,维度逻辑可以集中化管理,该逻辑是一段处理代码。
3)逻辑模型
逻辑模型在不同地方有不同的解读,指标管理工具中的逻辑模型是指标、维度和物理表绑定的载体。逻辑模型可以绑定派生指标、计算指标、复合指标三种指标,也可以绑定维表维度、枚举维度、衍生维度和退化维度四种维度。绑定到逻辑模型的指标、维度,可以直接绑定到物理表的字段,也可以绑定到根据物理表字段构建的计算字段。
计算指标、复合指标还能根据计算逻辑或者复合逻辑,非物化的绑定。逻辑模型可以绑定多个指标、多个维度,反过来,一个指标、维度可以绑定到多个逻辑模型中。更通俗的说,一个指标的多种实现方式,是通过逻辑模型指定的。
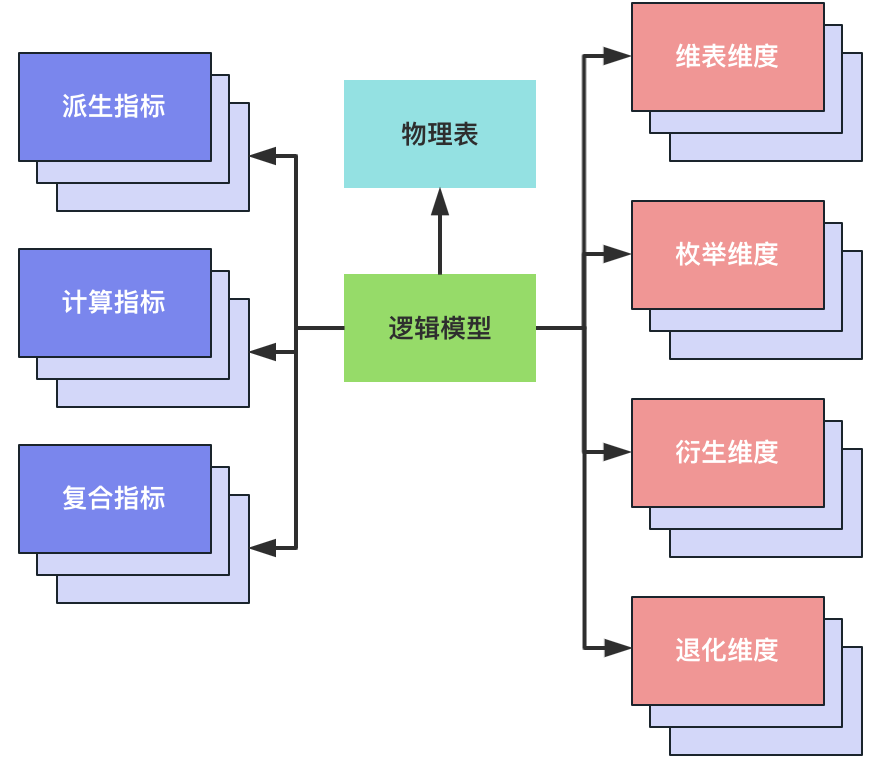
逻辑模型在指定物理表的时候,还对物理表的存储引擎、物理表的数据布局、数仓层级进行了指定。当前数链支持Hive、SR、ClickHouse三种存储引擎;数据布局支持一般APP表、Cube表和GroupingSets表;数仓层级支持APP、DM、DWS和DWD。
数链建设标准指标服务化中,取数逻辑自动化,一方面能实现集中管理(Single Source of Truth),另一方面也是提效过程。取数逻辑自动化,在标准指标服务化中主要体现在:
支持通过指标、维度取数,用户只需要提供所需要的指标和维度,通过取数接口获取数据。上面逻辑模型中提到,指标与逻辑模型是一对多关系。自动化的取数逻辑,会根据所需的指标、维度、分区范围,以及性能最佳的取数方式去选择合适的逻辑模型。需要重点指出的是,当计算指标依赖的派生指标只能通过不同的模型获取时,该取数过程支持通过联邦查询完成。
支持多种数据布局的表,当前已经支持一般APP表、Cube表和GroupingSets表。在取数中,已经屏蔽了不同数据布局的取数逻辑,用户无需关心原先表的数据布局方式。
支持多样的数仓建模模型,数仓建模规范产出中,可以是单例、星形和雪花模型。雪花和星形模型,自动化取数逻辑已经可以通过自动关联所需的维表,实现维表维度中的不同维度属性上卷等复杂的取数逻辑。
支持日、周、月、季粒度的上卷,在之前不同时间粒度的数据,只能通过开发不同的表实现。在查询性能有保障的情况下,现在可以实现时间粒度的上卷能力。
除了通过取数逻辑自动化实现取数提效之外,指标一致性也是数链建设标准指标服务化的核心出发点。指标一致性,一方面是通过统一的消费接口,另一方面,则是根据指标的实际现状,进行被动和自动的校验。
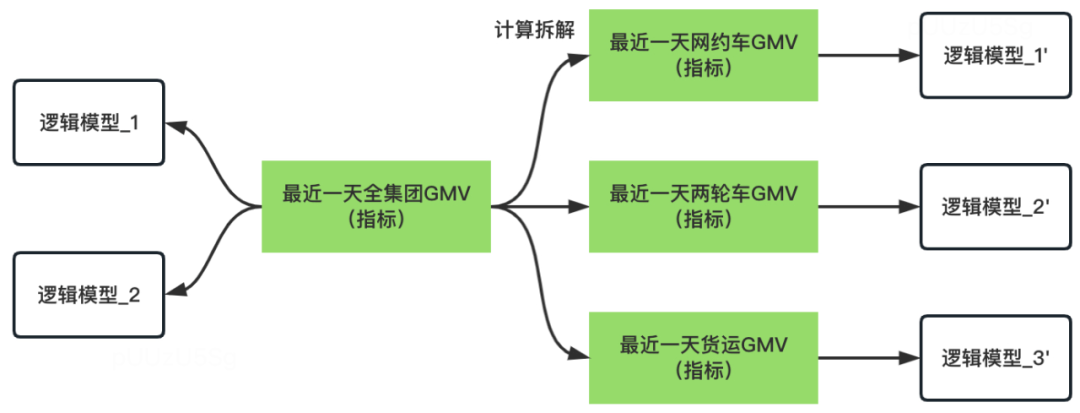
被动指标校验,由用户在平台配置所需要的进行校验的指标,如下图所示,像“最近一天全集团GMV”一样,可能在多个逻辑模型中实现。因此,校验逻辑是在几个逻辑模型产出后,进行一次周期性的校验。还有一种情况则是,“最近一天全集团GMV”,可以通过“最近一天网约车GMV”+“最近一天两轮车GMV”+“最近一天货运GMV”实现。因此,如下图所示,检验逻辑可以是左侧的逻辑模型_1和右侧的逻辑模型_1‘、逻辑模型_2’、逻辑模型_3‘产出后,进行一次周期性的校验。
自动指标检验,检验的逻辑跟被动指标校验的区别在于,模型拆解方式由系统自动生成,另外,可以进行校验的指标也由系统筛选出来。
当下接入数链标准指标服务化的服务有北极星、数易和InSight,这三个产品也是滴滴最核心的数据产品。标准指标服务化在打通这三个产品的时候,都具备不同的挑战,具体会在其他同学分享的文章进行详述。这里只简单介绍下数据产品接入、查询的基本流程。
通常流程中,数据BP将会根据指标管理工具依次录入指标、维度,数据开发同学依据不同的数据架构方式构建数仓,并创建逻辑模型,和指标、维度进行关联绑定。管理好的元数据,会被实时同步到数链。
数易、北极星、InSight通过元数据接口,对报表、看板进行构建。发起数据查询时,请求将发送到数链,并经过模型筛选、优化,生成最终的执行SQL,查询的数据再返回数据产品侧。
数据服务体系整体架构
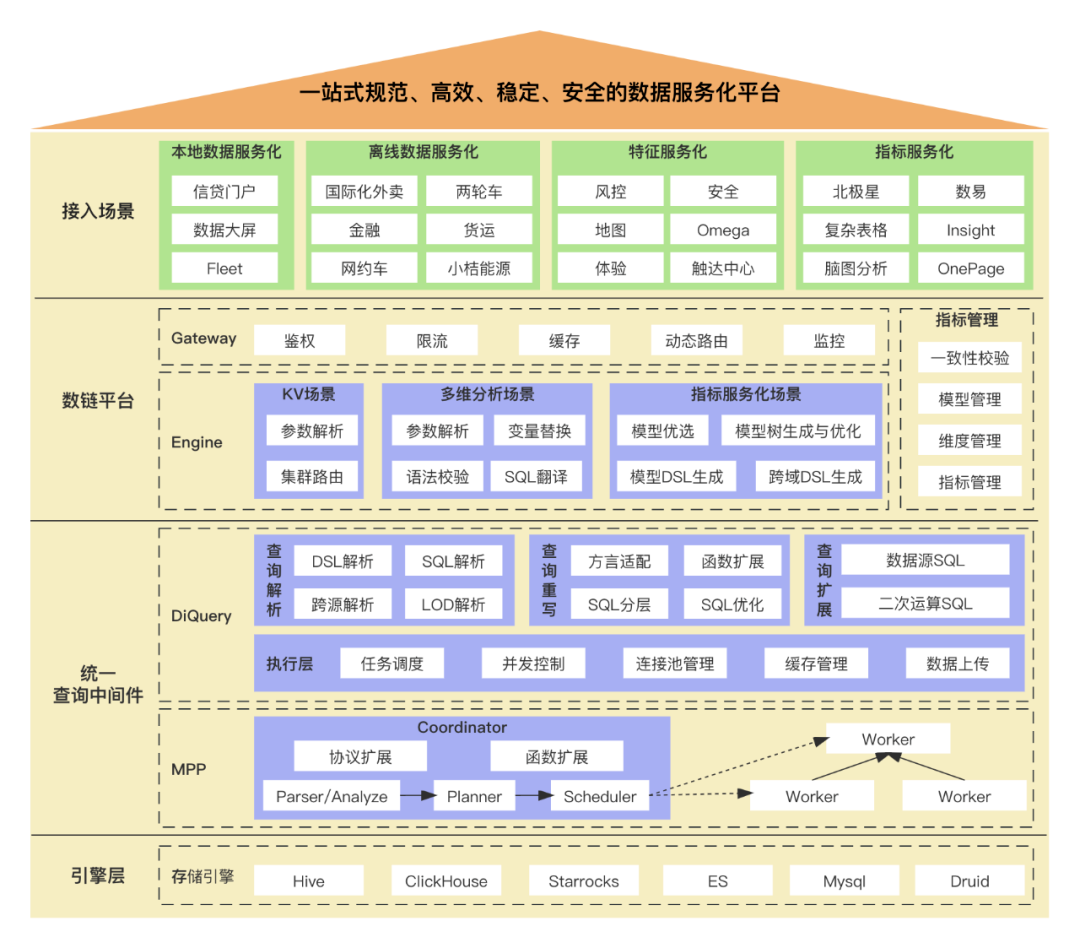
数链平台旨在打造一站式规范、高效、稳定和安全的数据服务化平台。当前服务的业务场景主要分为本地数据服务化、离线数据服务化、特征服务化和标准指标服务化。数链平台分为网关层和引擎层。网关实现的是统一的入口,并提供了鉴权、限流、缓存、路由、监控等能力。引擎层将实现场景分成了key/value键值对场景、多维分析场景和标准指标服务化场景。
key/value键值对场景主要服务特征服务化,即牛盾、地图特征等业务场景。多维分析场景,主要服务于本地数据服务化和离线数据服务化,即Horus、九霄等业务场景。key/value键值对场景、多维分析场景是阶段二的核心能力,标准指标服务化场景则是阶段三的核心能力。
为了支撑多样、复杂的数据查询诉求,我们还建设了统一的查询中间件:DiQuery。DiQuery依托于MPP的强大查询能力,构建了统一的查询能力,服务于数链、数易等数据产品。DiQuery除了支持单表查询能力之外,还支持了联邦查询、LOD复杂函数查询能力。DiQuery支持同环比、四周均值等扩展函数,并支持在此基础上的上卷能力。
总结与展望
滴滴数据服务体系的发展,经历了原始的数据回流任务方式、统一数据服务化平台建设、标准指标服务化建设,一步步在建设更好的数据服务体系。标准指标服务化建设,是今年的重头戏,在数仓研发、产品和平台研发的鼎力协作中高速发展。
现在的数据服务体系,解耦了数据生产和数据消费的关系。接下来,需要推进数据生产的标准化,进一步解决指标一致性问题,提升数仓建设效率,并通过指标视角提升数据质量等等。标准指标服务化,将是一场一步步推进的数据平台重要演化,并在业界已经慢慢拉开帷幕。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721