
至少,从目前这两者的官方文档说明,或者通过我的亲身实践来看是这样。
那么下面,就来详细聊聊,JDBC这种虽然具有普适性的数据库连接方式,在流式读取(或者说计算)中会存在哪些短板。
数据源的读取分类
我们知道,随着企业对数据处理的要求越来越高,这就直接导致我们的数据处理系统,对数据源的读取方式有着更加多变的要求。
对数据源的读取方式和频率,从业务端的使用需求场景来看,大致可以分为两大类:
第1种:为一次性的,即一次读取完目标系统(比如数据库)的所有数据,我们称之为「批」处理;
第2种:连续性的,在第1种的基础上,依然监控着数据源端的变化,继续读取后续新增、变化的数据,我们称之为「流」处理。
其中第1种,是我们对数据源读取的传统要求,主流的计算引擎Spark和Flink都能满足。
但对于第2种,虽然无论是Spark还是Flink这两款计算引擎本身,都支持流式计算这个特性,但是这个支持其实有个重要的前提,那就是得数据源端,以及跟数据源端对应的对接方式配合才可以。
Spark的JDBC
之前我吹过牛,说但凡你能叫出名字的存储系统,或者数据库,Spark都有与之对应的接口,从而读取到其中的数据,或者将计算后的结果存储到其中。
诚然,Spark确实能做到这一点,但是,当我们想要用流的方式去读取一些特定数据库的数据源时,它却显得有些力不从心了。
比如,我想让它以流的方式去读取mysql中的数据,咋整?
能想到的就是用它的structured streaming框架,来尝试读取mysql,但是呢,打开官网一看它支持的数据源(最新的),不免有点失落:
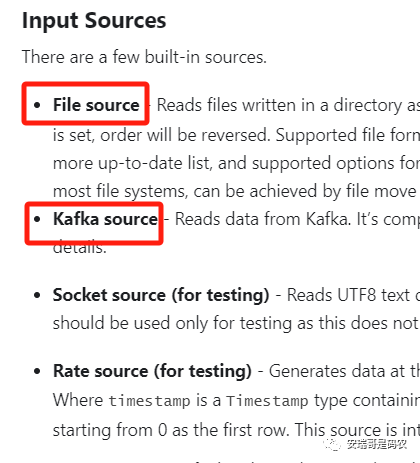
也就是说,官方明确支持可以用流的方式读取的数据源中,是没有mysql的,也没有提到JDBC。
但是呢,之前的多次实践经验告诉我,有时候官方的话也不能全信,咱最好还是亲自试验一把,万一可以呢,对吧。
根据以往的经验,我写出了如下的核心代码(记得提前在pom文件中引入对应的mysql-connector包):
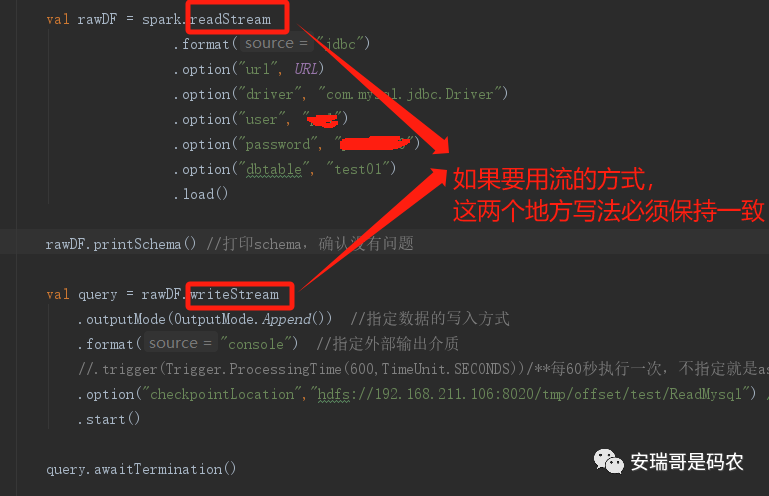
看起来好像是那么回事,但是一运行起来你会发现:
果然不行,官网诚不欺我。
但我知道,Spark肯定是可以通过JDBC的方式读取到mysql数据源的。
于是,把核心代码改成这样,就能跑通了:
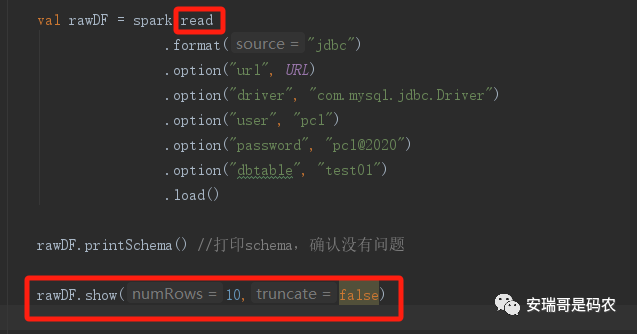
只是这样一来,就违背了我的初衷,这个逻辑就由原本我想要的「流计算」给硬生生改造成了「批处理」,也就说,这个修改之后的代码,它就不再是 Spark structured streaming 而是普通的 Spark。
所以说,Spark官方做不到(至少目前为止)直接用JDBC,以流的方式读取数据源。
在GitHub上看到一个开源项目,通过对官方原生支持的jdbc方式改造之后,说可以支持用Spark structured streaming来增量读取mysql数据源,我暂时没有去验证,有兴趣的同学可以去看看。
地址为:https://github.com/sutugin/spark-streaming-jdbc-source
Flink的JDBC
打开Flink的官网,在Flink connector一栏中赫然就出现了JDBC的身影(也没有mysql):
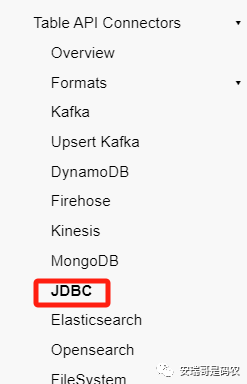
那既然这样,咱就来试试。
首先需要配置开发环境,跟Spark不一样的是,Flink想要读取mysql的数据源,那需要引入flink特有的jdbc connector(非传统的mysql-connector)。
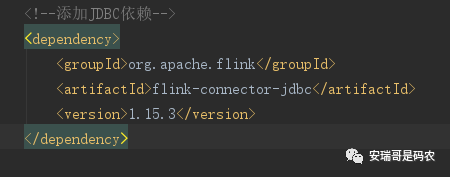
注意这个版本的选择,可能跟官网上描述的不一样,最新官方文档的 version 由 connector 版本+Flink版本两部分组成,而我这个版本稍微旧一点。
然后就是代码部分,如下(跟上面的Spark一样,这里只演示读取mysql数据,然后打印出来):
package com.anryg.mysql.jdbcimport java.time.Durationimport org.apache.flink.contrib.streaming.state.EmbeddedRocksDBStateBackendimport org.apache.flink.streaming.api.CheckpointingModeimport org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanupimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.table.api.bridge.scala.StreamTableEnvironment/*** @DESC: 用JDBC方式读取mysql数据源* @Auther: Anryg* @Date: 2023/11/8 10:49*/object FromMysql2Print {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentenv.enableCheckpointing(10000L)env.setStateBackend(new EmbeddedRocksDBStateBackend(true)) //新的设置state backend的方式env.getCheckpointConfig.setCheckpointStorage("hdfs://192.168.211.106:8020/tmp/flink_checkpoint/FromMysql2Print")env.getCheckpointConfig.setExternalizedCheckpointCleanup(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) //设置checkpoint记录的保留策略env.getCheckpointConfig.setAlignedCheckpointTimeout(Duration.ofMinutes(1L))env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)val tableEnv = StreamTableEnvironment.create(env)/**第一步:读取mysql数据源*/tableEnv.executeSql("""Create table data_from_mysql(|`client_ip` STRING,|`domain` STRING,|`time` STRING,|`target_ip` STRING,|`rcode` int,|`query_type` int,|`authority_record` STRING,|`add_msg` STRING,|`dns_ip` STRING,|PRIMARY KEY(`client_ip`,`domain`,`time`,`target_ip`,`rcode`,`query_type`) NOT ENFORCED|)|with(|'connector' = 'jdbc',|'url' = 'jdbc:mysql://192.168.221.173:3306/test',| 'username' = '***',| 'password' = '***',| 'table-name' = 'test02' //确定文本数据源的分隔符|)""".stripMargin)/**结果直接打印*/tableEnv.executeSql("""|select * from data_from_mysql limit 100""".stripMargin).print()}}
整个代码内容,跟上篇文章写的CDC方式读取mysql非常相似(有兴趣可以去看我的上篇文章对比一下)。
但是呢,把它运行起来之后,当程序把目前这张表的数据读取完,就会戛然而止:
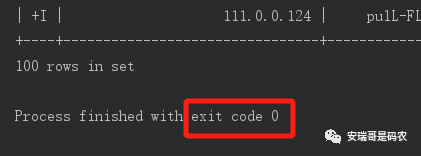
也就说,虽然咱用的是Flink流式计算的上下文(StreamExecutionEnvironment),但是,因为程序用的JDBC方式读取数据源,所以,它依然只能以批处理的方式运行。
在这点上,Flink跟Spark的表现是一模一样的。
最后
通过上面的验证可以确定,不管是Spark还是Flink,想要以JDBC的方式来流式读取mysql数据源(或者其他数据库)是行不通的,至少,直接用官方提供的「正规军」方式是不行的。
那么,对于想直接通过计算引擎,去读取某些数据库(比如mysql)的增量数据,好像当下的最优解决方案只有Flink CDC了。
当然,JDBC也并不是一无是处,对于一些低版本的数据库(CDC暂时不支持的),比如mysql5.5及以下版本的历史数据导入,它还是能派上用场的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721