
一、背景
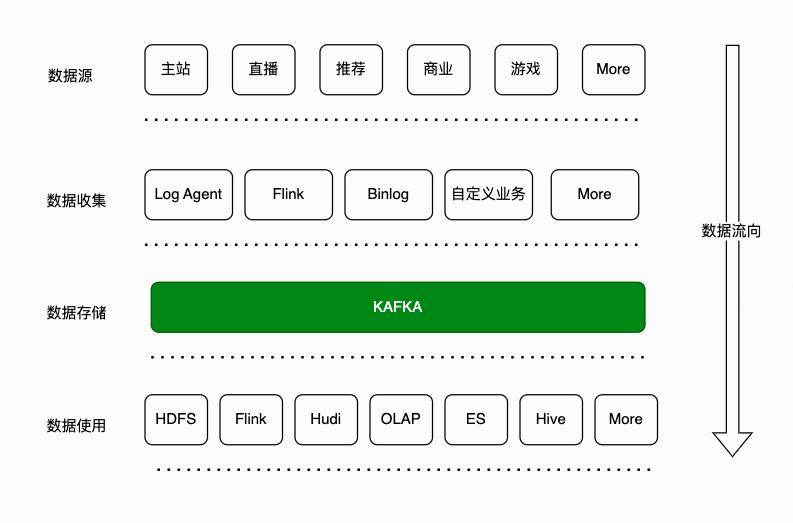
Kafka 是我们公司各个部门的重要数据中间件,主要用于上报、暂存和分发各种数据。我们不仅支持大数据场景,同时也保障在线场景的稳定性。
我们拥有1000+台Kafka机器,组成了20多个集群,针对不同业务场景配置了不同规格的机器,磁盘类型包括HDD,SSD和NVME。每日PB级输入,输出数十PB,肩负着公司数据传输的重任。随着集群规模的扩张,我们也遇到了越来越多的挑战。
二、面临的挑战与痛点
客户端的读写方式多种多样,难以预测,集群的稳定性和资源利用率难以协调。过高的读写操作可能会导致机器磁盘I/O爆满,影响用户的读写体验。
集群多业务共用,如何减少核心业务与普通业务的互相影响,减少爆炸半径。
开源版本虽然有限速的功能,但是限速的粒度很粗,不够灵活,难以实时根据磁盘状态进行对应调整。
为保证集群稳定性,Kafka机器上下线流程繁琐、效率低下,如何提升上下线效率。
开源版本在分配partition时只考虑每台机器Partition数量,不考虑磁盘流量负载情况,也不考虑Topic之间的流量差异,会造成集群中机器间、磁盘间负载不均衡。
开源版本缺少自动均衡和迁移速率控制的功能,这可能会对用户的实时读写造成影响。人工进行迁移和速率控制的操作不仅效率低,而且难以管理。
随着公司业务不断扩大,一套IDC不足以支撑整个公司的服务,如何控制协调多个IDC是所面临的问题。
Kafka 只有一个工作线程池,慢请求可能导致线程池阻塞,影响其他请求处理效率。
三、思考与方案
由于Kafka承载着公司传输的重要职责,集群规模的不断扩大给集群的稳定性和易治理性带来了巨大的挑战。为了应对这些挑战,我们需要开发一套自动化治理系统,来有效地解决目前面临的问题。
Guardian 是一套自研的Kafka federation cluster controller。该服务通过Raft保证了高可用和一致性。此外该服务会从Kafka Server端收集各类数据进行计算和分析,执行治理计划。包含以下功能:
federation cluster的元数据管理与集群
remote storage元数据管理与存储
uuid(topicId, segementId)的分配
收集集群信息进行调度
多租户管理与label隔离
故障预警与自愈
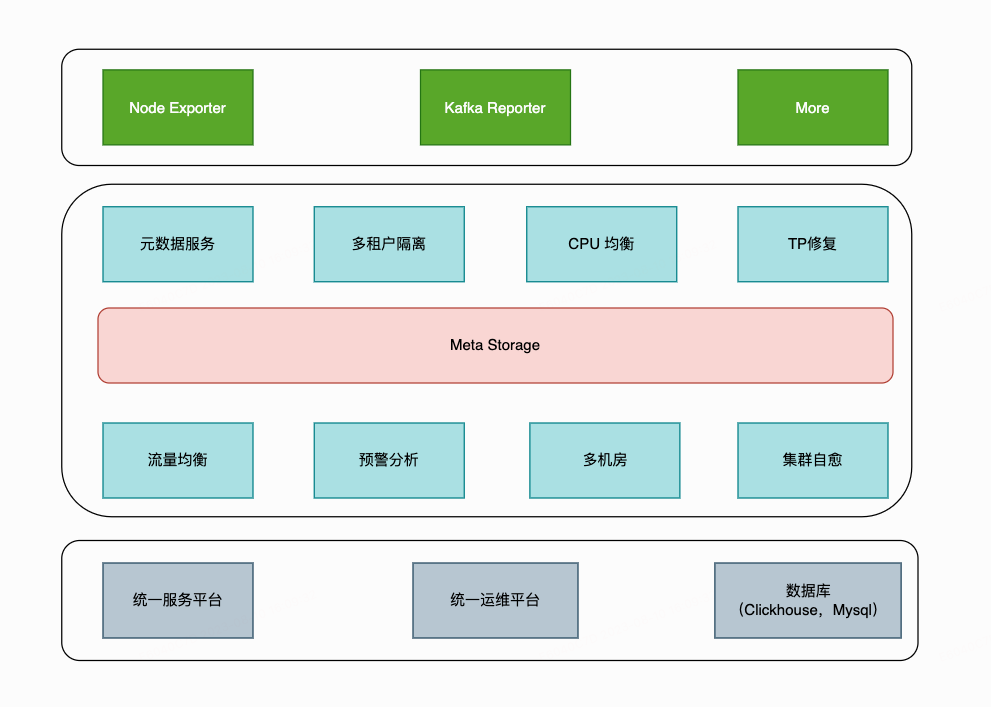
备注:基于JMX协议采集Metrics的性能非常差,这是因为jmx协议一个请求只能获取一个mbean。随着metric的加强,可能达到万级别,此时cpu消耗会占20%甚至更高。Kafka Reporter为基于GRPC,http协议的内置Metric上报服务,只需要一个rpc即可拉取全部监控数据。
1)Partition级别限速保护
①相关背景
Kafka 是一个 I/O 密集型的服务,用户行为不可预测切多变。当用户读取最新数据时,能够从 Page Cache 中高效快速获取,但如果需要从磁盘中读取数据,那么就要考虑如何控制磁盘 I/O 和磁盘资源的使用,以便为用户提供最大的吞吐量。
开源的限速方案存在问题是粗力度,比如限制某ClientId的读速度为5MB/s,那么此Client在某台机器下读取所有订阅的Partition的速度的总和被限制到5MB/s左右,无法精确限制到Partition。
②相关优化
我们的目标是尽可能让磁盘合理且充分地利用。因为Partition是落在一个个磁盘下,为了给用户提供更高的吞吐,我们需要将每个磁盘的资源利用率进一步提高,因此我们给Kafka新增Partition粒度的限速逻辑。为了保证磁盘的正常运行,我们通过管控系统实时监测每个磁盘的ioutil和Latency等关键指标。一旦发现某块磁盘超过了我们设定的阈值,我们就会判断该磁盘的健康度下降,需要进行优化处理。因此,我们会尝试对该磁盘下的io操作进行限速,使得该磁盘的ioutil和Latency恢复到合理水平。
是否读取磁盘数据难以判断,我们实现了一个估算算法,用可用内存大小除以磁盘读写的速率和,粗略估算出一段数据能在PageCache里面存在的时间T,使用Partition的MessageInRate * T 估算出此Partition能在PageCache里面缓存数据条数,用此Partition LEO - MessageInRate * T 如果大于要拉取数据的Offset,那么认为此数据是实际读磁盘数据。
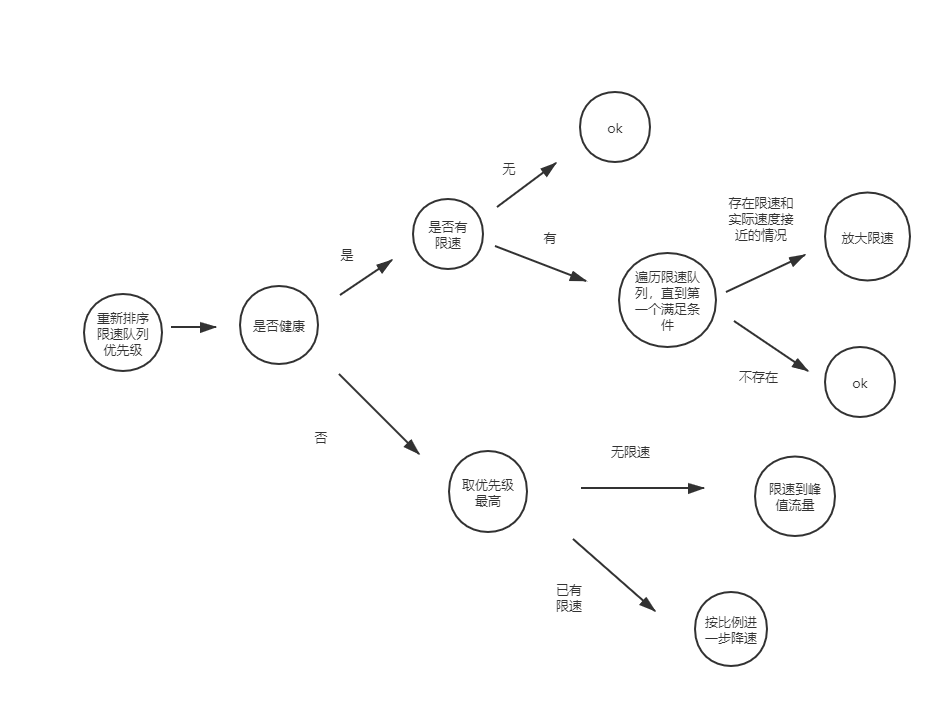
Guardian基于集群监控数据进行集群磁盘的健康度检查,根据每一个分区的监控数据进行根因分析,根据分析结果及时进行限速调整。
磁盘io相关行为分为六种:用户读/写磁盘,主从同步读/写磁盘和磁盘间迁移读/写磁盘。
异常行为:超过预期的写磁盘,任何读磁盘。
对所有异常行为排序的队列我们称之为”异常行为队列“。异常行为队列排序方式为当前流量大到小排优先级。
具体流程如下图所示:
③ Partition级别限速效果
无限速保护,直接安排磁盘搬迁任务:
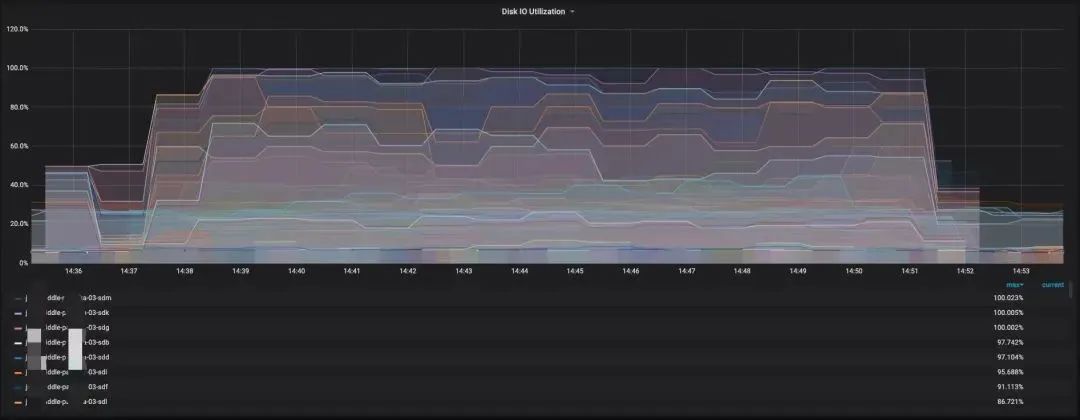
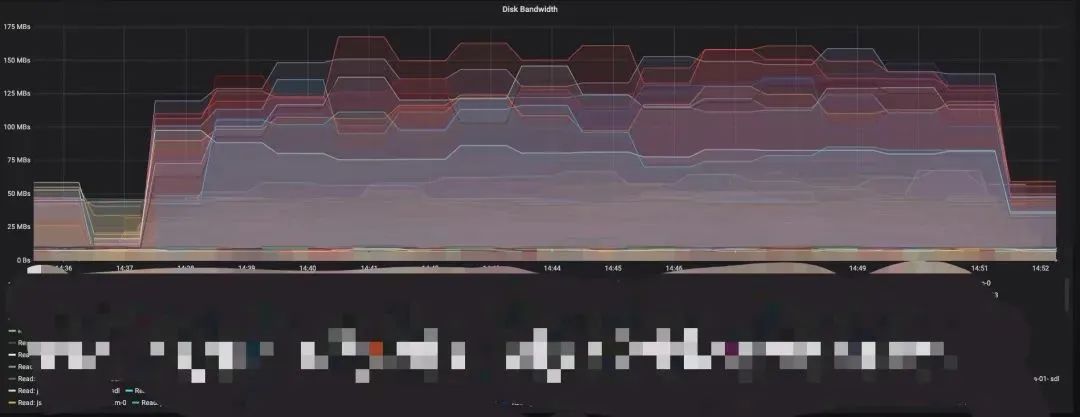
在开启Partition级别读磁盘限速保护后安排磁盘间搬迁任务:
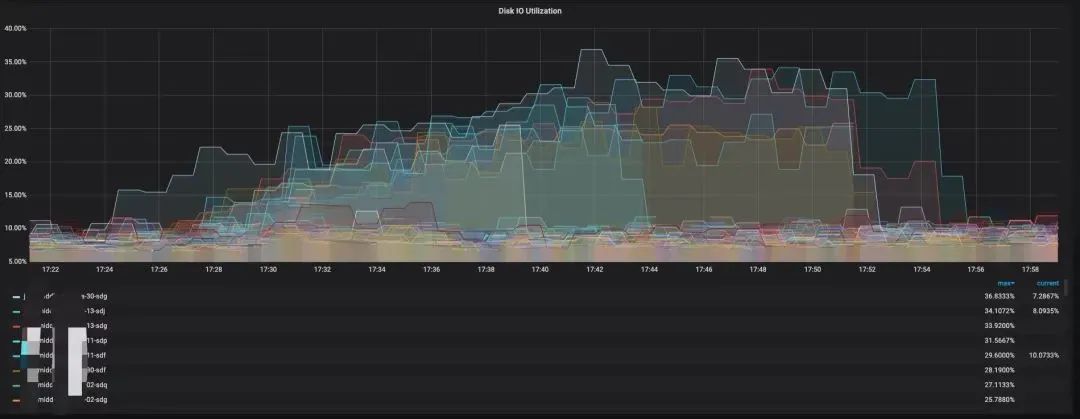
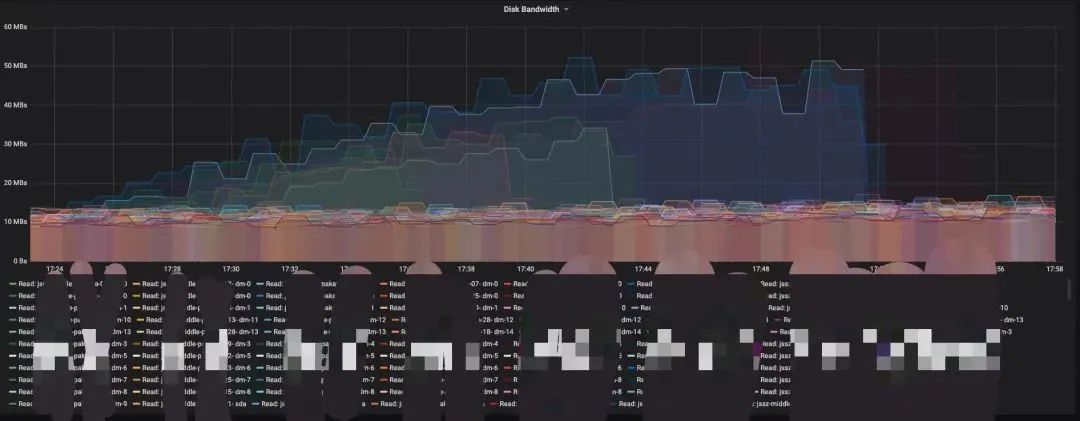
在实际使用中,根据集群状况实时进行自动限速保护的功能对Kafka集群的稳定性做出了很大贡献。
2)自动Partition均衡
①相关背景
为了解决开源 Kafka 的负载分配不均匀导致的磁盘热点问题,我们开发了一种基于磁盘指标、集群 Topic 分布情况和每个 Partition 流量指标的 Partition 自动均衡迁移计划功能。
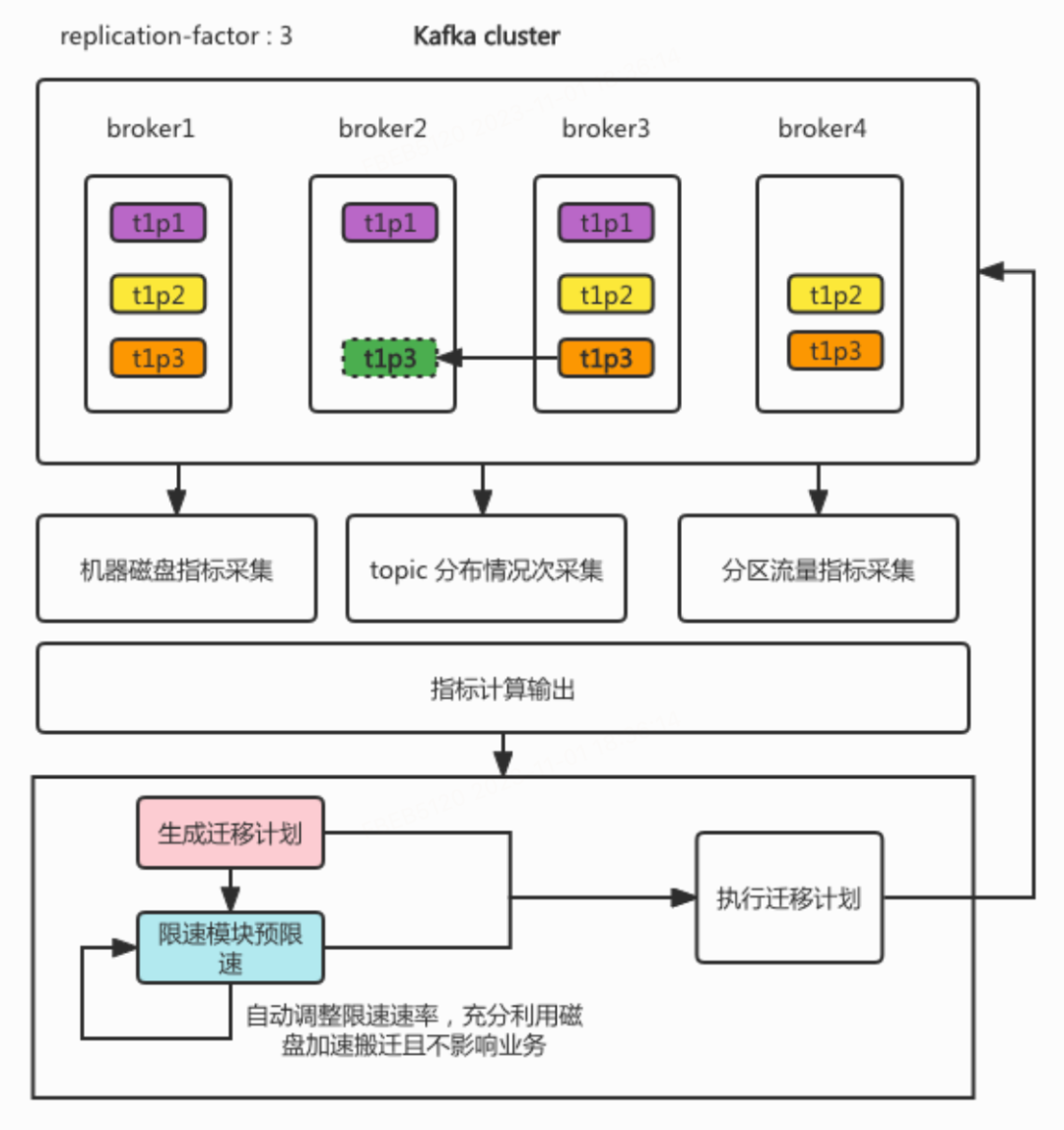
②相关优化(Kafka版本为2.4及以上)
迁移计划。我们根据采集到的数据进行计算,分析哪些机器负载过高,筛选出需要均衡的Partition。生成迁移计划时,会考虑目标机器磁盘的流量负载,通过指标采集模块获取每个磁盘的历史窗口流量负载,然后按磁盘按照历史流量负载中位数进行排序,选择最小的磁盘放入分区副本。
搬迁任务增量提交,解决长尾问题。在集群执行均衡迁移计划时,不同Partition所承载的流量不同,所在的机器负载不同,搬迁所需要的时间也会不同。我们采取增量提交均衡任务,让耗时较长的任务不会阻塞其他任务,保持高效执行。
自动动态调整搬迁速度。一天内不同时间段集群的负载是不同的,我们会根据集群内机器的负载动态调整搬迁的速度,让搬迁任务不会影响到集群的稳定性和用户的使用。
多并发搬迁。我们支持不同集群不同Partition并发的执行搬迁计划,并可控制并发度。
Partition预分配。新建Topic时,我们会根据当前磁盘负载和该Topic的预期估值流量进行计算,生成该Topic 所有Partition的预分配计划。
Leader均衡。为了避免Partition Leader机器严重不均衡造成的机器热点问题,我们会自动生成均衡计划进行Partition Leader均衡。
节点异常、Topic扩容 迁移取消。当某个节点异常,搬迁计划无法顺利执行完成时或当流量上涨需要进行Partition扩容时(开源Kafka不支持在搬迁时进行扩容),我们会自动取消当前所影响的搬迁计划。
3)多租户资源隔离管理
①相关背景
由于各业务场景及优先级不同,我们需要尽可能避免互相影响及互相争抢资源的状况,同时还要避免集群数量膨胀带来的运维及使用问题。由此提出Kafka多租户方案,提高对共享资源的管控,对高优流提供更好的隔离性。
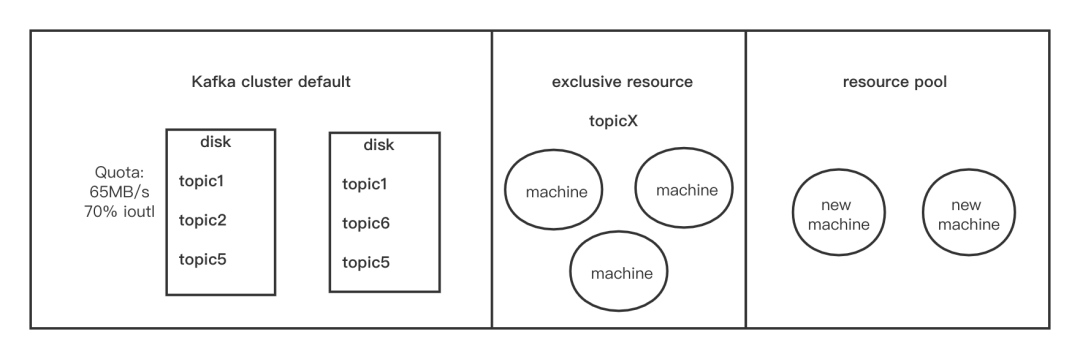
②相关优化
资源独占:
Topic创建:相同业务域的Topic共享独占资源,用户在创建Topic的时候指定对应的独占资源即可,该Topic仅会在独占资源上创建。支持动态调整,任务无感。
机器划分
新的独占资源: 从资源池划所需机器。
已存在独占资源:检查已有资源是否满足新需求,不满足时按需扩容。
独占资源缩容:选择机器,将对应机器上的所有partition迁移到剩余的机器后,机器归还资源池。
支持自动限速保护、自动均衡搬迁功能。
这里的租户概念对应为应用域划分。
4)多机房管理
①相关背景
随着公司的业务拓展,单个IDC不足以支持需求,因此系统需要支持跨idc管理。
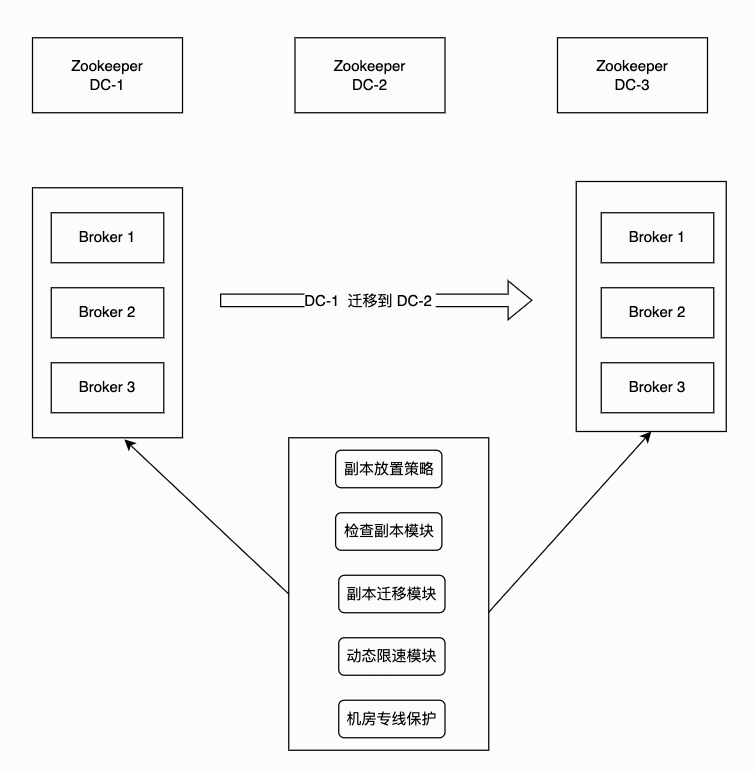
②相关优化
业务迁移idc后,秉承着就近原则,对应的数据也需要迁移idc。我们的系统支持使用方无感的情况下,一键完成不同IDC间的Topic迁移。
按需配置副本放置策略,系统根据所填配置自动生成迁移计划,在迁移的过程中,有限速模块保证集群的稳定性,迁移过程中无需人工干预。
配置粒度可控,从集群级别到topic级别均可。
Topic在迁移过程中,offset保持一致,期间用户读写均无感。
一般相关的业务在同一IDC中,但是也会有多个任务分布在不同机房。我们支持idc感知的从读功能,用户请求时返回就近的副本,在同IDC读取。
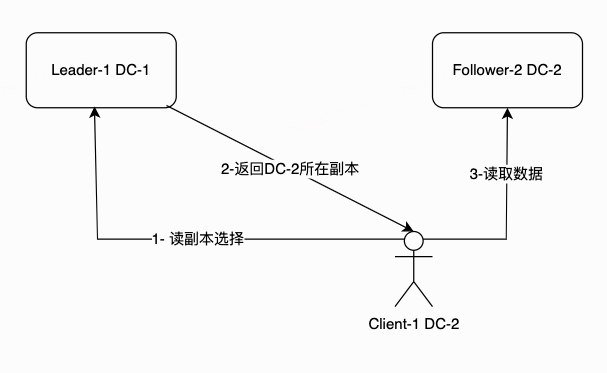
通过上报数据分析,实时计算专线消耗,保护专线。
5)请求队列拆分
①相关背景
一般物理机上有多块磁盘,有较大的内存和较大的CPU。不同公司Kafka的部署方式不太一样,有的选择部署多个实例,一个实例一块磁盘,有的则是部署一个实例,利用Kafka支持多盘的特性。
两种方案各有利弊,我们采用的是后者。一台物理机上有10+HDD盘。一个实例上有上千Partition,上万个连接。如果其中一块磁盘Fail-Slow,或负载特别高,磁盘上的请求耗时会增长很多。假设请求均匀,受影响比例理应仅为1/14 = 7%,但实际会有100%影响(讨论的Kafka版本为2.4.1)。
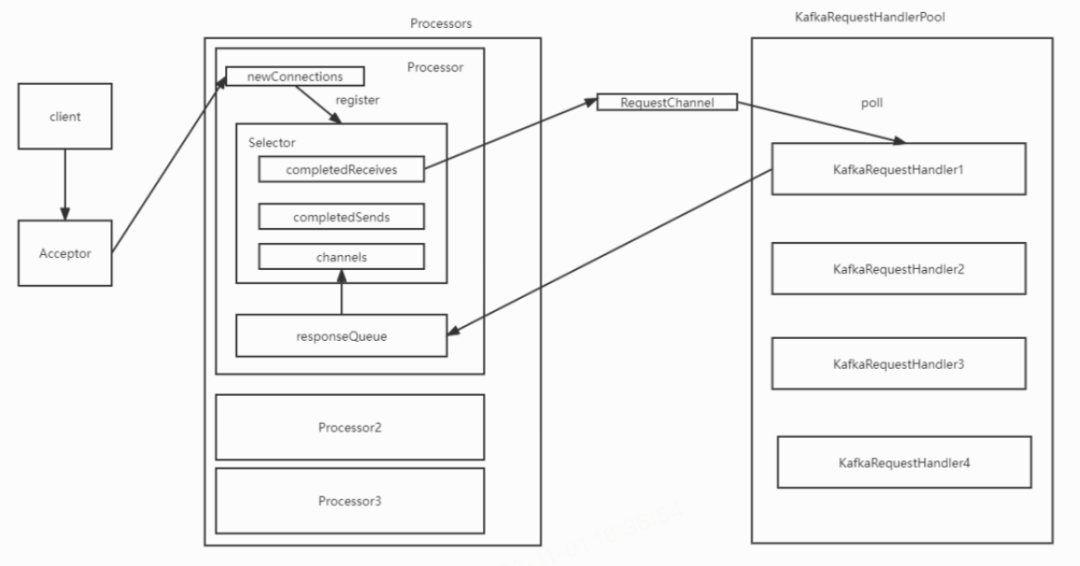
上图为Kafka相关部分的线程模型,涉及的文件有:
core/src/main/scala/kafka/network/SocketServer.scala
clients/src/main/java/org/apache/kafka/common/network/Selector.java
clients/src/main/java/org/apache/kafka/common/network/KafkaChannel.java
core/src/main/scala/kafka/server/KafkaRequestHandler.scala
Kafka虽没使用Netty框架,架构是大同小异的,依然是N个select/poll线程(下文称为Processor线程)处理network io + m个工作线程(下文称为requestHandler线程)。如上文所述,多数情况可以很好工作。
Kafka作为一种分布式消息系统的实现,最主要的工作是收发消息(读写文件),以下我们分别讨论Produce和Consume的部分细节。
Produce:
Acceptor线程: 建立连接后,该连接被投递到了某一个Processor中(roundRobin)。
Processor线程:Client发送请求后,Read Socket,读到一个完整的请求包后将其后放入到requestChannel中。
某一个requestHandler线程:Poll到该Req,经过一系列的校验,定位到Partition对应的File和当前Position后写入,满足一定条件时调用Flush。假设ACK = 1,既Leader写入后就返回成功,生成Response对象(包含已序列化的byte[])写入到对应Processor的responseQueue中。
Processor线程:获取到Response后,Write socket (省略select/poll及粘拆包细节)。
机械磁盘的写是非常慢的(混合随机读写场景),实际上多数produce请求延迟很低,这是因为linux的page cache机制将写磁盘操作转化为写内存,而写内存是非常快的。只有在极个别的情况下(主动fsync,或者达到阈值),才会同步写磁盘。这也是Kafka的produce latency存在毛刺(很多时候看上去有规律),且毛刺远大于均值的原因。
Consume:
Acceptor线程: 建立连接后,该连接被投递到了某一个Processor中(RoundRobin)。
Processor线程:Client发送请求后,Read Socket,读到一个完整的请求包后将其后放入到requestChannel中。
某一个requestHandler线程:Poll到该Req,经过一系列的校验,根据FetchOffset找到对应的Log File Position(先通过Index找到大致位置,然后一个个Batch的读取,直到找到FetchOffset所在的Batch的 Position),假设数据足够多,生成Response(保存了File Position Size的元信息)写入到对应Processor的ResponseQueue中。
Processor线程:获取到response后,调用Sendfile(Zero Copy)发送 (省略select/poll及粘拆包细节)。
注意:在requestHandler和Processor中都有io操作。
类似于Produce,得益于Page Cache机制,大部分读操作仅需要读内存,大多数场景下耗时非常短。
Batch粒度是用户写时决定的,如果用户Batch写入条数过小,就会大大增加Offset寻址次数。在Page Cache Missing时还会产生不可忽略的io负载。(参考core/src/main/scala/Kafka/log/LogSegment.scala LogSegment.translateOffset)。
虽然Zero Copy有上下文切换以及内存Copy的优势,可仍旧是同步io。Page Cache Missing时需要从磁盘读取到Page Cache,而一个Processor负责处理若干Socket的收发,Processor线程的阻塞意味着这些Socket上的Requests也需要忍受额外的Latency。
另一个需要注意的点是使用低版本的Client与高版本的Server交互时,Server需要做Up/Down(Produce/Consume) Conversion来适配Client Version。此时无法直接调用Sendfile发送,而是一个个Batch的读取,转换,然后写入Socket。(参考:clients/src/main/java/org/apache/kafka/common/record/LazyDownConversionRecords.java AbstractIterator.makeNext)
②相关优化
优化基于以下:
每个Client实例(连接)生产特定少数Topic,消费特定少数Partition。
如果能做到线程隔离,保证所有的慢请求与正常请求不共享线程,则正常请求不会受到影响。
慢请求总是集中在部分Partition上,且总是少数。
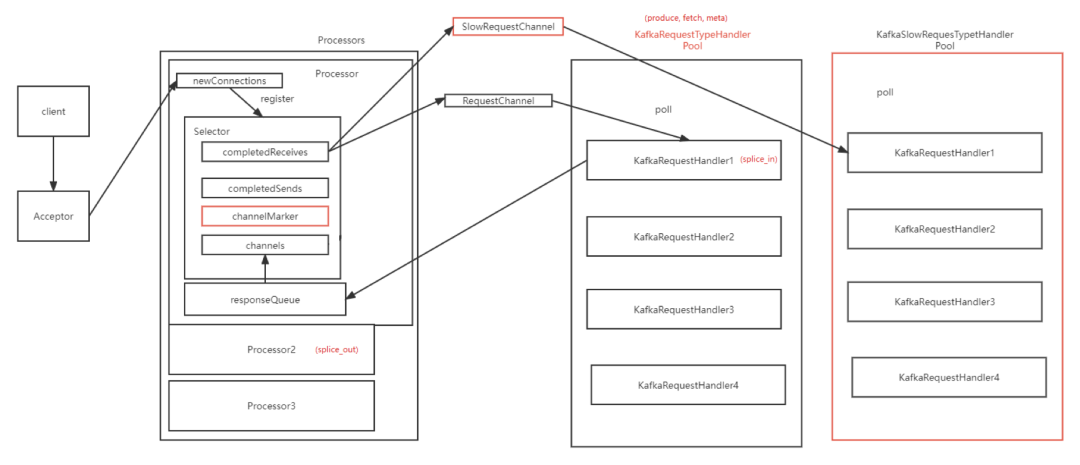
线程模型修改如上图。
ChannelMarker,监控每个Channel(连接)的RequestHandler线程耗时及Processor线程耗时并打分,标记较慢的channel。
RequestHandler根据requestType拆分线程池,Fetch,Produce,Default。并且新增对应的SlowRequest的线程池。1.中标记的channel请求会投递到对应的slowRequest线程池中,保证线程隔离。
如果ChannelMarker不能很好分类,该算法近似于原本的线程模型。另外将其他请求与读写线程池拆分,能尽可能避免Controller与Admin请求超时。
6)Tiered-Storage
①相关背景
Kafka的Partition和磁盘上的目录一一对应,因此有以下问题:
个别磁盘读写量过大,会出现磁盘热点,受限于磁盘性能上限。
迁移需要同步完整数据,导致迁移时间非常长,需要小时级甚至天级,提前治理要求极高。
Partition不支持读写资源分离,读写磁盘会互相影响。
Partition的总数据量取决于磁盘的容量上限,无法满足1周及以上的需求。
任务间的写入消费速度不同,数据过期时间不同和峰谷流量情况不同,导致难以合理规划。
社区提供了一套Kafka Tired Storage 方案,但是也存在很多不足:
社区主推S3作为Remote Storage,缺少基于HDFS的实现。
目前kafka提供的实现是TopicBased,1 metadata per message,且为了保证元数据不丢需要等message发送完成后才能继续工作,partition的增加会加剧该实现的性能问题。
当发生leader stale时,stale leader依然能够写topic,导致脏数据。并且基于compact topic的数据清理也有性能和及时性两方面的问题
remoteLogManager会实时消费metadata topic,忽略本replica无关的partition。reassign partition不会从头消费导致部分metadata丢失。
治理要求依然很高,同步副本数据耗时依然需要30min+。
注:截至今天,kafka已发布(3.6.0)的remote storage相关功能只是early access version,后续可能优化。

②相关优化
我们的目标是将Kafka的Partition和磁盘强绑定关系打破,允许同一个Partition的数据分布在不同Storage层上,并且我们采用HDFS作为Remote Storage。
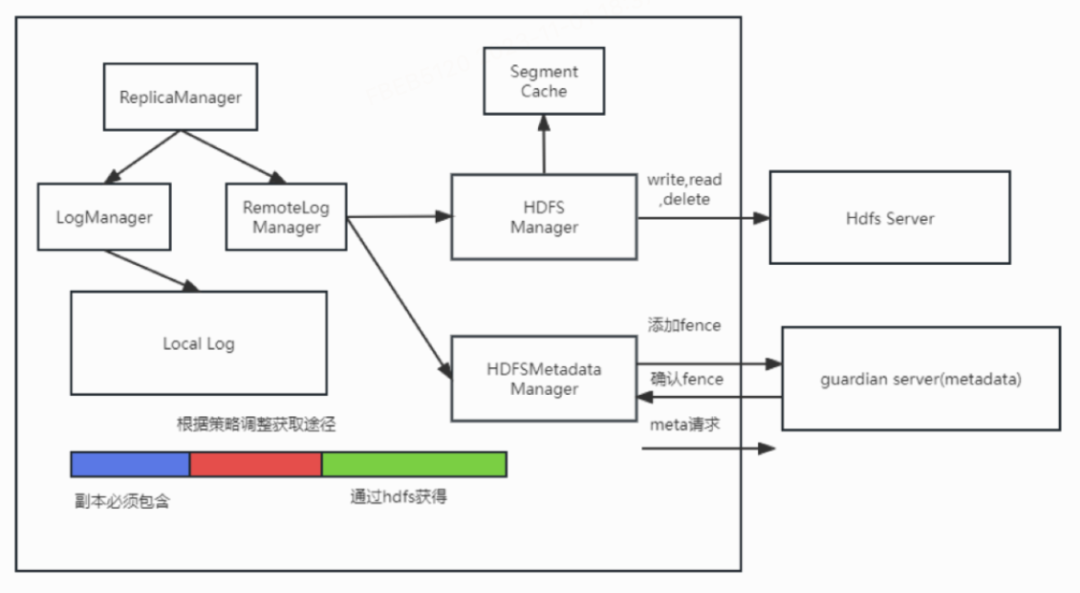
我们设计了分层存储meta服务(基于Raft实现HA)。
官方设计的是通过meta topic来存储meta,但是该方案有个大问题,无法保证数据不丢,且无法高效获取某个partition的meta(需要回放全部数据)。我们倾向于实现自己的Meta Server。Meta Server内部是通过Raft做到一致性及HA的。与Kafka交互的协议上选择GRPC。Meta Server在功能上类似于meta topic,每一组复制,删除都是一个事件组(metaData), 每一个事件组都有自增且唯一的编号,拉取Event 通过这个编号获取。Meta server底层用RocksDB存储,Key为cluster_topic_uuid_id_partition_event_id,Value为事件组的PB序列化Byte,拉取通过rangeScan实现即可。snapshot保存尚未删除的复制信息。
支持基于不同策略的offset拉取模式。
当新的Follower拉取数据时,返回local-log-start-offset。我们自定义了local-start-fetch-offset。该值为 max ( local-log-start-offset,local-log-end-offset - 平均速度 * 阈值 。为什么不用remote-log-end-offset,有可能该值和local-log-end-offset 过于接近,导致过多请求从Remote Storage读取,增加了RS的开销。为什么不用local-log-start-offset,一般我们本地仍会保存若干小时数据,全部数据都备份仍旧需要相当的时间,且这些数据都是在RS上的。出于提速的考量只需要同步local-start-fetch-offset的数据。
大于local-start-fetch-offset的数据,我们通过Local Read获得,在此之前的数据通过Remote Storage获得。Leader尚未完成Meta信息同步时,则Local有的数据都从Local read。Local 没有的数据(小于local-start)由RLM代理尝试获取,直到超时。同步完成但是Remote也没有时OffsetOutOfRange ,Remote有但是Remote故障时等待直至超时。
修改协议支持批量,不再是写一个Segment写一次Meta,增加了Leader Fence保证强一致。
Segment下载到本地Cache后读取,HDFS 1 segment/per read, 大幅降低HDFS负担和时延要求。
减少写RT抖动,降低写延迟 (因为Kafka Broker不再需要存储全部数据了,SSD磁盘的容量限制不再是瓶颈,而SSD的低延时却有极大的优势)。
7)Kafka 审计功能
①相关背景
公司内部使用Kafka的部门非常多,一个Topic经常多个用户在使用,无法精准定位到该Topic的上下游使用者,日常运维难以治理和管控。
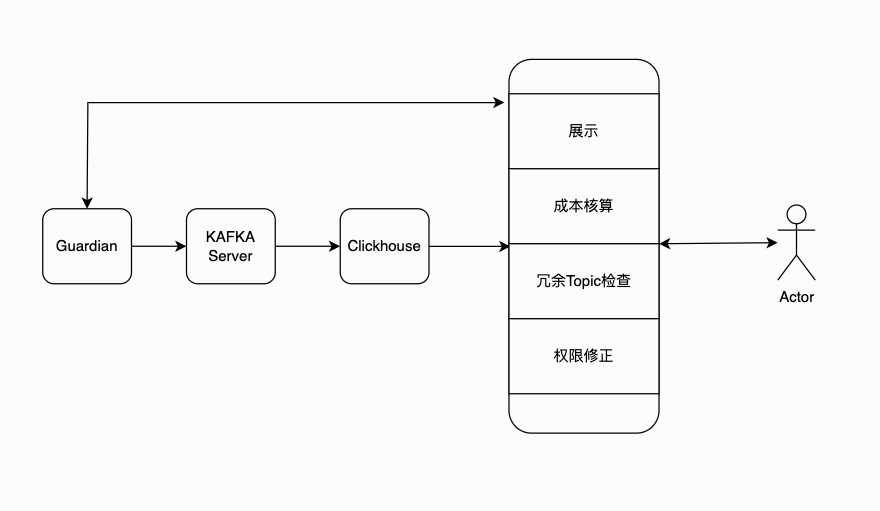
②相关优化
我们对 Kafka 进行了改造,增加了审计功能,可以提供生产、消费等一系列请求的详细数据,并将这些数据实时写入到 Clickhouse 中,方便问题排查。
除此之外,我们支持查询某个时间切片内的机器和集群的详细情况。
基于审计数据,我们实现了成本管理系统,可以有效地治理一些冗余的 Topic,达到降本增效的目的。
利用 Kafka 的审计功能,辅助修正了历史上混乱的 Topic 权限,提升了数据的安全性。
1)集群平滑发布
①相关背景
随着集群规模不断地扩大,如何快速平滑发布成为一个越来越大的难题。

②相关优化
我们开发了一种能够自动批量上下线机器的服务,用户只需选择目标集群,服务就会根据集群的实时状态,在不影响集群服务稳定性的情况下,自动完成机器的上下线操作。整个过程无需人工干预。
机器下线:当某台机器需要下线时,服务会先将该机器作为Leader的所有Partition进行迁移,确保Partition的可用性不受影响。
机器上线:当某台机器恢复正常并重新提供服务时,服务会自动将该机器原先负责的所有Partition恢复到原来的状态。
结果:极大节约人力成本,Kafka滚动升级从15人/天缩短到1人/小时(提单后自动化)、搬迁完全自动化,降低对业务的影响。
四、未来展望
支持分钟级调度。目前迁移的耗时一般在小时级别到天级,下一步是将迁移任务进一步提速,使任务在分钟级完成。
支持分钟级自检自愈系统。目前硬件故障需要人为操作移除故障节点,下一步目标是全自动分钟级摘除。
支持动态扩缩容。目前集群扩缩容完全依赖人为操作,未来集群的扩缩容将完全自动化,服务根据集群实时状态进行分析后自动进行机器扩缩容。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721