
一、背景介绍
作为线上定位问题和排查故障的重要手段,日志在可观测领域有着不可替代的作用。因此,日志系统需要追求稳定性、性能、成本、易用性、可扩展性等关键点。
目前我司的日志系统是基于ELK的,支持云主机、容器日志采集和特殊分类日志的综合采集等功能。但是随着公司的业务发展,日志应用场景逐渐遇到了一些瓶颈:
数据增长和处理需求增加:业务的不断扩张和数据量的增加,原有的日志系统无法满足现有的数据处理需求。数据处理速度变慢,存储空间不足等问题。
数据质量和可靠性要求提高:日志数据对于公司业务和运维至关重要,因此数据质量和可靠性要求越来越高。原有的日志系统存在日志丢失、日志收集慢等问题,需要进行改进。
现状:目前总共运行 8个 ES 集群,机器数量100+, Logstash 机器 50+,需要的硬件和维护成本很高,通过扩容的方法去满足业务场景,ES集群会太大会变动不稳定,创建独立集群,也需要更高成本,两者都会使得成本和维护工作量剧增。
鉴于这些问题,去年下半年开始探索新的日志系统架构,以彻底解决上面的问题。
二、目前主流日志平台对比

三、新的日志平台关键需求
高效支持聚合查询
支持多区域和跨租户查询
降低成本,并能处理 10 倍规模的问题
提高可靠性,简化操作
兼容性:能够无缝迁移现有的ELK平台的数据,无需进行大量修改
最好用户可以继续使用类Kibana 来交互分析日志
高性能采集器:采用高性能的采集器,提高日志收集的速度,降低数据采集延迟。
并行处理:采用并行处理的方式,同时处理多个日志数据流,提高数据处理速度和效率。
四、新架构
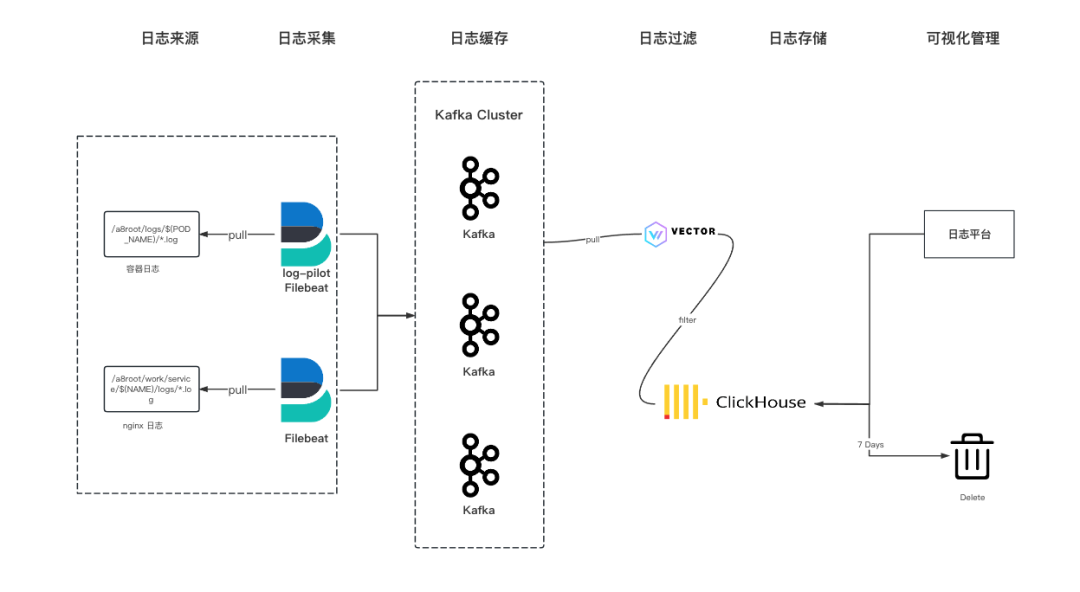
Log-Pilot 是在 Kubernetes 中进行容器日志收集的工具,具有易于部署和使用、支持多种日志来源、实时日志查看和搜索、多种输出方式等优点。支持动态发现配置的能力,采用声明式日志配置,可以自动化日志收集和处理,降低配置的复杂性和出错的风险。缺点是目前已经没有维护者了,存在一定的风险和不确定性,但灵活性和易用性比较好。
Vector 是高性能的可观察性数据管道, 可以收集、转换日志、指标和跟踪信息( logs, metrics, and traces),并将其写到想要的存储当中;可以实现显著的成本降低、丰富的数据处理和数据安全。
Vector 用 Rust 编写, 设计理念是简单、高性能、易扩展和低资源占用,包括自定义 DSL,以一种安全、高性能的方式动态转换数据。同时支持自定义插件来满足更复杂的需求,在性能和资源占用方面表现出色,特别是在处理大规模数据流时。
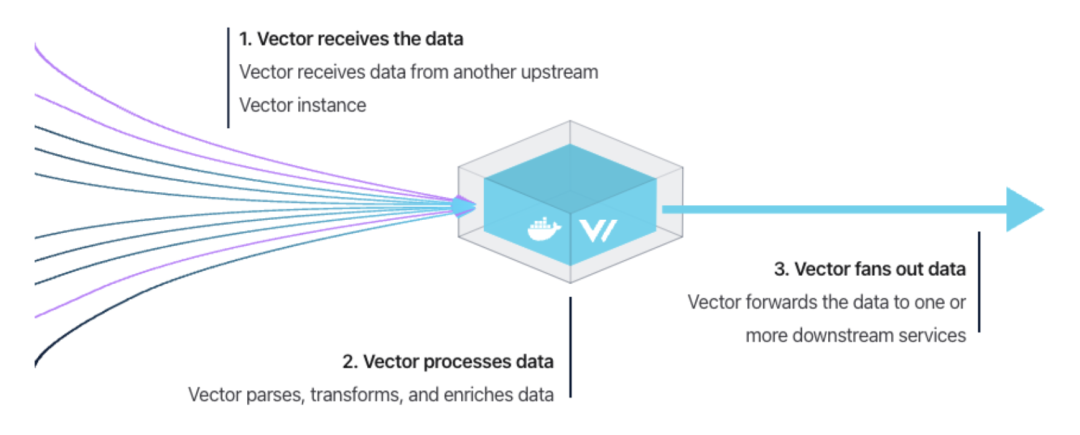
聚合器用于处理从多个上游源收集数据并执行跨主机聚合和分析。vector 既可以用作代理,也可以用作聚合器。
1)vector配置文件
# 来源(sources)[sources.my_source_id] # "数据源"名称type = "kafka" # 类型bootstrap_servers = "10.x.x.1:9092,10.x.x.2:9092,10.x.x.3:9092" # kafka链接地址group_id = "consumer-group-name" # 消费组idtopics = [ "^(prefix1|prefix2)-.+" ] # topic,支持正则# 变换[可选](transforms)[transforms.my_transform_id] # "变换" 名称type = "remap" # 类型inputs = ["my_source_id"] # "来源"名称source = ". = parse_key_value!(.message)" # 以键/值格式解析值# 打印输出到console[sinks.print]type = "console"inputs = ["my_transform_id"]encoding.codec = "json"# 水槽(sinks)[sinks.my_sink_id] # "水槽"名称(数据往哪发送)type = "clickhouse" # 类型inputs = [ "my_transform_id" ] # 输入,这里的输入是上一层的“变换”名称endpoint = "http://127.0.0.1:8123" # 输出的地址database = "default" # clickhouse 数据库名称table = "table" # clickhouse 表名称auth.strategy = "basic" # 身份验证策略auth.user = "user"auth.password = "password"compression = "gzip" # 压缩配置skip_unknown_fields = true # 允许丢弃表中不存在的字段
2)vector写入clickhouse 需要注意的点:
①Vector 自带的自动均衡 topic 功能可以保证数据基本均匀分布。
②合理设置数据批次大小和写入频率,以控制数据写入的速度和频次,降低 parts 数量、减少服务器 merge、避免 Too many parts 异常的发生。使用阈值控制数据的写入量和频次,超过 10w 记录写一次或者 10s 写一次。
batch.max_bytes = 2000000000 # 限制每个批次的最大字节数batch.max_events = 100000 # 限制每个批次的最大事件数batch.timeout_secs = 10 # 限制批处理操作的最大等待时间
③使用分布式表可以将数据拆分成多个 parts 并在不同服务器上进行写入,可以提高写入速度和可靠性。
④在建表时,根据业务需求和数据特性合理设置 partition,避免过多的 partition 和异常的发生。
⑤合理设置主键和索引,避免数据乱序,从而提高写入速度和数据的可查询性。
总之,Vector 提供的自动均衡 topic 功能、合理的数据批次、写入频率、分布式表的使用以及主键、索引的设置都可以对 Vector 写入 ClickHouse 数据库的性能和稳定性产生重要的影响,需要仔细评估和调整。
五、日志存储 - Clickhouse
具有高写入吞吐量:对比 Elasticsearch (ES),ClickHouse 在写入吞吐量方面更加高效;
具有高吞吐量的单个大查询能力;
服务器成本更低;
更稳定,运维成本更低;
ClickHouse 采用 SQL 语法,比 ES 的 DSL 更加简单,学习成本更低。
数据规模和实时性:包括数据量、数据写入频率以及实时性要求。
查询负载和性能需求:包括查询负载、查询复杂度、查询频率、并发性以及对集群性能的需求。
集群管理和维护:包括集群的可靠性、容错性、监控和维护等方面。
重视字段索引创建:将公共约定的常用名称独立成字段,方便添加索引,提升查询效率。
合理选择分区字段:根据业务实际场景,灵活定制设置分区键,针对性优化提高性能。
合并树引擎与排序字段:选用合适的合并树引擎 如MergeTree,排序字段尽可能是查询的字段,充分利用主键索引。
选择合适的压缩算法:更强悍的压缩算法,往往需要牺牲一定的性能为代价。经测试,LZ4查询响应要比ZSTD快30%左右,而LZ4的磁盘占用空间要比ZSTD多2.5倍左右。如果使用LZ4查询耗时为1秒,而ZSTD查询性能为1.5秒左右,虽然秒级的影响对使用方来说,体感并不明显,但高达2.5倍的存储开销却耗费不少。选择合适的压缩算法可以在保证查询性能的情况下,降低存储开销。
# 创建本地表CREATE TABLE [IF NOT EXISTS] [db.]local_table_name ON CLUSTER cluster(name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],...INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2) ENGINE = engine_name()[PARTITION BY expr][ORDER BY expr][PRIMARY KEY expr][SAMPLE BY expr][SETTINGS name=value, ...];# 创建分布式表:CREATE TABLE [db.]d_table_name ON CLUSTER clusterAS db.local_table_name ENGINE = Distributed(cluster, db, local_table_name [, sharding_key])
六、可视化分析平台
在升级日志架构的过程中,很多用户反映希望能够延续之前的日志使用方式,尽量减少迁移学习的成本。为了后续的定制的需求以及后续的扩展,最终决定自研日志可视化查询分析平台。
提供接近 Kibana/阿里云日志服务SLS 的界面,减少用户的迁移成本;
作为排障的入口,和内部其他组件打通,如监控告警,分布式追踪等。
目前的日志平台实现了查询语句高亮和提示、日志时间分布预览、查询高亮以及日志略缩展示等等。
七、监控与告警
ClickHouse提供了丰富的性能监控数据,包括查询的执行时间、内存使用情况、磁盘使用情况、连接数等等。与Prometheus进行集成,可以将ClickHouse的监控数据暴露给Prometheus,再使用Grafana等工具进行可视化展示和分析。
八、成果
ClickHouse 日志系统对接了服务端日志、Nginx 日志等,与原有ELK 架构相比,日志方面的总成本减少了 60%,多存储了 30% 的日志量。
九、后续规划
ClickHouse 的确是一个强大的分析引擎:
SQL 查询中的查询服务支持。
通过自适应使用 PreWhere 和 Where 子句,微调索引粒度,探索跳数索引,并根据更多收集的统计数据微调查询设置,积极改善查询延迟的差异性。
冷热分层存储,提高数据保留率并降低成本。
总体来说ClickHouse的运维比ES简单,主要包括以下几个方面的工作:
新日志的接入、性能优化;
过期日志的清理,按TTL 自动清理;
ClickHouse的监控,使用prometheus+Grafana的实现;
数据迁移,一般不搬迁历史数据,只要将新的数据接入新集群,随着时间的推移,历史数据会被清理下线,当老集群数据全部下线后,新老集群的迁移就完成了。确实需要迁移数据时,采用ClickHouse_copier或者复制数据的方式实现。
常见问题处理:
1)慢查询:通过kill query终止慢查询的执行,并通过前面提到的优化方案进行优化
2)Too many parts异常:Too many parts异常是由于写入的part过多part的merge速度跟不上产生的速度,导致part过多的原因主要包括几个方面:
设置不合理
小批量、高频次写ClickHouse
写的是ClickHouse的分布式表
ClickHouse设置的merge线程数太少了
总结
将日志从ES迁移到ClickHouse可以节省更多的服务器资源,总体运维成本更低;
优化日志查询性能,让ClickHouse在日志分析领域提供更大的价值;
但是ClickHouse毕竟不是ES,在很多业务场景中ES仍然不可替代。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721