
几十年来,数据仓库(data warehouses)一直是企业构建数据平台的主要架构方法。然而,随着云、大数据和 Hadoop 等技术的出现,现代数据平台的发展加速,导致数据湖(data lake)和数据湖仓(data lakehouse)等各种选项的出现。
根据领先的云提供商发表的文章,数据湖仓代表了新一代的数据平台。但每个数据平台架构师都应该问自己的问题是:data Lakehouse 是我的特定用例的理想架构吗?或者我应该选择数据湖或数据仓库?
在这篇文章中,我将探讨这些架构之间的差异,并分析哪种架构在哪些场景中最有效。
一、数据仓库
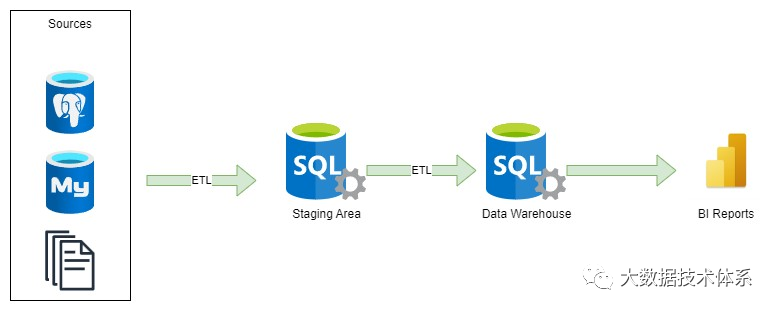
数据仓库架构(DW、DWH),又名企业数据仓库(EDW),几十年来一直是占主导地位的架构方法。数据仓库充当结构化业务数据的中央存储库,使组织能够获得有价值的见解。
在将数据写入仓库之前定义架构非常重要。通常,数据仓库通过批处理进行填充,并由 BI 工具和即席查询使用。数据仓库的设计专门针对处理 BI 查询进行了优化,尽管它无法处理非结构化数据。它由表、约束、键和索引组成,支持数据一致性并增强分析查询的性能。这些表通常分为维度表和事实表,以进一步提高性能和实用性。
数据仓库的常见设计包含一个暂存区,在该暂存区中使用 Informatica PowerCenter、SSIS、Data Stage、Talend 等 ETL 工具从各种来源提取原始数据。然后,使用 ETL 工具或 SQL 语句将提取的数据转换为数据仓库中的数据模型。设计数据仓库的架构方法有多种,包括 Inmon、Kimball 和 Data Vault 方法。
现在,让我们研究一些不同的数据仓库实现模式。有几种体系结构方法可用于设计数据仓库。在这篇文章中,我们将简要概述这些架构。
在企业数据仓库的上下文中,多个部门具有不同的报告要求,因此必须实施数据集市。数据集市(如定义)是专门优化的数据模型,可满足特定业务域或部门的独特需求。例如,营销部门的报告需求将与会计部门的报告需求大不相同。
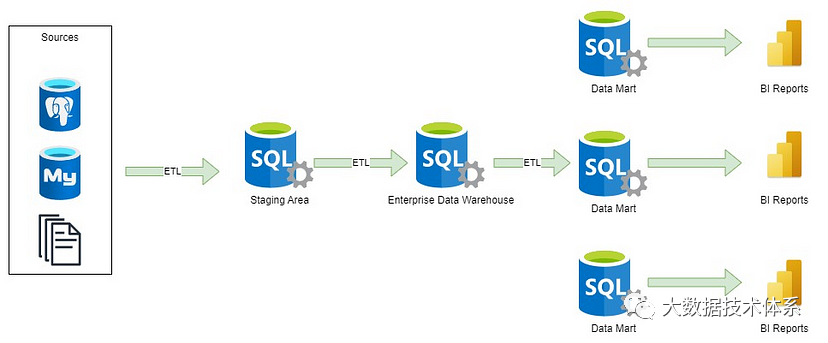
数据平台的另一个重要组件是操作数据存储,专门设计用于存储来自事务系统的最新数据。它与数据仓库 (DWH) 的主要区别在于没有历史数据。操作数据存储旨在促进更频繁地从源系统导入数据。
我们是否需要现代数据平台中的传统数据仓库?答案是:视情况而定。
如果我们正在为银行或保险公司开发一个平台,其中监管报告或BI工具的使用至关重要,那么数据仓库仍然是最佳方法。它确保针对这些特定目的对数据进行结构化、准备和优化。
Azure Synapse、Redshift、BigQuery 和 Snowflake 等技术支持创建可用作数据仓库的标准数据模型。与流行的 BI 工具(如 Power BI、Tableau 或 Qlik)集成,可以生成所需的报告或将数据提取为 XLSX、XML 或 JSON 文件等格式。为了消除对大量 ETL 工具的需求,可以建立一个 ELT(提取、加载、转换)过程来使用直接从源系统中提取的数据。此外,上述所有数据库引擎都支持外部表,这有助于将数据从数据湖导入数据仓库。创建双层体系结构。
我将在本文的后面部分重点介绍它,但简要地说,这种方法支持使用 BigQuery、Redshift 或 Snowflake 等平台创建数据仓库,利用熟悉的 SQL 和 DBT(数据构建工具)和 GCP Dataform 框架等工具来建立满足组织报告要求的 ETL 流程。
但是,重要的是要注意流行的机器学习系统,如TensorFlow,PyTorch,XGBoost和scikit-learn,并没有与数据仓库无缝集成。此外,通常需要分析可能无法在现有数据模型中实现的数据。
优势:
对数据进行结构化、建模、清理和准备。
轻松访问数据。
针对报告目的进行了优化。
列和行级安全性、数据掩码。
酸事务支持。
缺点:
数据模型和 ETL 过程中实现更改的复杂性和耗时。
必须定义架构。
平台的成本(取决于数据库提供程序和类型)。
数据库供应商依赖性(例如,从Oracle迁移到SQL Server时很复杂)。
二、数据湖
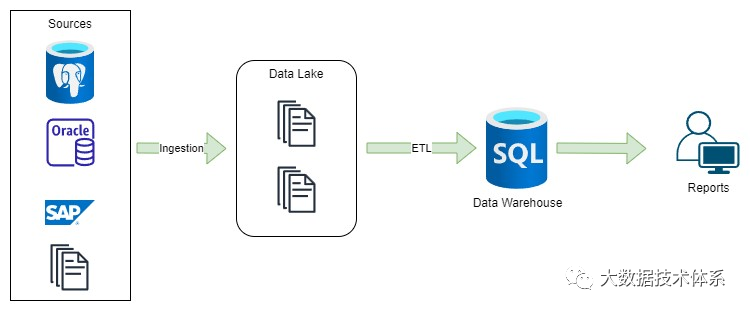
数据湖利用了基于Apache Hadoop(2006)及其Hadoop分布式文件系统(HDFS)构建的文件API的低成本存储。数据以各种格式存储,包括 Avro 和 Parquet 等开放文件格式,以其高效的压缩率和查询性能而闻名。数据湖通过其读时模式方法提供了灵活性。
新的Hadoop和MapReduce技术的引入为分析大量数据提供了一种经济高效的解决方案。但是,仍然存在替代选项,允许将数据子集加载到数据仓库中,以便使用 BI 工具进行分析。
开源格式的使用使数据湖可供各种分析工具访问,包括机器学习和人工智能。尽管如此,这还是带来了新的挑战,例如数据质量,数据治理以及数据分析师MapReduce工作的复杂性。为了应对这些挑战,引入了Apache Hive(2010),提供对数据的SQL访问。大数据平台和数据湖的开源性质促进了众多工具的开发。虽然该平台提供了灵活性,但由于使用的工具种类繁多,它也带来了复杂性。因此,可以在此处找到一个名为“是口袋妖怪还是必应数据?”的测验,允许用户测试他们对该平台的了解。
数据湖开发的下一阶段是引入云环境和数据存储,如S3,ADLS和GCS,它们逐渐取代了HDFS。这些新的数据存储是无服务器的,具有成本效益,以及存档等附加功能。云提供商引入了新型数据仓库,包括Redshift(2012)、Azure数据仓库、BigQuery(2011)和Snowflake(2014)。这有助于实施结合数据湖和数据仓库的两层架构。另一个重大进步是Apache Spark,它支持大规模数据处理并支持流行的编程语言,如Python、SQL和Scala。
1)Medalion
我遇到了几种数据湖设计,目前最流行的是 Medallion 架构。但是,根据特定用例,还会遇到其他模式。
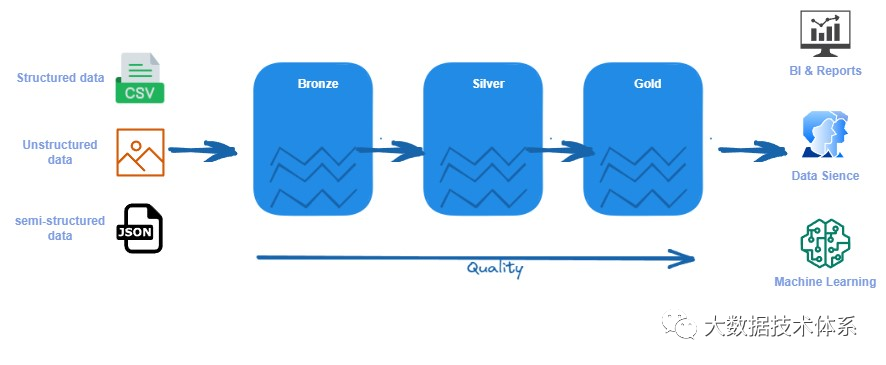
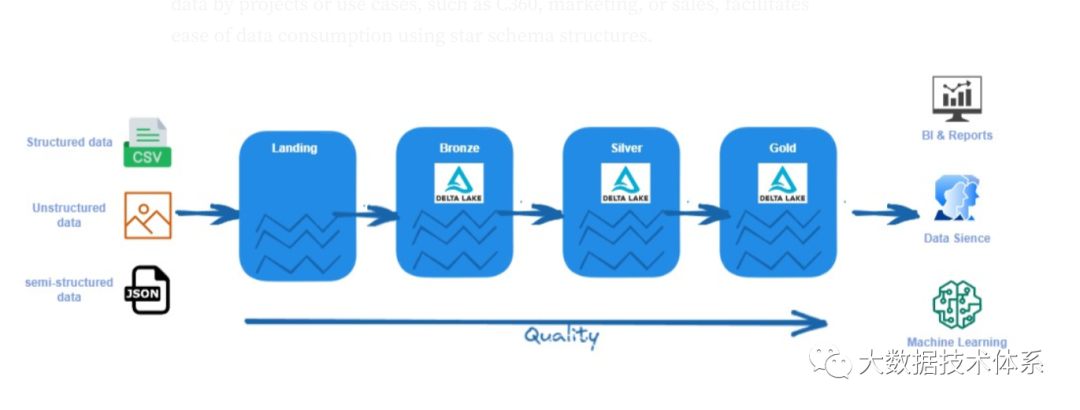
在 Medallion 架构中,bronze层负责从源摄取原始数据并将其转换为Silver层,在那里它以常见的数据格式(如 Parquet)存储。最后,数据被聚合并存储在Gold层中。

青铜(bronze)/原始区域:以其原始格式(如 JSON、CSV、XML 等)存储数据。我们在从源系统摄取数据时保留数据。此数据是不可变的,此处的文件是只读的。此处的文件应组织在每个源系统的文件夹中。我们应该阻止用户访问此层。
白银(Silver)/清理区域:存储可以扩充、清理并转换为常见格式(如 Parquet、Avro 和 Delta)的数据(这些格式具有良好的压缩率和读取性能)。我们可以在这里验证数据,标准化和协调。我们还定义了数据类型和架构。数据科学家和其他用户可以访问此层。
黄金(Gold)/精选区域:这是消费层,针对分析而不是数据引入或数据处理进行了优化。此处的数据可以在维度数据模型中聚合或组织。可以使用 Spark 查询此数据或数据虚拟化。在这种情况下,性能可能是一个问题。您还可以将数据导入 BI 工具,以改善仪表板的用户体验。
Medalion的替代方案可以是我上面提到的两层数据仓库,在这里我将进一步探讨它。在这种方法中,我们在数据湖中有青铜和白银,然后将数据加载到数据仓库中以进行分析。
要加载数据,我们可以使用批量加载命令或外部表。BigQuery,Redshift,Snowflake和Synapse具有此功能,可以从数据湖文件中读取数据并通过ELT过程对其进行转换。这种工作方式提高了集成,尤其是当我们使用具有已定义架构的parquet文件并且读取性能良好时。

例如,我们还可以在单独的存储桶中创建一个存档层,以降低数据存储的成本(我们可以更改存储类型以降低成本)。
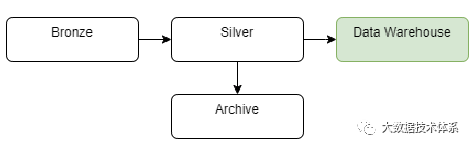
此外,我们可以创建一个产品区域,支持数据工程师和分析师为分析和 ML/AI 目的构建自己的结构和计算。
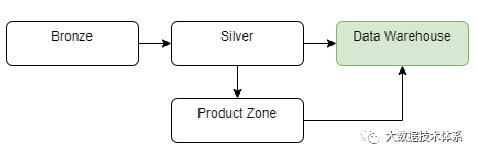
存档区域区域可用于存档旧数据以供将来分析,以降低存储成本。云提供商提供不同类型的存储,这些存储具有不同的访问时间和成本。这是优化数据存档成本的好方法。
产品/劳动区 这是进行探索和实验的层。在这里,数据科学家、工程师和分析师可以自由地进行原型设计和创新,将自己的数据集与生产数据集混合在一起。此区域不能替代测试或开发环境。
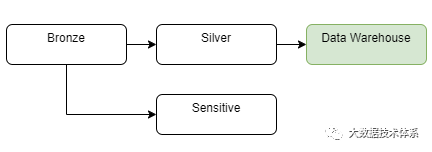
敏感区域是我们需要处理敏感数据的数据湖的另一种设计。通常,只有特定用户才能访问此层,并且访问比数据湖的其他部分更受限制。
为了防止数据沼泽的发生,必须在数据湖中建立简单且自描述的文件夹结构。应实施适当的层次结构,确保文件夹是人类可读的、易于理解的和不言自明的。在启动数据湖开发过程之前定义命名约定至关重要。这些措施将促进数据湖的适当利用,并有助于访问管理。此外,了解如何构造文件夹结构以增强查询引擎对数据的理解也很重要。推荐的方法是以青铜层和银层内呈现的方式组织数据。
-Source-Entity-year-month-date-files
实现此分层结构将有效地管理查询引擎的分区数据。通过在结构化层次结构中组织数据,查询引擎可以有效地导航和访问特定分区,从而优化性能并增强数据检索功能。
-SAS-CTAS-2023–07–07ctas.parquet
-Source-Entity-files
对特定表采用完全加载策略时,可以在不分区的情况下创建文件夹结构。在这种情况下,如果整个表是完整加载的,则可能不需要分区,因为数据不是根据特定条件分段的。相反,可以建立一个简单的文件夹结构来组织和存储完整的数据集。
-Salesforce-accountsaccounts.parquet
在考虑黄金层时,建立面向领域的结构是有益的。这种方法不仅促进了访问管理,还提高了数据湖的利用率。通过在特定于域的类别(如客户、产品或销售)中组织数据,用户可以轻松地导航和利用相关数据来满足其特定业务需求。
-Sales-accounts-accounts.parquet-Finance-time_registraion-time.parquet
当我最初遇到“lakehouse”一词时,我发现自己质疑与传统数据湖方法的区别。当时,AWS 引入了 Athena 和 Redshift 外部表等功能,Glue 目录促进了各种 AWS 服务之间的无缝元数据共享。这一发展使得能够在黄金层内创建数据模型,允许类似于数据仓库中的查询功能。主要提供商实现的 SQL 引擎(如 Spark SQL、Presto、Hive 和外部表)的可用性促进了数据湖的查询。然而,在数据管理、事务 ACID 支持以及通过索引实现高效性能等领域仍然存在挑战。
三、数据湖仓
由Databricks实施的数据湖仓架构代表了第二代数据湖,并通过结合数据湖和数据仓库的优势,提供了一种设计数据平台的独特方法。它作为一个统一的平台,用于容纳数据仓库和数据湖。
Data Lakehouse 架构不仅像传统数据仓库一样支持 ACID 事务,而且还提供了数据湖中存储的成本效益和可扩展性。此体系结构支持直接访问数据湖的所有层,并包括对有效数据治理的架构支持。此外,数据湖仓还引入了索引、数据缓存和时间旅行等功能,以增强性能和功能。它继续支持结构化和非结构化数据类型,数据以文件格式存储。
为了实现Lakehouse架构,Databricks开发了一种名为Delta的新型文件格式(有关文件格式的更多详细信息将在本文后面描述)。但是,作为Delta的替代品,可以使用其他文件格式,例如Iceberg和Apache Hudi,提供类似的功能。这些新的文件格式使 Spark 能够利用新的数据操作命令来改进数据加载策略。在数据湖中,可以执行对表中行的更新,而无需将整个数据集重新加载到表中。
Data Lakehouse主要使用奖章架构来组织数据。正如我提到的,我们有三层数据湖屋青铜、白银和黄金。数据湖屋的主要区别在于文件格式。我们使用 Delta 格式来存储数据。或者,如果我们使用Databricks以外的其他工具,我们可以使用Iceberg或Hundi作为主要数据格式。我们可以通过几种方式组织湖屋中的数据,我将在下面介绍这些方式。
我们用于“按原样”从源摄取数据的青铜。数据在存储中与源系统对齐和组织。如果我们从源导入数据,我们将以 Delta 格式保存。如果数据不支持 Delta,或者当源系统将数据直接转储到存储中时,数据可以由引入工具引入并以本机格式保存。
白银保留使用参考数据或主数据进行清理、统一、验证和扩充的数据。首选格式是增量。表仍与源系统相对应。数据科学、即席报告、高级分析和 ML 可以使用此层。
黄金层托管一个数据模型,供业务用户、BI 工具和报表使用。我们使用增量格式。此层保留包含计算和扩充的业务逻辑。我们只能从白银中获得一组特定的数据,也可以只获得汇总数据。在此层中,表的结构是面向主题的。
组织湖仓的另一种方法是利用Data Vault方法。此方法特别适用于处理大量数据、多个数据源和频繁集成更改的组织。数据保管库模式类似,但它涉及数据建模和组织方面的重要更改。
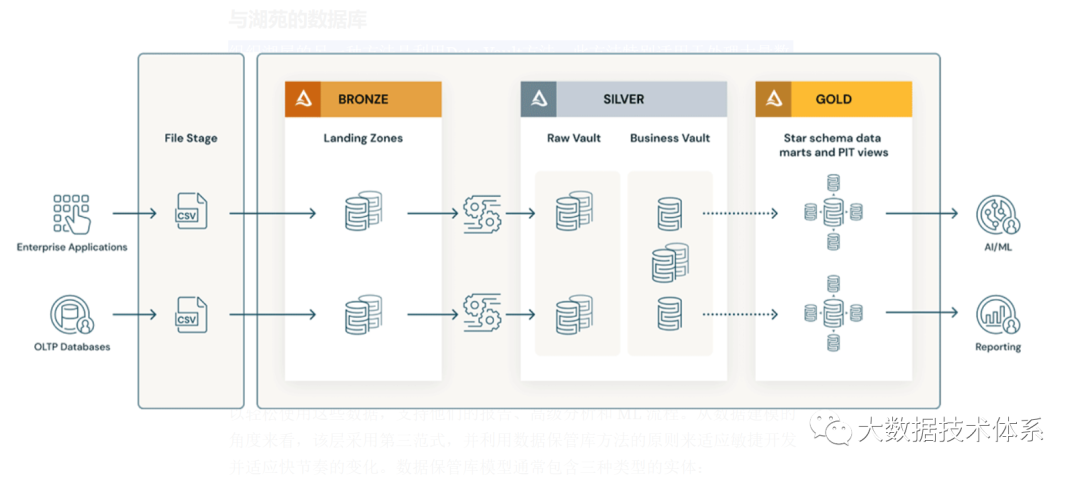
青铜层负责从源系统摄取数据,同时保持原始结构“原样”。可以添加其他元数据列,例如加载时间和批处理 ID。此图层存储历史数据、增量负载和变更数据捕获。从源系统导入数据时,建议以 Delta 格式保存数据以提高性能。在数据以不同格式到达的情况下,实施登陆和暂存区域或其他登陆层可以促进从源系统接收数据。在这种情况下,数据以其本机格式存储,然后在青铜/阶段区域中转换为增量格式。Databricks 自动加载工具可用于简化青铜/阶段区域中的转换过程。
银色层通常称为企业存储库,用于清理、合并和转换青铜层中的数据。用户可以轻松使用这些数据,支持他们的报告、高级分析和 ML 流程。从数据建模的角度来看,该层采用第三范式,并利用数据保管库方法的原则来适应敏捷开发并适应快节奏的变化。数据保管库模型通常包含三种类型的实体:
Hub 代表核心业务实体,如客户、产品、订单等。分析师将使用自然/业务键来获取有关 Hub 的信息。Hub表的主键通常是通过业务概念ID、加载日期和其他元数据信息的组合得出的,这些元数据信息可以使用Hash、MD5和SHA函数来实现。
链接表示 Hub 实体之间的关系。它只有连接键。它就像维度模型中的无事实事实表。缺乏属性——仅连接键。
卫星表具有中心或链接中实体的属性。他们有关于核心业务实体的描述性信息。它们就像维度表的规范化版本。例如,产品中心可以有许多卫星表,例如类型属性、成本等。
这些表是根据客户、产品或销售等域进行组织的。
黄金层充当数据仓库模型或数据集市的基础。遵循维度建模方法(例如 Kimball 方法),该层侧重于报告目的。用户可以利用 BI 工具来使用该层的数据或执行临时报告。还可以在黄金层内建立数据集市,以满足不同部门的特定数据建模需求。按项目或用例(例如 C360、营销或销售)组织数据,有助于使用星型模式结构轻松使用数据。
Delta是Databricks推出的一种开源数据存储格式,旨在提供可靠且高性能的数据处理。它提供 ACID 事务功能、版本控制、模式演化以及高效的数据摄取和查询操作。Delta 通常用于 Apache Spark 环境,支持批处理和流数据工作负载。它提供数据压缩、数据跳跃、时间旅行查询等功能,实现高效的数据管理和分析。
Iceberg是Netflix开发的开源表格式,专为大规模数据湖设计。其主要重点是提供 ACID 合规性、时间旅行功能和模式演化,同时确保出色的性能和可扩展性。Iceberg 与 Apache Spark 和 Presto 等流行查询引擎配合良好。它提供了高效的数据操作、列级统计和元数据管理等功能。Iceberg 允许用户对大型数据集执行快速、一致且可靠的分析。
Apache Hudi 是 Uber 开源的,Hudi 旨在支持柱状数据格式的增量更新。它支持从多个来源提取数据,主要是 Apache Spark 和 Apache Flink。它还提供了一个基于 Spark 的实用程序,用于从 Apache Kafka 等外部源读取数据。支持从 Apache Hive、Apache Impala 和 PrestoDB 读取数据。还有一个专用工具可将 Hudi 表架构同步到 Hive Metastore。
Apache Paimon(incubating)是Apache flink孵化出来的子项目,前身为flink table store。支持高速数据摄取、变更数据跟踪和高效的实时分析。具有如下能力:
1)统一批处理和流处理:Paimon 支持批量写入和批量读取,以及流式写入更改和流式读取表更改日志。数据湖:作为数据湖存储,Paimon 具有以下优势:低成本、高可靠性、可扩展的元数据。
2)合并引擎:Paimon支持丰富的合并引擎。默认情况下,保留主键的最后一项。您还可以使用“部分更新”或“聚合”引擎。
3)Changelog 生成器:Paimon 支持丰富的 Changelog 生成器,例如“lookup”和“full-compaction”。正确的变更日志可以简化流管道的构建。
4)Append Only Tables:Paimon支持Append Only表,自动压缩小文件,并提供有序流读取。您可以使用它来替换消息队列。
四、UniForm
即将推出的 Delta Lake 3.0 旨在为所有三种 OTF 提供通用格式 (UniForm)。目标是让 Delta Lake 表可以像 Hudi 或 Iceberg 表一样访问。UniForm 目前处于预览阶段,存在一些限制。
五、数仓、数据湖、数据湖仓
Lakehouse 是最好的选择吗?通常情况下,答案是“视情况而定”。
决定架构时需要考虑多种因素。例如,如果您打算使用 BigQuery、Snowflake、Synapse 或 Redshift,那么采用两层架构仍然是一个不错的选择。这使您能够利用数据湖的优势,同时在 DBMS 数据库中托管数据模型。值得注意的是,Lakehouse 的概念仍然相对较新,并不像其他建筑范式那么成熟。通过利用数据湖和数据仓库,您可以利用每个平台的优势并利用团队内的不同技能。例如,您的数据工程团队可能会使用 Python 和 Spark,而仅专注于数据仓库的团队可以使用 SQL。
选择数据仓库引擎时值得进行彻底的分析,因为每个选项都有自己的一组考虑因素。这些可能包括并发、自动扩展、计算与存储分离、与 Delta、Iceberg 和 Hudi 等文件格式的集成、与非本地云提供商的有限兼容性、零复制克隆、性能调整、成本、GIS 等因素 支持和维护工作。数据仓库在数据一致性和治理方面提供了强大的功能。它们配备了用于数据验证、数据质量检查和数据治理策略执行的内置机制。事实证明,此类功能对于具有严格数据治理和合规性要求的组织至关重要。
当处理复杂的 ETL 流程以及不需要大量计算能力来表示数据时,两层架构是一个合适的选择。在这种情况下,利用数据湖和 Spark 进行数据处理,并结合 PostgreSQL 等开源数据库来提供数据,可能是一种有效的方法。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721