
数据湖将成为管理大量原始、非结构化和半结构化数据的基础。它可以将历史数据存储为单一事实来源,这对于在不同部门和团队之间保持数据一致性、完整性和可信度是至关重要的。
通过集成Apache Spark、Trino或ClickHouse等计算引擎,data lake变为data lakehouse。这不仅有助于存储大量数据,而且有助于高效处理数据。
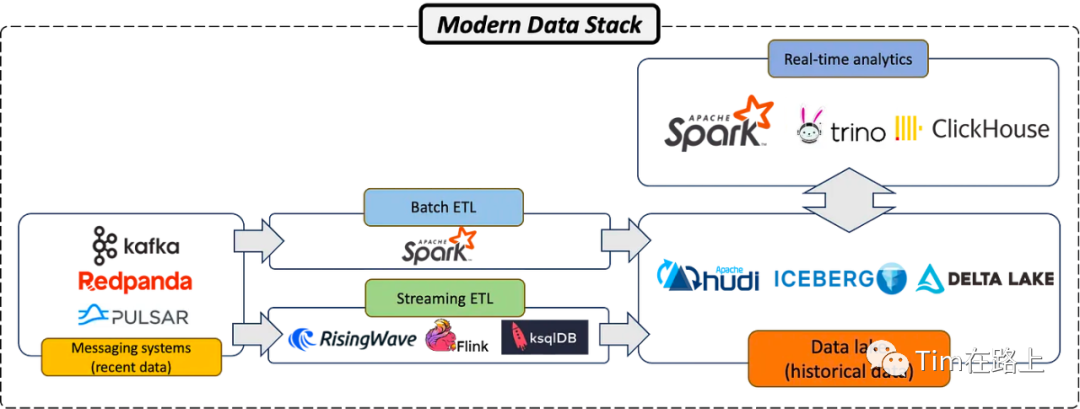
Apache Kafka是一种广泛使用的事件流平台,几乎所有的公司都在使用。起初,Kafka一直被作为数据管道来进行实现,随着其持久化能力与可靠性,它也被视为现代数据技术中的“新兴的数据存储库”。
许多数据工程师使用 Kafka 保存最近读取的数据,通常持续 7 天到一个月,然后再将这些数据传输到数据湖中。
在印象中“事件流平台是针对实时数据的,而数据湖是针对历史数据的”。然而,随着数据组件的发展,越来越多的表明 Kafka 正在演变成一种新形式的数据湖。
一、为什么说Kafka是数据湖?
数据湖是一个集中式存储库,允许您存储任意规模的所有结构化和非结构化数据。与以结构化和有组织的方式存储数据的数据仓库不同,数据湖以原始、本机格式保留数据,通常采用扁平架构。
目前流行的数据湖管理框架有三种,即Apache Iceberg、Apache Hudi和Delta Lake。虽然这些系统都有其独特的功能和优势,但这三个系统都被广泛用于大规模存储和管理历史数据。
它们的设计和功能使处理大量数据变得更加容易,并且它们与 Apache Spark、Flink 等流行计算引擎的集成功能使它们适合各种大数据应用程序和分析用例。
Kafka 本质上非常适合作为数据湖。在讨论 Kafka 是否是数据湖的新形式之前,我们首先检查一下 Kafka 是否具备成为数据湖所需的所有属性。
ACID属性:正如 Martin Kleppmann 在 2018 年旧金山 Kafka 峰会主题演讲“ Kafka 是数据库吗?”中强调的那样。,Kafka 已经发展到包含所有类似数据库的属性,特别是原子性、一致性、隔离性和持久性 (ACID)。虽然许多人使用 Kafka 只存储最近的数据,但 Kafka 实际上具有无限保留性,类似于现代数据湖。这种功能使 Kafka 成为存储大量数据的有吸引力的选择。
分层存储:人们犹豫是否使用 Kafka 存储长期数据的一个关键原因是认为 Kafka 是基于高性能机器的,其使用价格昂贵。但这已经是曾经的事实,Kafka 的经典设计需要将数据存储在计算实例中,这可能比对象存储或HDFS存储昂贵得多。然而,这种情况已经改变。Confluence 构建的最新版本 Kafka以及Redpanda和Apache Pulsar等其他流行的事件流平台都采用了分层存储,将冷数据存储在廉价的对象存储中,从而降低了成本并使得持久数据成为可能。这种新设计使 Kafka 适合以低成本存储大量数据,而无需担心可扩展性。
存储实时数据:虽然许多人使用数据湖来存储历史数据,但现代数据湖正在不断发展并变得越来越实时,例如越来越多的人使用数据湖来支持流批一体的能力。这种演变是自然的,因为现代应用程序和设备可以连续生成大量数据。因此,数据湖正在实施优化以允许实时提取数据。作为一个事件流平台,Kafka 本质上支持实时数据摄取。其架构非常适合存储快速移动的实时数据和缓慢移动的历史数据。
存储不同类型的数据:Kafka 可以处理多种数据类型,从关系数据等结构化数据,到 JSON 和 Avro 等半结构化数据,甚至文本文档、图像和视频等非结构化数据(尽管不常见)。这种多功能性在当今多样化的数据环境中至关重要,它使 Kafka 能够充当组织所有数据的集中存储库,从而降低管理多个存储解决方案的复杂性和开销。
二、Kafka适合成为新的数据湖吗?
Kafka 拥有数据湖的所有属性,但 Kafka 是否有潜力成为生产中的新数据湖?
这里有支持这个观点的理由:
作为Data Source:许多业务直接将数据提取到 Kafka 中,然后再将其传输到数据仓库或其他存储系统中。如果使用Kafka作为永久保留数据的数据湖,就消除了在不同系统之间重新定位数据的必要性。消除数据移动不仅可以降低成本,还可以最大限度地减少数据不一致和丢失的可能性。
单一事实来源:利用 Kafka 作为数据湖意味着它可以作为整个组织真正的单一事实来源。数据不一致的发生是因为人们转换数据。但如果我们使用数据源作为数据目的地,那么我们就不会遇到任何数据不一致的问题。此外,这种方法通过减少需要维护、同步和集成的系统数量,显着简化了数据架构,从而使基础设施更易于管理、更不易出错且更具成本效益。
丰富的生态系统:Kafka 拥有非常丰富且强大的生态系统,用于从各种数据源获取数据,并且大多数计算引擎可以轻松使用来自 Kafka 的数据。这种灵活性极大地促进了 Kafka 与现有系统和工作流程的集成,从而减少了采用 Kafka 作为数据湖所需的工作量和复杂性。此外,Kafka 的功能不仅仅限于数据摄取和存储。它还本身提供轻量级流处理功能(通过Kafka Streams),这意味着数据可以在摄取时实时处理。对于需要实时分析和决策能力的组织来说,这是一个显著的优势。
三、Kafka能取代现有的数据湖组件吗?
首先我的答案是否定的,至少在不久的将来不会。
尽管 Kafka 能够存储实时和历史数据,但这并不意味着它将取代广泛使用的数据湖管理组件,如 Apache Iceberg、Apache Hudi 和 Delta Lake。
这些数据湖管理框架针对大规模数据存储进行了优化,同时保持了 ACID 属性。从功能上来说,Kafka 尚未整合关键功能,例如用于压缩的数据类型感知、对查询下推的支持以及对更新和插入的支持,对列式数据的支持,这使得它在提供历史数据方面的吸引力较低。
近期可能采用的架构是利用Kafka作为统一的读写接口,将热数据和温数据存储在Kafka中。然后,冷数据可以在用户不知情的情况下透明地从 Kafka 逐步过渡到 Iceberg/Hudi/Delta。
这种方法利用了 Kafka 和现有数据湖的优势。用户可以直接调用Kafka API继续读写数据,无需考虑底层结构和数据格式。这意味着底层数据转换和存储机制的复杂性被从最终用户手中抽象出来,简化了他们与系统的交互。
四、使用 Kafka 构建流数据 Lakehouse
Lakehouse融合了数据湖和数据仓库的最佳功能,它提供了一个统一的平台,可以处理大量结构化和非结构化数据,并支持高级分析和机器学习。
随着Kafka演变成一个新的数据湖,本质上可以构建一个可以存储和处理实时数据和历史数据的“流式的Lakehouse”。
在 Kafka 之上构建流数据 Lakehouse 至少需要两个关键组件:
流处理系统。第一个基本组件是流处理系统,例如Apache Flink,Spark Streaming。这些系统旨在处理存储在 Kafka 中的实时数据流,使企业能够通过分析生成的数据来做出更快、更明智的决策。
实时分析引擎。第二个关键组件是实时分析引擎,例如 Apache Spark、Trino 或 ClickHouse。这些引擎旨在分析处理后的数据、提供见解并促进决策。它们能够以低延迟处理大量数据,这使得它们非常适合基于 Kafka 构建的流数据 Lakehouse 架构。
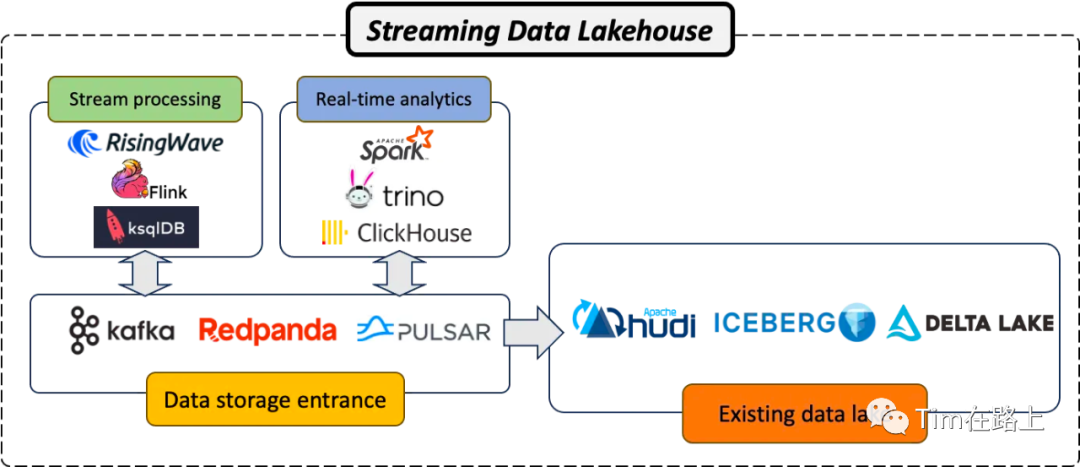
通过将 Kafka 与强大的流处理系统和强大的实时分析引擎相结合,企业可以创建能够处理现代数据处理和分析需求的流数据 Lakehouse 架构。
该架构使组织能够最大限度地发挥数据的价值,提供实时洞察,从而推动更好的决策并创造竞争优势。
五、Kafka成为真正数据湖还需提供的能力
虽然 Kafka 非常强大且用途广泛,但如果 Kafka 真正演变成一个数据湖,那么还有一些需要改进的地方。
压缩的数据类型感知。目前,Kafka 将数据视为字节数组,不知道数据的实际结构和类型。这种意识的缺乏意味着 Kafka 执行的压缩是通用的,并且不如理解数据结构时的效率高。如果 Kafka 能够了解它正在处理的数据类型,它就可以更有效地执行数据压缩。这一改进将通过最大限度地减少需要传输和处理的数据量来降低存储需求并优化分析查询的性能。
支持查询下推。查询下推是一种将查询的部分内容(例如过滤器)下推到存储层的技术,从而实现更高效的数据检索和处理。目前,Kafka不支持查询下推,这意味着所有数据都需要加载到内存中并进行处理,即使只需要一小部分数据。如果 Kafka 能够支持查询下推,那么它将通过减少需要加载到内存和处理的数据量来提高分析查询的性能。
支持更新和删除。目前,Kafka 被设计为仅追加日志,虽然有处理更新和删除的解决方法,但它们并不像传统数据库那样简单和高效。如果Kafka能够原生支持更新和删除操作,那么数据维护将会变得更加简单和高效。它还将使 Kafka 成为一个更完整、更通用的数据存储解决方案,从而提高其作为数据湖的适用性。对于许多组织来说,这一新增功能将改变游戏规则,简化其数据架构并减少与数据维护相关的开销。
结论
如果Kafka完成了数据湖能力的支持,那么对于整个数据产品来说就是一次整合和变革,将根本性缩短现有的数据处理链路,同时可以统一数据源,减少数据产品间的转换适配等成本。
Kafka天生的“流式底子”能力,也正代表了现代数据架构的转变,加上流处理系统和实时分析引擎,使其成为构建流式湖仓一体架构的坚实基础。此外,它对数据持久化的支持、以及作为单一事实来源的能力和丰富的生态系统进一步巩固了其作为可行的数据湖选项的地位。
我是希望数据下层组件们最好能够统一下,不同特定领域数据存储数据引擎事实上本身是有很多共通点的。当前不同数据组件间数据的共享已然成为很大的成本项,也造成了体验感差的问题。最后让我们看看Kafka和其他事件流平台在不久的将的发展,是否可以实现简单统一的数据源平台框架。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721