
Github: https://github.com/ByConity
自 ClickHouse Inc 宣布其重要新功能仅在 ClickHouse Cloud 上开放以来,一些关注 ByConity 开源的社区小伙伴也来询问 ByConity 后续开源规划。为回答社区疑问,我们将之前分享的关于 ByConity 与 ClickHouse 相关功能对比的 webinar 整理为文章,并更新 ByConity 0.2.0 所发布最新功能与 ClickHouse 对比内容,帮助社区小伙伴了解 ByConity 开源社区规划与进展。
ByConity & ClickHouse 使用视角对比
一、架构和组件
ClickHouse 是典型的 MPP 架构,节点对等,所有的功能都被放在 ClickHouse server 组件中。当部署 ClickHouse 集群时,主要是把 ClickHouse server 部署在一组物理机上。
1)分布式表 & 本地表
ClickHouse 提出了分布式表的概念,当 Client 做查询时,首先连接节点找到分布式表,通过 sharding key 的定义以及集群的配置知道分布式表对应的本地表及分布节点。再通过两阶段的执行,先到节点上做本地表的查询,再把查询结果汇聚到分布式表,然后再返回给客户端。
2)Replicas
ClickHouse 提供数据复制的能力,通过对每一个本地表配置 Replica 进行数据复制。不管是分布式的执行,还是数据的复制,都需要 Coordinator 进行节点之间的通信,包括任务的分发等。
3)Zookeeper & ClickHouse Keeper
ClickHouse 之前通过 Zookeeper 提供 Coordinator 能力,部署一个 ClickHouse 集群需要同时部署一个 Zookeeper 集群来承担对应的工作。后来发现 Zookeeper 集群存在很多局限性,在大规模分析型数据查询中会碰到很多性能瓶颈和使用问题,因此进行了一定改进,用 C++ 和 raft 协议实现了 ClickHouse Keeper 组件。ClickHouse Keeper 提供两种部署方式,既可以像 Zookeeper 一样作为单独的集群去部署,也可以放在 ClickHouse server 里跟 ClickHouse server 一同部署。
ByConity 是存算分离的架构,整体架构主要分为三层:服务接入层、计算层和云存储层。
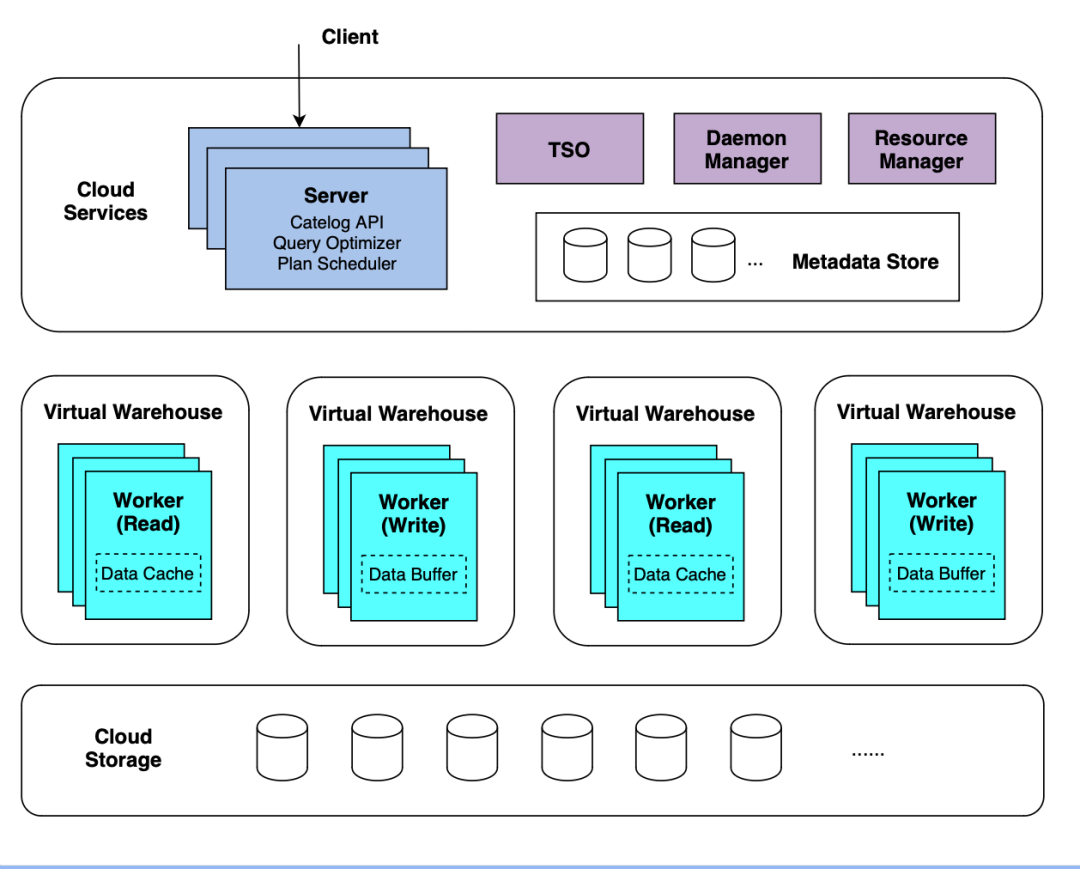
1)服务接入层
由一组 server 和共享的服务组件组成,包括 TSO、Daemon Manager、Resource Manager。
Server
服务接入层的 server 是做所有查询的入口,当 Client 连接 server 时,server 会先做查询的前处理,包括 SQL 解析、查询优化,生成 Query Plan。每个 Query Plan 由多个 PlanSegment 组成,server 负责把 PlanSegment 下发给 worker 做具体计算。
查询过程中会涉及到元数据的管理,比如需要知道库表、字段的定义及统计信息,如 Part 的信息等等,server 就会跟元数据的存储交互。元数据在 ByConity 目前采用 Foundation DB 来实现。
TSO:TSO(Timestamp oracle)是提供全局唯一单调递增的时间戳。在分布式事务的时候非常有用。在后面的事务部分将会介绍。
Daemon Manager:用来调度和管理任务。ByConity 的分层架构涉及到管理节点,对应提出了后台任务的概念,如 merge、实时数据导入时 Kafka 的 consumer 等,都作为后台任务来进行。后台任务的集中管理和调度都由 Daemon Manager 来实现。
Resource Manager :顾名思义用来管理资源。计算层的 Virtual Warehouse 以及 worker 都由 Resource Manager 管理,分配查询和数据写入应该由哪个 worker 执行;Resource Manager 同时做一定的服务发现,如有新的 worker 加入或新的 Virtual Warehouse 创建时,Resource Manager 能够发现。
2)计算层
计算层由一个或者多个 Virtual Warehouse (计算组)构成,执行具体的计算任务。一个 Virtual Warehouse 由多个 worker 构成。
计算层为无状态的一层,为了查询的某些性能,这里会有 Disk 的参与,把一些数据缓存在 worker 本地做 disk_cache。在 ByConity 的查询中有冷查(第一次查询)和热查的区别,冷查需要从远端的云存储把数据拉到 disk_cache,后续查询可以直接重用 disk_cache 的数据,查询速度更快。
3)云存储层
采用 HDFS 或 S3 等云存储服务作为数据存储层,用来存储实际数据、索引等内容。
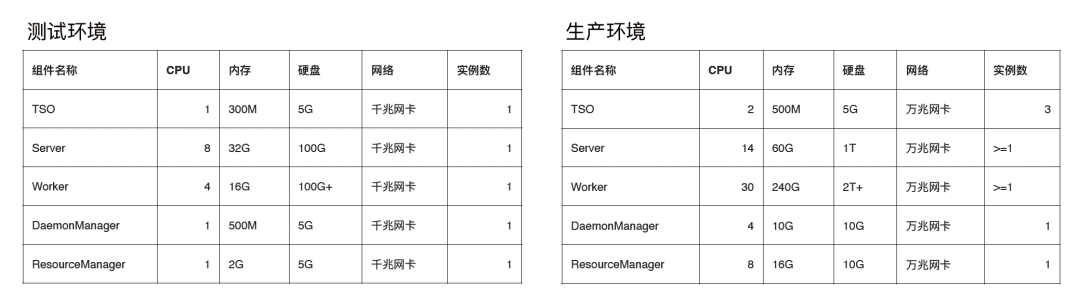
在部署 ByConity 时,不同的组件有不同的硬件要求。对一些共享服务,如 TSO、Daemon Manager 和 Resource Manager,其资源需求相对较低且比较固定;server 和 worker 所需资源相对较多,尤其是 worker,需要根据不同的查询场景部署到不同的硬件规格上。
ByConity 社区推荐使用 Kubernetes 来部署,可通过官方提供的工具和脚本来实现自动化操作,集群后期的运维管理也更方便。具体的部署方式可在文档中查看:https://byconity.github.io/zh-cn/docs/deployment/deploy-k8s
由于部署 ByConity 也包括元数据以及远端的存储,即使部署测试环境也有前置要求,即 HDFS 和 Foundation DB。如本身已有环境,可直接进行配置使用。如果没有,可参考对应的部署文档进行设置。
ByConity 的架构演进源于字节在使用 ClickHouse 过程中所遇到的痛点。ByConity 的组件虽然比较复杂,但设计这些组件有其对应的优势。
1)资源隔离
资源隔离是一个业务高速发展中集群环境变复杂的过程中不可避免的问题。资源隔离有多个层面。
租户隔离,在 ToB 的业务上指多租户;在企业内部一般指各个业务线之间在共享集群上的业务隔离。不同的业务线之间通常希望独占部分系统资源,在进行分析、查询这些工作时可以相互不影响。这里必然也伴随着计算资源的隔离。
读写分离,由于读操作和写操作对硬件的要求、发生的时间以及热点都不一样,通常希望读写之间也不要互相影响,能够分开用不同规格的资源去跑。
冷热分离,一般指冷数据和热数据的存储能够用不同的硬件资源分离,一方面可以减少成本,另一方面也可以让冷热不同的查询之间不受影响。比如说如果有缓存的话,冷查询不会冲掉热查询的缓存,进而对热查询造成性能影响。
2)ClickHouse 的资源隔离
ClickHouse 没有在架构层面对资源隔离做专门的设计,因此 ClickHouse 在做上述这些资源隔离时需要单独的方案。
读写分离可以通过精准配置 replica(部分专门负责读,部分专门负责写),结合 load balance 策略以及集群的部署方式做一定的区分。但此方案有一定局限性,一是运维成本较高,需要手动精准控制。二是读写分离的资源不方便重用,专门用来负责写的 replica,在读请求高峰时无法 serve 读请求。
冷热分离可以通过 TTL,TO DISK,TO VOLUME 的功能,把冷数据和热数据分别指定不同的存储介质去存储。存储方面能够带来成本节约的好处,但是在计算层面依然使用同样的资源,无法做到分离。
3)ByConity 的资源隔离
ByConity 可以通过 Virtial Warehouse 部署和使用实现多级资源隔离。由于 Virtial Warehouse 是无状态的,可以针对不同业务、不同场景按需创建。Virtial Warehouse 的创建操作是无感的,所包含的 worker 的创建也比较灵活。不同的 Virtial Warehouse 之间资源独占,可以比较轻松地实现上述隔离。
租户隔离:不同的业务线可以根据各自需求创建不同的 Virtial Warehouse,对计算资源可以天然做到物理隔离。计算资源也可以在计算热点不同时做调整,实现成本控制和节省。
读写分离:ByConity 的设计要求用户在部署时指定好读和写操作分别使用哪个 Virtial Warehouse,系统会自动地根据不同的读写请求把计算转发到不同的 Virtial Warehouse 中,其天然具备读写分离的能力。
冷热分离:从存储上来讲,因为 ByConity 存算分离,所有的数据都会落在远端存储中,不需要做数据冷存介质和热存介质之间的区分,所有的数据都会有完整的一份在远端存储中。由于 disk_cache 的存在,热数据有缓存加速,且所有热数据的载入不需要用户介入,都是自动计算的过程,可以根据查询把所需要的热数据载入到 worker 本地。
扩缩容是在业务不断增长的场景中必须要考虑的话题。业务在爆发式增长的过程中,可能每两周就需要对集群进行一次扩容,每次扩容都需要伴随很多操作,带来很多的成本。因此扩缩容不得不考虑。
1)ClickHouse 的扩缩容
ClickHouse 架构层面未专门考虑扩缩容。ClickHouse 的扩缩容需要通过一定手段来实现:
扩容副本,通过使用新的节点来部署新的 ClickHouse server,并把副本转移到新的节点上。但是副本扩容之后需要一定的时间进行复制,并且需要对复制的成功率及结果进行校验。这些操作都需要运维手动去做,没有专门的功能支持。
扩容分片,通过增加 Shard 把新的分片部署到新的节点。这种方式会导致数据无法再均衡,即老的数据依然落在老的分片上,在进行具体查询时不同节点上的数据分布不均,需要进行数据再均衡。而数据再均衡的过程在 ClickHouse 中无法自动实现。
2)ByConity 的扩缩容
ByConity 是基于存算分离的无感弹性扩缩容,通过 Virtial Warehouse 和 worker 来实现。
业务隔离:Virtial Warehouse 可以根据不同的业务线去创建,其创建和销毁均无感。
负载隔离:每个 Virtial Warehouse 可以根据业务量的变化调整 worker 的数量。具体来说:一些组件如 Resource Manager 可以自动发现新增加到集群中的 worker,并自动实现数据再均衡。
二、数据库的基本操作
1)ClickHouse
SQL 标准:ClickHouse 的 SQL 标准为 ClickHouse SQL,它从 ANSI SQL 演化而来,但有很多项不符合 ANSI SQL 标准,如果从其他的数据库迁移到 ClickHouse 需要有较多修改。
支持协议:ClickHouse 支持的协议主要是 TCP 和 HTTP,client 和 driver 使用 TCP 协议,也有一些工具和专门的 driver 使用 HTTP。
客户端:ClickHouse 本身就有 ClickHouse client,同时对于不同的语言也会有驱动性,比如 clickhouse-jdbc,clickhouse-go。
表引擎:在创建库表的时候,ClickHouse 有 MergeTree 家族表引擎,要为每一个表去指定所用的表引擎,用得最多是 MergeTree 以及 MergeTree 衍生出来的 MergeTree 家族,如 replacing MergeTree,aggregated MergeTree 等。
2)ByConity
SQL 标准:ByConity 能够兼容 ClickHouse 原生的 SQL 标准,在 SQL 标准上提供了 dialect 的配置。除了可以使用 ClickHouse 原生的 SQL,ByConity 还提供了 ANSI SQL 的方式。ANSI SQL 不是严格意义上完全符合 ANSI 标准的 SQL,考虑到 ClickHouse SQL 与 ANSI 有比较多的 gap,ByConity 会把一些不符合标准的地方尽量做到符合 ANSI SQL 标准。ANSI 的 dialect 可以看作是比 ClickHouse SQL 更加符合标准的 SQL 方式。
支持协议:ByConity 原生支持 ClickHouse 的 TCP 和 HTTP 协议。
客户端:除了 ClickHouse 支持的客户端以及驱动器,ByConity 有专门的客户端用于支持自己的配置和参数。
表引擎:ByConity 提供了合一的表引擎 CnchMergeTree,分布式的执行过程都封装在里面,可以替代 ClickHouse 原生 MergeTree 家族多个 MergeTree 的能力,如 by default 的 MergeTree、replacing MergeTree,包括支持唯一键也在 CnchMergeTree 中封装。
Virtial Warehouse 及计算组配置:创建 ByConity 库表有专门的设置,可以通过 DDL 为库表的读和写指定默认的 Virtial Warehouse。读写分离也是通过此操作实现的。
1)ClickHouse
ClickHouse 的数据导入包括基础的 insert 操作,外部文件的导入 insert into … infile…。另外 ClickHouse 提供了很多的外表引擎,可以利用这些外表引擎创建外表,通过 insert select 从外表把数据导入 ClickHouse。ClickHouse 多用在实时数仓场景,在 ClickHouse 的数据导入中,实时数据导入是一个比较重要的话题。ClickHouse 专门的表引擎—— ClickHouse Kafka 在 ClickHouse 中用得非常多。
2)ByConity
ByConity 对于基础 insert、外部文件导入以及外表数据导入与 ClickHouse 相同,语法上也一样。此外,ByConity 提供了更多的数据导入方式,包括一个数据导入工具,PartWriter。
PartWriter :可以集成在 Spark 的流程处理中,不通过 ByConity 的表引擎,直接将数据文件转换为 ByConity 能够识别的的 parts 文件。
后台任务:在数据导入时有很多后台任务需要管理,如数据导入之后的 merge 和 mutate 任务,Kafka 表引擎实时消费任务等。通过操作语句跟后台任务进行交互,监控后台任务的执行情况及系统表的性能指标,能够实现对后台任务的精准控制。
1)ClickHouse 的 Kafka 表引擎
ClickHouse 做 Kafka 的数据导入会创建以下几个部分:
用 Kafka 表引擎创建 Kafka 外表,指定从哪个 Kafka 的集群消费数据,整个 consumer 如何配置
定义一个 ClickHouse 的 MergeTree 表,作为数据真正写入的表
定义一个 Materialized View,把上述两个部分连接起来
Kafka 的数据导入在创建以上三个部分之后会在后台运行,之后不停地把数据从 Kafka 消费出来写入到目标表。
2)ByConity 的 Kafka 表引擎
ByConity 从基本用法跟 ClickHouse 一致,从 Kafka 消费数据也是创建外表、CNCH MergeTree,并创建一个 Materialized View 把两部分连接起来。但是 ByConity 在具体操作中跟 ClickHouse 存在差异。
3)Kafka 消费模式方面的差异:
ClickHouse 在 Kafka 消费时使用 High Level 的消费方式。这是一种自动化程度更高的消费方式,可以动态分配 Kafka 的 Partition 到 Consumer 的 instance。当发现有 Consumer 挂掉或有新的 Consumer 加入时,可以自动 Rebalance,把 Partition 进行重分配。ClickHouse其 MPP 的架构更加适合 High Level 消费方式,可利用 Kafka 进行 Rebalance。但是这种方式很难保证 Exactly Once,因为在 Rebalance 过程当中会由失败引起数据的重复消费,如果这些重复消费在目标表中没有去重手段,肯定会造成数据重复,无法保证 Exactly Once。
在此消费方式下,Partition 经常 Rebalance 到不同的 Consumer 节点,在 ClickHouse 中则会 Rebalance 到不同的 ClickHouse shard,一方面运维排查比较困难,另一方面很难控制 Partition 具体会落到哪些 shard 上。
4)如何保证 Exactly Once
ByConity 采用 Low Level 的消费模式:Kafka 消费当中的 assign 静态地分配 Partition 到具体的 consumer instance,这也是 ByConity 多层架构的便利性,可以由 server 控制 Partition 的分发,由worker 执行真正的 consumer instance 的消费操作。
本身具有调度能力的产品更倾向于用 Low Level 的消费方式,如 Flink 和 Spark streaming。此方式的一个最大的好处是不会造成数据重复,尽量保证 Exactly Once,精准控制哪个 Partition 由哪个 consumer 消费。同时在提交 offset 时,也会让数据写入和 offset 的提交有事务保证。在线上运维排查及数据审计时也更加方便,Partition 不会乱飘,如发现 Partition 有比较大的 LAG 也有迹可循,直接从 server 上找到具体的 worker,进而找到具体失败的原因。
1)ClickHouse
ClickHouse 对复杂查询的支持并不完整,它采用两阶段聚合的方式,即分布式表和本地表。在分布式表把查询分发到本地表,在本地表做第一个阶段的聚合之后再聚合到分布式表做第二阶段的聚合,也称为scatter/gather 的模式。
ClickHouse 提供了 GLOBAL JOIN 和 GLOBAL IN,类似于 Broadcast Join 的方式。在一个大表去 join 小表的时候,可以让小表的数据先一步被计算出来,然后分发到大表去做 local 的 join。ClickHouse 对复杂查询支持有限,多表 join 一直是 ClickHouse 的痛点。使用 ClickHouse 需要在前期尽量把数据打平成大宽表。
2)ByConity
ByConity 的复杂查询通过优化器来实现,优化器对复杂查询有非常大的性能提升,推荐默认打开。ByConity 引入了多阶段的查询,首先由优化器生成执行计划并分派到各个 worker,进而支持比较复杂的查询,如节点之间有数据的消费能力的查询。
优化器的工作需要统计信息支撑,因为它里面有 CBO,需要去手动地维护统计信息。ByConity 提供了对统计信息操作的手段,包括 create Stats,drop stats,以及去查看统计信息的手段。具体内容可以参考优化器的分享:
ByConity Monthly Webinar-20230321-优化器原理解析与性能差异_哔哩哔哩_bilibili
链接:
https://m.bilibili.com/video/BV1Ro4y1b7mu?spm_id_from=333.337.search-card.all.click&vd_source=c09f0713b2507369924e94f4fec6c133
三、分布式事务
在分布式系统中,不同的系统对事务支持程度不同,一般考虑 ACID 四个特性。OLTP 数据库对事务的要求较高,一般支持多种事务的隔离级别,且会支持比较高的级别,如 Serializable。但是一些 NoSQL 的数据库,为了达到极致性能,会把 ACID 的部分特性做得相对较弱。
OLAP 的环境中很多时候并不特别强调事务的重要性。但在真正的业务中,即使对 OLAP 系统,事务也是非常重要的。其中一个关键是保证数据的准确性,有些系统虽然能够保证最终的一致性,但在过程中会出现数据不准确的情况。对实时性要求比较高的系统,数据不准确会带来不好的用户体验。
此外在使用 OLAP 系统时,因为数据不都是一次性导入的,经常会有数据的增量更新,在这种需求里面也需要事务操作。
ClickHouse 虽然有分布式的查询,但是并不支持分布式事务,本地事务支持目前仅针对单次写入在 max_insert_block_size 以内的数据有事务保证。
此种事务保证对于大部分在 ClickHouse 里面真正跑的查询是不够的,ClickHouse 社区目前正在实现事务增强,如提供 MVCC 和 RC 的隔离级别,支持多 insert 和多 select 组成的交互性事务。此功能还目前还在 experimental 阶段,需要特殊配制才能使用。即使最终完全实现也还是一个 local 的事务,只针对本地表有事务保证,无分布式事务的规划。
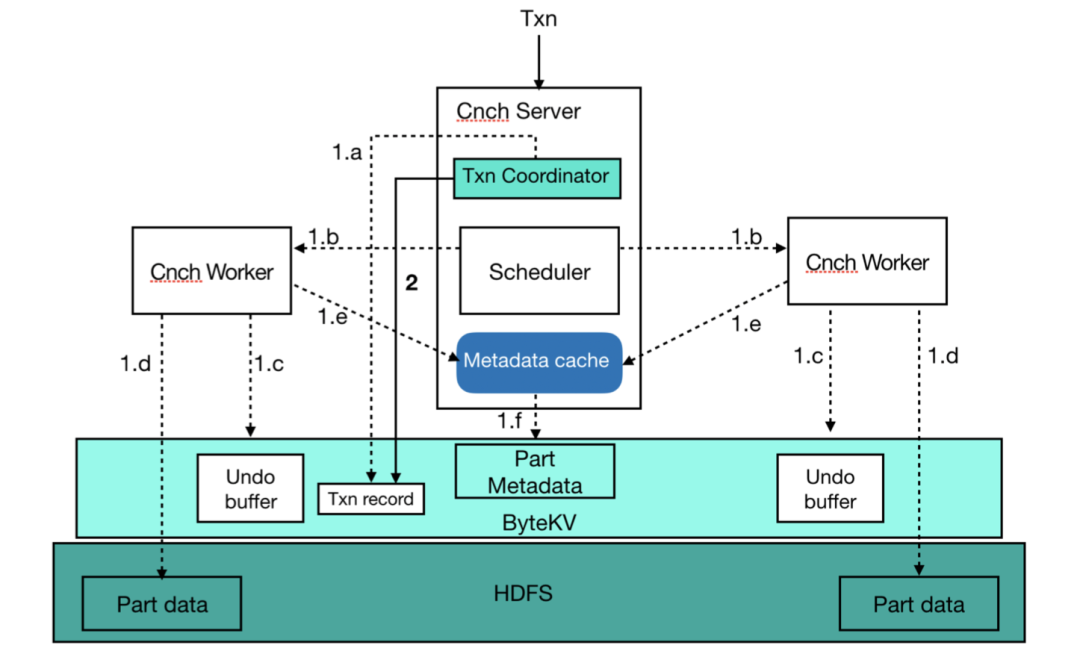
ByConity 进行了比较完整的分布式事务实现,其 ACID 的特性保证如下:
原子性(Atomicity):ByConity 在各种情况下都会保证原子性,包括掉电,错误和宕机等各种异常情况。
一致性(Consistency ):保证数据库只会从一个有效的状态变成另外一个有效的状态,不会有中间状态被看到,任何数据的写入必须遵循已经定义好的规则。
隔离性(Isolation ):ByConity 为用户提供的是 read committed(rc)隔离级别的支持。未完成的事务写入对于其他事务是不可⻅的
持久性(Durability ):ByConity 采取的存储计算分离结构,利用了成熟的高可用分布式文件系统或者对象存储,保证成功事务所提交数据的高可用。
另外,ByConity 通过两个比较重要的组件来进行事务保证。
Foundation DB:通过 Foundation DB 的能力做事务中的必要操作。Foundation DB 本身具有的原子性操作及CAS的操作在事务的执行过程中有帮助。
Timestamp Oracle(TSO):通过 Timestamp Oracle 提供全局唯一时间戳,时间戳是单调递增的,可以用来做事务的 ID。
在事务的具体实现中,这是一个典型的两阶段提交的实现。第一个阶段写入事务记录,包括写 undo buffer,远端存储,提交元信息等。第二个阶段真正提交事务,并更新事务记录的提交时间。在事务成功和失败的时候,用 undo buffer 去做一些清理。
四、特殊的表引擎
很多分析型数据库有 Upsert 的需求,如果表中存在已有数据,希望覆盖掉前面的重复数据,因此需要唯一键的保证来进行判读。ClickHouse 很难保证数据插入的唯一性。ClickHouse 提供的 replacing MergeTree 可以在一定程度上达到此效果,但 replace MergeTree 不保证键一定是唯一的,因为它是异步,要在 merge 时才能做数据的覆盖。如果 merge 一直不做或者做得比较晚则会出现重复数据的状态,而这种状态在很多场景下不允许出现。因此需要一个能够保证键的唯一性的场景来做 Upsert 的支持。
ByConity 对 Upsert 支持中,行级的 update 操作被转换成 delete + insert。行级 delete 通过 DeleteBitmap 实现,DeleteBitmap 存放了该 part 中所有被删除的行的行号。具体的增删改查都会围绕 DeleteBitmap 操作,比如 insert 时修改 Bitmap 对比版本信息;在 select 之后,根据 DeleteBitmap 当中的标识去 filter 数据。
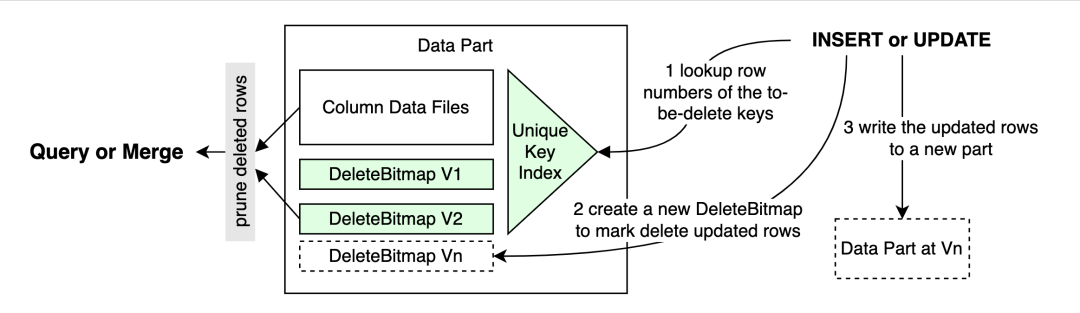
为了加速执行,ByConity 对 Unique Key 创建了 index。因为在 Bitmap 中放的是行号,从 key 到行号需要索引,通过 Unique Key Index 可以实现 Key 到行号的快速定位。
唯一性的保证也需要控制写冲突的发生。在并发的情况下,如果有不同的写请求过来,需要加锁去保证写冲突不会发生。从上可知,Unique 表引擎需要一定代价,是在真正需要此场景的表里才会需要用到的表引擎。
Snowflake 提出了 cluster table 的概念,即当一个表的数据量比较大时能够对表的数据进行再分片。即使是同一个 Partition 中的数据,也希望能够再分片,增加整个系统的并行度,并利用分片的 key 做性能优化。
Bucket 表在 ByConity 中需要以下语句来实现:
在 DDL 指定 cluster key,以及把表建成多少个 Bucket
CREATE TABLE t(...)CLUSTER BY (column, expression, ...) INTO 32 BucketS
Bucket 后期可通过 ALTER TABLE修改
ALTER TABLE t CLUSTER BY (column, expression, ...) INTO 64 BucketS
也可以把 Bucket 表整个 drop 掉
ALTER TABLE t DROP CLUSTER
1)需要使用 Bucket 表的场景
首先表的数据要足够大,一个 Partition 的数据要产生足够多且比较大的 Parts,⾄少需要显著多于 worker 的数量,不至于产生很多的小文件。另外要有一些性能优化的场景,有助于查询中性能的提升。
2)使用 Bucket 表的收益
针对 cluster key 的点查可以过滤掉大部分数据,降低 ΙΟ 量以获得更短的执⾏时间和更⾼的并发QPS
针对 cluster key 聚合计算,计算节点可以在数据子集进行预计算,实现更小的内存占用和更短的执行时间
在两张表或多张表 join 时,针对 cluster key 可以获得 co-located join 的优化,极大程度上降低 shuffle 的数据量并得到更短的执行时间,提升查询效率。
3)Cluster key 的选择
用 Bucket 表的时候,需要注意 cluster key 的选择,选择的时候要尽量去选在查询条件中经常会用到的组合的 column、经常需要聚合的 column,以及 join 时的一些 join key。
4)分桶数量的选择
分桶数量可以参考 worker 的数量。做 Bucket 表一定程度上的目的是能够尽量发挥多个 worker 的计算能力去进行并行计算。所以在分桶数量选择上可以尽量地去选 worker 的倍数,比如 1 倍或者 2 倍。
5)Recluster
分桶指定好了可以改变,但是改变需要一定的代价,需要数据的重新分配。因此建议尽量在必要的时候才进行 recluster 的操作。
ClickHouse 支持以外表的形式读取 Hive 以及 Hudi/Iceberg 等格式。这些外表都是以本地单机表的形式存在,因此性能并不能令人满意。且实现上较为割裂,使用起来较为不便。目前 Hive 仅能支持读取 HDFS 上数据,Hudi/Iceberg 仅能支持读取S3上的数据。
ByConity 通过统一的 Multi-catalog 的架构,极大增强了使用外表的便捷性。
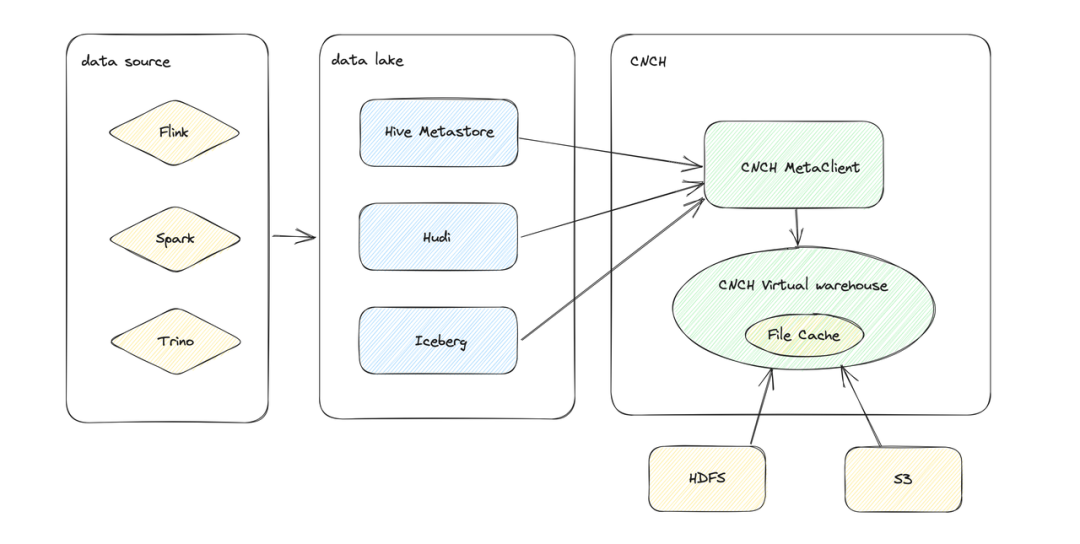
1)ByConity Multi-Catalog
Multi-Catalog 的设计允许用户在同一个 Hive 实例中同时连接多个不同的存储和元数据服务,而不必为每个存储创建单独的 Hive 实例。这简化了数据管理和查询的复杂性,使组织能够更好地管理和利用其多样化的数据资源。目前已经支持的外部 Catalog 有:Hive,Apache Hudi,AWS Glue。
用户可以使用创建一个基于 Hive 和 S3 存储的 Catalog
create external catalog hive_s3properties type='hive', hive.metastore.uri = 'thrift://localhost:9083';
然后使用三段式的命名来直接访问 Hive 外表
select * from hive_s3.tpcds.call_center;
也可以使用 query 来查看 external catalog 相关的信息
-- display information releated to hive_s3show create external catalog hive_s3;-- show databases in hive_s3show databases from hive_s3;-- show tables in tpcds database in hive.show tables from hive_s3.tpcds;
2)ByConity Hive 外表
ByConity CnchHive 可以充分使用 Virtual Warehouse 的计算资源执行查询。支持 HDFS 和 S3 文件系统。为了优化性能,ByConity Hive 外表支持统计信息集成优化器,它可以根据数据的统计信息自动选择最佳的执行计划。统计信息集成优化器可以在 benchmark 中显著提高查询性能。目前ByConity Hive 外表不仅能完整跑通 TPC-DS 基准测试,同时在性能方面表现出色。
CREATE TABLE tpcds_100g_parquet_s3.call_centerENGINE = CnchHive('thrift://localhost:9083', 'tpcds', 'call_center')SETTINGS vw_default = 'vw_default';
3)ByConity Hudi 外表
ByConity 实现了对 Apache Hudi Copy-On-Write 表的进行快照查询。在开启 JNI Reader 后可以支持 Merge-On-Read 表的读取。Hudi 支持同步 HiveMetastore,因此 ByConity 可以通过 HiveMetastore 感知 Hudi 表。
CREATE TABLE hudi_tableENGINE = CnchHudi('thrift://localhost:9083', 'hudi', 'trips_cow')SETTINGS vw_default = 'vw_default';
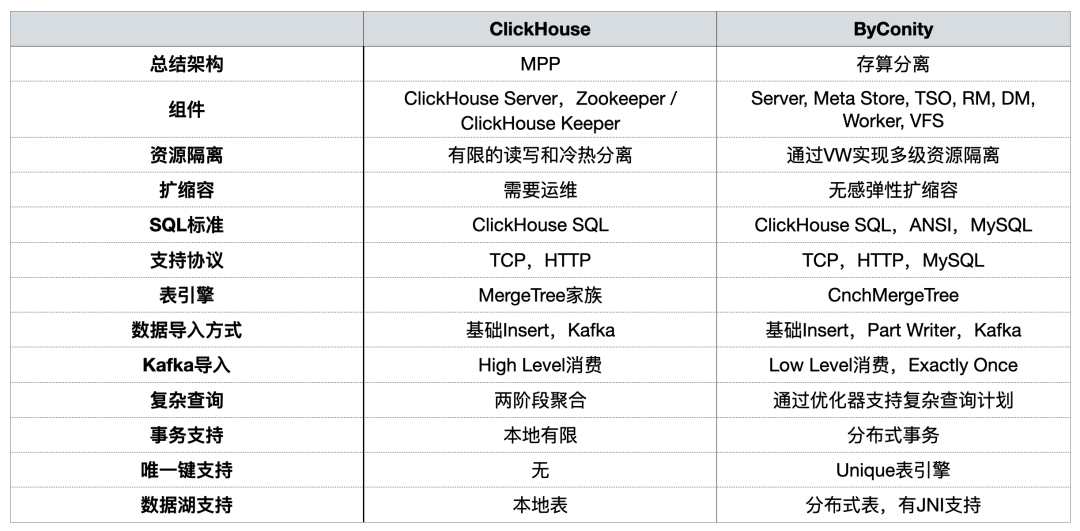
五、总结
下表总结了 ClickHouse 和 ByConity 之间的一些不同点,帮助大家有一个比较清晰的了解。除此之外,ByConity 还有很多特性。欢迎关注更多相关的内容分享。
Github: https://github.com/ByConity
分享视频:从使用的角度看 ByConity 和 ClickHouse 的差异_哔哩哔哩_bilibili
https://m.bilibili.com/video/BV1Ro4y1b7mu?spm_id_from=333.337.search-card.all.click&vd_source=c09f0713b2507369924e94f4fec6c133
PPT 获取:https://bytedance.feishu.cn/file/X43Nb8Ec5o0kHcxIzdGcf880nSh?from=from_copylink









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721