
其实呢,类似的对比在之前的文章中已经写过了一些,只不过那些对比都是相对比较零散的,或者主观上的。
那么这篇文章,咱就来点「正式」的对比,由于是不同的数据库引擎,所以对于同一个业务功能来说,不仅可以对比出查询效率,还可以对比出其SQL语法的差异性。
废话少说,下面就正式开始……
一、数据库环境准备
我会把同一份数据源(约2.4千万数据量,13个字段), 通过Spark,给分别写入到Doris的普通表模型(非聚合),以及Clickhouse(以下称CK) 的MergeTree表模型(非聚合引擎),并且,用尽可能相同的表结构。
两个数据库的一些具体情况如下:
| 软件版本 | 表类型 | 数据量 | 数据分布度 | |
| Doris表 | 1.2.3 | Duplicate表模型 | 24633163 | 分布在3台子节点上 |
| CK表 | 23.4 | MergeTree引擎表 | 22178231 | 分布在3台子节点上 |
其中Doris的建表语句如下:
CREATE TABLE `logs_from_spark01` (`client_ip` varchar(200),`nature` varchar(20),`province` varchar(30),`city` varchar(30),`operator` varchar(20),`domain` varchar(200),`time` varchar(200),`target_ip` text,`rcode` int(11),`query_type` int(11),`authority_record` varchar(500),`add_msg` varchar(200),`dns_ip` varchar(200)) ENGINE=OLAPDUPLICATE KEY(`client_ip`, `nature`, `province`, `city`)COMMENT 'dns logs'DISTRIBUTED BY HASH(`client_ip`) BUCKETS AUTO
而CK的建表语句如下。
先看分布式表的创建语句:
CREATE TABLE cluster_db.logs_from_spark_cluster on cluster template_3shard_2replica(`client_ip` String,`nature` String,`province` String,`city` String,`operator` String,`domain` String,`time` String,`target_ip` String,`rcode` Int32,`query_type` Int32,`authority_record` String,`add_msg` String,`dns_ip` String)ENGINE = Distributed('template_3shard_2replica', 'cluster_db', 'logs_from_spark_cluster_local', cityHash64(client_ip))
再看对应本地表的创建语句:
CREATE TABLE cluster_db.logs_from_spark_cluster_local on cluster template_3shard_2replica(`client_ip` String,`nature` String,`province` String,`city` String,`operator` String,`domain` String,`time` String,`target_ip` String,`rcode` Int32,`query_type` Int32,`authority_record` String,`add_msg` String,`dns_ip` String)ENGINE = MergeTreeORDER BY (client_ip, nature, province, city)
从建表语句可以看出来,为了尽可能保证接下来查询效率对比的公平公正,这里的字段类型,以及数据写入时的排序方式,在符合各种数据库的规范前提下,尽可能保持一致。
这里需要事先说明的是,CK集群跟Doris集群虽然规模一样,都是3个子节点,但是它们分别部署在不同的服务器上,而且Doris集群的服务器硬件要比CK集群硬件条件好上很多。
怎么形容呢,如果把Doris的硬件条件类比法拉利的话,那么CK集群的硬件就只能是BMW的普通3系水平。
所以,这个对比咱不能看绝对的查询效率,还要考虑到他们彼此之间硬件的差异。
二、开发环境准备
因为之前就写过了用Spark structured streaming读取kafka数据源(数据已经提前灌到了kafka中),分别写Doris和CK的样例,所以这里稍加改造就能直接用了。
至于为什么不用flink,因为我要用kafka的latest的模式消费数据,而flink在latest模式下,经过我的环境验证,存在丢数据的风险。
为了防止文章篇幅过长,这里就暂不贴出相关的代码了,有兴趣的同学可以去翻看之前的历史文章。
Spark(streaming)自定义sink写Clickhouse
三、数据写入效率对比
由于写入的是同一份数据,且都用的Spark的流式引擎,但是不同数据库采用的写入策略是不一样的。
Doris写入采用的是stream load的方式;
而CK的写入采用的自定义的jdbc方式;
同一份数据,Doris用流的方式花了约1个半小时,而CK则超过了3小时(关键还没写完),所以从写入效率对比来看:
Doris的 stream load 完胜 CK的JDBC。
四、开发环境遇到的问题
大数据开发的特点之一就是,开发过程中充满了不确定性,比如你在本地IDE环境调试好好的代码,但是一旦提交到集群你会发现,咦……居然报错了。
这里的报错,绝大多数情况都是jar包冲突引起的,因为我们知道,本地开发环境里,我们人为引入的pom依赖中维护了一套jar包的版本,但是集群环境里,同样也引入了一套必要的,集群服务运行时需要的jar包版本。
而当这两个不同环境的jar包,出现某些版本不一致时,就有可能抛出因为冲突而导致的异常,比如我这里就出现了:

这个报错的核心原因在于,IDE环境里出现了hadoop-hdfs这个包的2.7版本,而我的Hadoop集群是3.1的版本。
至于为什么会出现这个Hadoop-hdfs的2.7版本,原因在于我上次在pom文件中加入了hudi连接hive需要的相关依赖,而这个依赖的子依赖中,就有这个2.7的版本。
所以说,随着一个大数据的软件项目功能越来越多,依赖也变得越来越多时,这个jar包的冲突问题,几乎是防不胜防。
当然,解决办法就是,直接把这个2.7版本的hadoop-hdfs排除掉就好了。

五、PK正式开始
1、找出target_ip为空时(实际数据为双引号),此时每个不同domain的个数(要求domain统一小写)
按理说挺简单一个查询需求,应该一个SQL就搞定了,但是呢,对于CK和Doris来说,想要达到相同的查询目的,查询语句却无法共用。
先来看CK的查询语句:
SELECTlower(domain) AS domain,count(domain) as countFROM logs_from_spark_clusterWHERE target_ip = '""'GROUP BY domain
再看查询结果:

再来看Doris。
因为Doris也同样支持lower,以及count函数,所以按理说,把CK的查询语句照搬过来,换个表名,就能实现一样的查询功能了。
但是呢,实际的跟想象中的好像有点点不一样:

很明显,从查询的结果来看,它深深地误会了我的意思,可以明显看到有些经过lower转换后的数据,并没有在count的时候进行汇总。
看到这,瞬间我就懂了,该版本的Doris还不够聪明,如果想要实现跟CK一样的查询目的,必须要来个嵌套才可以。
于是,这个SQL语句得这样来写:
selectdomain,count(domain) as countfrom(selectlower(domain) as domainfromlogs_from_spark01where target_ip='""')tgroup byt.domain;
才能得出我想要的查询结果:

这里请忽略查询结果跟CK的有些对不上,因为通过Spark用jdbc的方式向CK写入数据实在是太慢了,还没等完全导完我就开始了测试,但是数据量已经相差很小了,对测试结论影响不大。
从查询耗时来看,Doris和CK都很快,Doris比CK略微快一点点,平均耗时都在1秒以内,但Doris的硬件资源更好。
于是我斗胆下结论:在当前查询条件下,从查询效率上,Doris跟CK打了个平手;
但是从查询的SQL便捷程度来说,Doris不如CK。
2、查询上网次数最多的前100个client_ip,以及他们分别的归属地是哪里
对于这个查询需求来说,虽然SQL逻辑要比上一个复杂,但是好在同一个SQL,Doris和CK可以共用。
SQL如下:
selectt1.client_ip,t2.nature,t2.province,t2.city,t1.countfrom(selectclient_ip,count(client_ip) as countfromlogs_from_spark01group byclient_iporder bycount desclimit 100)t1inner joinlogs_from_spark01 t2ont1.client_ip=t2.client_ipgroup byclient_ip,nature,province,city,count
其查询结果如图所示:
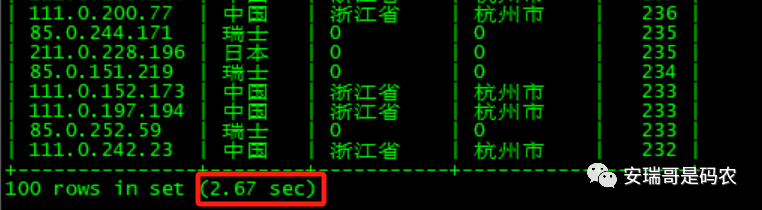
Doris查询结果

CK查询结果
考虑到Doris的查询效率是CK的3倍多,但同时Doris所在集群的CPU和内存资源是CK集群的2倍。
于是这么一算的话,该场景下,Doris的查询效率要强于CK。
3、count distinct的效率对比
低基列的查询场景:查询 client_ip 字段的count distinct。

Doris的查询结果

CK的查询结果
从查询效率来看,对于低基字段的count distinct,效率都很高,都控制在1秒内,几乎难分伯仲。
高基字段的查询场景:查询 domain(区分大小写情况下) 字段的 count distinct。

Doris的查询结果

CK的查询结果
可以看出来,换成高基列后,Doris 和 CK 的查询效率都明显下降,考虑到硬件的差异,两者也算打个平手吧,行不。
4、来个复杂点的
需求:以分钟为标准,找出连续上网次数最多的前100个client_ip。
比如:
1.2.3.4这个ip,分别在16:00、16:01、16:02、16:05这4个时间点都上网了,那么它连续上网的次数就为3(因为16:00、16:01、16:02连续)。
同样的,这个复杂的SQL在Doris和CK中,必须采用不同的写法,因为语法的限制,或者说Doris没有那么智能,Doris的写法要显得更加臃肿一点,相比之下,CK的则要更简洁一些。
先看CK的SQL:
SELECTclient_ip,max(row_num2) AS maxFROM(SELECTclient_ip,row_num2,date_minFROM(SELECTclient_ip,sub_date,row_number() OVER (PARTITION BY client_ip, sub_date) AS row_num2,date_minFROM(SELECTclient_ip,date_min,row_number() OVER (PARTITION BY client_ip ORDER BY date_min ASC) AS row_num,subtractMinutes(date_min, row_num) AS sub_dateFROM(SELECTclient_ip,toStartOfMinute(parseDateTimeBestEffort(time)) AS date_min,row_number() OVER (PARTITION BY client_ip, date_min ORDER BY date_min ASC) AS row_numFROM logs_from_spark_clusterWHERE (isIPv4String(client_ip) = 1) AND (length(time) = 14) AND (time LIKE '20220730%')) AS AWHERE A.row_num = 1) AS B) AS C) AS DGROUP BY D.client_ipORDER BY max DESCLIMIT 100
查询结果如下图所示:
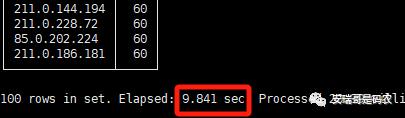
可以看到,CK的查询时间约为10秒左右(多次测试后)。
再看Doris的查询SQL:
selectclient_ip,max(row_num2) as maxfrom(selectclient_ip,row_num2,date_minfrom(selectclient_ip,sub_date,row_number() over (partition by client_ip,sub_date) as row_num2,date_minfrom(selectclient_ip,date_min,row_number() over (partition by client_ip order by date_min) as row_num,minutes_sub(to_date(date_min), row_num) as sub_datefrom(select client_ip,date_min,row_number() over (partition by client_ip,date_min order by date_min) as row_numfrom(selectclient_ip,minute_floor(time) AS date_minfromlogs_from_spark01wherelength(time)=14andtime like '20220730%')t) Awhere A.row_num=1) B) C)Dgroup byD.client_iporder by max desclimit 100
可以看到,其查询语句要比CK的复杂一些。
查询结果如下:
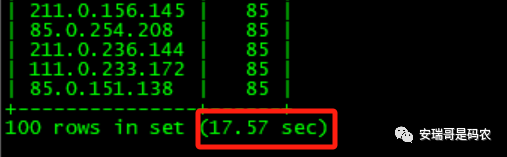
可以看到,其查询时间约为17秒左右(多次测试后得出)。
在当前场景下,即便CK集群的硬件更弱,但是其查询时间只花了大概10秒,
因此,可以下下结论:当前查询条件下,CK效率比Doris明显要高。
5、最后再来个简单的
需求:查询出 client_ip 中包含的所有国家、省份、城市,以及运营商。
查询比较简单,所以SQL在Doris和CK中可通用:
selectnature,province,city,operatorfromlogs_from_spark01group bynature,province,city,operator;
查询结果如下所示:

Doris查询结果

CK查询结果
从结果来看,该场景下,CK效率高于Doris。
七、最后
虽然此次对比,Doris跟CK集群部署在不同的服务器中,但是从上面的对比结果来看,考虑硬件强弱的差异,以及数据量存再少量的不同。
根据不同查询场景,依然可以大致得出结论。
但还是那句话,不能简单粗暴的认为哪个数据库就一定比哪个数据库「快」,因为不同的查询需求,在不同的数据库中,表现都是不一样的。
另外,你可以看出来,我的SQL写的其实不咋地,主打一个能跑,但是咱这次的重点不在这里,对吧。
那么对于以上的对比测试结论,你会选 Doris 还是 CK 呢?








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721