
不知道大家有没有这样的烦恼:使用 Flink CDC 同步数据时,每次都要写一堆代码,然后使用命令行一个一个提交任务。
这样做会导致我们的数据同步工作变得非常繁杂,而且鉴于每个人的编码风格以及代码经验参差不一,导致后期代码维护非常困难。
另外,数据同步工作并非只有我们开发人员去实施,更多的时候数据同步工作是由相关业务人员或者数据工作者去完成的。这时候一套零代码可配置的数据同步系统就显得十分的重要。
一、可行性研究
我们来看下基于 Flink CDC 的实时数据同步系统是否可行?
首先,Flink CDC 目前已经支持的插件非常丰富,比如:mysql cdc、mongo cdc、oracle cdc、sqlServer cdc、postgreSQL cdc,db2 cdc等等。除此之外,Flink CDC 的社区也非常活跃,数据同步的过程中遇到问题也能得到及时快速的响应。
其次,Flink CDC 支持全量同步、增量同步、根据指定数据位置进行同步,并且对于整库同步也是支持的,能够满足我们几乎所有的数据同步需求。
最后,Flink 本身也支持我们自定义各种 source 和 sink,如果 Flink CDC 目前的插件不满足我们的实际数据同步场景,我们可以自定义 source 来实现,自定义 sink 使得我们很轻松的可以将 Flink CDC 采集的数据同步到我们的数仓中去,对于 Apache Doris 数据库更是可以轻而易举的将数据同步过来。
所以,只要我们定义好 Flink CDC 任务提交所需要的数据结构,就可以零代码实现对各种数据源进行实时同步。
二、 系统功能
元数据是数据同步的基础,因此我们特意做了元数据管理的可视化操作。用户可以通过新建数据源,选取相关的数据库和数据表进行元数据同步。
我们做了后台管理界面供用户进行很方便的同步数据,整个同步过程只需要用鼠标就可以配置出数据同步任务。
有时候源端的表名、字段名和目标数据库的表名、字段名并不相同,这就需要我们在新建任务过程中建立源端和目标端数据表和字段的映射关系,这样我们在数据同步过程中就可以根据我们自己匹配的数据表和字段进行同步。
这里主要得益于 Flink CDC 丰富的数据源支持,目前系统中主要支持 Apache Doris 和 mysql,未来会支持更多的数据源。
基于 Flink 的 savePoint 机制,我们支持同步任务的断点续跑。并且基于 Flink 的Application 模式,我们实现了任务的启停接口和任务监控功能。
这里我们使用了 kafka 来实现数据缓冲,防止瞬时数据量太大,导致集群出现问题。相比于 Flink CDC 直接入库,使用了 kafka 中间件,有效的减少了传输过程中造成的数据丢失,以及上下游组件性能差异太大造成的反压问题。
三、数据同步系统操作流程
1)数据源管理
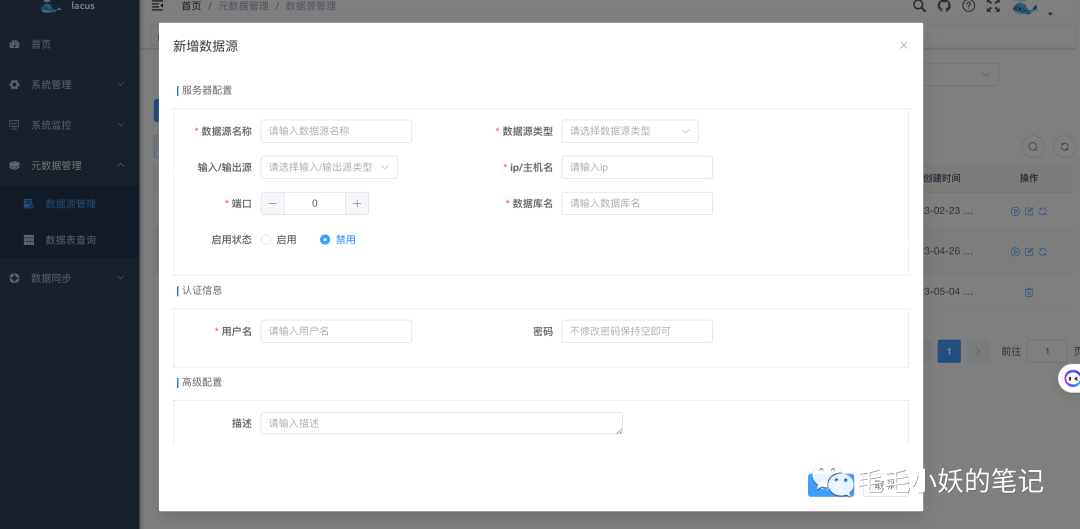
以下为数据源新增界面,通过这个界面,我们可以配置服务器相关信息、数据源认证信息以及其他参数。
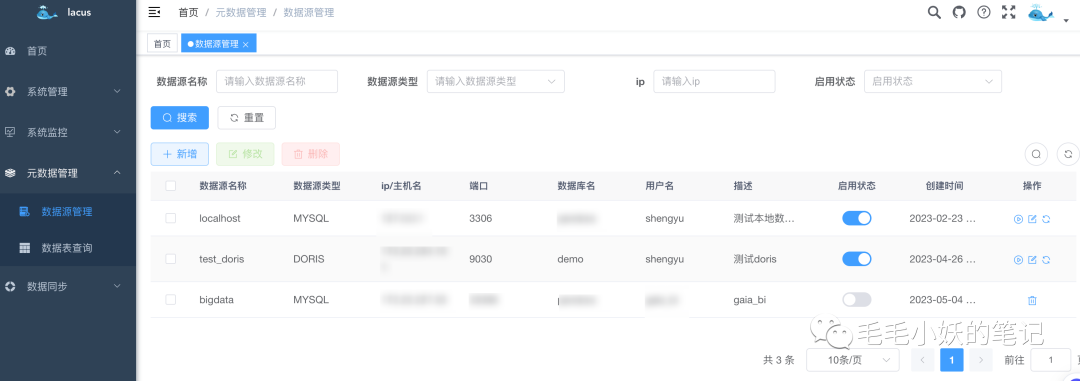
以下为数据源列表界面,可以输入检索条件对数据源进行查询。并且支持对数据源进行测试、编辑、删除、元数据同步操作。
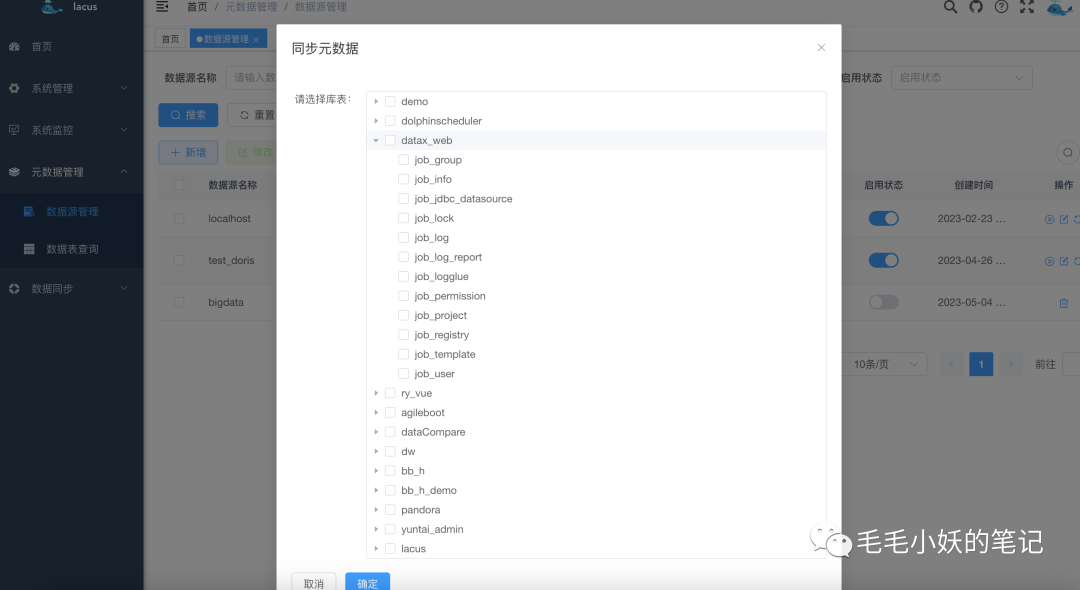
以下为元数据同步界面,我们可以选择需要同步的库表,将数据源同步到元数据系统中。
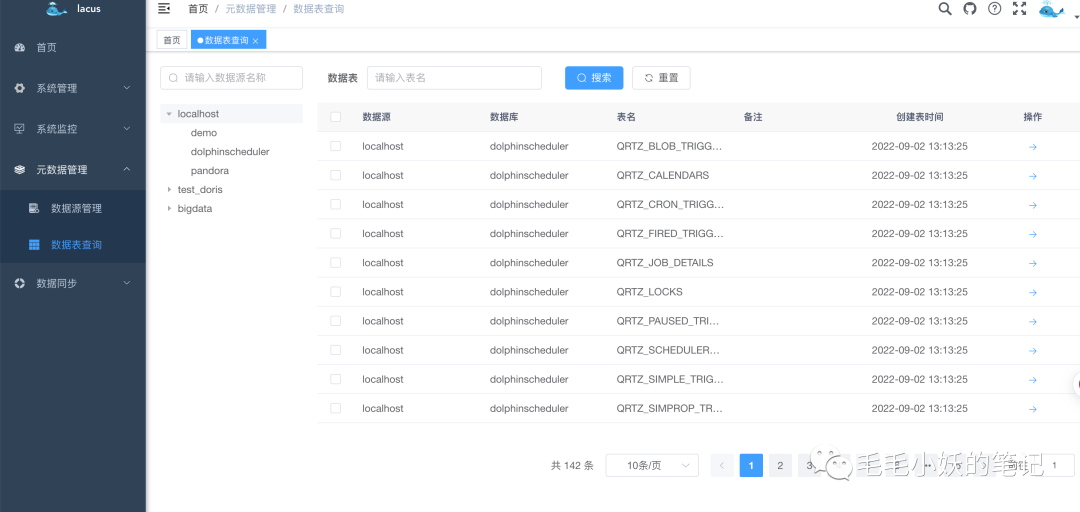
2)数据表查询
以下为数据表查询界面,左侧是数据源和数据库选择界面,这里采用了懒加载的树形结构,保证了界面美观优雅的同时,在数据量特别大的情况下我们的操作也能显得非常的从容和丝滑。当选择了数据源或者数据库,右边对应的数据表信息也一目了然。
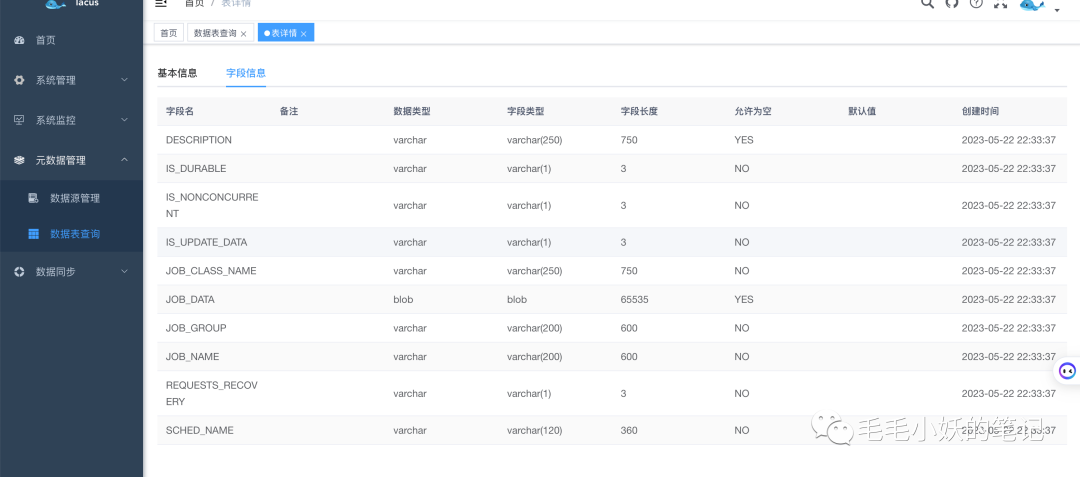
通过查看表详情,我们可以看到数据表的详细信息以及对应的字段列表,后期加上数据血缘功能,我们会更清楚的知道每个表以及字段的来龙去脉,方便我们后期对数仓中表及字段的溯源情况。
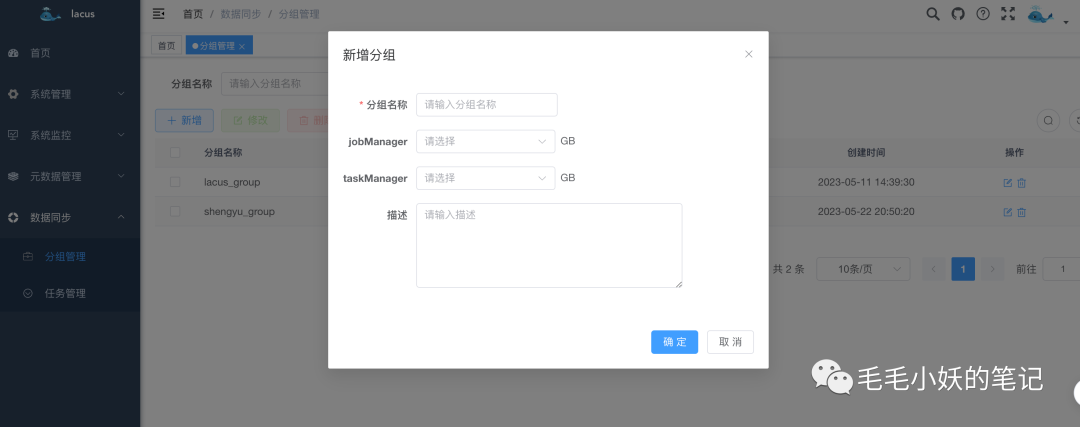
1)分组管理
这里的分组并不仅仅是一个目录分类管理的功能,我们为每个分组提交一个 Flink 任务,在服务器资源比较紧张的场景下,将多个任务合并提交会大大的节省服务器资源;并且后期如果加上告警功能,也能很方便的进行告警通知。
如下图,我们在新建分组的时候可以为每个分组单独设置 taskManager 内存和 jobManager 内存,以适应不同的数据同步任务需求。
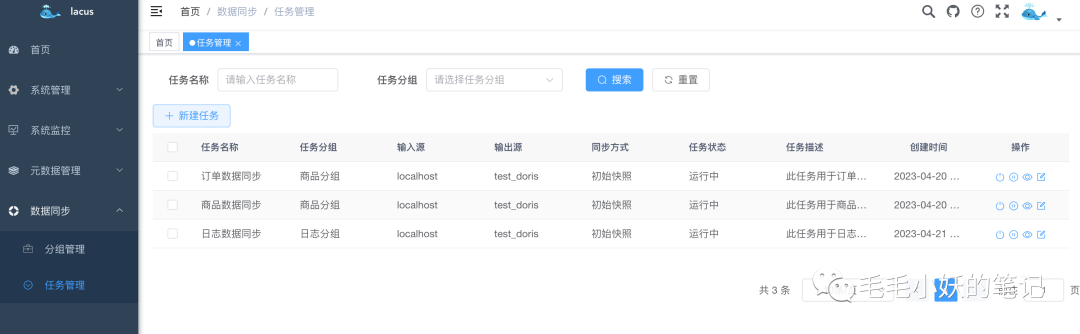
2)任务管理
任务管理是我们数据同步的核心,之前的所有维护信息都是为数据同步做准备的。在任务管理界面,我们可以清楚的知道每个数据同步任务的输入输出源、同步方式以及任务状态。并且能够方便的对数据同步任务进行启停以及监控。
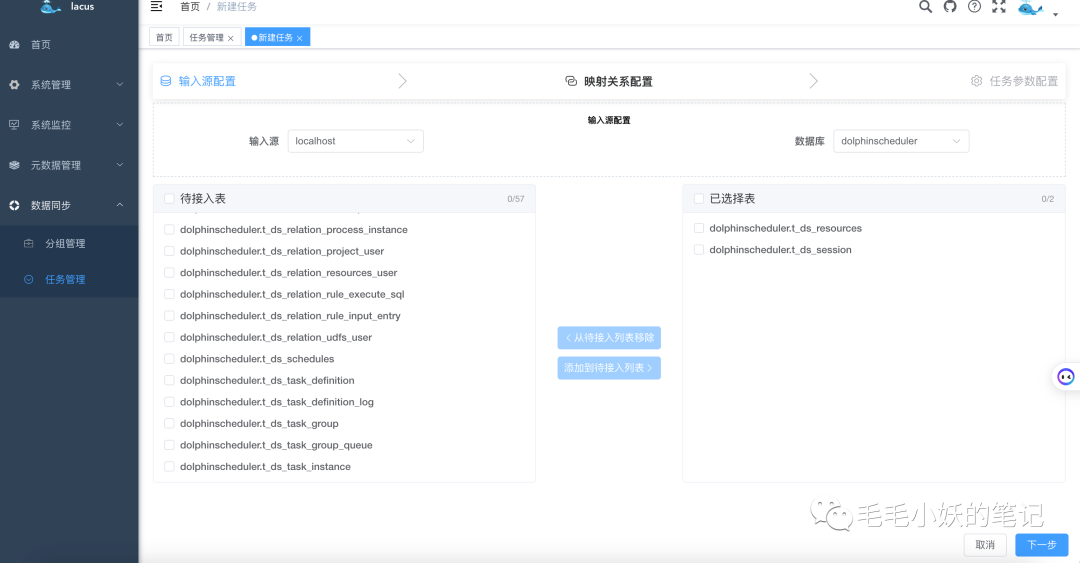
通过点击新建任务按钮,我们就可以正式开始数据同步之旅了。
首先,我们需要选择输入源信息,包括数据源、数据库、数据表的选择。通过穿梭框的形式,我们可以很方便的选择需要同步的数据表。
选择好输入源之后,我们就要选择输出源信息了,同样的,我们也要选择输出端的数据源、数据库。
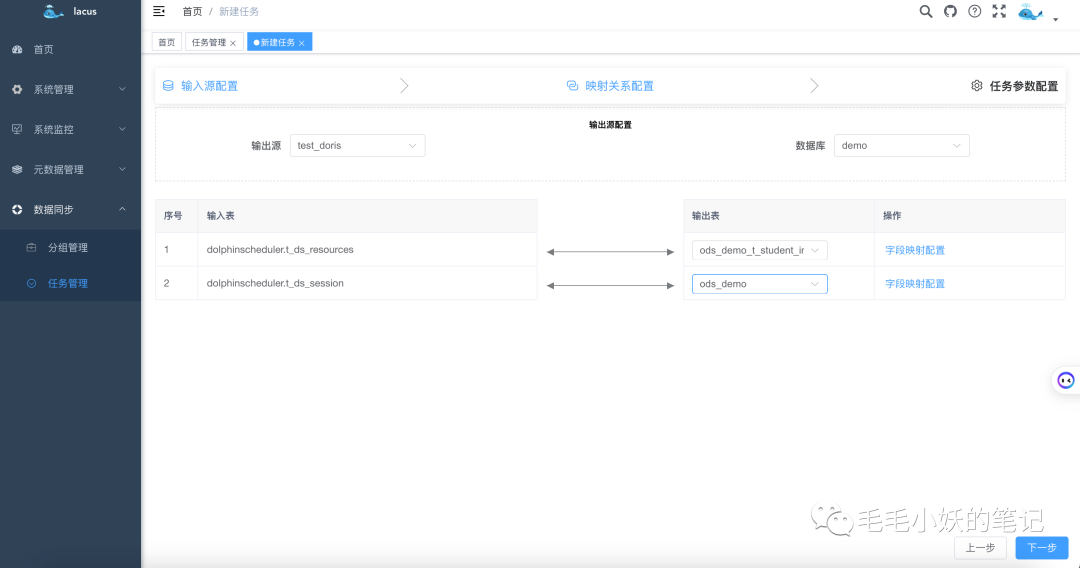
选择好输入源和输出源之后,我们需要建立输入表和输出表的映射关系。
在每一个映射表的操作栏选择字段映射配置,我们可以选择输入表和输出表的字段映射关系。
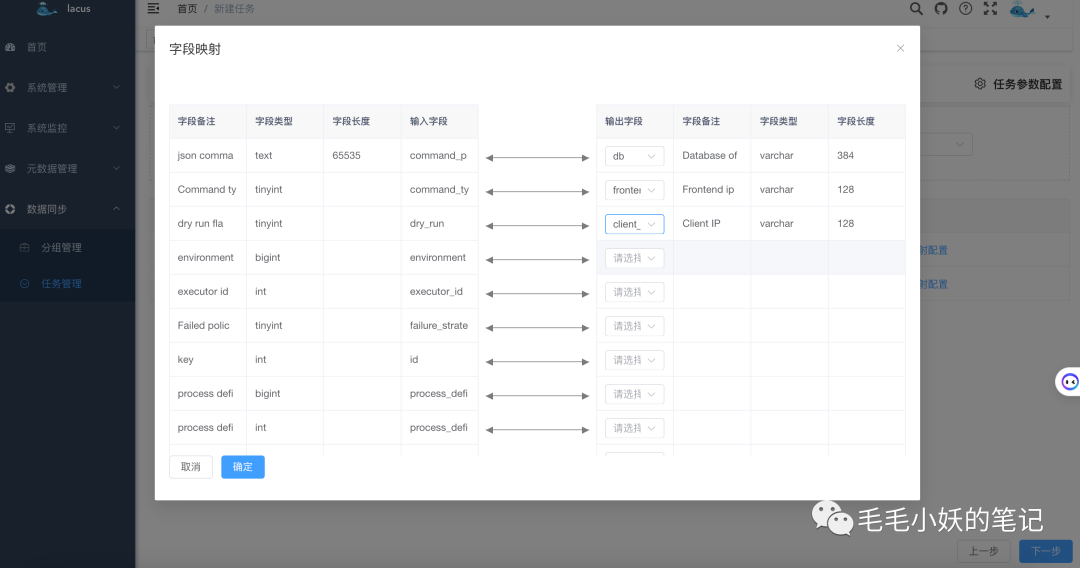
在输入源和输出源、数据表映射关系以及字段映射关系的选择完之后。接下来,我们还要简单的填写一下本次同步任务的基本信息,比如:任务名称、调度容器(yarn 或者 k8s);还有窗口间隔、最大数据量、最大数据条数的配置,这些参数也是限流的一些必要配置参数,在任务运行过程中,会根据这三个参数做数据同步的权衡。
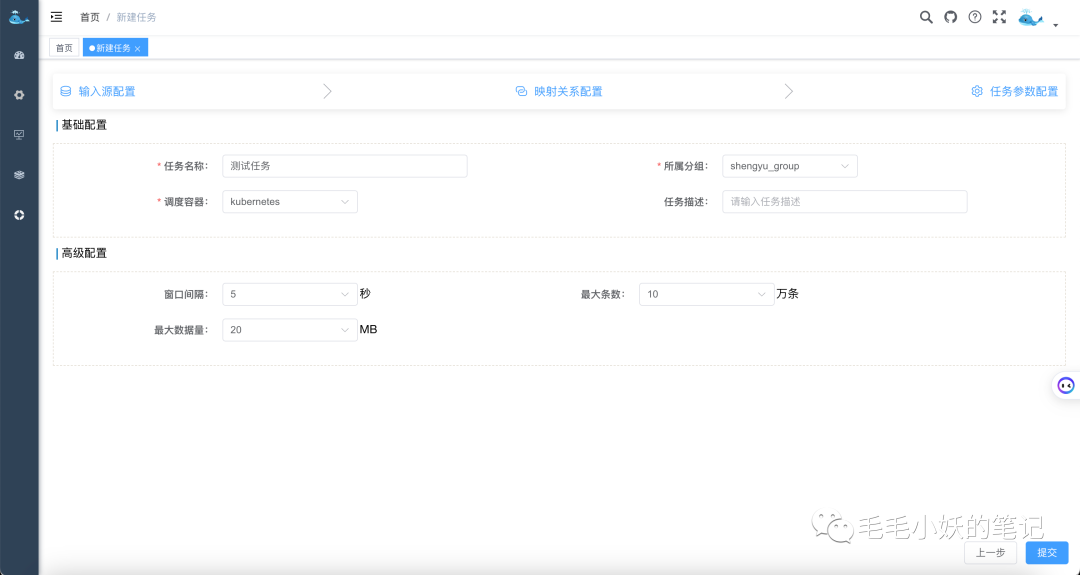
以上所有信息填写完毕,点击提交按钮,一个数据同步任务就完成了。
四、任务提交流程
当我们在页面上运行一个任务后,在后端会构建两个 json 数据,对应会提交两个 Flink 任务。
其中一个任务负责用 Flink CDC 将输入源的数据同步到 kafka 中;这里为什么要先同步到 kafka 中,上文已经提到可以认为是缓冲层。
另一个任务负责将 kafka 中的数据实时拉取到 Doris 或者其他数仓中。
具体的代码逻辑这里就不展开详细解说了,感兴趣的可以联系作者进行详细交流。
五、总结
所有的技术都是为了我们更好的工作和生活而出现的。所有的偷懒也并不是贬义词,相反,如果我们能够从繁杂的重复劳动中发现规律,不断地进行抽象和优化,之后的工作看似是偷懒了,其实是我们为了提高工作效率而早早的布局了而已,毕竟谁也不想每天进行毫无意义的重复性的劳动,仅此而已。也许目前的系统并不完美,我相信在不断踩坑的路上,一定会越来越好的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721