
我们知道,对于一个号称功能强大的数据库来说,它能够支持数据写入种类的丰富性,某种程度也就决定了它使用场景的广阔性。
Doris提供的数据写入方式跟Clickhouse有些类似,都多到让你看花眼,都可以根据不同数据来源进行个性化选择。
只不过,从官方文档的描述来看,Doris支持的数据导入方式好像要更丰富一点:
它将不同的导入类型用了两种不同的描述方式,但其实里面的内容很多又都是相同的。
今天这篇内容不打算聊这些导入方式有哪些区别和联系,因为官网已经说的很清楚了,不再赘述。
在之前聊CK的文章中,我们聊了如何用kafka数据源,分别写入CK的本地表,分片表,以及副本表,并大致体验了下十亿级数据量写入CK后,表的查询效率情况。
那么这篇文章,咱同样也准备用kafka数据源写入Doris的表,也灌入亿量级的数据源,跟CK做个对比,看看数据查询情况如何。
一、 导入方式的选择
既然要把数据导入到Doris表中,那么首先要做的事情就是选择数据的导入方式。
我们知道,对于一个外部数据源,想要把其数据写入到数据库表中,那么具体实现方式是有非常多的,但总结起来可以分为两大类:
通过外部工具方式导入:比如兼容的第三方数据导入工具,支持的API写入,用计算引擎写入等;
通过数据库本身提供的方式:不用额外开发代码,也不用第三方工具,通过数据库自身提供的一些功能来写入;
对于一个自诩功能强大的数据库来说,我们当然首选数据库自带的导入方式,看它到底能不能满足要求,以及在使用过程中会有哪些坑,和值得注意的地方。
对于CK来说,之前文章已经介绍过了,它提供的内部导入kafka数据的方案就是创建kafka引擎表(外部数据源表),拿我提供给大家的上网行为数据来举例,在CK创建的引擎表语句是这样的:

CK中创建的kafka引擎表语句
但是此时,数据并没有真正进入到CK内部,这张创建好的表(dns_logs),本身是不存储任何数据到磁盘的。
然后通过这张外部引擎表,结合CK的物化视图功能,就可以把kafka的数据给接入到CK内部。
但是对于Doris来说,虽然也有外部数据源表(这点跟CK一样),但是目前从官方文档来看,它还不支持Kafka引擎表:

Doris虽然不支持kafka引擎表,但是它支持另一种方式对kafka数据的导入,这种方式叫:Routin Load,也叫例行导入。
但是目前这种导入的方式仅仅支持kafka一种数据源,也就是说它是专门为kafka而设计的一种外部数据源导入方式:

二、导入步骤
这个Routin Load的导入方式有点不一样的地方在于,需要你先创建承接数据的Doris表,也就是OLAP表,然后通过创建一个Routin Load导入任务来把数据给灌入到这张Doris OLAP表中。
如果类比CK的话,这个“Routin Load导入任务”就有点类似于CK创建物化视图的功能,因为CK的物化视图一创建(基于kafka引擎表和CK表),数据就开始从kafka持续导入到CK表中。
于是,我先在Doris中创建一张承接kafka数据的Doris表:

接着再创建一个Routin Load导入任务:
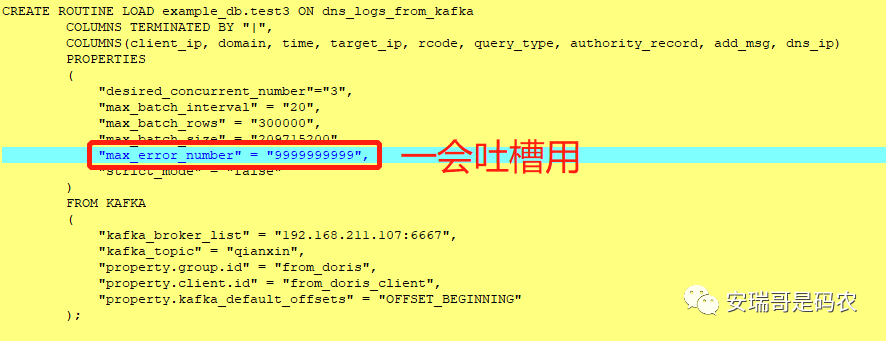
由于无法通过类似show create table的方式查看,只能这样贴出来
这里可以设置很多参数,具体的官网介绍的也很清楚,这里不想赘述。
然后通过命令:SHOW ROUTINE LOAD FOR ${load_name} 来查看任务进度:
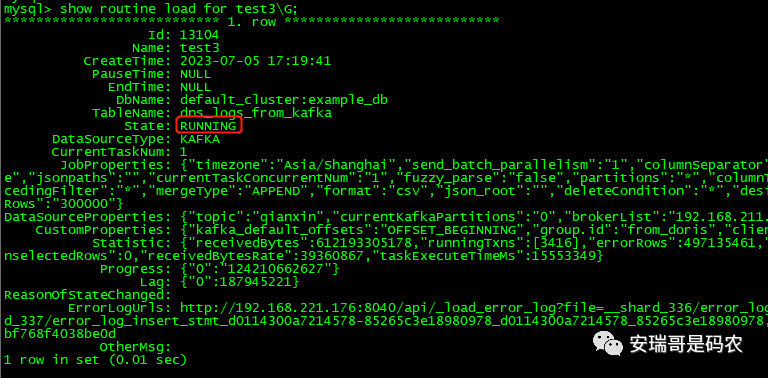
这里比CK要好的地方在于,可以通过这种方式随时查看数据导入的进度和状态,而且可以支持断点续传功能,但CK貌似没有提供这样的接口便利。
但是,无论是CK还是Doris,通过数据自身提供的这种数据导入方式,依然有些做得不够完善的地方,那么接下来,就是我要吐槽的了。
三、槽点说明
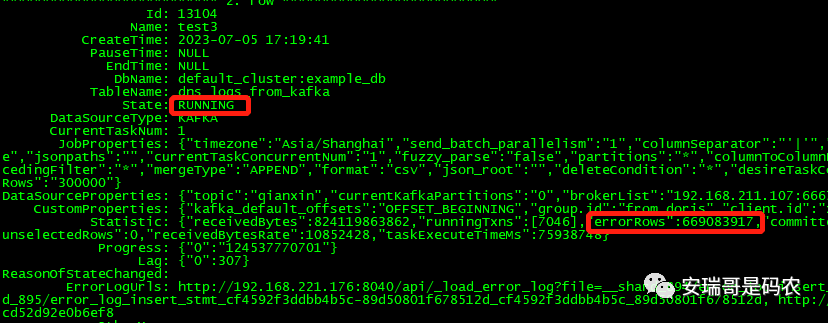
可以看到上面那幅,我创建导入kafka数据的Routin Load导入任务的黄色截图中,被标记的部分,那个设置是用来读取kafka数据时可以忽略的错误条数的。
那为啥我要那么设置呢?
原因在于我当前这个kafka的topic其实放了两种不同类型的数据,一种类型是11个字段,而另一种类型为9个字段:

9字段数据源

11字段数据源
但是,我此时只想要写入那个9字段类型的数据,按理应该可以根据导入规则进行一些设置和过滤,但是我找了一圈,就是没有找到更好的办法(其实根据字段个数来筛选就可以了),我查了官网提供的解决方案:
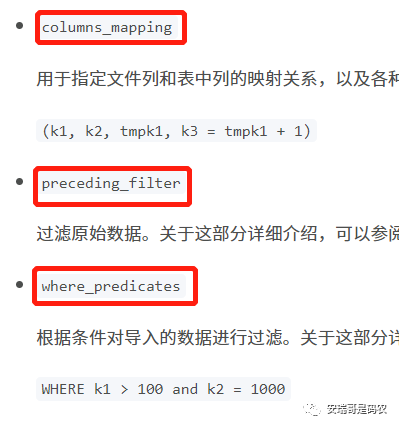
目前来看,只有这3个可以作为筛选数据源的手段,但是:
1. columns_mapping:这个是用来做字段映射的,用于kafka数据通过分隔符分隔之后,调整其源数据字段顺序,跟实际Doris表中的顺序关系的,显然满足不了要求;
2. preceding_filter:只能对列值进行条件限制,也满足不了;

3. where_predicates: 同样,也只能对列的具体值进行限制,也满足不了:

虽然文档中说“详细介绍,可以参阅【列映射,转换与过滤】”这部分说明,但是依然没有找到解决办法。
并且,就这个问题,我还专门咨询了Doris的PMC,也确认了当前版本的Doris无法就这个情况进行筛选(并被告知该功能正在开发中)。
当然,这个缺陷不能说明是个多大的问题,其实CK对于Kafka数据源的导入也有类似问题(都无法支持高阶功能的数据过滤),而且CK还不支持对kafka数据列的过滤,几乎没有主动筛选功能。
四、应急办法
既然Doris无法通过判断kafka数据源中,单条数据的字段数量来筛选目标数据,那么就只能想出一些“骚操作”来解决这个问题了。
好在Doris在用Routin Load导入kafka数据时,提供了一个有用的参数,叫max_error_number:

也就是在根据数据导入规则(根据分隔符切分后有9个字段)导入数据时,如果导入的数据不符合标准(字段长度不对),能够允许不符合规则的最大条数。
看到这里,我眼前一亮,这个利用Routin Load导入数据的方案能不能行,就看这个参数了。
果然,在没有加这参数之前,这个导入任务一启动就报错了:

提示说,导入的数据字段比要求的多,也就是那个11字段的数据惹的祸。
但是加入这个参数之后,导入任务就能正常运行了,虽然状态显示有很多错误的row被解析(允许忽略),但是导入任务并不会因此而暂定(挂掉):
当然,CK我也用的是同样的策略(也利用了同样的错误忽略参数),才把数据给正常导入到数据库中,虽然不优雅吧,但也是目前能想到的解决办法之一了。
五、查询对比
通过以上这种方式,我大概向这张Doris表灌入了1.3亿+条数据(时间所限只导入了这么多),分布在3台BE上,整个导入过程没有出现任何异常。
对比CK集群,同样是一张分布在3台CK服务器上的分片表,也取相同的数据量进行查询对比。
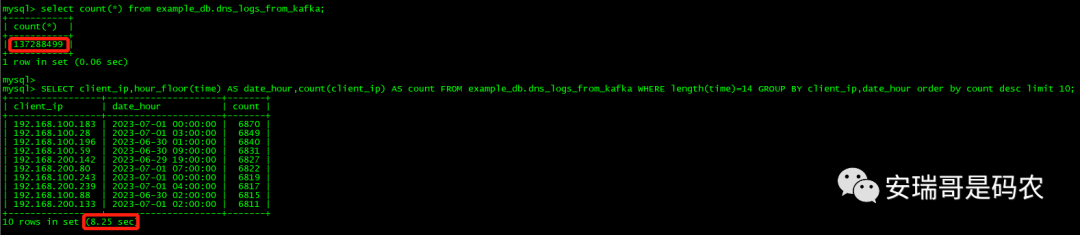
查询条件为:以小时为单位统计各个上网IP在各个小时内的上网次数,并取上网次数前10的结果。
Doris的查询结果,如下图所示:
CK的查询结果,如下图所示:

可能你会好奇,CK的查询语句除了函数语法有些不一样外,为什么还有个嵌套查询,原因在于CK这张表数据导入的早,目前已经有几十亿数据量了,于是先从里面取跟Doris表一样多的数量后,再执行的聚合操作。
加上数据写入表中的类型,排序方式都是一样的,所以理论上,这个对比应该是公平的。
经过了多次的查询测试后发现(约10次),CK和Doris在对于这个场景的查询,查询时间基本一致,都维持在8秒左右(前后两次查询的时间都隔的很开情况下)。
而且对于CK来说,如果两次查询的时间挨的很近的话,第二次的查询效率要明显比第一次快(比如第一次是8秒,1分钟内再查就变成2秒),估计是利用了OS缓存机制。
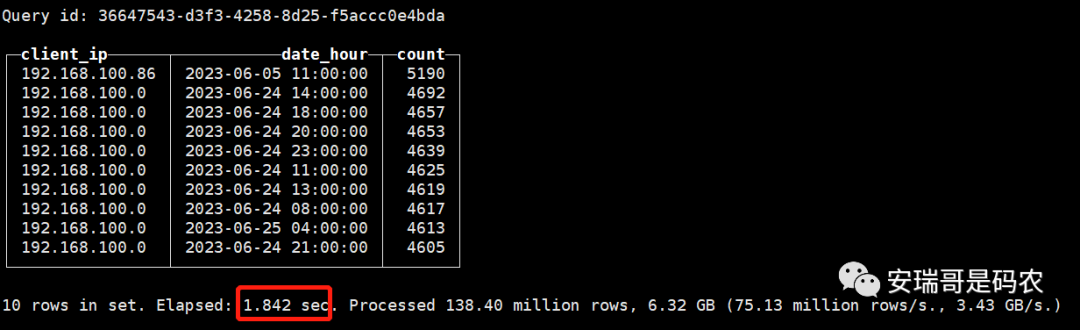
但Doris每次查询时间,无论第一次查询跟第二次查询的时间挨的有多近,其查询效率都保持不变,永远都在8秒左右。
所以,如果这里非要分个胜负的话,个人认为CK要强一点,而且要知道,这两个集群中,CK的集群硬件配置要明显比Doris的硬件配置差一些(内存和CPU只有它一半)。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721