
一、背景介绍
ES作为公司的基础存储之一,服务于各个业务线,包括会员、营销、订单等各个场景,对服务的稳定性要求特别高。
5月19号凌晨1点多收到线上会员ES集群的报警,一个节点OOM(OutOfMemory)自动重启了,会员集群是公司最底层最核心的集群之一,会影响公司所有的业务线,不敢错过任何的问题。
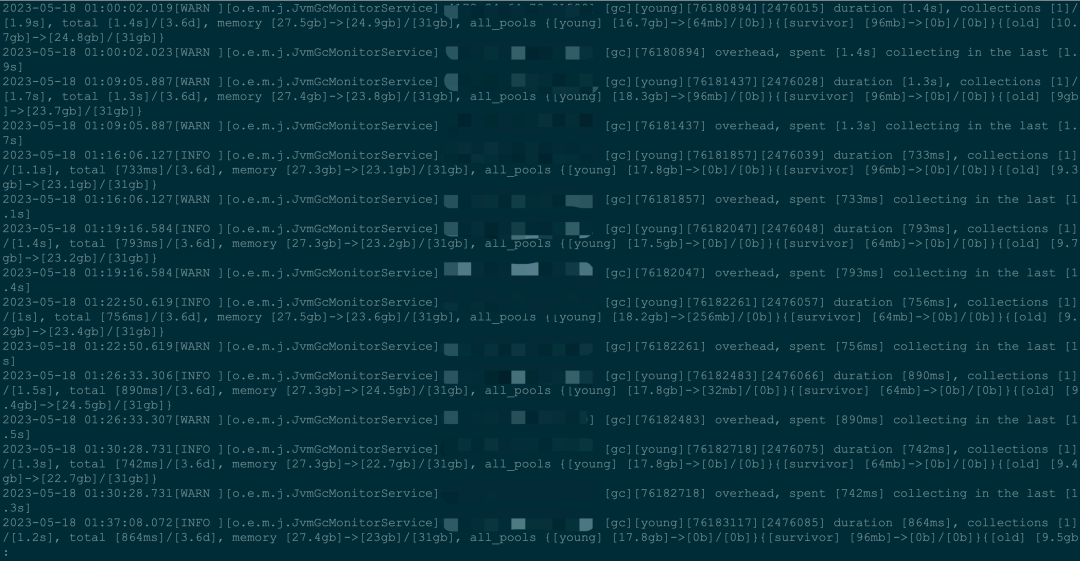
当开始排查OOM的时候发现问题比想象的严重,最近几天晚上11点到早上7点之间耗时波动特别大,集群非常不稳定。

在ES对应的日志里面也发现了大量的slow gc log,甚至OOM log。
es版本:6.8.0
二、问题思考
会员服务es集群已经稳定运行4年多,没有出现过任何的抖动,为什么最近凌晨低峰期会有抖动,白天高峰期反而很稳定。
三、排查过程
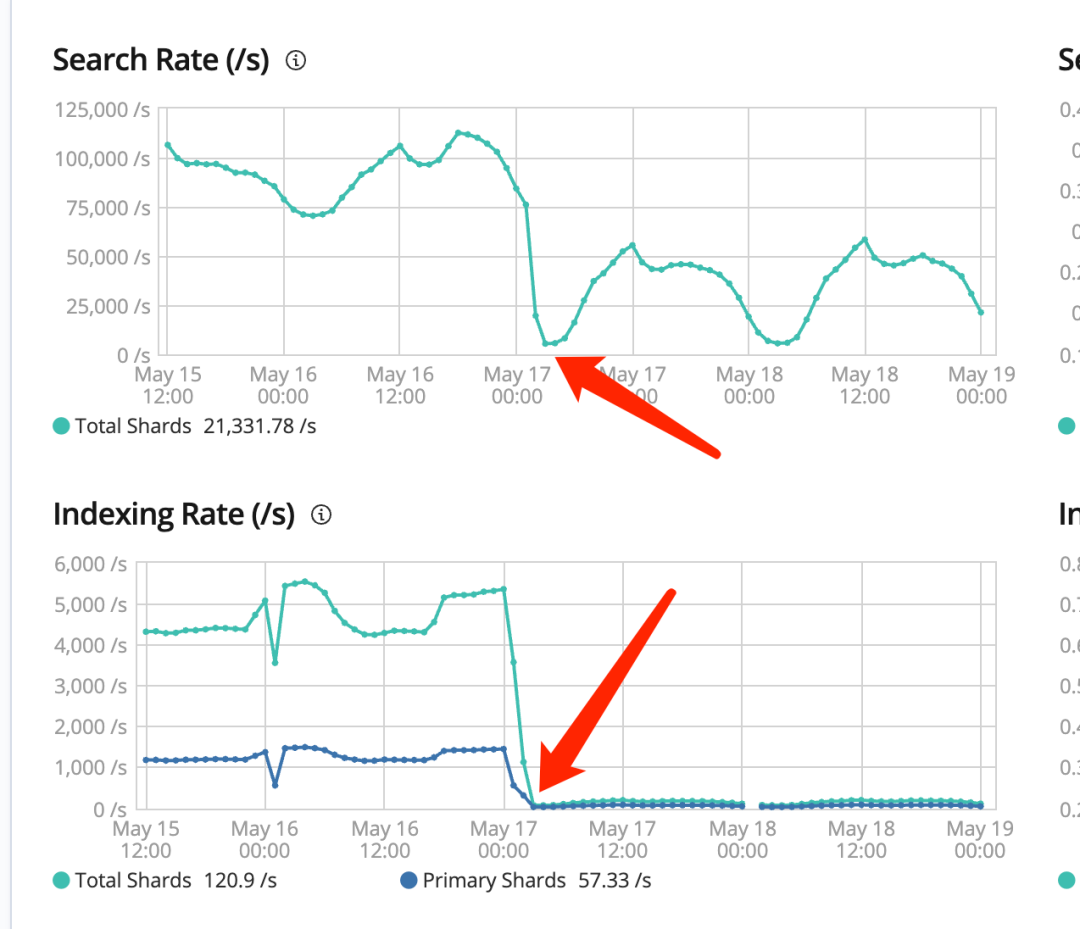
通过耗时监控与日志排查,发现首次出现在17号凌晨2点多,同时排查了kibana对应的监控发现一个巧合点,那个点业务有调整写入查询流量全部下来了。
bingo"破案了",业务上线了一个新功能导致的。但是跟业务聊下来发现,并不是上线了新功能,而是下线了一个导入数据的服务。
铩羽而归,以失败告终,从头开始,技术问题通过技术手段解决。
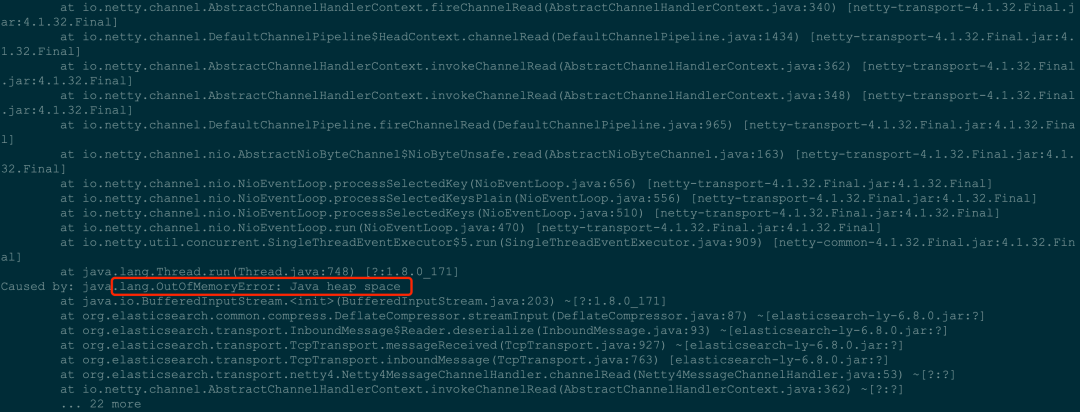
问题出现的点程序大量触发gc,并且有对应的dump文件,那就从dump文件开始分析。
从以往运维ES的经验来看,这个版本的ES出现OOM,绝大多数原因都是多层聚合导致的,dump里面比较容易排查。
但是这次这个dump给了我当头一棒,没有超大对象,只有一堆的正常对象。
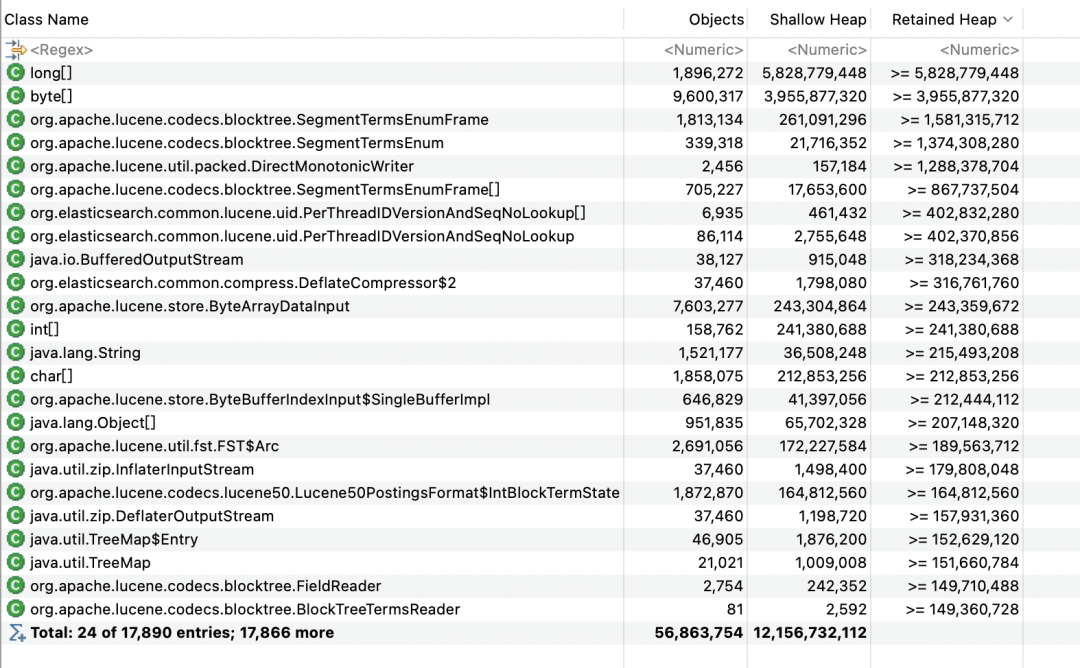
不过倒是第一次见这堆大long[],怀疑是什么触发了ES的内存溢出,继续往下排查。

都是不同SegmentReader读取Segment导致的,这边就相对比较清晰了,应该是某个查询会需要大量的读取Segment导致的,所以只需要找出对应的查询条件即可。
继续查找上下文,查到对应的查询条件:

翻译成对应的DSL:
[{"size":100,"timeout":"1500ms","query":{"bool":{"filter":[{"bool":{"must":[{"bool":{"should":[{"term":{"el_memberid":{"value":"240000001302699480","boost":1.0}}},{"term":{"el_memberid_app":{"value":"240000001302699480","boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}}],"must_not":[{"term":{"delete_flag":{"value":1,"boost":1.0}}}],"adjust_pure_negative":true,"boost":1.0}}],"adjust_pure_negative":true,"boost":1.0}}}
面对这个再正常不过的DSL,又陷入了无力,这个不应该会造成问题。
又在dump里面翻了半天,实在没找到什么突破。
所以觉得凌晨再抓一下现场,一直在gc,内存在一直涨,只需要比对两个dump就可以确定是涨的内存了。
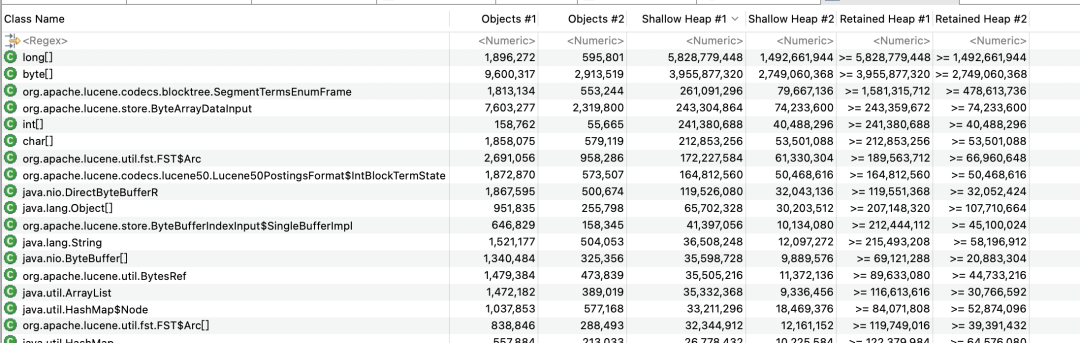
比对后更加烦躁了,全部是之前dump见过的。
多年的屡试不爽的经验,OOM了从dump里面都能找出来原因,今天失败了。

柳暗花明又一村,发现ES每次输出slow gc log的时候,都会有一段to-space exhausted的gc日志。
根据 oracle-technical 里面的描述:

出现这个错误调整一下对应的gc的参数就可以解决。
接着问题就来了:应该怎么调?为什么调整这些?调多大?为什么会是凌晨出现?
根据这些疑点,继续了排查:
什么情况下会出现 to-space exhausted
简单来说:old区不够用了,这个时候会把young区所有的对象全部转化成old区对象。
一个很好的文章验证:https://www.jianshu.com/p/952307cef88f
为什么会在凌晨出现
既然凌晨必现,就开始了凌晨抓现场,方向很明确,观察gc相应的情况,命令行 jstat -gc pid 1000 1000

从jstat可以发现 Eden 区 跟 Old 区同时在慢慢地涨,而且很长时间不会触发gc,这个也就跟dump文件对应起来了,一直在分配一些大的long[]超过了 regionSize的一半,就直接分配在了old区。
所以当old区接近用满的情况下,再分配一个对象就会触发上述的to-space exhausted,触发to-space exhausted 后需要将young区所有数据搬到old区,这个过程比较耗时,就触发了es的slow gc log。
所以为什么出现的凌晨也有了些思路,因为集群白天有比较多的别的流量,会更多更快的做很多小gc,会源源不断的回收old的空间。
为了验证这个想法,5月20号凌晨搞了个小程序,在低峰期往集群里面大量灌数据,让集群能够更及时的回收内存。

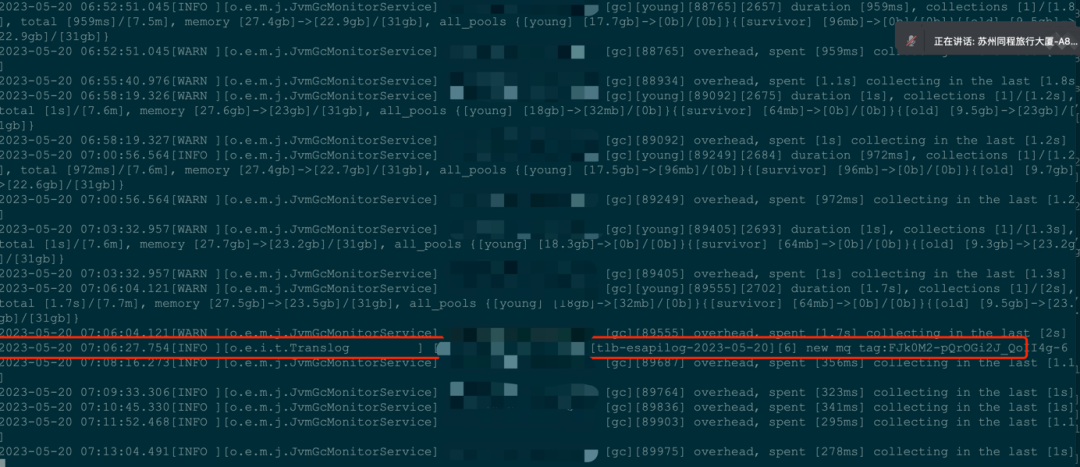
如图可以看到,当我在开启了大量的灌数据的时候,ES就没有再输出对应的slow gc log,当我关闭灌数据的时候,ES的内存使用毛刺就出来了,印证了我的想法。
经过一个晚上的灌数据,系统也表现的比之前更好。
所以以后凌晨就开一个程序来灌数据避免问题么?很不雅观,也不能接受。还是必须从根本解决问题,那就是参数调整。
四、参数优化
截止到上述结论,优化的方向已经很明确了:
尽早的回收old区空间,或者不分配在old区。
即使有较多的对象分配在old区,也要保障不触发to-space exhausted。
尽早的回收old区空间,或者不分配在old区。
哪些对象会分配在old区呢?
大对象:超过regionSize的一半,但是我们的size已经是最大的32M了;
长寿命:这个case从gc日志里面看长寿命的不太多;
所以在这个case里面不能够解决对象进old区,那就只剩一条路了:怎么能够尽早的回收old区呢?
怎么才能够通过参数的方式模拟出白天的gc情况或者说能调整后使得整体的性能、吞吐量更好呢?
不太想调整ConcGCThreads,线上环境机器配置比较多,不能够提炼出一个比较好的固定的值。
但是g1有个参数MaxGCPauseMillis,最大的期望暂停时间,g1会通过各种方式来调整,比如动态调整各个空间的大小,gc线程数等更低的时间就会造成更频繁的gc以及使用更多的资源。
默认200ms,观察了下gc日志,在我们的环境中,在young分配60%的情况下,大部分也能够满足,可以适当的调小改参数,这样能够满足我们的需求。而且看了下机器的资源,cpu相对比较富裕,这样对白天高峰也会有正向的作用。
方向很明确:保障old区有足够的空间。
g1通过InitiatingHeapOccupancyPercent来控制是否需要触发gc,默认45%,及当old区占用空间超过总heap大小的45%会触发。(不同的jdk版本不一样,老版本的是堆使用量与堆总体容量的比值)
在我们的case中发现,young区被动态的分配了18.5G的空间,所以在抛问题的时候即使old区用满也不会触发gc (为什么是18.5G,是根据G1MaxNewSizePercent,新生态动态分配最大大小,默认60%,合计heap 31GB。所以给新生态分配了18.5G)
所以要规避这个问题,要么缩小InitiatingHeapOccupancyPercent,要么缩小G1MaxNewSizePercent,保障old区至少分配45%+的空间。
我们最终没有选择InitiatingHeapOccupancyPercent,因为过小的话会导致过多的并发收集周期和混合式垃圾收集,给应用造成过多的停顿。
我们选择G1MaxNewSizePercent,这样可以保障young区会分配更小的空间,这样单次gc耗时会有优化,但是可能会带来更多的gc,但是从监控看,这个gc耗时可以接受。
综上所述,此次调整一共优化了2个参数:
-XX:MaxGCPauseMillis=100 能够更快的,更多的gc。
-XX:G1MaxNewSizePercent=40 兜底策略,保障old区可以分到更多的内存,不会触发to-space exhausted加上后续的fullgc,而且还有个好处,会使用更小的young区,也可以更快速的gc。
五、优化后的效果

从业务耗时监控看,平均耗时不管是白天还是晚上都有了明显的改善。

90线的毛刺也有了明显的改善。

业务系统异常率也基本没有了。
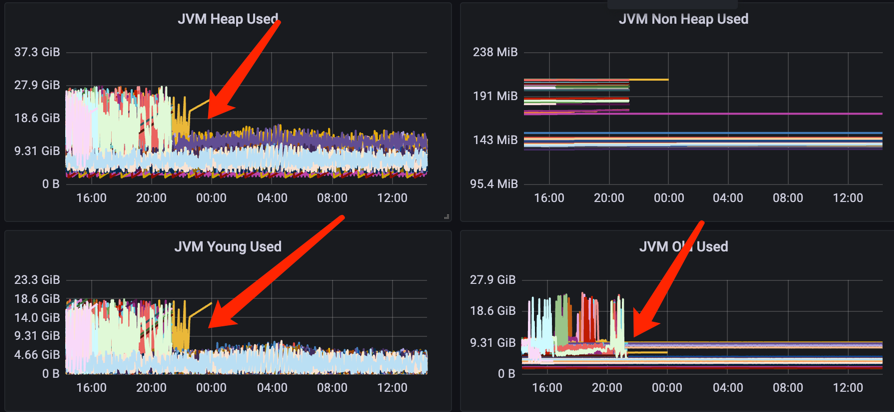
整体的es监控看,heap使用也更稳定了、更平滑了。从结果看,经过连续3个晚上的爆肝验证,效果跟预期的一致,耗时更低、毛刺更少、更稳定了。
总结:
不能放过任何一个问题,要永远相信墨菲定律,要不然问题可能会发展成比你想象的更糟糕。
遇到问题要冷静分析与思考,不能总相信经验。
参考资料
[1] https://www.oracle.com/technical-resources/articles/java/g1gc.html (MTL) Model for Personalized Recommendations
[2] https://docs.oracle.com/en/java/javase/11/gctuning/garbage-first-garbage-
collector-tuning.html#GUID-2428DA90-B93D-48E6-B336-A849ADF1C552
[3] 可能是最全面的G1学习笔记.
https://mp.weixin.qq.com/s?__biz=MzIwMjA3MDE3MQ==&mid=2650737377&idx=1&sn=f6df531f2dc800bade69bacda49387c4&chksm=8eefeb15b998620321852547a180abd8ed2a76f08a472a70b431c26790b7f0b57e07ce8fe1b3&token=1882596701&lang=zh_CN#rd
[4] https://help.eclipse.org/latest/index.jsp?topic=/org.eclipse.mat.ui.help/welcome.html
二、问题思考
会








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721