
作者介绍
许睿哲,2020年12月加入去哪儿网-数据平台团队,目前主要负责公司的esaas云服务与实时日志ELK平台的开发、维护与优化。主导参与了公司的es平台的SLA规则的制定与开发、ES架构升级迁移与jinkela集群拆分等工作。
一、背景综述
Qunar 的实时日志平台使用的是 ELK 架构,其中 Elasticsearch 集群(以下简称:ES 集群)和 kibana 平台在机房 A,Logstash 集群在机房B。
目前机房 A 在使用过程中存在以下一些问题隐患:
机房 A 目前为饱和状态,批量新增机器难以支持。
机房 A 主要由 Hadoop、ES 集群组成,业务交互会产生大量跨机房流量,峰值会影响到业务。
基于上述因素,与 Ops 同事沟通后,决定整体迁移 ES 集群到机房 B。这样不仅可以解决上述两个问题,和写入端的 Logstash 集群也同在一个机房,网络通信更有保障。
此文主要介绍 ES 集群节点迁移实战过程中的一些实践与探索演进经验,对于日常的平台开发与运维也能有所借鉴和参考。
二、迁移方案
Qunar-ES 日志平台主要存储全司实时日志,通过 filebeat、fluent-bit 等采集工具将日志采集到 kafka 后,由 Logstash、Flink 按照不同 topic 写到对应的索引中。一个 appcode 的日志对应到 ES 就是一个索引。
其中 Logstash 层还负责日志数据的 filter 逻辑,平台这边给业务用户提供了专门的 logstash-debugger 来进行 logstash的filter 测试与开发。
kibana 对接 ES 集群数据提供给全司,按照 space=>user=>role=>index pattern 的模式来管理用户的权限。以下是整体的实时日志平台架构图:
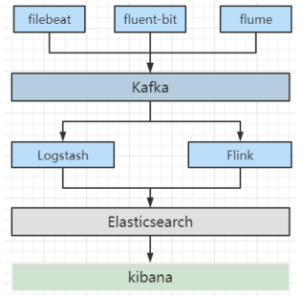
ES 日志集群目前是公司最大的一个独立 ES 集群,文档数达到了万亿级,存储量也在 PB+,节点数(ES 节点非机器数)也在500+,如图:

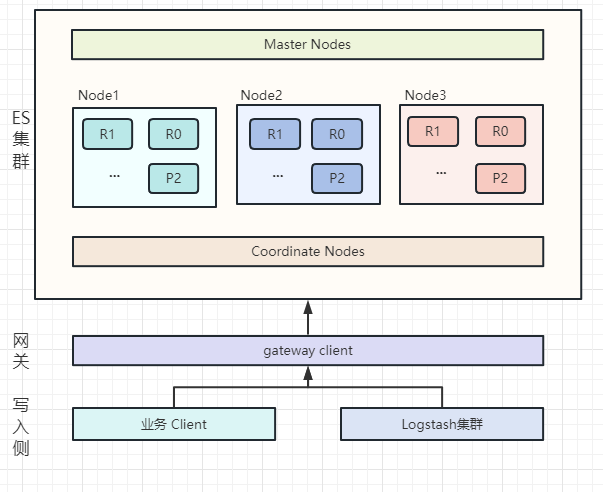
集群使用了多种类型的节点,master 、data 节点独立部署,角色分离,使用专门的 coordinate node 作为协调节点作为 data node 与外部请求的桥梁,在 coordinate node 外部增加了一层网关 gateway 层,直接接收用户请求,可以对请求进行审计与处理。集群架构图如下:
如何保证迁移中的服务可用性与用户无感知
集群规模大、写入量大、使用范围广,迁移过程中,稳定和服务可用性是第一要务。如何保障稳定性是首先要解决的难点。
如何提升迁移效率
1)迁移的速度:主要取决于迁移策略和持续的调优。迁移的总数据在PB级,单机器(机械硬盘)也到了10TB+,优化迁移效率,提升速度是后续持续研究的重点。
2)迁移的人工成本:迁移过程中,每个流程环节都需要人工介入,如何能提升自动化率,降低人工成本,也是研究提高生产力的方向。
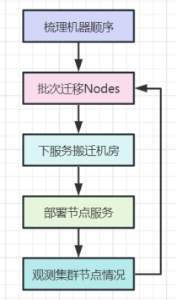
整体方案:按照机柜梳理出机房A的机器顺序,按批次进行节点数据迁移,将机器服务下线,搬迁到机房B中,重新部署,组网,并部署,启用。反复执行,直到全部迁移完成。可以参考以下流程图:
而从节点类型和服务维度来看,主要有以下几类,也是按照从 Data Node依次往后进行迁移:
Data Node
Coordinate Node
Master Node
Kibana
Service
本期迁移重点和难点都集中在数据节点的迁移,故而后续大量篇幅都在讲解数据节点迁移的演进变化。
三、迁移过程
做好以上前置准备事宜后,开始第一阶段的迁移工作,此阶段历时1个月。此阶段主要重点在于以下三件事:
手动迁移节点
调参保证稳定性
整理问题,确立后续工作侧重点
从机器列表(已排好序)中选取机器,以5台(单个机器有两个数据节点)为单位,进行exclude._name 操作:
PUT _cluster/settings{"transient" :{"cluster.routing.allocation.exclude._name" : "data1_node1,data2_node1,data1_node2,data2_node2,data1_node3,data2_node3,data1_node4,data2_node4,data1_node5,data2_node5"}}
注:迁移节点数据最直接的方法就是官方提供的exclude操作,这个操作是集群级的,可以直接通过"_cluster/settings"进行修改,执行操作后,集群会将匹配到的节点的分片reroute(同步)到其他节点上。通过exclude分为以下三种操作:
exclude._name:将匹配的node名称对应的节点数据迁移,多个node名称逗号分割。
exclude._ip:将匹配的node的ip对应的节点数据迁移,多个ip用逗号分割。
exclude._host:将匹配的node的主机名对应的节点数据迁移,多个host用逗号分割。
运行一段时间,发现存在一些问题:
因为是日志集群,属于写多读少的场景,中午到晚上是写入高峰,凌晨到早上属于写入低峰,在观测监控和机器报警中发现,节点在写入高峰时期会出现大量的load飙高情况(相较于exclude之前),而在低峰,相对要少很多,如图:
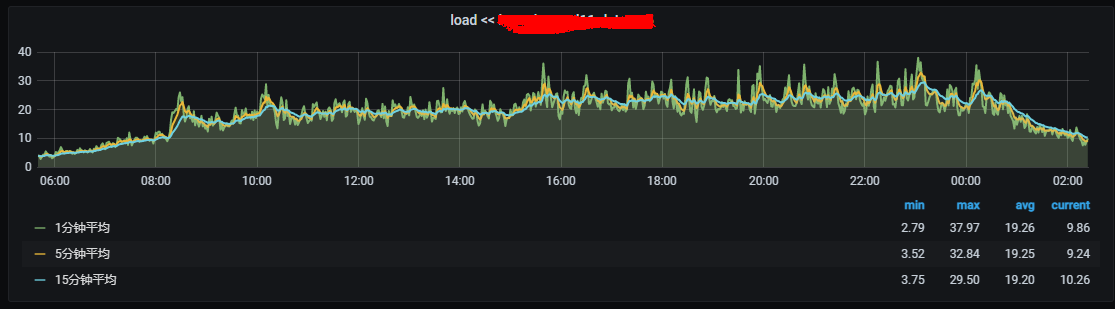
appcode 日志堆积数也会有所上升:
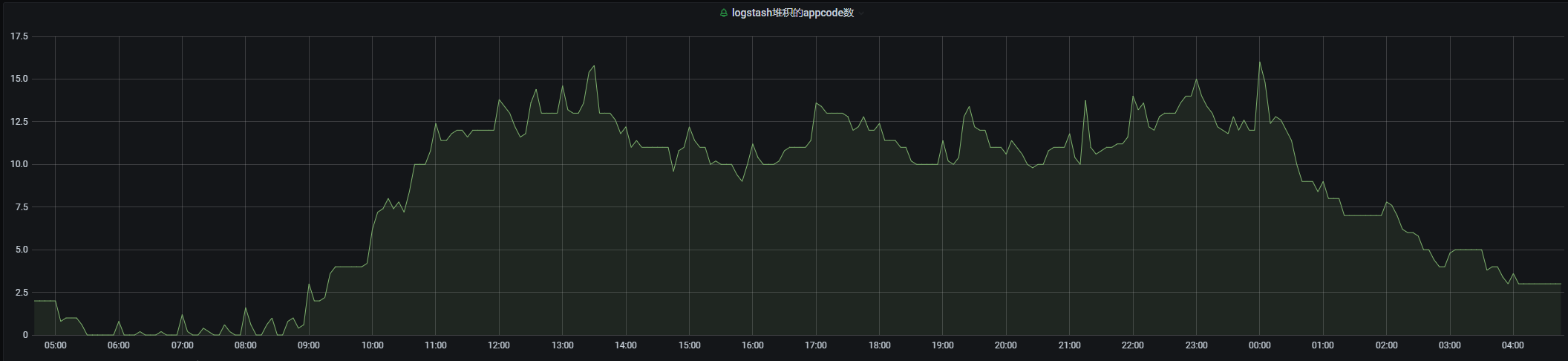
分析后,总结原因有以下几点:
添加 exclude_name 后,集群多了很多 relocating shards,此时会出现大量的分片迁移操作,通过_cat/recovery 可以看到期间的分片进行的过程。
白天集群是写入高峰,压力不算小,此时还需要同步数据,会造成 exclude name 对应的节点,因为要大量的迁出数据,会进行大量的磁盘读操作,同时,还有很多分片还在进行当前的写入操作,磁盘 io 很容易趋近于100%(使用的是机械盘)。
迁入分片的节点也因为读取量的飙升,导致了磁盘的 io 上涨。继而影响同步两侧的节点纷纷 load 飙高,影响的就是会有个别的 appcode 写入堆积。
调整过程:
根据峰值调整 exclude_node 的批次量,做如下调整:
高峰时期:调整到2个机器节点同时 exclude。
低峰时期:保持5个节点同时 exclude。
调整以后,除白天写入尖峰会有一些 load 飙高外,基本趋于平稳,堆积也大大回落。
有了第一个阶段的经验,熟悉了节点迁移的基本流程和操作。以上作为自动化的前提准备,于是开始了相关的架构设计和实现工作,具体架构图如下:
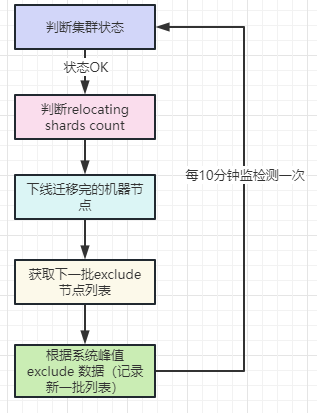
主要设计思路如下:
1)判断集群当前状态。达标才可以继续下一步操作,否则就等下一次检测。标准很简单:
status:集群状态为 Green
load:集群 load>30节点不超过7个;load>50的节点不能超过3个(基于日常集群情况)
2)判断 relocating shards count:
哪些节点迁移完成:如有,则统计数量
目前在迁移的 shard 数量
如果有节点迁移完成,且正在迁移的 shard 数量在40以内,可以进行新节点批次迁移,否则说明尚有多数分片在同步中,需等待下一次判断。
3)下线迁移完的机器节点。根据第二步得到的机器列表,下线前,需再次校验是否机器节点无索引分片。
4)获取下一批 exclude 的列表(顺序)
5)根据时间峰值进行 exclude(基于之前的经验)
高峰:2个机器节点
低峰:5个机器节点
注:
实际迁移的机器节点数为:需要迁移的节点数 X - 已经迁移完成的节点数 Y
这样可以保持系统一直迁移机器数一直稳定在峰值对应的数量
按照这样的架构实现的自动化迁移,在第二个阶段运行比较顺畅,变化也是十分明显:
节省人力成本(不用去手动操作),同时为第三个阶段的优化架构留出了演进基础。
保证迁移节点数量保持恒定。
之前的第二个阶段解决了自动化的问题,节省了迁移效率,在自动化稳定运行的同时,也在探索提升稳定性与迁移速率,在1~2月期间,主要做了以下几个方面的探索与实践。
1)total_shards_per_node
index.routing.allocation.total_shards_per_node:设置单个索引在单个节点上最多的分片数(包括主副本)。默认无限量。
调整原则:保证单个索引在单个节点上保留最少的分片数,以避免数据分片倾斜的情况,已提升整体稳定性。
total_shards_per_node 的调整逻辑如下:
total_shards_per_node: shard_num/(nodes_count * 0.95(buffer系数) * 0.5)
需要注意的是:
buffer 系数是一定要有的,否则一旦有节点宕机故障,就会一批分片出现 unassigned 情况,无法分配。
索引设置可以使用 template 进行控制,方便控制与修改。
索引级个性化的 template 参考如下:
{"order": 99,"index_patterns": ["log_appcode-*"],"settings": {"index": {"number_of_shards": "278","routing": {"allocation": {"total_shards_per_node": "2"}},"refresh_interval": "60s"}},"mappings": {"properties": {#索引独立的结构}}}注:上面这个template 模板设定的索引分片单个节点最多分配两个分片。
2)node_left.delayed_timeout
index.unassigned.node_left.delayed_timeout : 节点脱离集群后多久分配unassigned shards(默认1min),相当于延迟恢复分配多久的时间。
这个参数相当重要,尤其是大集群中,节点宕机重启时有发生,如果不做设置,节点对应的数百副本分片就会进行恢复操作,期间会耗费大量的 IO 资源,影响集群稳定性。而且集群重启后,还会进一步做 rebalance 以平衡分片。
索引恢复主要有6个阶段,如下:
INIT:刚开始恢复的阶段
INDEX:恢复Lucene文件
VERIFY_INDEX:验证Lucene index中是否有分片损坏
TRANSLOG:重放Translog,同步数据
FINALIZE:执行refresh操作
DONE:更新分片状态,完成操作
当机器宕机重启后,机器对应的所有分片会短暂成为 UNASSIGNED SHARD 状态,默认60s后集群 UNASSIGNED SHARD 进行恢复操作,此时会把原本宕机机器的未分配分片(副本)分配到其余节点,因为是副本分片同步,需要从主分片进行同步数据,比从本地恢复慢了不少,且极为影响性能。过程类似于:
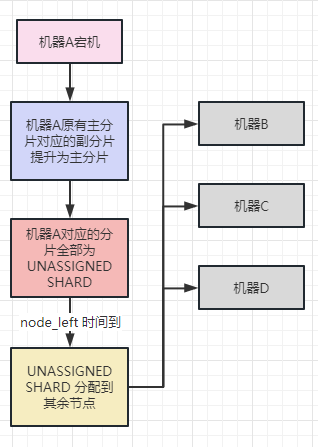
基于此,针对 node_left 的设置做了两次的尝试:
a. index.unassigned.node_left.delayed_timeout: 120m
将所有的索引 template 设置延迟分配时间设置为120分钟。
当遇到节点宕机后,不会再次出现大量分片迁移的过程,当节点重启后,分片会从节点本地进行恢复,效率高,性能影响小。
但是如果是节点故障宕机,无法启动时,会出现在 delyed_timeout 时间到达后,进行集中大量的分片恢复,如果节点分片多,同样会有性能方面的影响和损耗。
b. index.unassigned.node_left.delayed_timeout: random time
在调大延迟分配时间后,还会出现集中分片恢复的情况,主要是因为对于单一节点的索引分片都是同一时间变成的 unassigned,也会在同一时间进行恢复。
基于此,将 delayed_timeout 设置为随机数值,在创建索引的时候,设置为100~300min区间的随机数,类似如下:
delayed_timeout = random.randint(100, 300)PUT /index/_settings{"settings": {"index.unassigned.node_left.delayed_timeout": delayed_timeout}}
调整后,在故障宕机观测,会发现恢复分片是一个持续间断过程,而非之前的突增突降。如图对比:
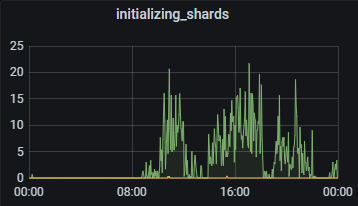
3)单机器单节点迁移
数据节点的物理机的配置为:32core 128g 14TB(为主,还有9TB、18TB)。
单物理机部署两个节点(data1,data2)实例,每个节点占用16core 64g资源,磁盘共用。
之前两个阶段的迁移是以物理机为单位进行迁移,批次迁移多台物理机数据,期间会因为大量的数据同步传输导致磁盘io问题,所以需要在高低峰进行批次调整,以保证稳定性。但是批次量无法提升,导致速率不太理想。
此次更换为单机器单节点迁移,exclude_node 中只选择同批次机器的data1,等 data1节点迁移完成后,迁移 data2。cluster exclude 设置如下:
PUT _cluster/settings{"transient" :{"cluster.routing.allocation.exclude._name" : "data1_node1,data1_node2,..."}}
使用单节点迁移后,单批次节点在高峰期可以增加50%,低峰时期增加80%。在迁移过程中,集群整体写入,与同步节点的 cpu、磁盘 io 均比较稳定,当 data1迁移完成后,批次节点的 load 整体会控制在10以内,稳定性得到相应的提升。
4)cluster_concurrent_rebalance
cluster.routing.allocation.cluster_concurrent_rebalance: 用来控制集群内并发分片的 rebalance 数量,默认为2。
ES集群的 cluster_concurrent_rebalance 参数长期使用的在10(节点数多,增加分片的同步效率)。
在迁移节点过程中,同步的节点会非常多,出现很多的 relocating shards,且同时还会有 rebalance 的分片,在迁移之后,还会继续做 rebalance。
此处为了减少 rebalance 的频率与周期,设置 cluster_concurrent_rebalance 为0,相当于一直都不做 rebalance。
但是如果长期不进行 rebalance,分片会出现倾斜不均衡的情况,基于此,进行了3.3.4 手动 reroute 操作,来调整分片的均衡。
注:
cluster.routing.rebalance.enable:none 可以等同于
cluster.routing.allocation.cluster_concurrent_rebalance:0。都相当于不做任何的分片均衡。
每周创建索引后,进行reroute。
➀rebalance 本身存在的问题
rebalance 节点主要由decider 控制器来决定的,而非当前分片使用的情况,这样会造成一个情况,机器在rebalance 后整体分片数均衡,但是写入不均衡(有些分片是当周分片正在写入数据,有些分片是上周分片,均衡之后可能会出现一些节点的当周分片数很多,导致写入压力大,磁盘 io 高,反而没有达到真正的均衡)。
现象是会有一些节点在高峰期出现持续高 load,磁盘 io 趋近100%的情况。不得不做一些手动的 reroute 分片,来缓解节点压力,遇到持续增高,可能会出现 node_left 重启的现象。
➁cluster_concurrent_rebalance为0带来的问题
因为3.3.3 中将 cluster_concurrent_rebalance 调为0,集群不会做分片均衡操作,新增索引分片会按照 decider 进行调度,最极端的情况会将某些分片数少的节点分配超过一倍的分片数。
举个例子:
周中新上的机器节点 node-300,到了周末统一创建索引的时候,由于 node-300基本没有分片(除少数新增索引外),会有大量的分片创建到 node-300中。
ES 集群创建完次周索引后,分片数在10w,数据节点数大致为450,平均到单个数据节点的分片大致为220+。而新周的索引分片数大约在5w+,对应的分片数为110+,而 node-300的新周索引分片数即为220+,相当于是其余节点的1倍以上。
上述两个现象直观导致的现象都是因为个别节点分片不均衡,导致性能受到影响,继而会出现 node_left 的情况。
分析了上述两个原因,决定从写入的分片均衡来入手。
因为是日志集群,索引是以周维度创建,每周日凌晨提前进行创建次周索引(tips:如果不提前创建,会在次周切换索引时,引发大量的 pending_tasks,造成集群写入大面积堆积),只要保证次周写索引的分片在索引节点均衡即可。
➂reroute new shard 调整分片均衡
在创建完新周索引后,可以对分片进行调整,流程图如下:
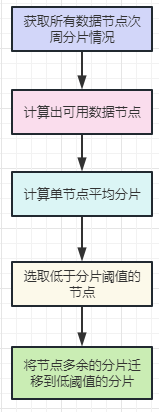
针对以上流程做简要说明:
主要的思路是:计算次周总的分片数/可用数据节点,得到平均分片,然后将分片多的迁移到分片少的节点。
因为是空索引,迁移时间基本可以忽略不计。
需要注意的是可用数据节点,从_cluster/health 可以获取到对应的可用 data node 数量,但是还需要将_cluster/settings exclude._name 中对应的节点数排除出去方是真实可用的数量。
同步完后,可以达到写索引的平衡(整体分片数不一定均衡)。
执行完同步脚本后分片均衡,以上问题顺利解决。
➃reroute new node
以上所有的措施已经能解决最核心的两个问题:稳定性、迁移速度。
按照当时迁移速度估算,可以在剩余1个月内完成全部的节点迁移,但是否有更快更好的方法做迁移?
在上个优化点 reroute new shard 调整分片均衡 中得到灵感,新分片迁移是很快的,因为没有数据,基本不费时间且对性能没有任何影响。那能否用于在迁移节点上来呢?答案是可以的。
在 reroute new shard 基础上,做了改进,并根据机器配置,做了差异化的处理(包括迁移节点和平衡分片),设计图如下:
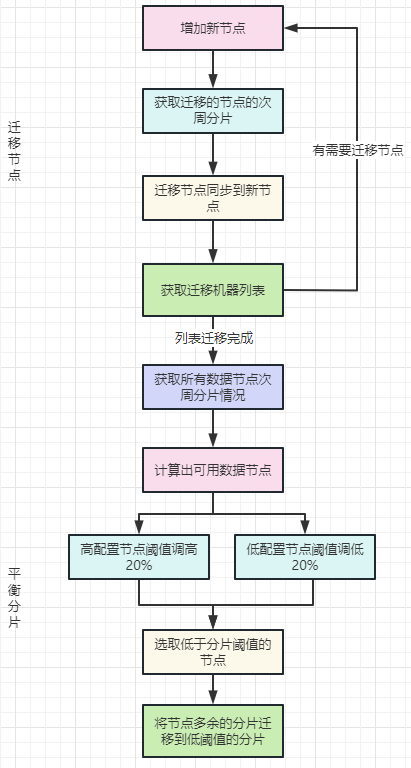
以上设计图有几点需要了解:
顺序:先进行节点迁移,然后进行分片平衡。
时间:一般会提前1-2天创建次周索引,可以在创建索引后进行以上流程操作。
节点迁移增加新节点相当于是将需要迁移的分片迁移到新节点上,因为是新节点,基本上不会有 reroute 冲突。
可以根据机器的配置进行阈值的调整,比如迁移节点后计算节点分片阈值为80(每个节点平均80个次周分片),可以将高配置的机器阈值提高:
* 48c的机器 阈值增加20%
* 32c的机器 阈值降低20%
如果有 ssd 机器,可以在原有阈值上进一步提升,也可以做点对点分片均衡调整,将高配置节点、分片数较少节点统一作为被同步节点,将配置低节点、分片数远高于阈值节点作为同步节点,进行 reroute。
分片均衡,可以参考以下用法:
POST _cluster/reroute{"commands": [{"move": {"index": "log_appcode-2023.18","shard": 59,"from_node": "data2_node1","to_node": "data2_node10"}}]}
在做完以上步骤后,等到次周开始,集群写入都切到了新的索引后,可以进行 exclude 节点操作,此时由于批次节点都没有写入索引,迁移同步分片会非常快,且对性能影响非常小。
总结:
用了这个方法,可以说,速度提升了2倍以上,并提前了一周多完成了节点的迁移。
reroute new shard 思路还适用于平时的平台开发维护,后来也用到了 ES日志集群的拆分工程中,至于 Qunar-ES 集群拆分实践,可以留作后续专门独立做一个分享。
5)coordinate node迁移
coordinate node 主要用来做协调作用,负责接收集群的读写请求,继而传递到数据节点进行实际的数据交互。
本身协调节点不进行存储,主要需要 cpu、内存的资源。
ES日志集群的协调机器大致在40+,分批次每周5台迁移即可,迁移完成,需要对 Logstash 的 output 端进行重刷服务。
注:
建议小集群可以不用单独的协调节点;
大集群协调节点建议如下配置(只做协调作用):
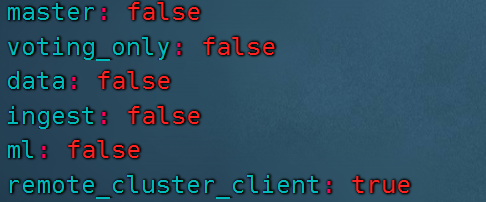
协调节点数:数据节点数 比例建议为:1:8~10。
如果有大批量的备用机器(可以没有独立硬盘)可以作为协调备份节点,可以先上对等批次的机器节点到集群,重刷 Logstash 的 output 端连接,之后将对应数量的节点服务下线,这样可以达到1~2批次内完成所有协调节点迁移工作。
6)master node迁移
master 节点迁移相对来说比较简单,只需要找到临时机器部署在机房 B,部署好对应服务,把机房 A 的 master 服务下掉,把机房 B 的 new master 节点起来即可。
注:
唯一需要注意的点是,由于整个集群的迁移是不停服务的,而 elasticsearch.yml 的 master 与 discovery 模块配置的 master 选举的节点列表已经写的是机房 A 的机器节点,一旦用了机房 B 的 master 服务,是无法感知对应的 node。
master 节点需要一个一个迁移,如果低于需要的最小数量,集群恐无法使用。
master 的 node 名称感知问题可以通过以下方法完成,将 new master 节点→host 到 old master 节点上,效果如下:

当然也可以通过负载和服务发现框架来实现动态调整 master 节点。
做完以上步骤,ES 集群就全部迁移到新机房了,后续就是对应的服务迁移与适配。
四、总结
最终在近三个月的时间里,不断尝试中,完成了集群整体迁移,并且提前了一周多的时间,也做到了零故障。期间遇到元旦峰值,也得到了锻炼和考验。
总结下大规模 ES 集群节点迁移主要的要点有以下:
战略层面
制定迁移计划:针对不同的节点类型制定不同的方案(提前制定好可预见的问题与应对方案,这点非常重要)。
能用自动化代替人工的,尽量多走自动化,提升效率,复用性高,稳定性好。
熟悉对应的底层原理与系统参数,可以更好指导技术层面的优化与实践。
技术层面
total_shards_per_node
node_left.delayed_timeout
单机器单节点迁移
reroute迁移演进
相信以上的经验和一些技术要点,不仅在集群节点迁移可以参考,同样也适用于大规模集群开发与维护。可以说,就是有了不断地集群平台维护开发的经验与总结,才逐步总结出各种优化方法。
小感想:有时候系统性的优化或者方案,从来都不是一蹴而就的,都要通过不断的尝试与调整,在对系统原理的把控上,进行方案的优化,从而取得持续的进步。
参考资料
https://www.elastic.co/cn/blog/how-many-shards-should-i-have-in-my-elasticsearch-cluster
https://www.elastic.co/guide/en/elasticsearch/reference/7.7/allocation-total-shards.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.7/delayed-allocation.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.7/index-modules-translog.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.7/cluster-reroute.html
https://cloud.tencent.com/developer/article/1334743?cps_key=6a15b90f1178f38fb09b07f16943cf3e
https://blog.csdn.net/laoyang360/article/details/108047071








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721