
一、什么是数据湖
数据湖概念于2010年[1]首次提出,经过多年的演变,目前演化出两种不同的定义——公有云数据湖、非公有云数据湖。
AWS [2]、Google Cloud [3] 以及国内的阿里云、腾讯云等公有云厂商对数据湖的定义是一个集中的、近乎无限空间的数据存储区,支持结构化、半结构化、非结构化等各种类型数据。
在公有云厂商的语境下,数据湖一般就是各家的云存储产品,比如 AWS S3、Google Cloud Storage、阿里云 OSS 等。
在云计算出现之前,公司数据主要分散在不同的业务数据库中,由于存储空间有限,存放的是经过处理后的结构化数据,丢失了部分原始信息。
随着业务发展,这类传统的数据库/数据仓库已不能满足多样化的数据应用场景需求。开源 Hadoop及公有云云存储的出现正是为了解决这一痛点,将不同类型的业务数据导入到Hadoop 或云存储中进行后续不同场景的处理,随用随取,因此被称为数据湖。
关于各家公有云的数据湖架构及解决方案,可以参看这篇介绍文章:《数据湖 | 一文读懂 Data Lake 的概念、特征、架构与案例》[4]。
Hadoop、公有云存储支持文件级别的操作,如上传文件、删除文件,不支持对文件内容里行级别的操作,如添加/删除/更新某行。因此,基于 Hadoop 或公有云存储构建的数据仓库不支持实时增量数据更新、不支持流式数据,延迟通常在小时级乃至 T+1。
为此,Uber、Netflix、Databricks 等几家公司在 2017-2019 期间相继推出了Hudi[5]、Iceberg[6]、Delta Lake 等,试图在 Hadoop、公有云存储层之上提供一个通用的表格格式(Table Format)层。国内(非公有云场合)一般称这三者为数据湖。这种叫法是不准确的,但业界一般都这么称呼,我们也跟着“将错就错”。在非公有云场合,如果不特别说明,数据湖一般就是指 Hudi、Iceberg、Delta Lake 三者之一。
综合以上两种定义,我们理解的数据湖应当具备以下几个特性:
统一存储:支持灵活的存储底座(公有云/私有云、HDD/SSD/缓存),具备集中的、足够大的存储空间。
通用数据抽象/组织层:支持结构化、半结构化、非结构化等不同数据类型,并抽象出一层统一的数据组织形式,Hudi、Iceberg、Delta Lake等目前仅统一了结构化数据格式。
支持批处理、流计算、机器学习等不同计算类型
统一的数据管理(元数据中心、生命周期、数据治理等),避免形成数据孤岛。
这类数据湖,我们称之为广义数据湖,与之对应的狭义数据湖就专指Hudi、Iceberg、Delta Lake。我们目前启动了多个项目推进广义数据湖建设,后续会另有专文阐述,本文及本系列后续文章将集中介绍狭义数据湖(下文简称“数据湖”)。
二、为什么需要数据湖
在上一节解释数据湖的定义时,已大体介绍了业务对数据湖的需求,本节将结合三个典型的场景来说明业务为什么需要数据湖。
事件流实时分析是大数据中常见的需求,典型的业务场景如分析广告投放效果、视频实时运营、日志排障等。而相应的技术产品也非常多,图1归纳了常见的产品及其特点:
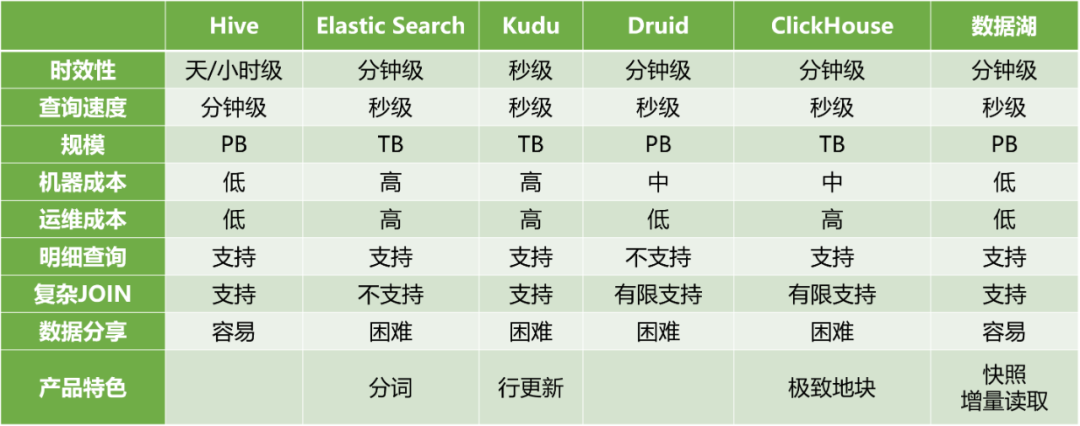
图1 各OLAP引擎特点比较
从图1可以看到,数据湖相比其他产品有如下核心优势:
时效性好:数据湖里的数据近实时( 1-5 分钟)可见,比 Hive 离线延时优势明显,能满足大部分业务的要求。
规模大:数据湖存储使用的是 HDFS,写入吞吐几乎无瓶颈。
成本低:数据湖无需单独服务器,机器成本低,运维成本低。
查询支持:数据湖支持明细数据查询,也支持各种复杂的联合分析。
数据分享:数据湖支持 Spark、Trino、Flink 等各类引擎分析,而数据进入 、ElasticSearch、Kudu、Druid、ClickHouse 后都只能使用专用的查询引擎分析,数据分享需额外导出为 Parquet 等格式。
传统上受规模、成本等限制,业务仅最终报表或者关键链路会使用实时分析,其他场景仍以离线分析为主。随着业务发展,需要一种更大规模、更便宜的近实时分析手段,数据湖就提供了这样的解决方案。
数据变更有如下几种类型,一种是行级变更,如 MySQL中会员订单,用户特征等,其拥有确定的行主键,且列变更频繁,对于此类数据进行聚合分析主要有如下方案:
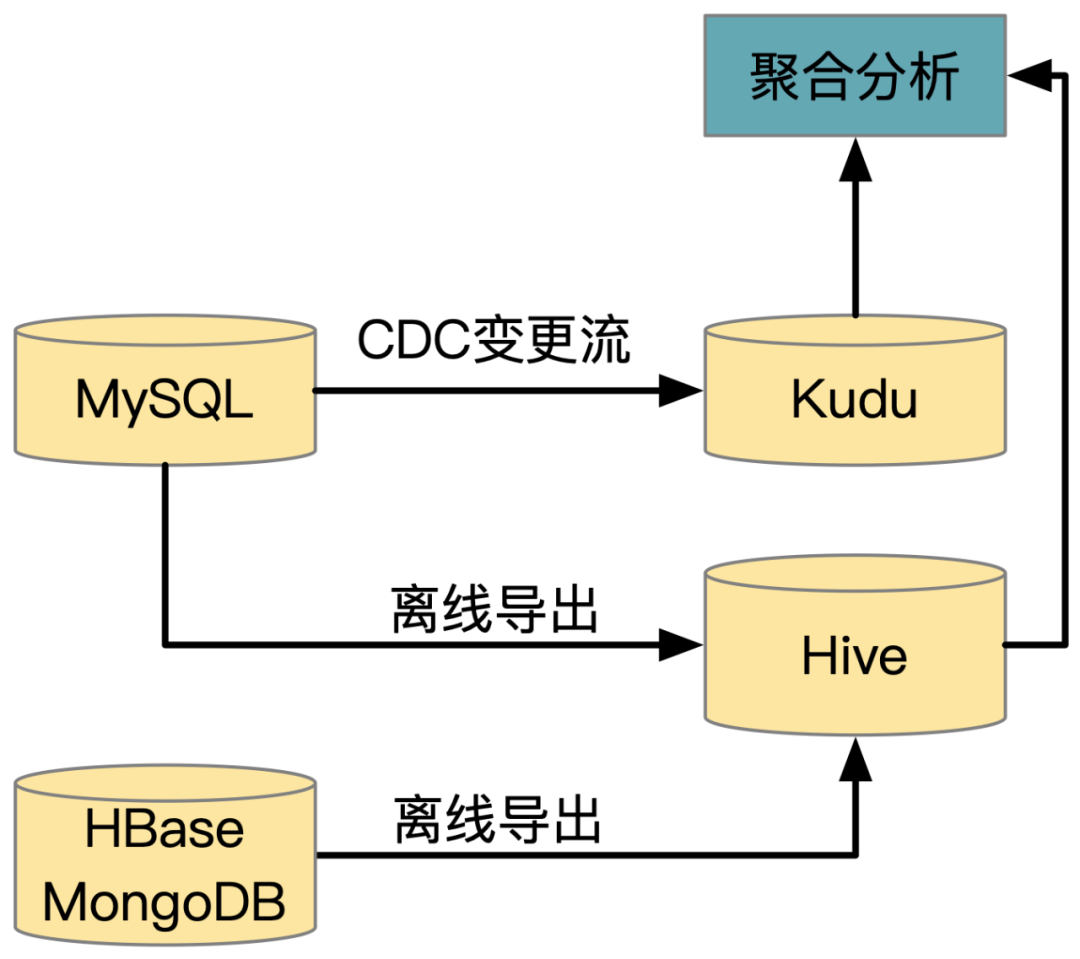
图2 大数据支持行更新常见方案
离线导出:缺点是同步延迟大,通常是 T+1;另一方面是同步代价大,每次需全量导出,给数据源 MySQL/HBase 带来较大读压力。
实时同步进 Kudu:面临规模小、成本大等痛点。
数据变更的另一种形式是新增行或列。Hive 若一个分区计算已经完成,那么晚到的数据只能丢弃,否则需要覆写整个分区。Hive 历史分区新增一个列也需要覆写整个分区。
数据湖解决了业务的上述痛点,业务能将 MySQL、MongoDB 中的变更近实时地入湖。新增行仅需将相应行写文件即可,新增列也支持单独写列文件,无需覆写分区。
爱奇艺大量业务采用图3上半部分所示的 Lambda 架构,实时链路采用 Kafka+Flink 技术,为业务提供实时推荐、实时监控等能力;离线链路采用 HDFS+HiveQL 技术,用于校准数据和扫描查询,该架构具有如下痛点:
离线通路时效性差、而实时通路容量低
维护两套逻辑,开发效率低
容易出现数据不一致
维护两套服务机器,成本高
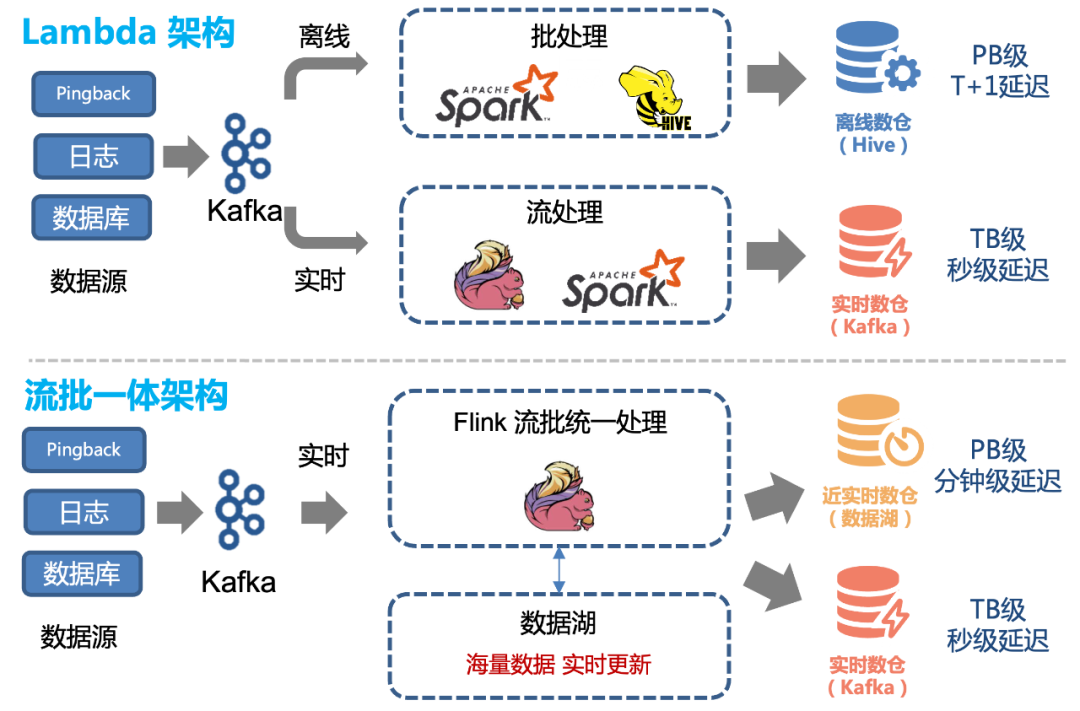
图3 传统Lambda架构和数据湖流批一体架构
而使用数据湖业务能实现流批一体,消费 Kafka 数据近实时入湖(5分钟延迟),既能满足离线的批量扫描、数据覆盖场景,也能满足大部分实时场景(需要秒级延迟的除外)。由此具有如下优势:
支持海量数据近实时更新
一套代码,避免重复开发
避免数据不一致
服务存储和计算成本更低
总结上述几类场景,可以用图4描述数据湖产品所需要的能力,归纳起来其需要具备如下关键特性:
规模大,成本低:能支持PB级别数据规模
支持更新:包括历史分区新增数据、行级更新等
增量拉取:将表的变更转成流数据用于构建下游表
时效性:近实时(5分钟)
查询快:交互级查询速度
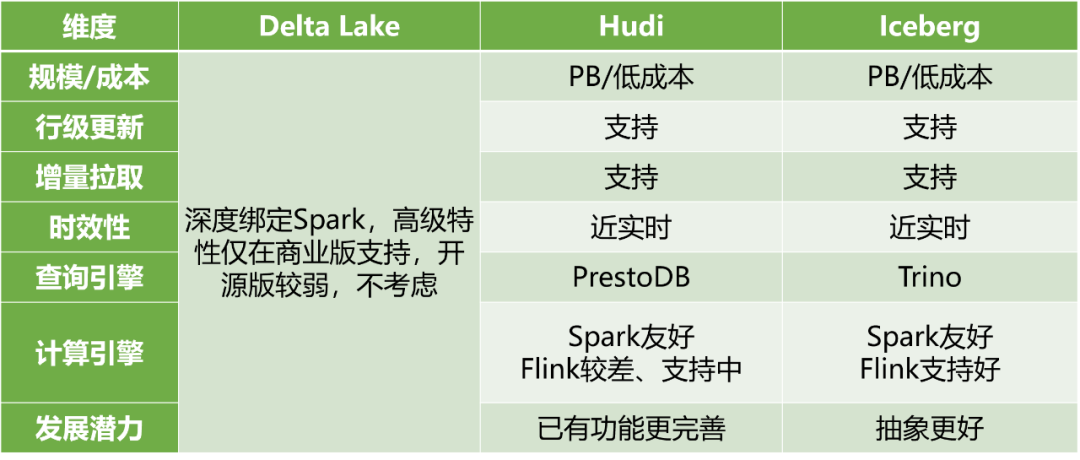
图4 归纳数据湖产品具备的能力
三、数据湖选型及原理说明
爱奇艺从2020年开始调研 Hudi、Iceberg、Delta Lake 这三个主流的数据湖产品(见图5),综合评估各产品的读写性能、平台适配(爱奇艺实时计算平台是基于 Flink 构建的)、未来发展潜力等因素,我们选择使用 Apache Iceberg 作为爱奇艺数据湖的核心基础。
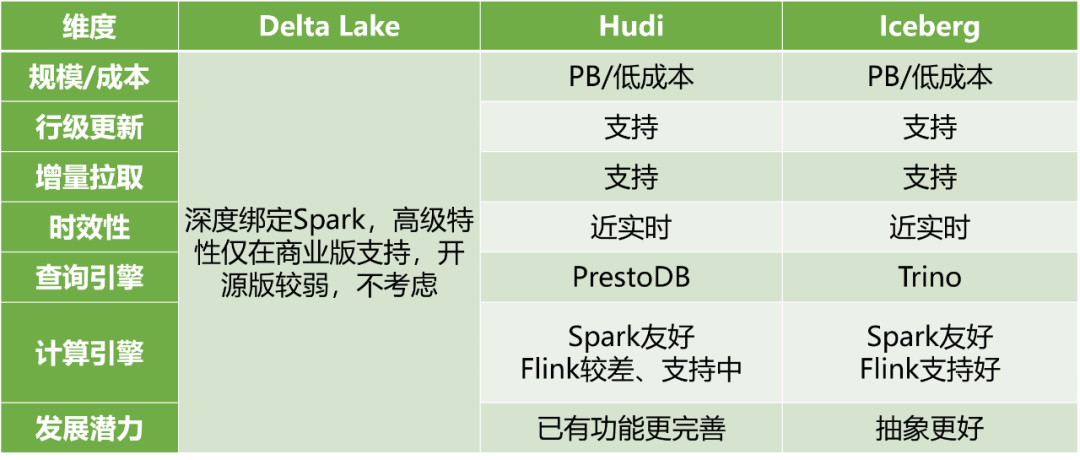
图5 狭义数据湖3大开源产品调研比较
后续内容将介绍 Iceberg 的基本原理,来进一步阐述数据湖的优势。
表格式[7]是 Iceberg 设计的核心概念,因而需要首先明确表格式的定义。从用户的角度,表格式用于回答“表里面有哪些数据”,表格式的关键目标是“让用户和工具能高效地处理表下的数据”。Iceberg 是一种新设计的用于大规模数据集分析开源表格式,图6简单说明了 Iceberg 所属的生态位:
Iceberg 不是存储引擎:其支持 HDFS、S3 对象存储作为底层存储引擎
Iceberg 不是文件格式:使用 Parquet 存储数据文件
Iceberg 不是查询引擎:可通过 Spark/Flink/Trino/Hive 查询
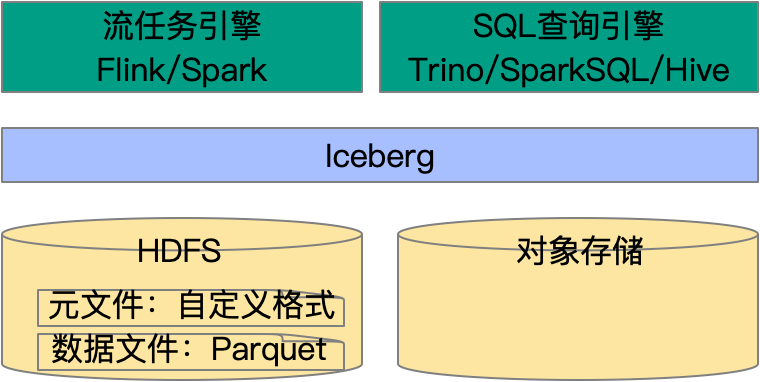
图6 Iceberg 生态位示意图
Hive 是一个非常宽泛的概念,包括 Hive 表格式、HiveQL、Hive 执行引擎等。具体到 Hive 表格式上,其自十多年前诞生以来改变并不大,Hive 表格式可以用图7简单地进行说明,其设计关键点是:
MySQL Metastore 存储元数据,包括库、表和分区信息,不包含文件信息,最小的原子操作是分区级替换。
用目录树组织数据文件,通过 LIST 目录接口获取分区下的数据文件列表,可实现分区级过滤。
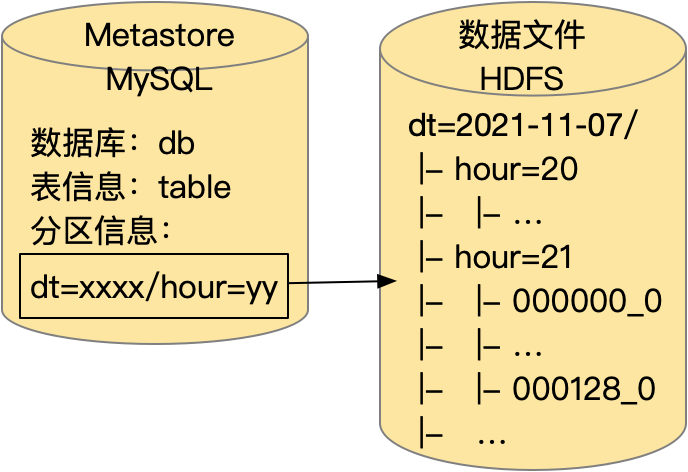
图7 Hive表格式说明
Hive 表格式概念非常简单,并成为事实上的标准,几乎所有的处理引擎均支持。然而 Hive 表格式的设计在大数据量和变更场景下有缺陷。
设计一:元信息不包含文件信息
Hive 元信息仅存储了分区级的信息,获取分区下文件需通过文件系统列举分区目录,导致如下缺点:
制定执行计划慢:假设一个表以小时分区且每小时有 100 个子分区,则 7 天范围共 16.8K 个分区,一个简单地扫描任务需执行 O(N)次 NameNode RPC 调用,N=扫描分区数,假设一次 RPC 调用需 2ms,制定执行计划需耗时 33.6 秒;
无法应用文件级过滤:例如表存储的是广告点击记录,且写入时按照广告主 ID 排序,此时我们查询特定广告主 ID 的记录,每个分区下仅命中少量文件,但 Hive 并无相关信息用于过滤掉其他文件;
设计二:最小的原子操作为分区替换
Hive 大量操作都是先将数据写到临时目录,然后通过将临时目录移动到目标路径完成操作,其缺点是:
不支持修改:分区任何修改都需执行分区级覆盖,如历史分区新增一列;不支持行级修改。
不支持增量:若有一个任务消费表 A 更新表 B,假设表 A 新增了迟到的增量文件,无法获取表 A 的增量更新部分触发计算更新表 ;业务要么选择丢弃增量部分不往下游传递,要么对整个分区进行重算。
依赖文件系统重命名:对于对象存储不友好
Iceberg 的表格式简化说明可参考图8。Hive Metastore 记录表名,并指向当前快照 S1,其指向了本次提交包含的所有数据文件;读操作访问快照 S1,写服务更新快照 S2,S2 在被提交前读不可见;S2 指向本次提交的增量部分数据文件,并将 Parent 指向 S1,S2 全量文件为 S2 和 S1 的总和。
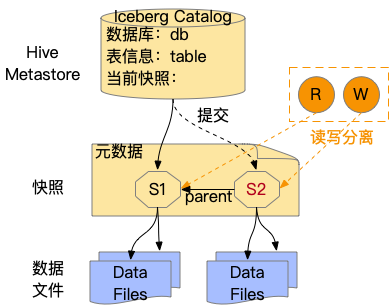
图8 Iceberg 表格式说明
Iceberg 和 Hive 最大的区别是,Hive 元数据仅记录到分区级别,Iceberg 元数据记录到文件级别。这一根本的修改,使得 Iceberg 具备如下几个优势。
优势一:快照之间的隔离
1、读写互不干扰:读写可操作不同的快照,写在提交前不可见。
2、支持并行写入:采用乐观锁的机制,写的过程不加锁,提交前检查是否冲突,无冲突则提交成功,包含冲突内容则放弃提交稍后重试。
优势二:更快地计划和执行速度
1、执行计划快:如前文所述 Hive 制定执行计划耗时和查询涉及的分区数正相关,而 Iceberg 直接读取元数据文件即可获得文件列表,制定执行计划耗时大幅缩短。
2、文件过滤加速执行:Iceberg 记录了文件的统计信息,不同的执行引擎可基于统计信息(MinMax 值、字典、布隆过滤器等)过滤掉无关的文件,大幅减少实际读取的文件数加速执行。
优势三:高效地实现小的修改
1、新增数据:Iceberg 支持往已有的表/分区中添加少量文件,无需分区级覆盖。
2、获取增量:Iceberg 支持获取 2 次快照间的文件变化,并支持流式地读取变更,从而实现增量更新下游表;
行级更新支持
行级更新是数据湖的一个非常有吸引力的特性,有行级更新能力后可以支持很多新的应用场景,典型的如 MySQL 表实时同步到数据湖进行分析。Iceberg 在 V2 格式[8]中实现了行级更新,采取 Merge On Read 的策略,其原理示意可用 图9进行说明,关键概念如下:
1、新定义 DeleteFile:格式上仍然是 DataFile,记录本次提交删除的行。
2、Merge on Read:读取时将 DataFile 和 DeleteFile 内容合并,得到准确的结果。

图9 Iceberg 行级更新一个例子
图9以一个示例进行说明,快照2包含一个DataFile(id=4)和DeleteFile(id=2),读取 S2 快照实际返回 id 集合是(1,3,4);
从原理分析可知,当 Delete 文件非常多时,相关表的查询性能会非常差。Iceberg 通过合并操作将 DataFile 和 DeleteFile 复写为真正的 DataFile,V2 格式表需配置合并任务,定期合并以控制表的文件数量。
技术小结 :Iceberg如何实现设计目标
前文介绍了数据湖的诸多特性和其设计原理,接下来我们总结一下其每个特性是如何实现的,有什么具体的限制:
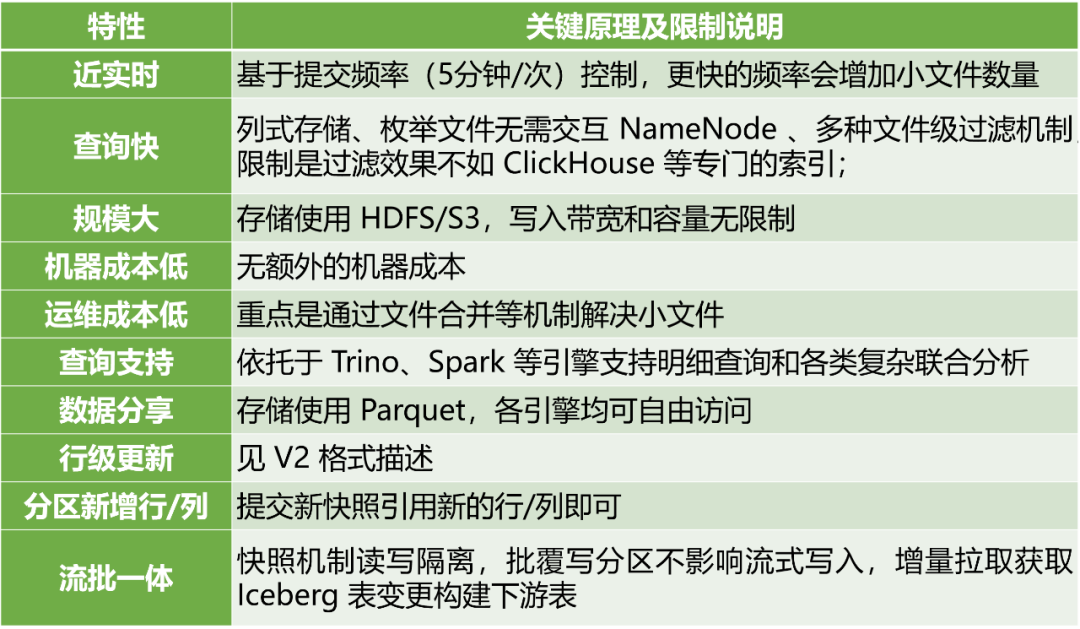
四、数据湖业务落地
本节介绍数据湖在爱奇艺一些业务具体的落地,重点介绍各业务原架构的痛点,使用数据湖后架构的演进和相应的业务价值。
1)业务痛点
Venus 是爱奇艺自研的日志服务平台,支持采集机器、容器上的日志进行集中存储分析。之前使用 ElasticSearch 作为存储,图10上半部分展现了 Venus 使用 ElasticSearch 作为存储引擎的架构。Venus 场景的特点是业务众多,且各个业务日志流写 QPS 大小不一,单个业务流量还可能会快速增加。由于 ElasticSearch 成本高昂,且单集群支持的写 QPS 有限,Venus 团队做出如下优化:
大部分业务配置的是 0 副本:因 ES 写入成本高,所有业务配置 1 副本写入成本需翻倍;0 副本导致任意硬盘/结点/集群故障都会影响部分业务写入。
业务隔离:给高优业务以独立 ElasticSearch 集群,低优业务共用公共集群,避免低优业务流量增长影响高优业务,但无法解决高优业务自身增长的问题。
流量调度:单个集群流量到瓶颈时,将部分流量调度到其他空闲集群;单个集群故障时,将业务流量调度到其他 ElasticSearch 集群。
即使应用以上优化,仍面临如下几个痛点:
写入失败多:业务排查时经常遇到日志延迟半小时以上,甚至写入失败,日志丢失等情况。
排障压力大:由于 0 Replica 很容易导致写入失败,每天需处理10+的运维请求。
成本高:ElasticSearch 设计上是牺牲写入时性能以换取查询性能,而日志类特点是写入 QPS 大,查询 QPS 低,Venus 机器经常磁盘达到瓶颈,而 CPU 和内存大量浪费。
2)新架构
深入分析 Venus 的业务需求后,我们可以总结其核心需求:
数据延迟低:日志采集到查询需要分钟级的延时。
查询速度快:交互式排障需要查询在秒级返回。
写入带宽高:峰值 QPS 千万/秒,总数据量在 PB 级。
Iceberg 完全符合上述业务要求,并且由于 Venus 平台封装了查询的入口,替换底下的存储引擎对业务是透明的。切换后架构图见 图10 下半部分:
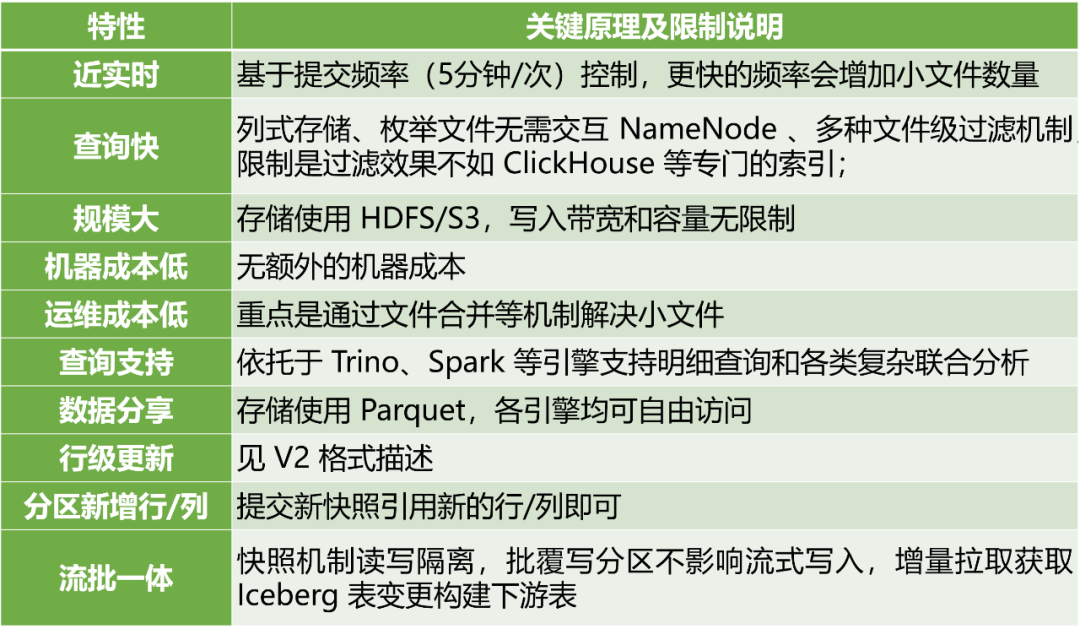
图10 Venus 日志存储由 ElasticSearch 切换为 Iceberg
3)落地效果
Venus 团队在 2021 年三季度开始逐步灰度流量,于 2022 年一季度全部切换为 Iceberg,最终取得如下收益:
成本优化:Iceberg 存储复用的 HDFS,查询所有业务共用一个 Trino 集群,无需部署独立的集群,节省大量机器成本。
写入稳定:由于 Iceberg 存储是 HDFS 3 副本,单个硬盘/结点故障不影响写入,且 Iceberg 写入带宽近乎无限,几乎不再发生达到写入瓶颈、存储容量不足、日志丢失的情况。
排障减少:Venus 团队统计入湖后运维量降低 80%,节省一个运维人力。
1)业务痛点
审核团队业务原架构可用图11虚线以上半部分进行说明,它包含如下关键组件:
MongoDB:存储全量审核数据,规模在百亿行,仅对 ID 构建索引,无法对其他列开启索引;
ElasticSearch:存储用于检索的列,因数据量限制不存储原始消息;线上服务查询某个关键字的记录时,先通过 ElasticSearch 服务筛选命中的 ID 列表,再对 ID 列表逐一查询 MongoDB 获得原始记录;
MySQL:针对一些报表需求,通过定时任务查询 ES 并将聚合结果存储在 MySQL;
Hive:业务原计划将 MongoDB 全量导出为 Hive 用于离线分析。
在原有通路中,报表分析场景面临诸多痛点:
开发成本高:每新增一个报表需求,需开发一个 ES 定时查询任务,将结果记录为一个 MySQL 表,并在报表页面进行适配,无法满足快速变化的分析需求;
ES 查询瓶颈:当定时查询任务较多时,给 ES 服务造成较大的压力,影响线上通路性能和稳定性;
数据质量:当历史数据发生变更,如曾经审核通过的记录当前审核不通过,并不会更新已算好的统计值(如审核通过率),从而报表数据质量会逐渐下降;
存储容量:ES 容量有限,当前 MongoDB 诸多大表不在 ES 通路;
Hive 通路:业务初步调研后发现不可行,一方面全量导出耗时很久,执行一天仍未完成,另一方面导出过程给 MongoDB 造成较大的压力。
2)新架构
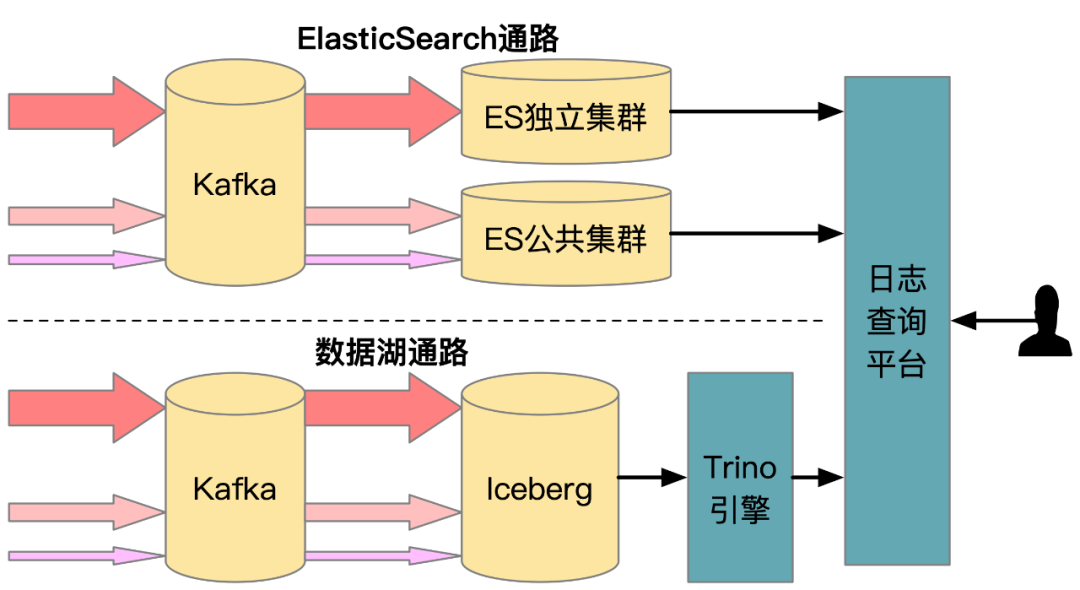
图11 审核业务数据架构图
在和审核团队共同评估业务需求后,可归纳出业务需求的特性:
行级更新:审核的记录会一直变化,如审核状态、修改时间等;
高效查询:支持基于不同列的高效过滤分析,支持和其他表联合分析;
容量大:支持百亿量级,且未来还有更多场景接入。
分析下来 Iceberg 满足业务的需求,由此设计了采用 Iceberg 完成报表分析的方案,见图12虚线以下部分。其关键为审核将变更消息投递到 Kafka,通过实时计算平台配置任务消费 Kafka 更新 Iceberg。业务初始时需将 MongoDB 全量导出到 Iceberg,后续通过行级更新保证 Iceberg 数据的一致性。报表系统使用 SparkSQL 查询 Iceberg,业务除报表外还可通过魔镜满足各类即席分析场景。Iceberg 方案具有如下优势:
开发成本低:撰写 SQL 即可。
查询可扩展:SparkSQL 算力可水平扩展,且不影响线上通路。
数据质量高:行级更新保证 Iceberg 数据和 MongoDB 完全一致。
存储容量大:Iceberg 存储是 HDFS,支持 PB 以上的规模。
时效性好:数据延迟在 5 分钟,近实时地反映数据变更。
3)落地效果
审核团队在 Iceberg 表落地后赋予业务了一系列新的可能性,审核团队基于 Iceberg 表拓展了一系列从无到有的场景,其中部分场景如下:
数据统计:审核团队人效统计、风险监控实时报警;
基于关键字下线:原先需对 ElasticSearch 表全量扫描,影响线上稳定性,现在批量扫描 Iceberg 表即可;
导出数据:由于 MongoDB 无法做 Group By 分析,需导出到 CSV 后再用 Shell 脚本处理,需十几个小时;当前大幅降低工作量,执行 SQL 语句即可,耗时缩短到 5 小时;
降低风险:对数由原先 16 小时缩短到 5 小时,降低漏审/误审带来的内容安全风险。
1)业务痛点
端上埋点在爱奇艺内部习惯被称为 Pingback,其本质是对事件的描述,在一些特定过程中收集用户行为数据,来研究对象的使用状况,为后续的优化和运营策略提供数据支撑。当前 Pingback 链路可以见 图12实时通路和离线通路两部分,其中离线通路以 HDFS、Hive/Spark 作为技术栈构建,将数据以分区管理,数据的延时在小时级别,支持全量读取与分区读取。实时通路以 Kafka、Flink 作为技术栈构建,支持记录级别的增量获取,数据延时在秒级,不支持全量数据读取。Pingback 当前通路有如下问题:
离线通路有小时以上的延时,无法对最新数据做分析;
实时通路不支持数据明细查询,全量分析;
为了同时支持全量分析和低延时数据可见性,构建 Lambda 架构,而同时维护两个开发链路导致开发维护成本高、实时离线数据不一致等问题。
2)新架构
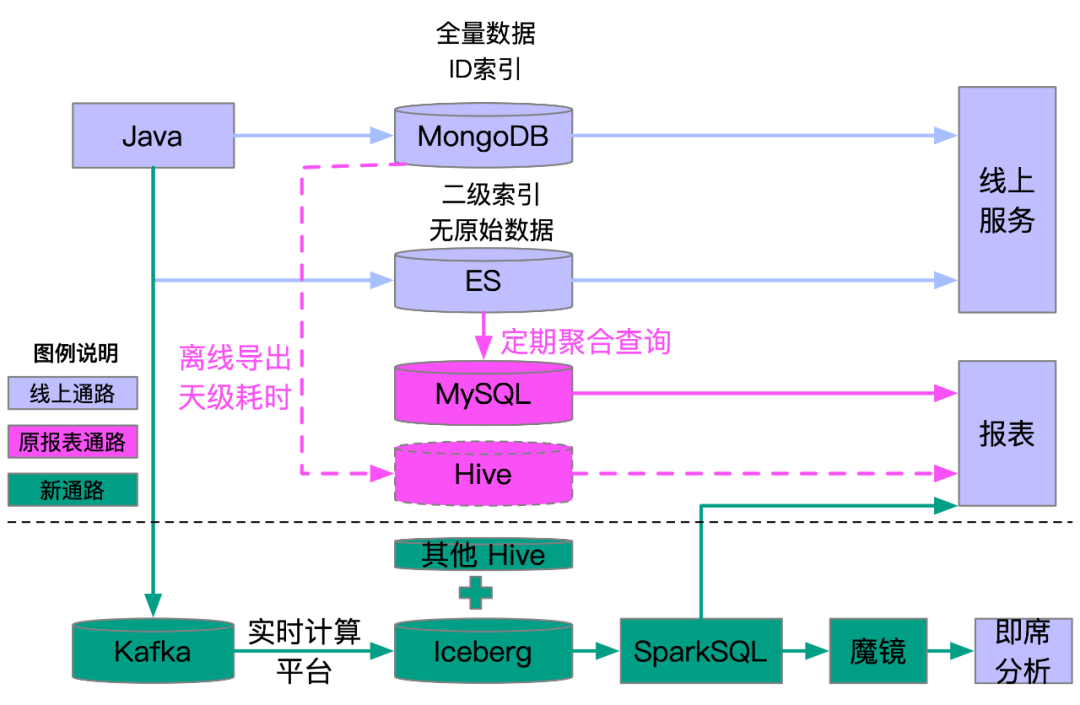
图12 Pingback原Lambda架构和新添加的近实时通路
基于 Iceberg 的特点,Pingback 计划新构建 图4-4 中的流批一体的“近实时通路”,该通路具体包括如下核心环节:
生产 ODS 层表:使用 Flink 增量消费 Kafka 中的全量数据,解析并按投递规则拆分生成 ODS 层表,一个 Flink 任务会拆分生成数百张 Iceberg 表;
生产 DWD 层表:通过 Flink 增量消费 Iceberg 表,进行维度扩展、标准化等加工生成 DWD 层表
下游 Pipeline:下游业务可通过 RCP 实时计算平台、Babel 离线计算平台继续构建 Pipeline,也可在 RAP 实时分析平台、魔镜离线分析平台进行查询分析。
理论上近实时通路可以完全代替掉离线通路,并能替换部分接受5分钟延时的实时通路;近实时通路将带来如下收益:
相比离线通路:数据可见性延时降低到5分钟以内,并且支持增量读取、版本回退等新特性;
相比实时通路:如果可接受5分钟的延时,具备实时通路增量读取的特性,并能支持全量读取、明细数据查询,具有更好的容错性;
相比Lambda架构:能做到存储计算的流批一体,避免开发维护两套代码及实时离线数据不一致的问题;
成本收益:预期近实时通路成本和离线通路接近,同时节省大量实时通路资源。
3)落地效果
当前已支持按需生产 Pingback 数据湖数据,应用情况如下:
播放 Pingback:已生产播放 Pingback 峰值 QPS 百万级的数据,并使用增量读取数据湖的方式构建了爱奇艺的点播、直播报表,数据与已有离线数据一致,延时在 1 分钟左右,相比实时通路成本下降 90%。
QOS Pingback:QOS Pingback 是监控 APP 运行状态的埋点信息,用于监控和排障。相比通过离线明细数据进行故障定位,使用近实时通路,在发现问题后,可立即查询明细数据定位故障,将大幅缩短故障定位时间。当前已稳定生产了 QOS Pingback 的 600 多张表,正在推动业务迁移到近实时通路。
后续计划逐步推动业务将离线通路,及接受分钟级延时的实时通路迁移到近实时通路,构建分钟级延时的 Pingback 流批一体通路。
1)业务痛点
会员订单信息是公司非常关键的信息,其原始信息存储在 MySQL 中,有非常多场景需要对订单信息进行聚合分析。MySQL 聚合分析性能不好,以及需要和其他 Hive 表 JOIN,因而需将订单表同步到 OLAP 引擎,目前通路可见 图4-5 虚线以上部分,主要有 2 种不同的通路:
通路一:MySQL 全量导出到 Hive
其具有如下缺点:
数据时延大:当前导出是天级,业务只能分析一天前的数据;
MySQL 压力大:每天全量导出数据量非常大,容易打满 MySQL CPU;
通路二:消费 CDC 变更流直接写 Kudu
其具有如下缺点:
Kudu 压力大:订单表消耗了 Kudu TB 级的写内存,一方面机器成本高,经常需运维集群,另一方面未来扩展性差,难以承接其他 MySQL 场景。
写任务运维:Kudu 集群写入性能有波动,会造成消费 CDC 变更流写 Kudu 任务堆积,需运维处理。
Spark 任务失败:风控业务定期扫描分析 Kudu 表,一旦 Kudu 表 Tablet 有迁移会造成任务失败。
2)新架构
Iceberg V2 格式支持行级更新后,官方给出了 Flink 消费 CDC 入湖的解决方案,经过多个版本的迭代,解决了一致性、避免重复消费 Binlog 等问题。在此基础上大数据也解决了多个实际使用的问题,如写入性能差、小文件合并、 BloomFilter 加速查询等。以订单表为例,接入数据湖有如下优势:
延时低:近实时延迟,低至5分钟/1分钟。
查询快:通过 SparkSQL 查询,结合文件合并等优化,性能和 Kudu 方案接近。
成本低:Iceberg 无需单独集群,机器成本非常低。
运维低:不会给 MySQL 造成巨大压力,无需特殊运维。
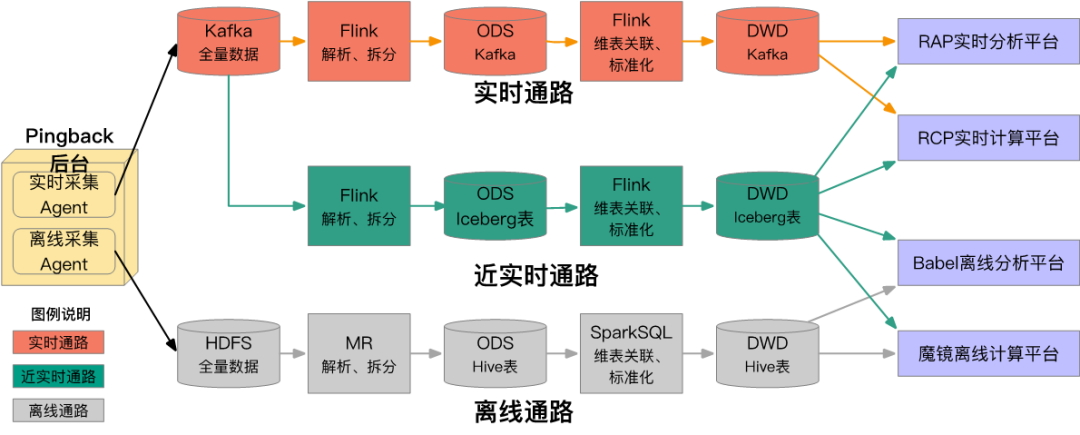
图13 会员订单表MySQL同步到OLAP引擎聚合分析
3)落地效果
目前订单表已完成入湖,数据延时在 1 分钟,通过应用小文件合并、BloomFilter等技术,SparkSQL 查询速度和 Impala/Kudu 方案接近。
五、总结及规划
当前数据湖发展非常迅速,Iceberg 社区、爱奇艺内部应用都在快速成长,在已有的落地场景中可以看到其能给业务带来巨大的价值,优化业务的数据架构,加速数据分析,降低成本。
本篇文章介绍了数据湖的基本原理和公司已落地的场景,我们也看到一些潜在的需求场景,如用户增长业务可应用数据湖进行实时归因、智能出价;奇谱视频元信息因会频繁变更,实时数据存储在 HBase 中,分析需先导出为 Parquet,入湖后可直接分析;进一步推广流批一体在广告、BI 的落地;使用数据湖将特征生产提速到分钟级、支持晚到数据和样本修正。
参考资料
[1] Dixon, James (14 October 2010). "Pentaho, Hadoop, and Data Lakes". James Dixon’s Blog.
[2] AWS. What is a data lake
[3] Google Cloud. What is a data lake
[4] 《数据湖 | 一文读懂Data Lake的概念、特征、架构与案例》
[5] Uber’s case for incremental processing on Hadoop
[6] Iceberg: A modern table format for big data
[7] Apache Iceberg: An Architectural Look Under the Covers
[8] Iceberg Table Spec








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721