
引言
随着大数据技术的广泛应用,集群规模的快速扩展,传统架构下基于大量物理PC服务器构建大数据集群也逐渐暴露出一些不足,主要表现在以下几个方面:
数据节点算力与其存储容量的不匹配造成的资源浪费
海量小文件支持能力差,管理节点性能容易出现瓶颈
无法有效满足跨中心数据容灾要求
为了更加充分的利用资源,满足性能和容灾要求,本文将简要介绍一下G行大数据上云之路的一些思考与探索。
一、云技术带来的改变
云技术的使用,对当前很多分布式软件技术带来的变化可能是颠覆性的。大数据技术——Hadoop也在这一技术变革中悄悄发生改变。Hadoop的设计理念,是使用廉价的物理PC服务器,并使用分布式存储和分布式计算技术,让每一台服务器自己掌管并处理一个数据分片,从而加快整体数据处理速度。
随着技术的持续演进,云技术对于大数据技术带来了重大改变,最具颠覆性的是大数据上云,实现存储和计算分离的架构变化。这个变化有效解决了存储和计算资源不匹配的问题,但同时由于计算数据需要通过网络传递给计算资源,对网络带宽和网络延时也提出了巨大挑战。接下来我们简要分析一下大数据上云带来的变化。
二、大数据上云带来的变化
随着大数据Hadoop技术推广,其在存储端的弊端逐步显现。当前Hadoop使用HDFS方法存储数据,数据迅速膨胀后,小文件急剧增多的特点尤为明显,导致管理节点性能出现瓶颈,无法管理更多数据。即便对数据节点扩容,也无法实现整体集群存储容量扩展,只能通过小文件合并或数据清理手段,完成元数据收缩,因此对业务的发展带来巨大限制。
此外,现有HDFS架构设计中并没有满足异地灾备问题,多数是采用HDFS外部包裹一层应用或采用搭建一个灾备集群的方法满足灾备需求,这两种方法都没有真正实现业务级别灾备。但根据目前业务要求,大数据系统需要像传统业务系统一样,都需要实现业务级别灾备方案。
随着价格不高、存储容量大且性能能够快速横向扩张的分布式对象存储出现,彻底改变现有大数据存储方法;另一方面,结合云技术算力的弹性供给,有效实现大数据存储资源计算资源分离。
分布式对象存储打破原有HDFS对数据文件数量天花板,原有HDFS中管理节点对于元数据存储上线是存在瓶颈的,并且达到上限后无法进行横向扩展。而分布式对象存储使用一致性哈希对元数据进行分区处理。被分区处理的元数据,在数据量不断增长情况下,通过扩展集群可以有效地提高服务容量,在部分服务出现异常时,对应分区数据可以快速切换到可用服务,实现重新提供服务。当数据规模增长到分区限制时,分布式对象存储可以重新设定分区,以支持更高规模的元数据。
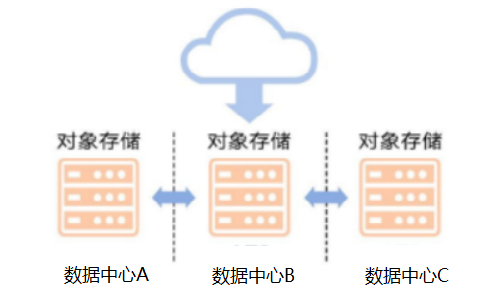
图1 分布式对象存储跨数据中心部署
分布式对象存储具有天然灾备能力,能够直接利用分布式对象存储多站点部署方式,实现数据中心级的容灾,这对金融行业来说至关重要。用户只需要配置数据复制规则,分布式对象存储便会建立起互联通道,将增量或存量数据进行同步。
对于配置了数据规则,可以实现在其中任何一个数据中心进行访问。由于跨数据中心数据具备最终一致性,在有限可预期时间内,用户会获取到最新数据。分布式对象存储这一数据天然灾备优势,HDFS存储方案是不具备的。由于底层存储数据具备了跨中心的容灾特性,与算力资源无状态特性相结合,就构成了金融行业最终需要的大数据集群跨数据中心容灾的架构。未来大数据技术将服务于数据湖一类应用系统,这类系统对于上传的数据,不再像数据仓库系统,对上传的数据进行严格定义。
数据湖未来可能存放大量小文件,HDFS对于小文件的需求无能为力,而分布式对象存储存储可以很方便管理大量小文件。分布式对象存储使用哈希方式进行管理数据,具体来讲,在分布式对象存储存储中,元数据业务数据使用同种方式进行管理,元数据管理同样可以进行横向扩展。而且近几年引入的NVMe-oF技术,实现对元数据查询进行优化,全面提升分布式对象存储性能。
当前分布式对象存储技术发展规律符合摩尔定律,未来可期。
当前Hadoop的MapReduce计算方式,是基于磁盘的数据交换方式。在云环境中,存储计算分离情况下,由于数据传输需要通过网络,这将带来两个方面的问题,一个是对基础网络带宽的压力,另一个是这种数据交换方式将会加大计算时间成本。因此,在进行大数据存算分离架构设计时要充分评估对网络带宽的需求。
另外,为了节省数据传输的延时,一些基于内存数据交换的计算引擎,在计算效率有显著的提高,因此得到更多青睐。虽然当前Hadoop生态中已经存在基于内存数据交换的计算引擎,但随着业务发展集群规模增大,计算任务管理和网络通讯管理,带来很多意想不到的困扰。由于分布式服务高度依赖相互之间的可靠通信,因此计算引擎必须考虑路由,重试和故障转移等场景,保证任务健壮性和计算引擎服务连续性。
早期大数据软件设计初衷,是服务于海量数据处理、业务服务水平协议要求相对较低业务系统,并没有对分布式系统的八个谬误的场景进行完备的设计。随着业务发展,使用大数据软件业务场景越来越复杂,服务的业务系统重要性的逐步提升,业务需求增加,各种云原生的大数据计算引擎也应运而生。
大数据集群网络通讯非常频繁,不仅暴露出大量业务数据通讯端口,同时管理端口也都直接暴露在网络中。现有Hadoop自身不具备安全防护能力,虽然借助一些安全软件对某些访问进行安全认证,但目前大数据软件在安全方面仍没有形成体系。
云原生大数据计算引擎,引入网格概念,当前众多云原生软件引入gRPC技术,用于提升数据通讯及交换能力。同时采用sidecar方式将网络通讯服务从计算引擎中剥离出来,使计算引擎的计算功能和网络通讯功能实现拆分,更好地使用云平台提供网络服务。同时在通讯功能中完善服务安全认证功能,提升大数据集群安全防护能力。
强大的可观察性是处理分布式系统复杂性的基本要求。当前Hadoop架构大数据软件,在可观察性方面没有过多的考虑。所有组件产生的日志,都是相互独立并没有进行串联。大数据软件的运维系统,也都是从集群使用角度看到信息。对于具体应用系统在集群中发生什么,运维系统并没有明确信息给予提示。
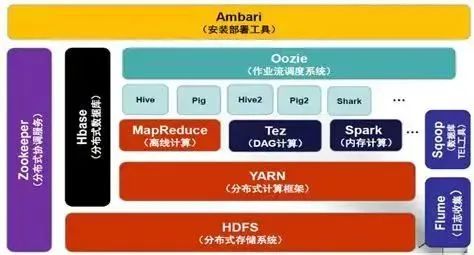
图2 Hadoop技术生态
当云原生大数据由于使用网格技术,并配合云技术可以处理所有通信,它可以提供有关分布式追踪信息。网格可以生成许多指标,例如延迟,流量,错误和饱和度。从之前只能看到单一节点问题,转向业务操作全流程跟踪服务。不仅知道某个大数据集群节点问题,也可以感知到业务侧服务体验。今后对于网格技术的完善,还可以为每个应用请求提供完整记录。可以帮助理解单个服务以及整个系统行为非常有用。
当前Hadoop软件主要是用Java语言开发,而JVM中GC操作已经是大数据软件一大问题,每次出现Full GC状况,大数据软件会处于挂起状态并引发连锁反应,给业务带来影响,而且排查比较困难。随着云技术和内存安全访问技术持续发展golang、rust等语言在开发的软件在云环境中得到推广,从而改善云原生软件健壮性和安全性。
Hadoop软件发展到今天,在yarn资源管理模块中也使用CGroup方式,对物理资源进行切分和管理,同时利用Container技术缓存应用端下发文件,提高应用运行效率。而云技术天生具备硬件资源的池化管理能力,在云上运行应用,不需要自行管理计算资源,可以直接调用云环境中各种API,快速部署和调动所需要运行资源。而且在业务低峰时段,可以将不需要的算力资源归还给云系统,使云环境下算力资源在各种应用中得到充分利用,避免算力资源浪费。
大数据上云后采用存算分离架构,充分解耦算力与存储的关系,真正实现按需合理分配计算资源和存储资源。在传统架构下数据节点CPU使用率普遍在10%以下,而在存算分离架构下,借助于云技术架构下算力资源快速弹性扩展能力能够,CPU使用率一般能够达到40%左右甚至更高,随着集群规模不断扩展,这种成本节约将非常可观。
三、新技术的使用
本文简要分析了当前大数据架构一些弊端和大数据上云后技术架构发生的变化。G行依靠在大数据技术和云技术方面多年积累的技术经验,正在积极准备大数据上云筹划工作,未来不仅对现有架构进行合理裁剪,而且将大力推进云原生技术在大数据业务领域的使用,通过我们的持续思考和探索,走出一条具有G行特色的大数据上云之路。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721