
一、问题与挑战
如何描述、存储和计算优惠并提供较好的业务可扩展性
如何保障大流量下优惠实时计算的性能
为优惠查询加速做的数据同步如何实现一致性
本文的方案经过线上系统验证,对于优惠系统设计的场景和数据同步的场景可做相应的参考。
二、背景
在我们日常生活中,常常会遇到下面这样的场景:

在闲鱼上,针对闲鱼交易中的粉丝购买和粉丝回购的优惠促销场景,提供了一种定向一口价的优惠能力:
卖家可以按商品分别面向全部粉丝、老粉、已购粉设置不同的优惠价格。
买家在导购、下单等场景可以实时看到自己能够享受的最低优惠价格。
三、技术实现
我们通过三个步骤来实现:
分解优惠的基本要素,实现优惠的基本表达和计算;
为了保障大流量下的优惠查询下性能和业务的可扩展性,对优惠对象的判定过程进行抽象和加速;
在优惠对象制备的过程中,通过离线+实时的方式同步数据,保障数据一致性。
四、优惠的描述、存储与计算
一个优惠主要描述了“谁对哪个商品享受什么优惠”,拆解为三个要素就是:【优惠对象】+【优惠商品】+【优惠价格】。
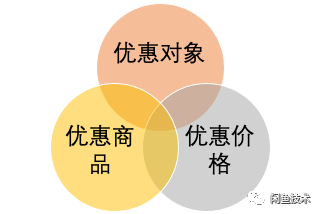
在这个规则中,主要是要解决如何描述优惠对象:在粉丝优惠的场景下,优惠对象是指卖家的粉丝、卖家的已购粉丝等,在存储一条优惠时,一个卖家的粉丝可以被描述为“卖家ID_all_fans”的符号(同理,已购粉丝是“卖家ID_buy_fans”)。这样我们可以得到一个优惠规则的描述大致如下:
【卖家A_all_fans】+【商品1234】+【18.88元】,对应的业务语义是:卖家A的所有粉丝,对于(卖家A的)商品1234,可以以18.88元的优惠价格成交。
以这条优惠为例,当买家B访问商品1234时,我们会执行这样的一个过程:
查询商品1234上的优惠规则,发现一条【卖家A_all_fans】+【商品1234】+【18.88元】的规则;
分析【卖家A_all_fans】表达的含义,表示的是卖家A的全部粉丝可以享受优惠;
确定买家B是否是卖家A的粉丝,如果是,则以18.88元的价格展示优惠或者成交。
这样,我们就实现了优惠设置和计算的能力,这个时候,我们只需要这样一个架构就可以实现:
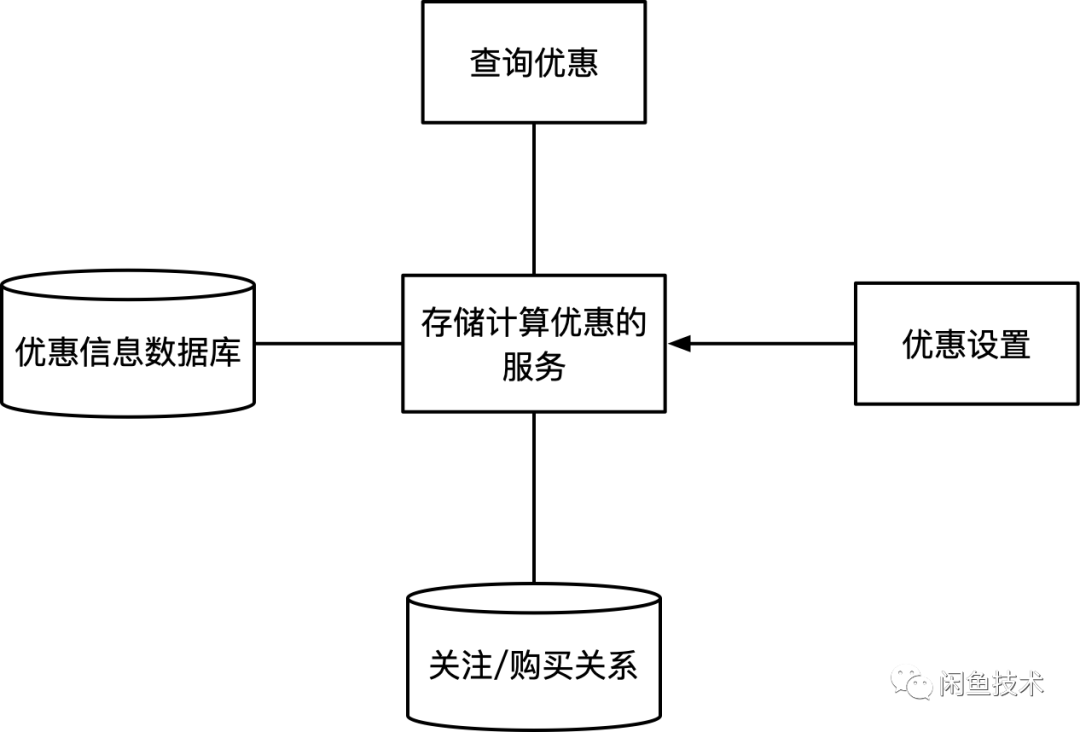
五、优惠对象判定的抽象和加速-人群
但这样的架构存在两个问题:
优惠计算过程需要解析【优惠对象】这个符号背后所包含的业务语义,再由系统进行判断买家是否符合条件,随着业务规则的升级,系统的会变的非常复杂,可扩展性差。
每一次优惠查询,都需要访问用户的关注关系、购买关系,这整个查询过程非常长,性能低下,当面对大流量时,系统会陷入瘫痪。
为了解决这两个问题,我们希望优惠计算过程不再需要理解【优惠对象】的语义,判定过程中也不要再去查询各个业务系统。
我们发现,优惠对象的判定过程,都是在回答“用户是否属于某个群体”,我们可以将这个关系进行抽象,提前制备并存储起来。在我们常见的技术手段中,表达一个用户是否属于某个群体有两种实现:
在用户对象上打上一个标记。
创建一个“人群”对象,将用户关联到人群。
一般情况下,第一种方式使用于群体较少可枚举的情况,第二种方案适用于群体较多的情况。在我们的实现中,使用了第二种方案。
我们将用于描述优惠对象的符号(例如“卖家A_all_fans”)作为人群的名称去定义一个人群,按照这个规则,我们为每个卖家的不同分组各定义这样一个人群(这里人群作为一个符号,这里不需要实际被“创建”)。
人群和用户的关系存储可以通过redis实现,我们设计一个类似:${user_A}_${crowd_B}的key写入redis。在查询时,查询${user_A}_${crowd_B}这个key是否存在,就可以判定user_A是否属于crowd_B。(当然这是一种比较简易的实现,实际设计中需要根据数据特性进行优化)。就这样,我们定义了人群的概念,并提供了一种实现人群的技术方案,这个架构中,人群在同时充当了“协议”和“缓存”的作用。
这时我们的得到的整体架构是这样的(顺带缓存了一下优惠数据):
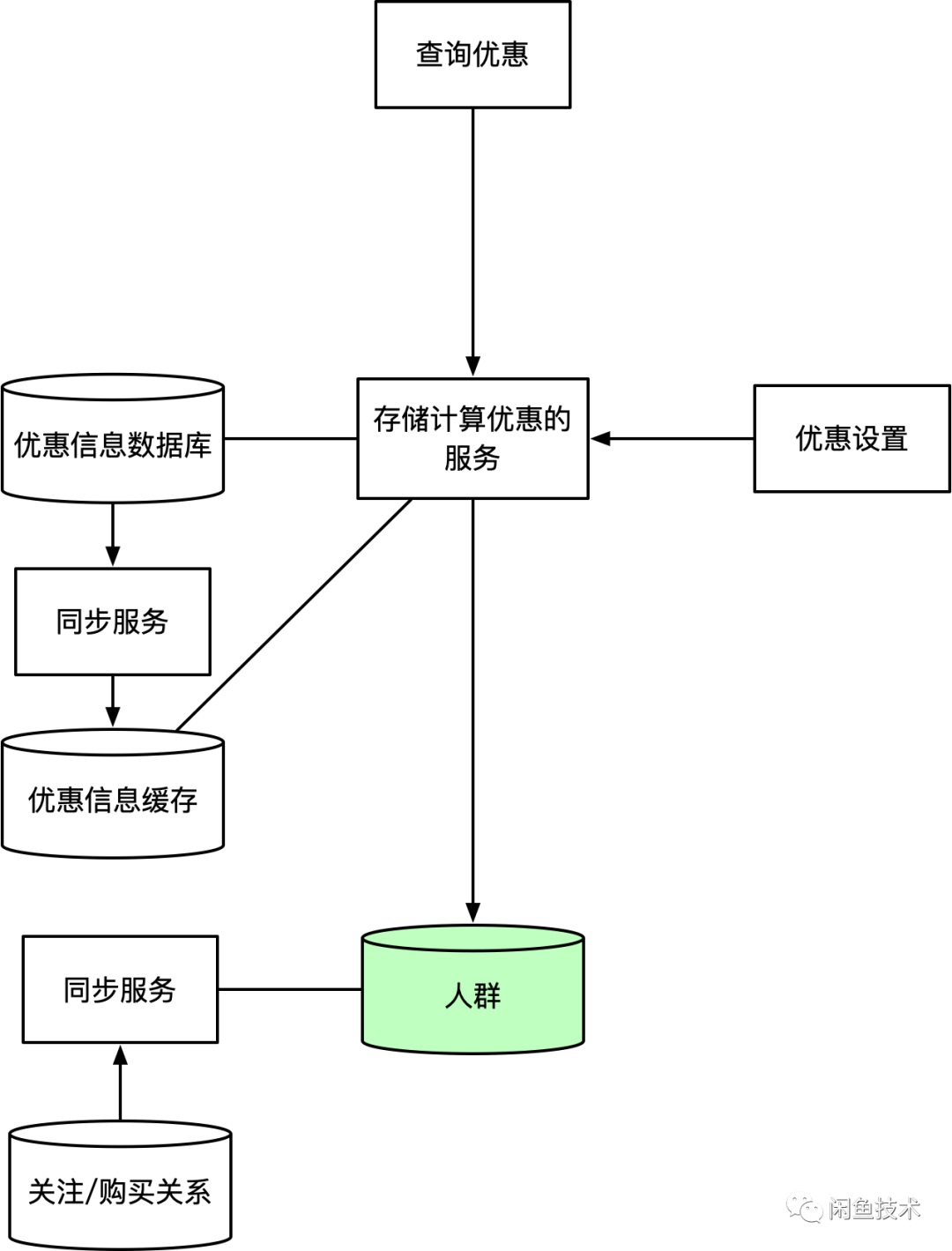
事实上,在我们基于中台的解决方案中,从一开始面临的就是这样的架构(实际中台的架构比这个会更复杂一些)。这里我们尝试从头演进了这个系统,也得到这样的一个方案。
在实际落地的过程中,我们核心要解决的问题,是如何将业务系统中的关注和购买关系同步到人群中,并保证数据的一致性。
六、人群同步的数据一致性
人群的同步整体上分为两个主要部分:
将离线业务数据通过T+1的方式,同步到人群服务中。
通过实时同步的方式,将当天实时产生的关注、取消关注等行为产生的变动,同步的更新到人群服务中。

这种结合的方式具有以下优点:
实时消费消息进行同步,保障了数据的实时性。
离线T+1的全量同步,保证实时同步过程中产生的数据不一致会被及时的纠正,保障了数据的最终一致。
离线同步解决了数据初始化过程中的全量同步问题。
但上述的两个过程中,会出现两类问题:
离线数据因为其数据存储的特征,只会记录存在的关注关系,如果是被删除的关注关系(取消关注),则不会出现在离线数据中。因此实时同步中,因未同步取消关注事件产生了不一致,数据无法被全量同步纠正。
离线同步和实时同步在实际实施过程中,会产生一种常见的数据冲突:用户A今天原本关注了用户B,某天较早的时候取消关注了,如果这个时候的离线数据还没同步完成,全量同步会再次将A对B的关注关系写入到人群中,出现了与实际数据的不一致。
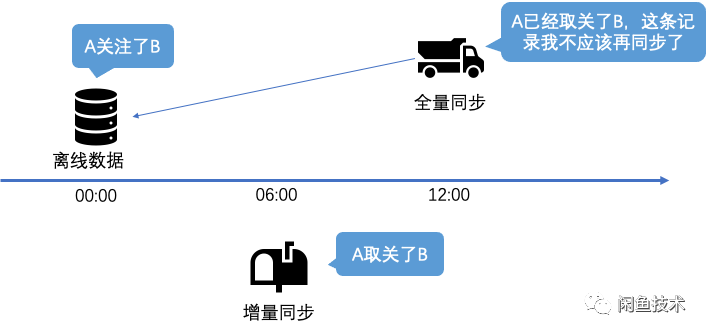
针对上述的两个问题,分别给出了以下两个解决方案:
针对取关数据误差无法通过全量同步纠正的问题,同步过程中,写入人群的时候会添加一个过期时间,这个过期时间略长于离线全量同步的间隔,这样的好处是一旦在实时同步过程中,出现了取关但未同步到人群的情况,这条记录会自动过期,从而避免了不一致的数据在系统中积累。
针对同步过程中发生数据冲突的问题,通过在实时同步的过程中,取关的事件在redis写入一条临时记录,表示该数据近期发生过取关;在全量同步过程中,去比对redis中是否有取关记录,避免发生冲突。
通过上述两个解决方案,我们实现了人群同步的最终一致性,最终实现的方式如图:
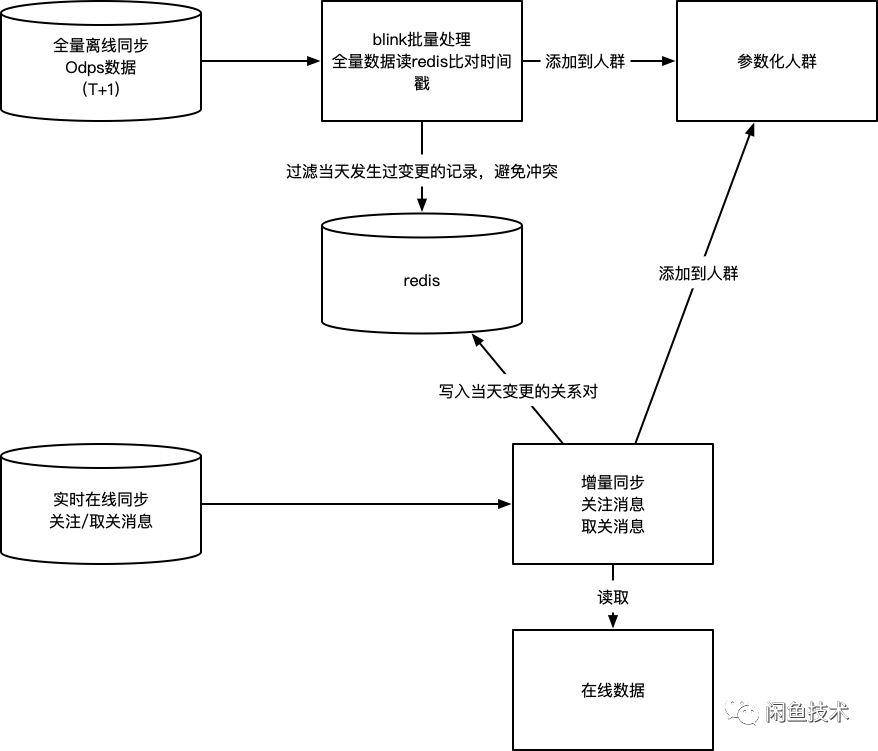
这样的同步方案,对于搜索、推荐等大流量的导购场景,提供了充分的数据一致性保障(绝大多数情况下,数据实时一致,对于小概率出现数据实时同步不一致,通过全量同步保障数据最终一致,满足导购场景的一致性要求)。此外,针对交易这样的要求强一致性但访问规模较小的场景,我们通过下单前对人群同步的数据进行核对,保障数据的实时完全一致。
七、结语
本文从三个部分介绍了优惠的实现:
通过对优惠要素的拆解和人群的定义,我们在描述、存储和计算优惠的同时,提供较好的业务可扩展性。
通过提前制备人群数据,我们保障了大流量下的优惠查询下性能,系统能够支持几十万QPS下的毫秒级响应。
在人群同步的过程中,通过离线+实时的方式同步数据,保障了数据的最终一致性。
八、思考
在优惠的实现过程中,我们直接面临了一个迭代了多年的优惠中台,需要我们通过同步人群数据的方式进行接入。可能一开始会疑惑为什么需要执行一个复杂、高成本且会引入数据一致性风险的同步过程。但当我们从业务的可扩展性、系统的性能角度从头进行推演的时候,我们发现最终会回到类似的架构上来。可以说,在特定的业务规模下,架构的演进有它历史的必然性。当然,也不是说这样的架构是适用于所有情况的,如果我们在一个较小的规模下去快速验证一个优惠能力,那么可能最开始的架构是最合适的,架构选型还是需要结合实际情况出发量身定制。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721