
以下的问题及方案探讨来自:微信交流及腾讯会议。
一、线上问题背景
10 TB 左右集群数据
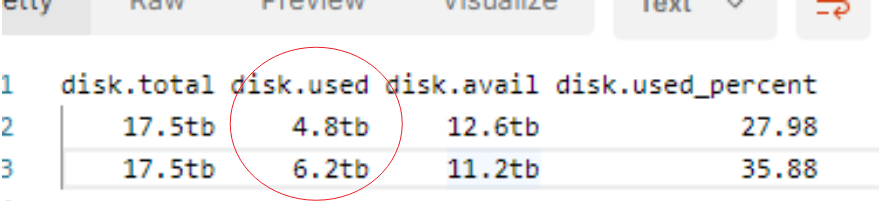
节点集群,资源使用率如下

最大索引:600GB
Elasticsearch 版本:7.17.4
集群共200分片
症状:集群重启无法启动,已启动了20个小时+,集群仍然无法完全恢复正常状态。
经交流反馈:之前,最长时间 8 小时启动集群。现在临近过年放假,直接无法启动。
Caused by: org.elasticsearch.action.UnavailableShardsException: [.monitoring-kibana-7-2023.01.17][0] primary shard is not active Timeout: [1m], request: [BulkShardRequest [[.monitoring-kibana-7-2023.01.17][0]] containing [2] requests]... 11 more[2023-01-17T06:19:46,326][WARN ][o.e.x.m.e.l.LocalExporter] [datanodeprod5.synnex.org] unexpected error while indexing monitoring document

二、企业技术负责团队提出的方案
Delete (cancel) the shards?——删除分片
Move the shards to another node?——移动分片到其他节点
Allocate the shards to the node?——重新分配分片
Update 'number_of_replicas' to 2?——更新副本数
Something else entirely?
三、交流排查发现问题
大前提:企业技术团队提出的方案都是基于 Setting 等的修改,但是当前集群一直处于主分片分配的状态,集群一直 red,很多操作是无法执行的。
我们采取一遍交流一遍排查问题,交流发现如下问题:
集群规划不合理,数据量10TB+,单只仅2个节点,节点角色都是默认值。
极大规模的单索引、极大规模的单分片有好几个,举例:存在超大 600GB 索引。
开发和运维都不清楚设置了几个分片和副本(非常诡异,没有重视)。
遇到重启耗时8 个小时,没有排查原因,没有引起重视,直到春节放假出了严重问题才足够重视。
一句话概括描述问题所在:
由于分片、副本个数设置不合理,分片大小规划不合理等集群前期规划不合理,导致集群重启耗时巨长,无法正常启动或者说启动一直显示:recovery 30%左右,非常慢。重启期间(recovery)由于持续有主分片未分配或恢复成功,导致集群一致处于red状态。
Kibana、Head 插件都无法连接成功(集群red状态,Kibana无法连接 Elasticsearch),只能通过 postman 工具执行有限的少数几个命令,集群响应巨慢甚至很多时候无响应。
四、解决方案探讨
基于如下五种情况,Elasticsearch 自动执行恢复(recovery):
节点启动(这种类型的恢复称为本地存储恢复);
将主分片复制到副本分片;
将分片迁移到同一集群中的不同节点;
恢复快照(又称作:快照还原 restore 操作);
Clone, shrink, or split 操作。
https://www.elastic.co/guide/en/elasticsearch/reference/current/cat-recovery.html
在集群尚可用的情况下,可以尝试使用以下操作:
GET _cat/recovery?v=true&h=i,s,t,ty,st,shost,thost,f,fp,b,bp&s=index:desc

用途:返回有关分片恢复的信息,包括正在进行的和已完成的。
注意:分片恢复完成后,恢复的分片可用于搜索和索引。
如下设置若生效,本质上是:
node_concurrent_incoming_recoveries和 node_concurrent_outgoing_recoveries同时生效。
incoming_recoverie可以简单理解为副本分片的恢复,outgoing_recoveries可以简单理解为主分片的恢复。
PUT _cluster/settings{"transient": {"cluster.routing.allocation.node_concurrent_recoveries": 3}}
默认值是2,理论上调大会增大并发。
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-cluster.html
当节点出于任何原因(人为原因或系统异常)离开集群时,主节点会做出以下反应(如下称为步骤 X 是方便后续的解读):
步骤1:将副本分片提升为主分片以替换节点上的任何主分片。
步骤2:分配副本分片以替换丢失的副本(在有足够的节点的前提下)。
步骤3:在其余节点之间均匀地重新平衡分片。
以上操作的好处是:避免集群数据丢失,确保集群高可用。
但可能带来的副作用也非常明显:其一,会给集群带来额外的负载(分片分配非常耗费系统资源);其二,若离开集群的节点很快返回,上述机制的必要性就有待商榷。
此时,延迟分片分配就显得非常必要,设置如下:
PUT _all/_settings{"settings": {"index.unassigned.node_left.delayed_timeout": "6m"}}
延时分片分配策略的本质(大白话):
当节点离开集群并确认几分钟(自己设定)可以快速上线的情况下,离开的过程中只触发步骤1的将离开节点上的对应的副本分片提升为主分片。此时集群至少不是red 状态,而是yellow状态。步骤2、步骤3不会发生,此时集群是可用的,待设定的几分钟内下线集群确保重新上线后,分片再重新转为副本分片,此时集群恢复绿色状态。
这个过程有效避免了步骤2、步骤3的分片分配,整体上以最短的时间确保了集群的高可用性。
https://www.elastic.co/guide/en/elasticsearch/reference/current/delayed-allocation.html
Elasticsearch 限制分配给恢复的速度以避免集群过载。
可以更新此设置以使恢复更快或更慢,具体取决于业务要求。在资源允许的情况下,想快就调大;反之,则相反。
但一味的追求快速恢复,将如下设置过高,正在进行的恢复操作会消耗过多的带宽和其他资源,这可能会破坏集群的稳定性。
PUT _cluster/settings{"transient": {"indices.recovery.max_bytes_per_sec": "100mb"}}
注意事项:
这是集群层面的动态设置,一旦设置后,对集群中每个节点都生效。
如果仅想限制有限的某个节点,可以通过更新elasticsearch.yml 配置文件的静态配置来实现。
https://www.elastic.co/guide/en/elasticsearch/reference/current/recovery.html
但是,上述操作对于当前出问题的集群都无法实现,主要原因:集群无法响应。
怎么办?这时候需要再寻它法。
能否物理删除不必要的索引,提高集群启动速度呢?这个大胆的想法就这么出来了。试试看!
五、索引恢复提速方案探讨
提速的核心:删除历史“包袱”(将来不再需要的大索引),以间接使得集群恢复加速。
免责说明:
如下的验证,仅在单节点集群验证 ok,多节点原理一致。
涉及文件的操作,是无法之法,万不得已,不要直接操作文件。
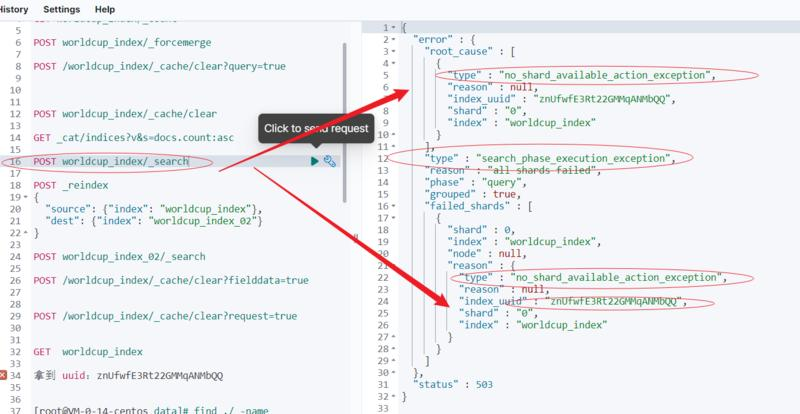
部分命令可执行,可以 cat/index
GET _cat/indices?v&s=docs.count:desc
见下图:

对应 uuid:"znUfwfE3Rt22GMMqANMbQQ"
这一步目的:找到需要删除、业务层面彻底放弃的索引直接物理删除文件,为重启集群会减少恢复压力。
[root@VM-0-14-centos data]# find ./ -name "znUfwfE3Rt22GMMqANMbQQ"
找到位置:
./indices/znUfwfE3Rt22GMMqANMbQQ

建议:先备份,后执行物理删除。
这样理论上可以正常启动,我自己小范围集群验证没有问题。
中间环节的验证截图:
再次强调:这是无法之法!万不得已,不要直接操作文件!
六、小结
由于涉及线上环境和10TB+的业务数据,开发团队暂没有立即采取文件删除的方案,待团队重新讨论和进一步核实后定夺。
这给我们后来人或者球友的警示如下:
“亡羊补牢”,在丢一只羊的时候就得补!
团队里得有个对ES相对比较熟悉的人,否则遇到难题非常麻烦(尤其节假日期间更为麻烦)。
定时快照功能很重要。
集群128GB 部署一个节点的必要性待验证。
相关调优参数的乱上,就是病急乱投医。要一个个验证可行后才可以大胆用。
要有小范围可测试的集群,线上环境动可能就是大问题。
大分片(数百GB)有百害而无一例,尤其集群重启、故障恢复就是累赘。大了不怕,ILM 必须得用起来。历史数据该清理的清理、该冷的冷处理方为王道!








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721