
一、现象
开发反馈日志系统查询不可用,运维收到日志系统kafka消息堆积告警。

二、背景
我们的日志系统从ELK架构迁移到基于ClickHouse集群架构,流程如下:
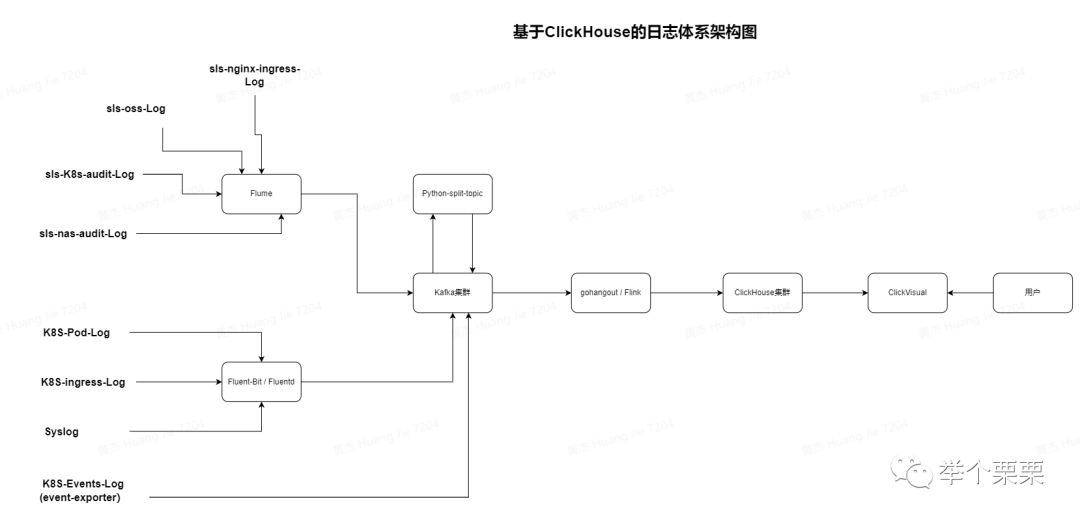
Flume:阿里云推荐的日志处理工具,可以很方便地把sls日志采集到 kafka topic 中。
Fluent-bit/Fluentd:早期集群通过fluentd采集日志,但fluentd效率相对较低,占用的资源比fluent-bit 高很多,因此逐步更改为 fluent-bit。
Python split topic:将k8s 采集的日志按需分发到指定的子topic中,以便于后续进一步被 gohangout 或者 flink 写入到 CK表中。
Gohangout:使用 golang 模仿的 Logstash,轻量高效。用于消费 Kafka 数据,处理后写入 ES、Clickhouse 等。
Flink:使用Flink开发job消费kafka日志并写入到Clickhouse中,支持批量写和定时写。支持自定义逻辑。
Clickhouse:ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS)。其具备查询速度快、数据压缩率高等特性。
Clickvisual:轻量级日志查询、分析、报警可视化平台; 其前端相当大一部分查询功能参考 Kibana。
由上面介绍可知,我们由gohangout和Flink两部分中间件读取kafka日志写入到ClickHouse集群中。
三、分析和恢复
根据告警的topic,查看了Flink任务消费的topic如下:

可以看到消费者不正常,消息也不断在堆积。此时查看Flink Job的日志:
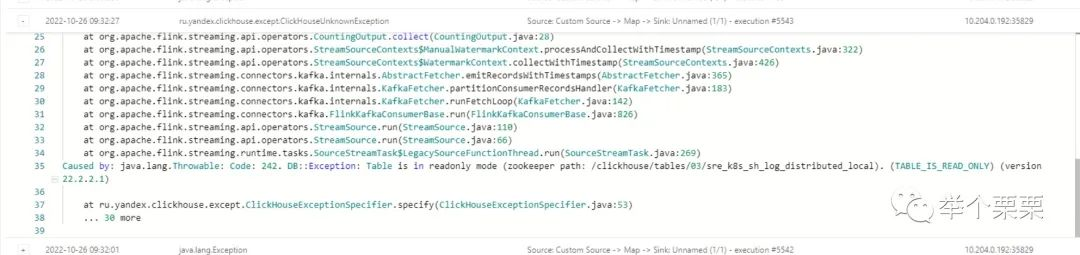
可以看到Flink写入Clickhouse时,表变为只读了。无法写入,所以报错,消息堆积。查看Clickhouse集群状态,发现不只是这个表。而是整个集群所有的表都变为只读了:

此时,gohangout也和Flink Job报一样的错。表只读。
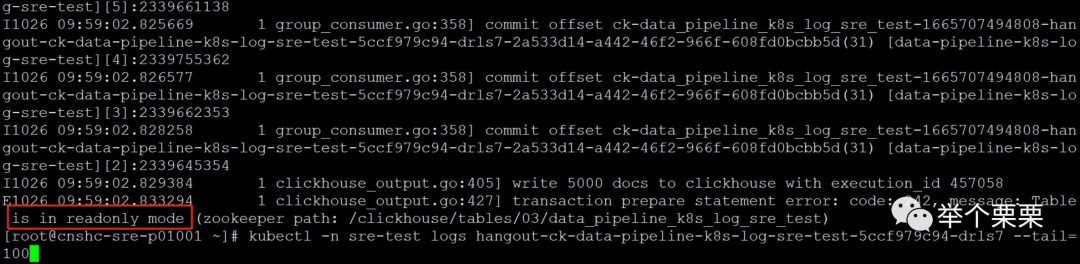
Clickhouse是使用zookeeper来存储元数据,并通过zookeeper实现注册和集群协调的。我们clickhouse集群和zookeeper集群都是部署的三节点(使用相同的节点)。应该和zookeeper集群有关系。查看zookeeper集群日志,报错如下:
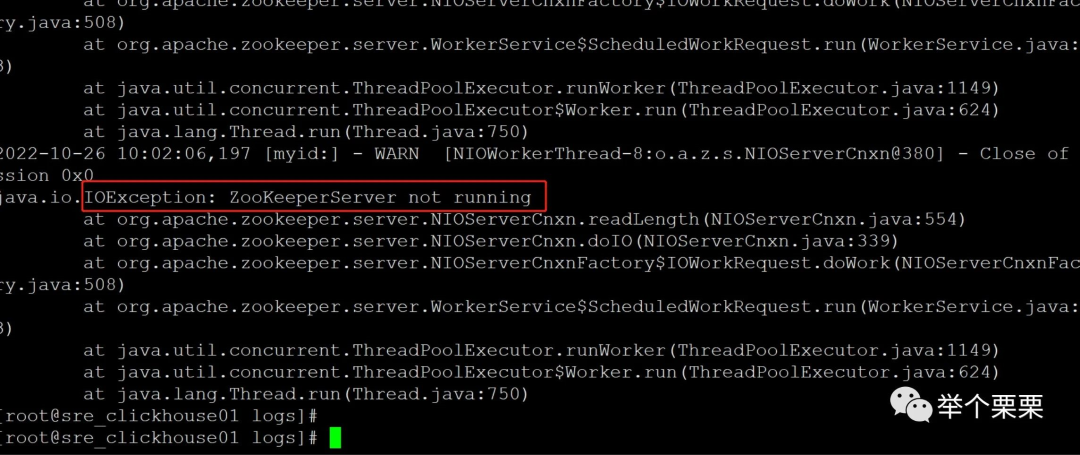
此时zookeeper集群状态异常。于是尝试逐个重启zookeeper进程,重启后,三个节点只有一个节点正常,其余两个节点不断重启。并报如下错误:
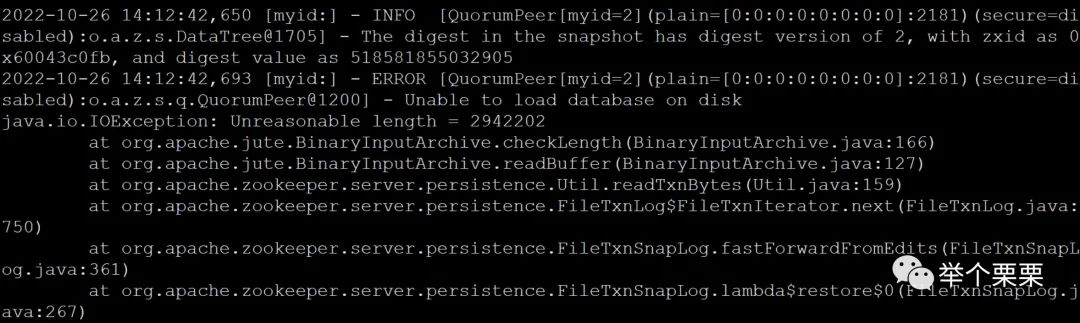
这个报错是说无法加载zookeeper的数据,因为读取元数据行大小超过1.01M。(zookeeper启动时会加载snapshot.xxx快照文件,逐行读取,每行默认不超过1M)。此时clickhouse报错如下:
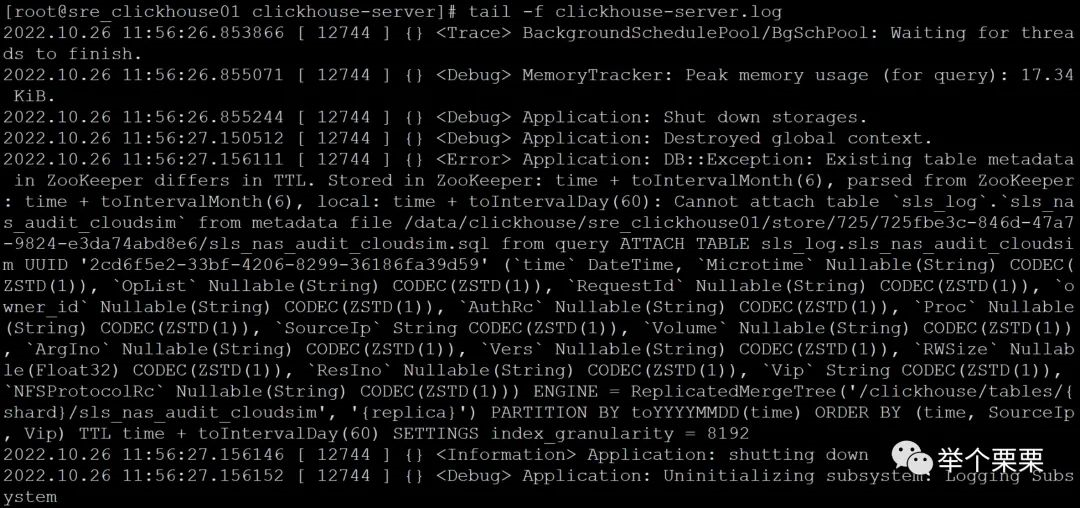
这个报错是说zookeeper元数据和clickhouse本地元数据的TTL配置不一样。同事反馈说是他前一天执行了TTL策略的修改(将数据保留6个月改为保留60天,以减少磁盘空间),当时执行时间很长但最终是成功的。由此判断应该是修改TTL策略的DDL执行异常导致zookeeper和clickhouse本地元数据不一致,从而使得clickhouse集群和zookeeper集群异常。修改TTL的DDL语句如下:
$ ALTER TABLE k8s_log.data_pipeline_k8s_log ON CLUSTER sre_ck_cluster MODIFY TTL timestamp + toIntervalDay(60);
下面尝试修复zookeeper元数据,恢复到clickhouse集群正常前的状态。询问同事是什么时候修改TTL的,大概时间为和zookeeper的snapshot.xxx文件时间对的上(但是不确定具体的时间):

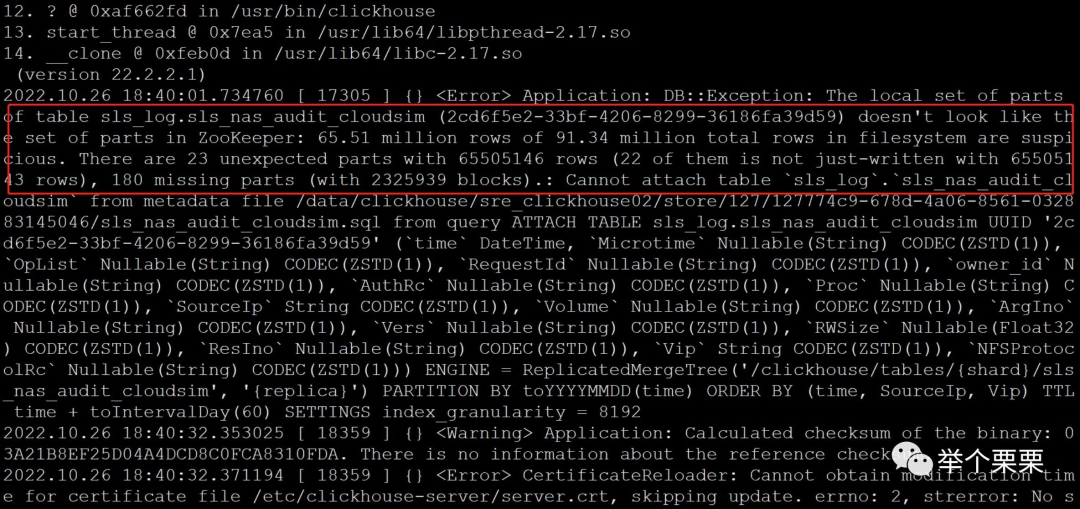
于是决定将三个节点上zookeeper的这个时间点以后的snapshot.xxx快照文件和log.xxx日志文件移到备份目录后逐一重启。如果重启后还是报“Unable to load database on disk. Unreasonable length - ”的错误就将三个节点的clickhouse进程都停掉,继续将snapshot快照文件往前删后重启zookeeper,直到没有这个报错。(不过需要评估集群最近正常状态的时间,不要恢复到过早的时间状态,可能元数据会差距过大)。我这里重试了几个最近时间的snapshot文件后重启zookeeper集群正常了。三个节点正常启动并状态正常,数据查看也正常。
zookeeper集群恢复后,开始尝试启动clickhouse。先只启动一个节点,报错如下:
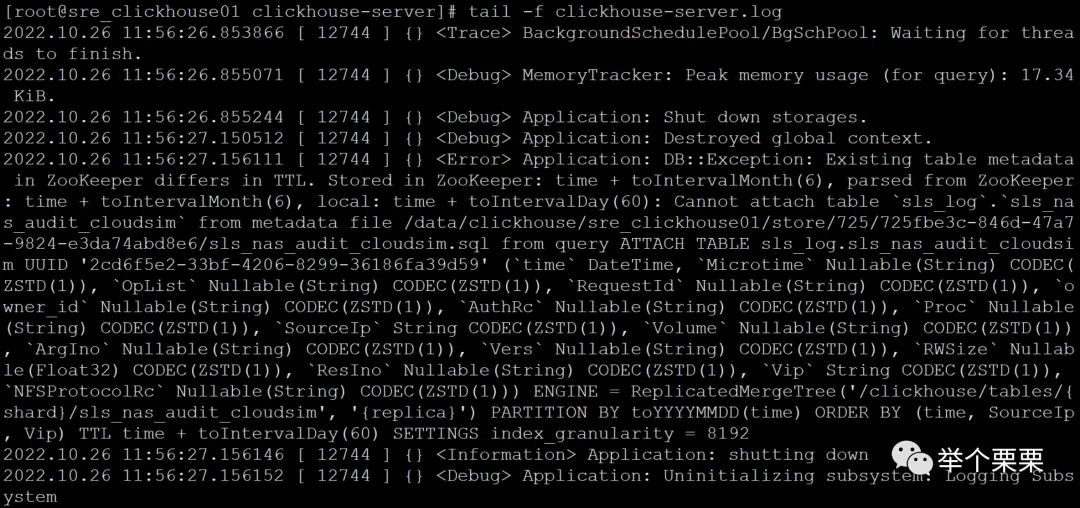
还是TTL元数据不一致的问题,可以看到,zookeeper的数据是TTL修改之前的策略:保留6个月;而clickhouse节点本地元数据是修改后的TTL策略:保留60天。元数据不一样,手工修改clickhouse本地的元数据,将TTL策略改回保留6个月。于是,到clickhouse的数据目录下的metadata目录下,grep所有的*.sql文件并将TTL修改为和zookeeper一致。(注意:clickhouse会把表结构的元数据以sql语句的形式保存到metadata元数据目录下)。修改完成后重启clickhouse进程正常了。重启clickhouse进程不一定马上起得来,数据量比较大的需要等一段时间,可以通过查看8123和9000的监听端口状态来判断进程是否真的正常启动了,也可以看日志是否正常加载数据。第一个节点正常启动后,用同样的是方式去启动另外两个节点,操作完成后发现,第三个节点也启动正常了。但是第二个节点启动报错并不断重启。
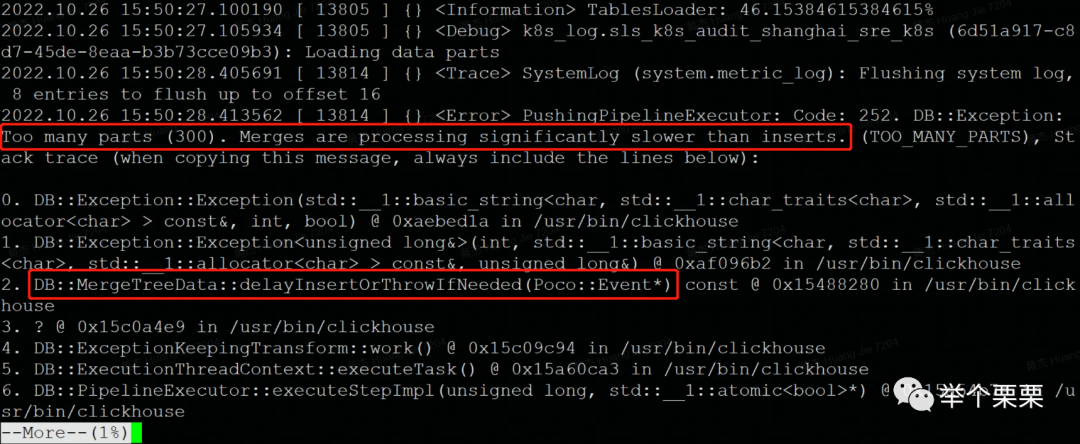
可以看到这里有两个报错,第一个是Too many parts(300)。但是我们已经将gohangout和Flink job停止了,已经停止写入了,为什么还会报这个错误呢?至于第二个,看样子应该是删除了zookeeper的snapshot.xxx和log.xxx日志后,表的数据块不一致导致的。由于是审计日志,可以删除。为了尽快恢复集群,于是决定将这个表在这个节点的数据删除掉。将clickhouse数据目录下的data/sls_log/sls_nas_audit_cloudsim软链的store数据目录和metadata/sls_log/sls_nas_audit_cloudsim.sql文件删除(我这里是移走备份)。在这个过程中同事找到一个表的表分区很多,有2.17w个。

怀疑可能是导致的Too many parts (300). Merges are processing significantly slower than inserts报错原因。于是也将该表的表分区数据直接删除,只保留了最近几个分区。然后重启clickhouse进程后正常了。为了验证是哪个操作解决了问题,于是我将sls_nas_audit_cloudsim表的数据和元数据恢复回去,重启clickhouse进程后同样报上面的第二个错。但是无法取证Too many parts(300)的错误到底是sls_nas_audit_cloudsim元数据不一致导致还是表分区过多导致。由于已经处理很久了,业务需要使用日志系统,集群已经恢复就没有继续折腾验证了。
到此,clickhouse集群恢复了。但是有部分数据是删除丢失了。并且sls_nas_audit_cloudsim表需要在该节点上重建,因为该表的数据和元数据都已经删除了。查看表可以看到只有分布式表,而没有原表。

于是,从其它节点查看该表表结构或者从备份的sls_nas_audit_cloudsim.sql元数据文件中查看sql来恢复。这里恢复时报错,说表在zookeeper中存在。因为我们只删除了该表在本地的元数据,在zookeeper的元数据还存在。还需要删除zookeeper中该表的元数据。删除如下:

使用deleteall删除节点目录(rmr命令新版本已弃用),如果是文件,使用delete命令。

如上图所示,删除zookeeper元数据后重建表成功。并测试集群读写正常。
至此,集群恢复。启动gohangout/Flink job进程恢复日志正常消费存储。
四、遗留问题
1)Too many parts(300)问题的原因验证;
2)TTL策略修改的正确姿势;
3)clickhouse和zookeeper集群状态的监控告警;
4)深入了解clickhouse和zookeeper的元数据存储机制,clickhouse启动流程分析。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721