
随着ClickHouse日志存储上线,开启替换ElasticSearch的切换过程,是时候为过去一段时间ClickHouse各种尝试做个总结。本文的主要内容有:
集群规模与调优
表结构设计要点
其他设计点补充
一、集群规模与调优
一个集群多少节点,节点使用什么样的配置,总共需要多少个集群。
在规划时首先需要考虑的,并在实践中也需要相互验证与调整。
使用冷热分离架构,一个节点挂2T的热盘以及5T的冷盘。
每个节点热盘使用SSD,冷盘使用普通盘。
笔者一个ClickHouse集群部署了20个节点。
1、集群规模
日志存储划分为几个集群,有的公司会将所有的日志存储在一个集群。
根据公司情况将ClickHouse集群划分了4个,具体规模需要根据实际情况评估。
集群一:存储支撑域相关日志。
集群二:存储非交易业务日志。
集群三:存储交易相关日志。
集群四:存储算法推荐相关日志。
备注1:划分为多个集群,可根据不同的业务域方便针对性的治理。
备注2:一个集群有问题时方便将日志流量调度到其他日志集群应急处理。
2、集群配置
1)集群配置一
刚开始规划使用16C64G的配置,然而查询确遇到了问题,无法投产。
测试精确查找一条日志,需要30秒。
模糊查询一条最近5小时内的日志,需要60秒。
备注1:投产需要查询耗时无明显的等待感,5秒内为宜。
备注2:小部分超过5秒也可以接受,否则无法在生产环境投入使用。
2)集群配置二
后来通过与业内ClickHouse专家与公司同事反复沟通与对焦,将配置提升到48C192G。
精确查找一条日志,几百毫秒返回。
布隆查询一条最近5小时内的日志,秒级返回。
模糊查询一条最近5小时内的日志,3秒内返回。
备注1:该配置基本满足了业务支撑类场景的使用。
备注2:然对于推荐算法这种高吞吐、大消息(高达20KB一条)依然不能解决。
3)集群配置三
针对算法推荐场景针对性治理,单条消息20KB左右,吞吐也很高。
首先是升盘将SSD PL1升级到PL2,进一步提高IOPS吞吐,然而依然存在问题。
模糊查询一条最近5小时内的日志,整个集群IPOS被打满,耗时超过30秒,无法投产。
进一步提高磁盘配置,将PL2升级为PL3,对应的配置也提高128C256G。
模糊查询一条最近5小时内的日志,大部分3~5内返回。
模糊查询一条最近1小时内的日志,大部分2内返回。
精确查找一条日志消息,大部分1秒左右返回。
备注:查询基本都在5秒内,没有特别明显的等待感,具备上线条件。
3、集群调优
除了集群规模、集群配置外,集群调优也很重要。
ClickHouse有几个参数需要调优,如下:
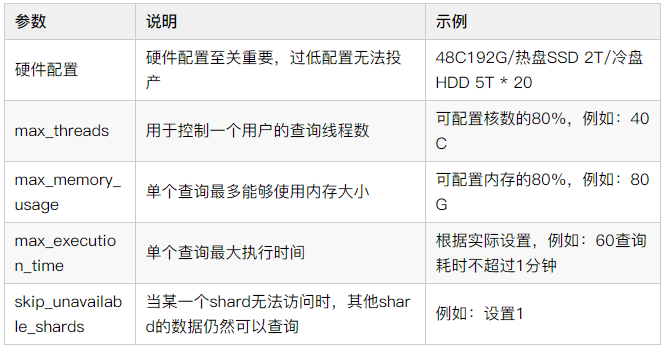
小结:根据不同业务场景划分多个集群,方便针对性调优治理,当然集群规模也不易过多,灵活权衡。
二、表结构设计要点
表结构的设计也至关重要,笔者团队在不断尝试时,表结构推了重来次数不下5次,不断调整提高查询性能。
1、重视字段索引创建
将公共约定的常用名称,独立成字段,方便添加索引,提升查询效率。
例如:链路ID设置为String类型,String类型的字段trace_id添加索引:
`tracing_id` String,INDEX tracing_id tracing_id TYPE SET(100) GRANULARITY 2,INDEX idx_tracing_id tracing_id TYPE tokenbf_v1(512, 2, 0) GRANULARITY 2
时间类型的字段record_time添加索引:
`record_time` DateTime64(3),INDEX record_time record_time Type minmax GRANULARITY 2
备注1:ClickHouse的MergeTree提供了4种类型的跳数索引(二级索引)。
备注2:4中类型跳数索引为:minmax、set、ngrambf_v1和tokenbf_v1。
备注3:充分为字段建立索引提高查询性能,只要能提高查询性能均可尝试。
备注4:笔者甚至为String类型的字段使用Set和tokenbf_v1两种类型的索引。
2、合理选择分区字段
选择什么样的分区字段是非常重要的,直接影响集群的整体性能。
笔者在此过程中也反复尝试了多种方式。
1)应用和天分区
是指每个应用每天一个分区,也方便各个应用的日志成本的核算和分摊。
通过测试存在以下问题:
几百个应用意味着一天有几百个分区。
Flink在写入时导致ClickHouse的整体IOPS居高不下。
严重时写入的IPOS占整体的30%以上,甚至50%。
备注:写入占用了过多的磁盘IOPS资源,严重影响查询性能,需要将更多的CPU/IO资源留个查询。
2)按天设置分区
是指一个集群的所有应用共用一个分区,每天创建一个。
通过测试有效降低磁盘IOPS。
为了能够根据分摊存储成本,将消息提大小、存储时长,提成独立字段解决。
分区字段示例:
PARTITION BY (toDate(log_time),log_save_time)
备注:按天分区能解决绝大多数业务日志,然而凡事总有例外。
3)按小时设置分区
按天分区在业务场景能满足需求,也降低了写入的IPOS。
然而在数据智能算法推荐场景,由于其日志量和消息大小均很大。
尽管将分区的迁移放在了凌晨2点之后,一个分区一个分区迁移。
当一个分区迁移时把整个集群的IPOS打满,而且是持续打满。
对半夜日志排查造成严重困扰,所以决定对该集群使用按小时创建分区。
PARTITION BY (toStartOfHour(log_time),log_save_time)
备注:根据业务实际场景,灵活定制设置分区键,针对性优化提高性能。
3、合并树引擎与排序字段
笔者在生产环境使用了MergeTree,而没有采用ReplacingMergeTree。
尽管日志可能重复数据,然而合并相同数据必然消耗集群性能。
一切都在取舍之中,一切让位与集群性能。
排序字段尽可能是查询的字段,充分利用主键索引。
ORDER BY (application, environment, log_time, ip, file_offset)
备注:选择合适的合并树引擎、利用好排序字段和主键索引。
4、选择合适的压缩算法
更强悍的压缩算法,往往需要牺牲一定的性能为代价。
CK的压缩算法LZ4和ZSTD也不例外。
经测试LZ4查询响应要比ZSTD快30%左右。
LZ4的磁盘占用空间要比ZSTD多2.5倍左右。
LZ4的压缩比约为1:4,ZSTD的压缩比约为1:10。
如果使用LZ4查询耗时为1秒,而ZSTD查询性能为1.5秒左右。
秒级的影响对使用方来说,体感并不明显,高达2.5倍的存储开销,确耗费不少。
ZSTD压缩示例:
`message` String CODEC(ZSTD),INDEX idx_message message TYPE tokenbf_v1(512, 2, 0) GRANULARITY 2,
备注:选择合适的压缩算法,笔者更倾向经济实用型,会选择ZSTD压缩算法。
三、其他设计点补充
下面是简化版本的demo创建表语句。
CREATE TABLE demo_log_local on cluster default(`app` String,`keyArr` Array(Nullable(String)),`valArr` Array(Nullable(String)),`msgBody` String CODEC(ZSTD),`record_time` DateTime64(3),`tracing_id` String,`storage_time` Int32,`msg_size` Int64,INDEX msg_size msg_size TYPE SET(100) GRANULARITY 2,INDEX app app TYPE SET(100) GRANULARITY 2,INDEX msgBody msgBody TYPE tokenbf_v1(32768, 2, 0) GRANULARITY 2,INDEX idx_msgBody msgBody TYPE tokenbf_v1(512, 2, 0) GRANULARITY 2,INDEX tracing_id idx_tracing_id TYPE SET(100) GRANULARITY 2,INDEX idx_tracing_id idx_tracing_id TYPE tokenbf_v1(512, 2, 0) GRANULARITY 2,INDEX record_time record_time Type minmax GRANULARITY 2)ENGINE = MergeTreePARTITION BY (toDate(record_time),storage_time)ORDER BY (application, record_time)SETTINGS allow_nullable_key = 1, storage_policy = 'ttl', index_granularity = 8192
在使用flink写入ClickHouse日志时,可以留有20%的余量,避免高峰期积压。
ClickHouse本身的运维、监控白屏化、告警配置、可视化查询控制台等。
小结:总之,从不同点触发去优化,让ClickHouse具备线上投产能力,把成本降下来的同时,不过度对使用造成影响。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721