
当我们想要批量进行副本扩缩的时候, 如果按照 --generate的重新计算分配方式来做的话, 那么这个数据迁移量是非常大的;有可能大部分的副本都有变动(牵一发而动全身)。那么我们有没有什么方式能够尽量减少这种变动呢?根据这个目标,我们本篇文章就好好思考一下设计方案。
想法1
我们指定,扩缩副本在kafka中是不直接支持的,但是我们可以通过kafka-reassign-partitions.sh工具来进行重新分配, 但是如果要给多个topic来进行扩缩副本操作的话,要自己去一个个的配置副本分配的位置,那么这是一个灾难;手动不仅容易出错,已非常容易让副本分配的不均衡。那么我们下面就来介绍如何去解决这个问题,动态地帮我们自动计算好扩容副本的分配方式;
首先,如何扩缩才是最完美的,既保证了均衡,又保证了变动最小,那就是:在原有的分配基础上, 扩缩副本这个变量,来达到我们上面的目的。
我们之前介绍过kafka分区副本的分配规则;那么在原有的分配基础上, 新增一个副本,是不是就变成下面这样了
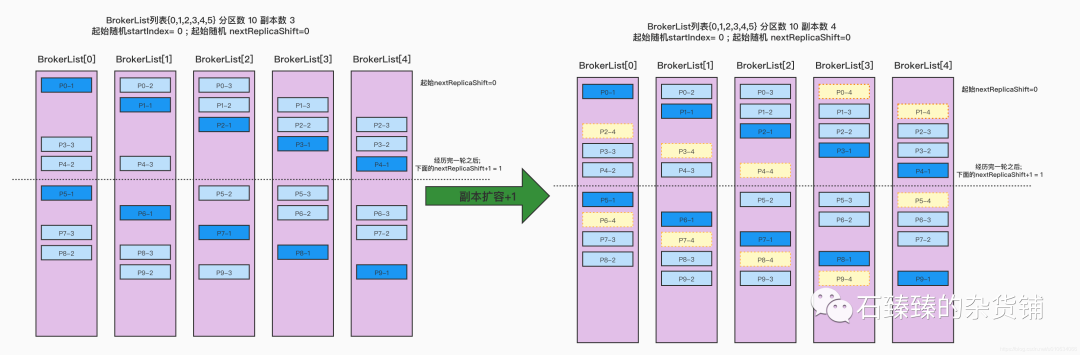
这样的变动是不是很小,只需要每个分区新增一个副本就行了,其他原有的副本不需要迁移; 然后写一个跟AdminUtils.assignReplicasToBrokersRackUnaware差不多的就接口来调用,就可以得到我们想要的分配情况了
影响分配情况的几个因素有:
BrokerList
分区数
副本数
起始随机数startIndex
起始随机nextReplicaShift
我们扩缩副本, 要变动副本数,其他的保持不变;然后根据现有的分区情况, 获取到其他几个数的。
1)如何获取这些数据
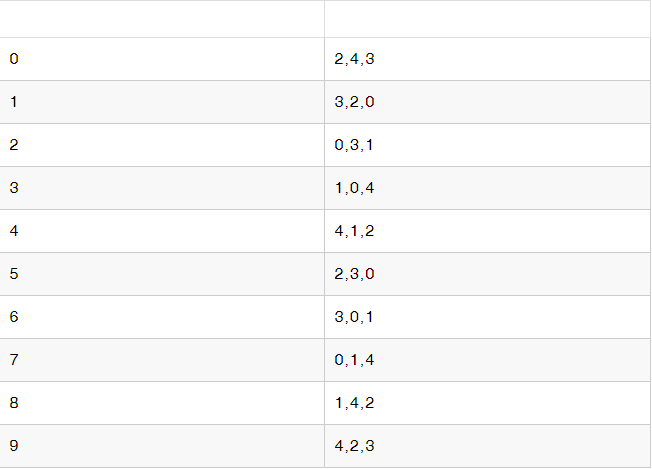
①从zk中获取topic副本分配信息,比如

{"version":2,"partitions":{"2":[0,3,1],"5":[2,3,0],"8":[1,4,2],"7":[0,1,4],"1":[3,2,0],"4":[4,1,2],"6":[3,0,1],"0":[2,4,3],"9":[4,2,3],"3":[1,0,4]},"adding_replicas":{},"removing_replicas":{}}
②我们指定一般情况下,分配都是从P0开始,我们把数据整理一下,如下:
分区号副本在Broker中分配情况
③BrokerList 是上面的集合{0,1,2,3,4} ;但是并不是说顺序就是这样的,只是表示有这个几个Broker参与了分配 我们把每个分区的第一个副本取出来{2,3,0,1,4,2,3,0,1,4};从里面获取连续5个(尾部跟头部也是相连)包含所有Broker就可以把它当成BrokerLIst顺序, 这里我们可以取 {2,3,0,1,4}也可以取{0,1,4,2,3} 都可以;这里我们最终选BrokerList={2,3,0,1,4}
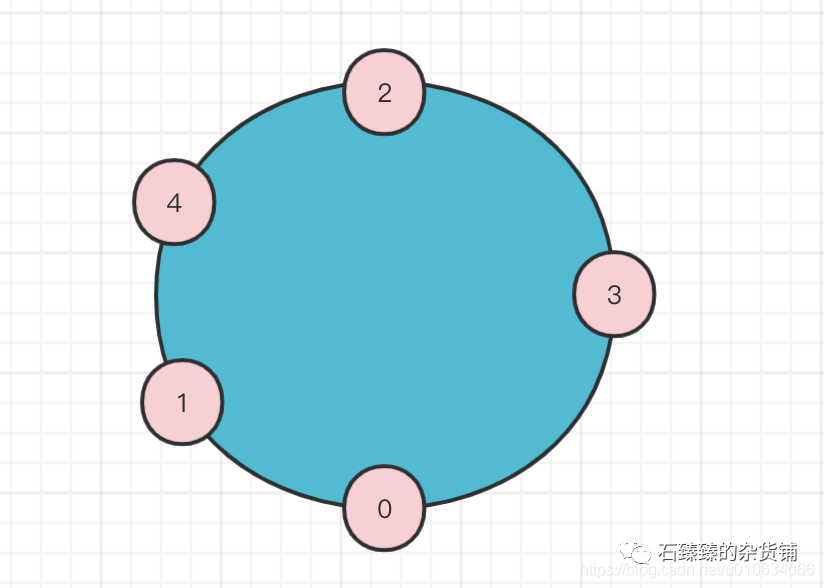
④分区数可以指定是10个;副本数是3个
⑤起始随机数startIndex 这个值的获取跟上面的BrokerList有关系;比如我们选择了BrokerList={2,3,0,1,4} ;先看看第一个分区的第一个副本是 2;再看2在BrokerList中的第几个位置;看到是第一个位置,那么索引值就=0;startIndex=0
⑥起始随机nextReplicaShift 就看看前面几个分区的第一个副本和第二个副本的差值;我们把上面的转换一下成索引位置
分区号brokerlist中索引值副本1和副本2的差值

到这里我们已经把所有变量算出来了
BrokerList={2,3,0,1,4}
分区数=10
副本数=3
起始随机数startIndex=0
起始随机nextReplicaShift=3
按照这些参数,重新调用接口AdminUtils.assignReplicasToBrokersRackUnaware 就肯定能够得到一模一样的分配数据 然后这个时候只调整副本数这个参数的话,就可以满足我们上面最小变动副本的要求了;当然: AdminUtils.assignReplicasToBrokersRackUnaware 并不能完全满足我们需求,因为nextReplicaShift=3不是参入传入的,是在里面随机产生的,所以我们自己按照这个方法写一个新方法微一下就行了;
如果副本的分配原本是自己手动指定的,并不是kafka自动计算的,则上面方法不可用;那么只能直接用kafka接口重新计算,完全重新分配了。


我们先回忆一下,如果进行过分区扩容,那么分区计算的并不是按照一个原则来进行分配的;请看 如果还按照kafka分区副本的分配规则方式来进行,那肯定达不到最小粒度的副本扩容了;因为后面进行过扩分区的分区肯定会进行数据移动;
把之前的例子搬过来再看看;例如我有个topic 2分区 3副本;分配情况
起始随机startIndex:0currentPartitionId:0;起始随机nextReplicaShift:2;brokerArray:ArrayBuffer(0, 1, 4, 2, 3)(p-0,ArrayBuffer(0, 2, 3))(p-1,ArrayBuffer(1, 3, 0))
我们来计算一下,第3个分区如果同样条件的话应该分配到哪里
①先确定一下分配当时的BrokerList 按照顺序的关系0->2->3 1->3->0 至少 我们可以画出下面的图
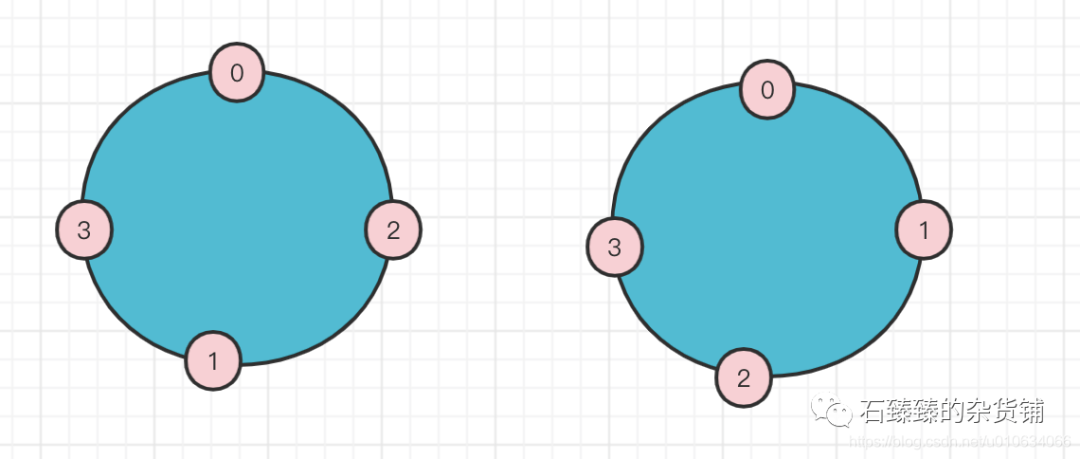
②又根据2->3(2下一个是3) 3->0(3下一个是0)这样的关系可以知道
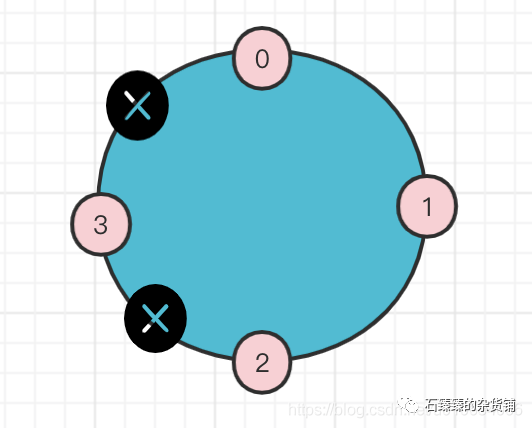
③又要满足 0->2 和 1->3的跨度要满足一致(当然说的是在同一个遍历范围内currentPartitionId / brokerArray.length 相等)
④又要满足0->1是连续的那么Broker4只能放在1-2之间了;(正常分配的时候,每个分区的第一个副本都是按照brokerList顺序下去的,比如P1(0,2,3),P2(1,3,0), 那么0->1之间肯定是连续的;)
结果算出来是BrokerList={0,1,4,2,3} 跟我们打印出来的相符合;那么同样可以计算出来, startIndex=0;(P1的第一个副本id在BrokerList中的索引位置,刚好是索引0,起始随机 nextReplicaShift = 2(P1 0->2 中间隔了1->4>2 ))
指定这些我们就可以算出来新增一个分区P3的位置了吧? P3(4,0,1)
然后执行新增一个分区脚本之后,并不是按照上面分配之后的 {4,0,1} ;而是如下
起始随机startIndex:0 currentPartitionId:2;起始随机nextReplicaShift:0;brokerArray:ArrayBuffer(0, 1, 2, 3, 4)(p-2,ArrayBuffer(2, 3, 4))
如果我又进行扩分区操作的话,还是一样的逻辑;假如我这再次新增一个分区
BrokerList={0,1,2,3,4} 扩分区的BrokerList都是经过排序的;currentPartitionId=3 起始随机nextReplicaShift=startIndex=第一个分区第一个副本BrokerId在BrokerList中的索引值=0那么P3是{3,4,0} 来,执行一下看看结果
起始随机startIndex:0currentPartitionId:3;起始随机nextReplicaShift:0;brokerArray:ArrayBuffer(0, 1, 2, 3, 4)(p-3,ArrayBuffer(3, 4, 0))
那么这种情况下怎么进行分配?如果还是想要实现我们的目标,最小成本的去扩缩副本,那么我们就需要找到是从哪个分区开始进行了 扩分区的操作 假如现在的分区
0,2,31,3,02,3,43,4,0
先去验证是否有冲突的地方;比如上面3>4(3下一个是4) 3>0(3下一个是0) 就冲突了;就可以直接去掉后面两个,再验证
0,2,31,3,0
是否冲突
然后根据不同情况来进行重新分配;同时又有其他问题 比如 存在手动分配过的分区 这种不是按照固定的规则来分配的,也不能按照上面的处理, 这种就需要重新完全分配了
所以总结起来,这种思路可行, 但没有必要;我也是写到了这里,才觉得没有必要。
想法2
相比第一种想法, 需要考虑过多的情况,这个想法就简单霸道多了
直接再每一个分区的最后一个副本上顺推就行了(如果是缩副本就减小) 比如5个Broker 4分区 3副本, 前面两个是创建的时候分配的,后面两个是分区扩容分配的
"0":[0,1,4]"1":[1,4,2]"2":[4,2,3]再扩容3个分区"3":[3,4,0]"4":[4,0,1]"5":[0,2,3]
副本扩容就直接假定BrokerList[0,1,2,3,4], 然后将最后一个副本往后顺推一个可用Broker;
"0":[0,1,4] ==》 [0,1,4,2]"1":[1,4,2] ==》 [1,4,2,3]"2":[4,2,3] ==》 [4,2,3,1]再扩容3个分区"3":[3,4,0] ==》 [3,4,0,1]"4":[4,0,1] ==》 [4,0,1,2]"5":[0,2,3] ==》 [0,2,3,4]
如果都只有一个副本,那么按照分区号简单做一个排序(一般情况是按照分区号大小顺序排的), 然后得到一个BrokerList;接着按照之前的算法重新计算就行,为啥不直接顺推断出第二个位置,因为原来第一和第二副本之间会根据遍历的次数nextReplicaShift+1
副本缩小直接从最后删除,多出来的副本
"0":[0,1,4] ==》 [0,1]"1":[1,4,2] ==》 [1,4]"2":[4,2,3] ==》 [4,2]再扩容3个分区"3":[3,4,0] ==》 [3,4]"4":[4,0,1] ==》 [4,0]"5":[0,2,3] ==》 [0,2]
这里还可以再优化一点的地方就是,保不齐运维同学手动分配状态为下面这种最后一个副本都在同一个Broker上的沙雕情况。
"0":[0,1,4] ==》 [0,1]"1":[1,2,4] ==》 [1,2]"2":[3,2,4] ==》 [3,2]
如果直接删除最后一个,那么Broker4中一下子删除了3个副本;爽歪歪,这样好像副本的分配就有那么一点点不均衡了;所以为了避免这种情况,我们做一个判断 遍历移除AR最后一个元素的时候,如果之前移除过,则过滤掉往前面推一位;(最终目的就是让副本移除尽量均衡一些)
优点这种粗暴的方式比较简单,也还合理,也不用考虑Topic之前是否有进行过分区扩容,或者有过自定义分区副本的分配;就一个字简单, 而且扩缩容改动也是最小的,只新增要新增的副本;对原来的副本不改动;如果开发运维同学自己有对分区自定义分配, 这种方式也不会去改动这一块;
缺点增加副本之后,新的分配方式有可能就不再满足 kafka默认的分配方式的排列了 相当于是自定义了分配方式;副本扩容是简单了,但是如果以后进行分区重分配的话, 分区迁移的动作会比较大;迁移的数据量也比较多;负载均衡性来说,可能稍微比上面想法1差一丢丢(存疑);
最终解决方案
想法1处理起来比较麻烦,考虑的点比较多, 而且如果有自定义的分区分配方式还可能会覆盖掉;想法2简单,不会覆盖用户自定义的分区分配方式,数据fetch量也不会太大。
所以最终使用想法2, 但是根据某些条件来使用想法1。
副本=1的情况,处理起来比较简单,我们可以按照想法1来处理;可以直接使用默认的方式计算一遍;其实主要还是要第一个副本与第二个副本之间的间隔是一个随机值 nextReplicaShift 随机。
下面讲解一下示例
1)现有分配是系统默认的分配方式
例如::下面是从现有zk中获取的副本分配情况;再做扩容副本的时候,传入的Broker列表的集合有{0,1,2,3,4,5};我想副本扩容到3个
"0":[2]"1":[4]"2":[0]
根据上面从zk中得到的的分配规则, 可知道当时分配时候至少有{2,4,0}这个顺序;那我们可以构造BrokerList={2,4,0,1,3,5}(随便什么顺序,只要满足2,4,0这个顺序就行,这样至少分区0,1,2的第一个副本不需要变动) 然后扩容到3个副本, 我们将构造
BrokerList={2,4,0,1,3,5}
分区数=3
副本数=3
起始随机数startIndex=0
起始随机nextReplicaShift=随机值 (这里要是随机值,很重要)
假如nextReplicaShift随机值是0根据这些参数计算出来的结果
"0":[2,4,0]"1":[4,0,1]"2":[0,1,3]
2)现有分配不是系统默认的分配方式
出现这种情况可能是进行过分区扩容、手动设置分区、等等,并不能完全找到匹配的BrokerList ,例如:
"0":[2]"1":[3]"2":[0]"3":[3]"4":[4]
像这种情况, 2->3->0 是满足条件的,但是下一个又到了3明显不满足条件;所以这种情况,我们只能尽可能满足最前面的分配了"3":[3] 不满足条件,我们就不考虑它及其后面的分配是否尽量少了(就是让他们重新按照之前的逻辑分配了) 从上面分配情况可以知道BrokerList的集合有{0,2,3,4} ;假设传入的Broker列表的集合有{0,1,2,3,4,5} 按照下面满足的条件构造BrokerList
"0":[2]"1":[3]"2":[0]
先构造一个满足条件的BrokerList={2,3,0,1,4,5} 然后扩容到3个副本, 我们将构造
BrokerList={2,3,0,1,4,5}
分区数=4
副本数=3
起始随机数startIndex=0
起始随机nextReplicaShift=随机值 (这里要是随机值,很重要)
假如nextReplicaShift随机值是0 根据这些参数计算出来的结果。
"0":[2,3]"1":[3,0]"2":[0,1]"3":[1,4]"4":[4,5]
如果判断到分配不均衡,则将会把不满足条件的部分重新分配分区副本。
使用想法2, 直接在最后一个副本的地方直接顺推至下一个可用Broker。
实现
直接使用LogIKM进行可视化操作, 暂未实现,敬请关注!







如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721