
汪文强,转转数据智能部高级数据研发工程师,负责公司实时、离线B2C业务数仓建设。
一、OLAP技术介绍及选型
1.1 OLAP基本操作
1.2 OLAP分类
1.3 主流OLAP特性及适用场景分析
二、应用场景及整体方案
三、OLAP的使用优化实践
3.1 druid的优化
3.2 clickhouse的优化
四、总结
一、OLAP技术介绍及选型
OLAP,On-Line Analytical Processing,在线分析处理,主要用于支持企业决策管理分析。区别于OLTP,On-Line Transaction Processing,联机事务处理。
OLTP 主要用来记录具体某类业务事件的发生,如交易行为,当行为产生后,数据库会记录这个事件是谁在什么时候什么地方做了什么事,这样的一行(或多行)数据会以(增删改)的方式在数据库中进行数据的更新处理操作,要求实时性高、稳定性强、确保数据及时更新成功,常见的业务系统如商场系统,ERP,客服系统,OA等系统都是基于OLTP开发的系统。
当业务发展到一定程度,积累了一些数据的时候,对过去发生的事情做一个总结分析的需求就会产生,这类需求往往需要把过去一段时间内产生的数据拿出来进行统计分析,从中获取我们想要的信息,为公司做决策提供支持,我们管这类场景就叫做OLAP。OLAP的优势:丰富的数据展现方式、高效的数据查询以及多视角多层次的数据分析。
我们常说OLTP是数据库的应用,OLAP是数据仓库的应用,两者主要的区别如下图:

1.1 OLAP基本操作
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot)。
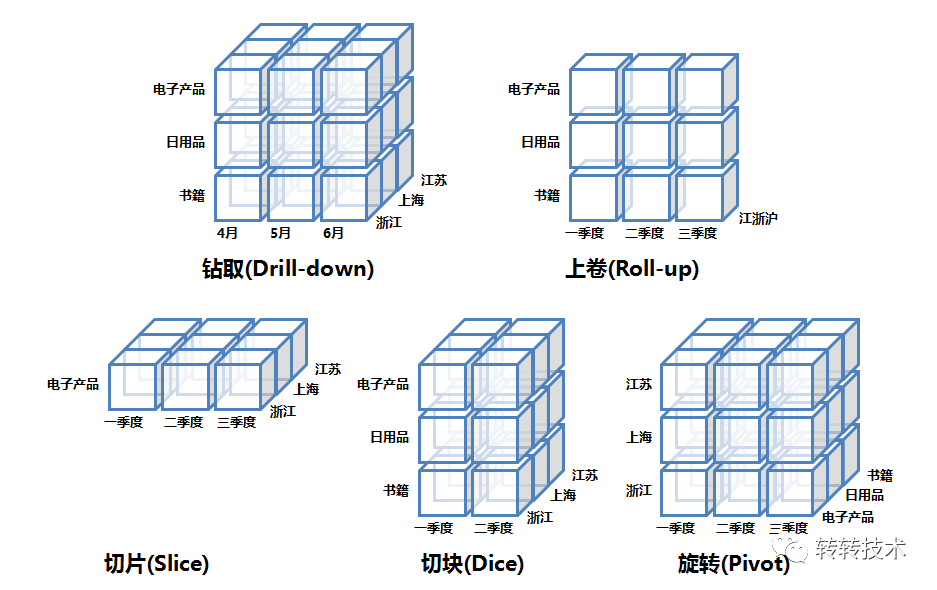
钻取:维的层次变化,从粗粒度到细粒度,汇总数据下钻到明细数据。eg:通过季度销售数据钻取每个月的销售数据
上卷:钻取的逆,向上钻取。从细粒度到粗粒度,细粒度数据到不同维层级的汇总。eg:通过每个月的销售数据汇总季度、年销售数据
切片:特定维数据(剩余维两个)。eg:只选电子产品销售数据
切块:维区间数据(剩余维三个)。eg:第一季度到第二季度销售数据
旋转:维位置互换(数据行列互换)。eg:通过旋转可以得到不同视角的数据
1.2 OLAP分类
OLAP按存储器的数据存储格式分为ROLAP(Relational OLAP)、MOLAP(Multi-dimensional OLAP)和 HOLAP(Hybrid OLAP)。
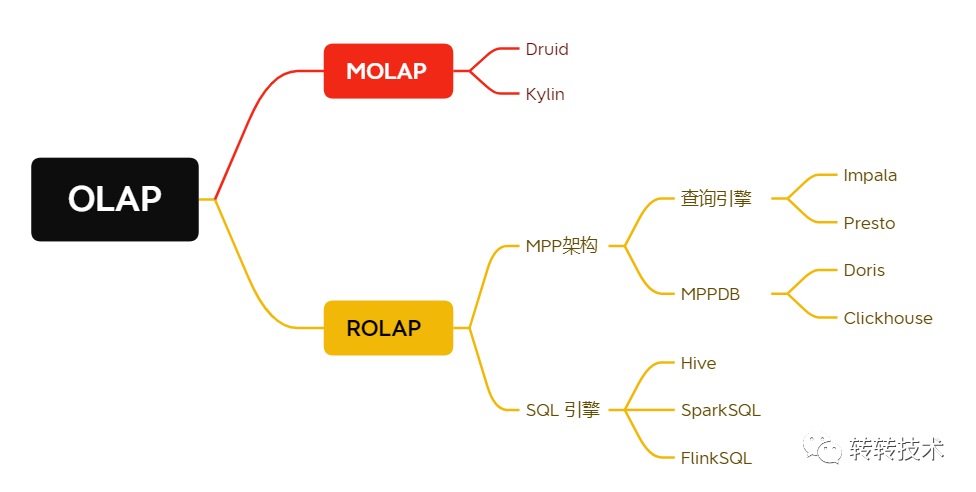
MOLAP,基于多维数组的存储模型,也是OLAP最初的形态,特点是对数据进行预计算,以空间换效率,明细和聚合数据都保存在cube中。但生成cube需要大量时间和空间。MOLAP的优势在于由于经过了数据多维预处理,分析中数据运算效率高,主要的缺陷在于数据更新有一定延滞。
ROLAP,完全基于关系模型进行存储数据,不需要预计算,按需即时查询。明细和汇总数据都保存在关系型数据库事实表中。ROLAP的最大好处是可以实时地从源数据中获得最新数据更新,以保持数据实时性,缺陷在于运算效率比较低,用户等待响应时间比较长。
HOLAP,混合模型,细节数据以ROLAP存放,聚合数据以MOLAP存放。这种方式相对灵活,且更加高效。
1.3 主流OLAP特性及适用场景分析
Druid
Druid是采用预计算的方式。主要解决的是对于大量的基于时序的数据进行聚合查询。Druid提供了实时流数据分析,以及高效实时写入,进入到Druid后立即可查,同时数据是几乎是不可变。通常是基于时序的事实事件,事实发生后进入Druid,外部系统就可以对该事实进行查询。
优点:查询延迟低,并发能力好,多租户设计较完善。
适用场景:QPS高的预聚合查询,不适用于明细查询,典型适用场景:用户行为分析,网络流量分析。
Kylin
kylin是一个MOLAP系统,多维立方体(MOLAP Cube)的设计使得用户能够在Kylin里为百亿以上数据集定义数据模型并构建立方体进行数据的预聚合。支持大数据生态圈的数据分析业务,主要是通过预计算的方式将用户设定的多维度数据立方体(cube) 缓存起来,达到快速查询的目的。应用场景应该是针对复杂sql join后的数据缓存。
优点:主要是对hive中的数据进行预计算,用户只需提前定义好查询维度,Kylin将会帮助我们进行计算,并将结果存储到HBase中,为海量数据的查询和分析提供亚秒级返回。
适用场景:适合数据量大,查询维度多,但是业务改动不频繁的场景。
Doris
Doris是MPP架构的查询引擎,整体架构非常简单,只有FE、BE两个服务,FE负责SQL解析、规划以及元数据存储,BE负责SQL-Plan的执行以及数据的存储,整体运行不依赖任何第三方系统,功能也非常丰富如支持丰富的数据更新模型、MySQL协议、智能路由等。不仅能够在亚秒级响应时间即可获得查询结果,有效的支持实时数据分析,而且支持PB级别的超大数据集,对于业务线部署运维到使用都非常友好。
优点:支持标准的SQL语法,同时支持明细和聚合的高并发查询,支持多表join和在线schema变更。
适用场景:适用于高并发的明细和多表关联聚合查询。典型场景:高并发分析报表、即席查询、实时播报大屏。
Clickhouse
ClickHouse从OLAP场景需求出发,定制开发了一套全新的高效列式存储引擎,并且实现了数据有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等丰富功能。以上功能共同为ClickHouse极速的分析性能奠定了基础。但是Clickhouse也有它的局限性,在OLAP技术选型的时候,应该避免把它作为多表关联查询(JOIN)的引擎,也应该避免把它用在期望支撑高并发数据查询的场景,Clickhouse的执行模型决定了它会尽全力来执行一个Query,而不是同时执行很多Query。所以它更适合对时效性要求高,QPS低于1000的类似企业内部BI报表等应用,而不适合如数十万的广告主报表或者数百万的淘宝店主相关报表应用。
优点:向量化SQL查询引擎,单表查询性能强悍、可以基于明细数据灵活聚合查询。
适用场景:QPS中等的明细查询及聚合查询,不适用于qps很高的场景,也不适用于多表join的场景,典型适用场景:交易数据分析,商业数据分析。
二、应用场景及整体方案
首先是日常交易、售后业务等业务板块的数据自助分析。运营业务侧需要实时统计订单销量、商品库存相关指标,估算订单的单量、增速是否达到策略的预期效果,库存异常波动原因、库存及时调动补充等。售后客服侧则需要根据实时指标去评估日常工作,更好的开展管理工作。
另外一个场景是大促活动期间的实时看板展示,在大型活动促销期间需要整个供应链和销售的实时数据,从用户流量到用户转化到订单、商品、库存等漏斗分析,让运营侧可以按照当前的数据及时调整活动策略,提升转化率。对大促活动期间的指标分析,也是一个很典型的多维分析的过程,OLAP平台要满足每天几万次的查询调用需求,查询的时延要保证在百毫秒级。
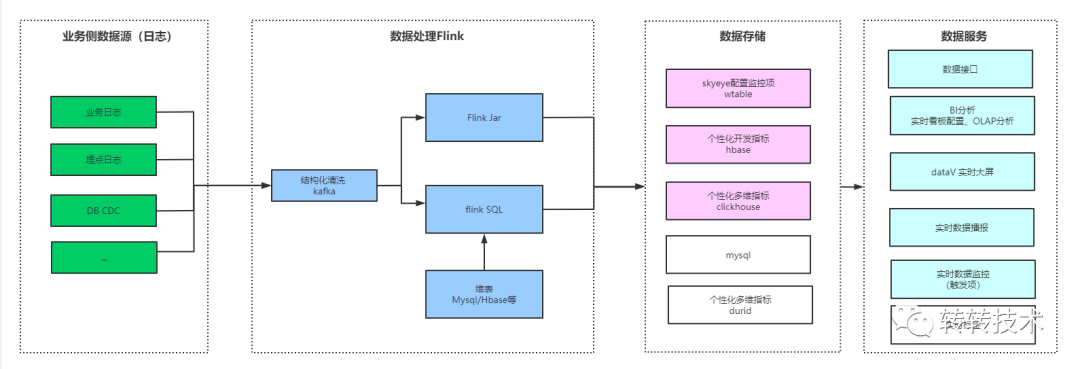
OLAP平台选型时对公司多个业务团队的需求做了调研,总结来讲,大家对以下几个点关注度会比较高,比如超大数据规模的支持,单个数据源可能每天有上十亿的数据量需要录入;查询时延,要保证在毫秒到秒级;数据实时性,很多业务线明确提出实时数据分析的需求;另外还有高并发查询、平台稳定性等。
根据对用户的调研,以及对比了各种OLAP在不同场景下的应用,我们得出了如下的OLAP分析架构图:
三、OLAP的使用优化实践
物化视图
什么是物化视图,假设一个数据源的原始维度有十个列,通过分析查询请求发现,group1中的三个维度和group2中的三个维度分别经常同时出现,剩余的四个维度可能查询频率很低。更加严重的是,没有被查询的维度列里面有一个是高基维,就是 count district 值很大的维度,比如说像 User id 这种。这种情况下会存在很大的查询性能问题,因为高基维度会影响 Druid 的数据预聚合效果,聚合效果差就会导致索引文件 Size 变大,进而导致查询时的读 IO 变大,整体查询性能变差。针对这种 case 的优化,我们会将 group1 和 group2 这种维度分别建一个预聚合索引,然后当收到新的查询请求,系统会先分析请求里要查询维度集合,如果要查询的维度集合是刚才新建的专用的索引维度集合的一个子集,则直接访问刚才新建的索引就可以,不需要去访问原始的聚合索引,查询的性能会有一个比较明显的改善,这就是物化视图的一个设计思路,也是一个典型的用空间换时间的方案。
缓存查询
为了提升整体查询速度,我们引入了 Redis 作为缓存,如果只是简单的按照每次查询 sql 结果进行缓存的话则存在一个问题,每次不同用户查询的时间周期不一致,导致命中缓存的比例较低,查询性能提升不是很明显。为了提高缓存复用率,我们需要增加一套新的缓存机制:我们按照拆解表的最细时间粒度,按照天和小时进行数据的缓存。当用户进行查询的如果只是部分时间跨度的结果命中 redis ,则只查询未命中的时间跨度,然后将查询的结果和 redis 中的缓存数据拼接返回给用户,进而提升查询效率。
冷热数据分层
通过配置每个节点的数据分配策略,让高频查询的数据尽量多的分散在不同的broker,减少单个节点的查询压力,调整 History Node配置参数。
#集群分片,不写默认_default_tierdruid.server.tier=hot#查询优先级,不写默认0,_default_tier分片的两个节点为0,hot节点的都改为100。这样,热数据只会查hot节点的机器。druid.server.priority=100#processing.buff,默认是1Gprocessing.buff = 4G#processing.numThreads:默认是繁忙时core-1做process,剩余的1个进程做与zk通信和拉取seg等。druid.processing.buffer.sizeBytes=1073741824druid.processing.numThreads=30
3.2 clickhouse的优化
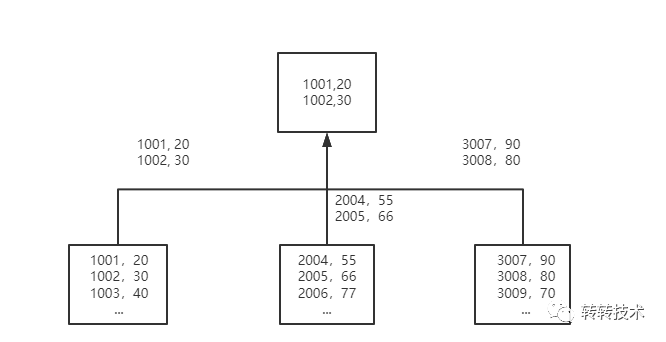
(1)distributed 分布式聚合查询
在 ClickHouse 的聚合查询中,每个机器都会把自己的聚合的中间状态返回给分布式节点,也就是说,即使你只是想要Top100,每台机器也会把自己所拥有的所有枚举值都返回给分布式节点进行进一步的聚合。ClickHouse 的聚合过程大致如下图:
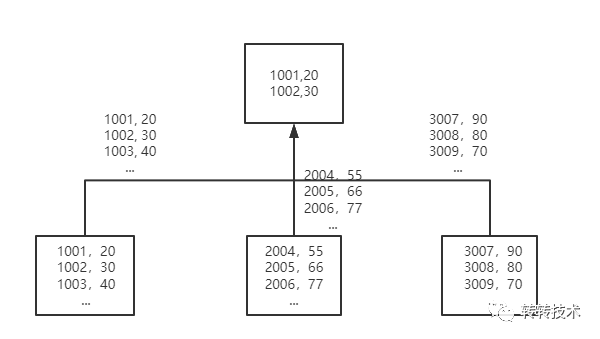
开启分布式查询优化后的执行图,如图所示,可以提前进行数据过滤,提升查询效率:
(2)跳数索引
clickhouse 数据库为列式数据库,其本身并没传统关系型数据库中所指的二级索引,clickhouse 提供了一种适用于列存检索的跳数索引算法来替代二级索引。
跳数索引类型
minmax
这种轻量级索引类型不需要参数。它存储每个块的索引表达式的最小值和最大值(如果表达式是一个元组,它分别存储元组元素的每个成员的值)。对于倾向于按值松散排序的列,这种类型非常理想。在查询处理期间,这种索引类型的开销通常是最小的。
set
这种轻量级索引类型接受单个参数max_size,即每个块的值集 (0允许无限数量的离散值) 。这个集合包含块中的所有值 (如果值的数量超过max_size则为空) 。这种索引类型适用于每组颗粒中基数较低 (本质上是“聚集在一起”) 但总体基数较高的列。
Bloom Filter Types
Bloom filter是一种数据结构,它允许对集合成员进行高效的是否存在测试,但代价是有轻微的误报。在跳数索引的使用场景,假阳性不是一个大问题,因为惟一的问题只是读取一些不必要的块。潜在的假阳性意味着索引表达式应该为真,否则有效的数据可能会被跳过。
在生产中只对枚举值比较多的字段诸如订单id,商品id用 bloom_filter 跳数索引,其他索引没有使用,因为 bloom_filter 的索引文件不至于太大,同时对于值比较多的列又能起到比较好的过滤效果。
(3)避免使用final
ClickHouse 中我们可以使用 ReplacintMergeTree 来对数据进行去重,这个引擎可以在数据主键相同时根据指定的字段保留一条数据,ReplacingMergeTree 只是在一定程度上解决了数据重复问题,由于自动分区合并机制在后台定时执行,所以并不能完全保障数据不重复。我们需要在查询时在最后执行 final 关键字,final 执行会导致后台数据合并,查询时如果有 final 效率将会极低,我们应当避免使用 final 查询,那么不使用 final 我们可以通过自己写SQL方式查询出想要的数据,举例如下:
create table t_replacing_table(id UInt8,name String,age UInt8) engine = ReplacingMergeTree(age)order by id;insert into t_replacing_table values (1,'张三',18),(2,'李四',19),(3,'王五',20);insert into t_replacing_table values (1,'张三',20),(2,'李四',15);#自己写SQL方式实现查询去重后的数据,这样避免使用final查询,效率提高SELECTid,argMax(name, age) AS namex,max(age) AS agexFROM t_replacing_tableGROUP BY id
四、总结
本文主要介绍了转转OLAP分析架构的选型和实践,通过引入 Druid 和 Clickhouse ,解决了公司当前场景下的多维分析需求。但目前 OLAP 能够支持的场景还是比较受限,对于高并发的自助分析场景和多表的关联分析等方面的支持还不友好,后续希望能做一个能够支持明细、聚合分析,还有关联场景的 OLAP 平台,进一步提升公司的实时 OLAP 分析能力。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721