
一、大数据架构演进
1、经典离线数仓架构介绍
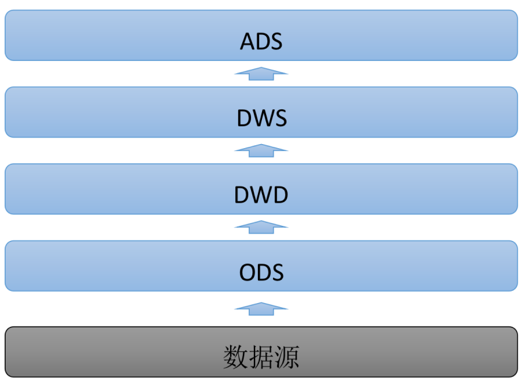
经典的离线数据仓库主要分为4层:
操作数据层(Operational Data Store),存储基础数据,做简单数据清洗。
明细数据层(Data Warehouse Detail),构建最细粒度的明细层事实表。
汇总数据层(Data Warehouse Summary),按照主题,对明细数据进行汇总。
应用数据层(Application Data Store),存放业务个性化统计指标,面向最终展示。
经典的离线数仓的优缺点十分清晰,优点是架构简单,开发成本低,资源成本低,数据易管理,数据差别小;缺点是数据时效性差、缺少实时数据。
2、Lambda架构介绍
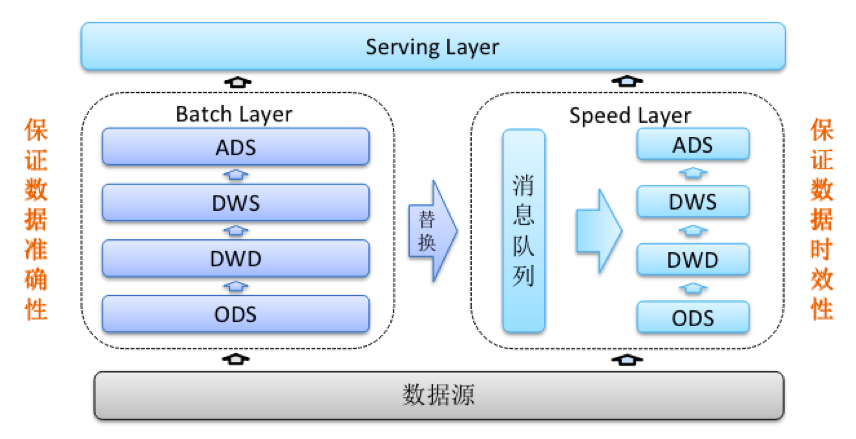
lambda架构是由Storm作者Nathan Marz于2011年提出的实时数仓架构,初衷也是弥补经典数仓架构时效性差的问题。整个架构会分三层:
Batch Layer
批处理层,这一层其实基本是复用了经典数仓分层架构,数据也是基于ods 、dwd、dws、ads的结构进行组织,也就保留了经典数仓数据准确、全面的特点。使用技术栈也是跟经典数仓一致,主要以mr、hive、spark等离线计算框架为主。
Speed Layer
加速处理层,这一层的重点在于产出高时效性的数据,对于数据的准确性和完整性可能会有一些降级,一般会采用kafka等消息中间件进行数据传输和存储,采用一些像Storm、Spark streaming 、Flink 等流式计算框架进行数据计算。
Serving Layer
服务层,这一层会将speed layer和batch layer层的数据进行合并和替换,输出到一些数据库或者olap引擎中,支撑上层的数据应用。
相比于经典数仓,Lambda架构由于引入了speed layer,能够把数据的时效性大大提前,由于同时具有speed layer和batch layer,使得Lambda架构能够同时兼顾数据准确性和数据的时效性,另外batch layer基本兼容了经典数据架构,所以在从经典数仓架构迁移Lambda架构的时候,可以省去一部分沉重的历史包袱,至于缺点嘛,也是因为Lambda架构同时具有speed layer和batch layer,那就会导致这么几个问题:
一个需求会有两套代码,同时开发两遍,也就会造成开发成本的浪费。
资源需要两份,一份离线的资源,一份流式的资源,整体资源占用比较多。
数据差异问题,离线和实时的数据总是有差异,对不齐,体验比较差。
3、Kappa架构介绍
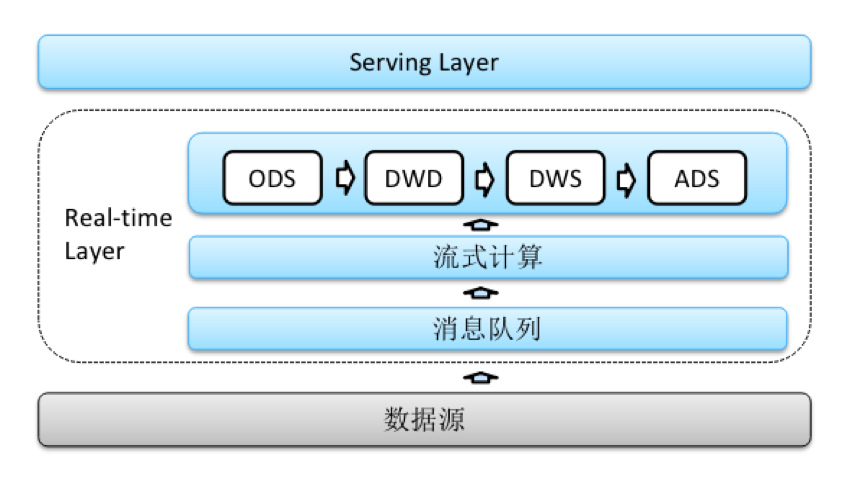
随着流式计算框架的不断发展,尤其是针对不重不丢语义的支持越来越好,Confluent公司CEO Jay Kreps于2014年提出了kappa架构。Kappa架构的核心思想是去掉Lambda架构的batch layer,实时计算和离线计算使用同一套代码。通过一套架构来同时满足业务对于准确性、全面性、时效性的要求。
首先,kappa架构肯定是解决了Lambda架构的几个缺点,因为实时离线使用一套代码,整个开发成本大大的降低,资源的成本也有了一定的节省,同时最关键的是实时和离线的统计做到了统一,消除了各类在离线数据diff问题。那当然,kappa架构也不是完美的,它也有一些缺点:
数据回溯的问题,业务口径的变更会带来数据回溯,kappa架构没有离线数据流,回溯的成本是很高的。
随着业务的复杂度增加,数据源的复杂度也增加,流式计算环节会面临各种复杂关联场景的挑战,开发和维护的成本非常高。
一些新业务,数仓可以从0开始建,Lambda架构的落地成本还是可以接受的。但是大多数情况下,我们的数仓建设都有沉重的历史包袱,好多存量逻辑面临实时化的改造,而这些改造往往是成本高,收益小。
二、背景
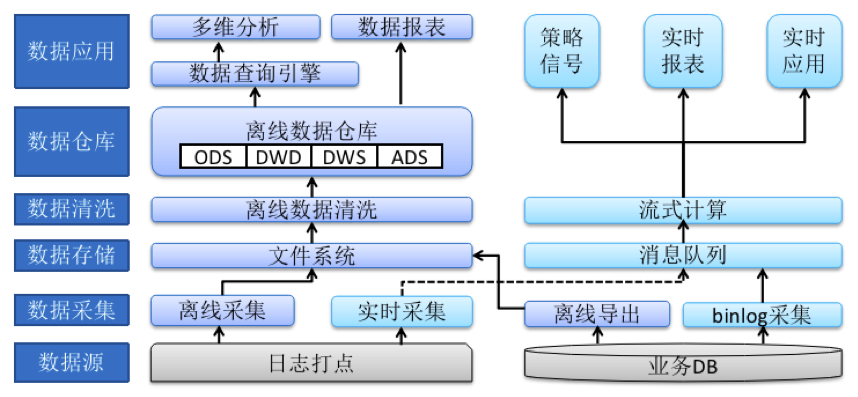
首先介绍一下旧的架构,根据前面讲的大数据架构演进,可以看出来旧的架构是一个Lambda架构。旧的架构也是基于经典数仓架构演变而来,新增了实时流部分,满足业务的高时效性诉求。深蓝的部分是离线流,浅蓝部分是实时流:
1)离线流
最底层是数据源,主要有两类,一类来源于日志打点,比如一些展现日志、点击日志,一类来源于业务的数据库,比如一些订单数据、物料数据。日志打点的数据经过日志采集工具小时或天级采集到文件系统上,业务数据库的数据经过dump工具天级别采集到文件系统上,再经过离线的数据清洗,构建数据仓库。数据仓库也是经典的分层数仓,数仓上层主要是承接多维分析和报表需求。
2)实时流
日志打点这块通过实时的数据采集,将有时效性要求的数据写入到消息队列,业务数据库的数据也通过采集binlog等变更流信息,将有时效性要求的数据写入到消息队列,消息队列之后就是流式计算环节,这个环节会按照需求,分别进行数据加工,满足策略信号、实时报表、实时应用的诉求。
旧架构在实际的使用过程中,也遇到了一系列的问题:
由于业务比较复杂,采用分层建模,数据表量级在千张级别,表关联场景多,一次查询可能需要关联几十张表,查询时效慢,平均时效在几十分钟级别。
数据延迟严重,大部分数据都是天级产出,个别小时级的数据产出也要延迟几个小时。
实时和离线数据存在差异,不能对齐,每次需要开发两套代码,维护成本高。
三、技术方案
1、整体架构
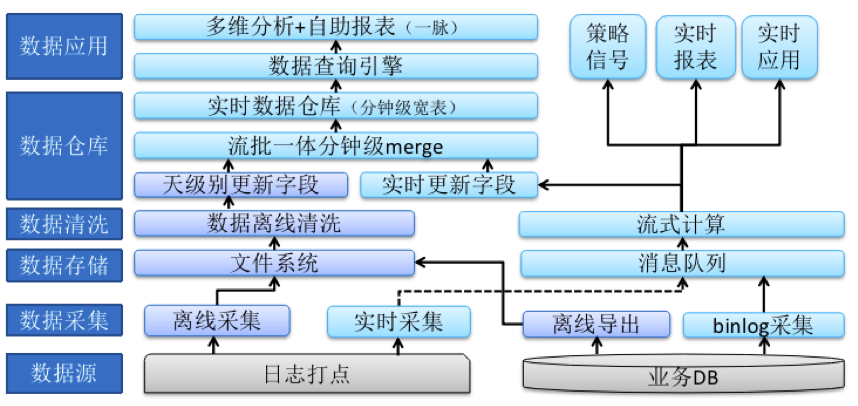
我们的流批一体实时数仓整体架构,整体上是一种Lambda和kappa的混合架构:
最关键的变化其实是数据清洗和数据仓库环节,每个字段会根据使用场景的时效性要求,来确定数据流是走实时还是离线。一个字段要么走实时,要么走离线,实时和离线不再是补充关系而是替换关系。这样也就避免了Lambda架构典型问题,实时离线两套代码、在离线数据不一致。同时没有时效性诉求的字段还是继续保留离线的处理逻辑,没必要强行切换到实时,增加资源成本和开发维护成本。
整个数据仓库也由之前的分层建模变成了宽表建模,实时字段和离线字段通过分钟级的merge合并成一张宽表。整体的建模思路也不再面向数据源建模,而是面向使用建模,保证业务方在使用的时候表尽量少,减少表的关联,降低查询耗时。
2、关键问题突破
1)数据更新问题
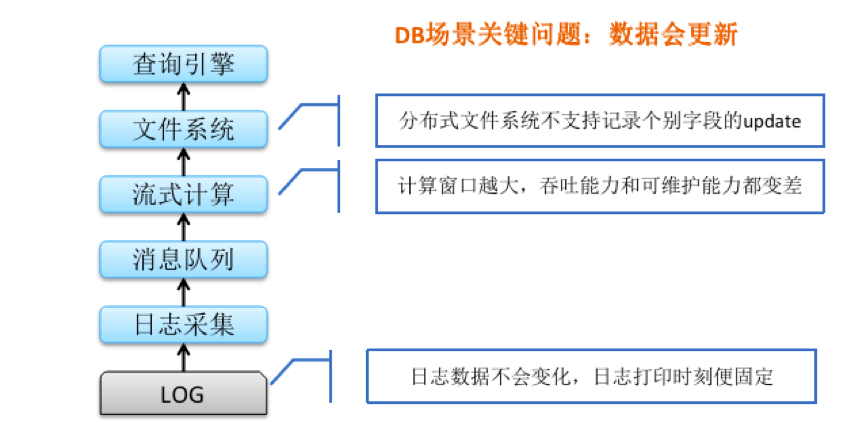
针对实时数仓,其实比较简单的是纯日志场景,一个典型的日志场景的实时数仓方案大概是这样的,原始的日志经过实时采集写入到消息队列中,再在流式计算环节,通过固定的时间窗口写入到文件中就好了,日志数据其实是不会变化的,日志打印那一刻数据就固定了,但是数据库数据是不一样的,他是会更新的,像比如说订单的状态,物料的属性,都可能会发生变化,但是分布式的文件系统往往是不支持更新的,那随着计算窗口的变大,吞吐能力和可维护性都变差。
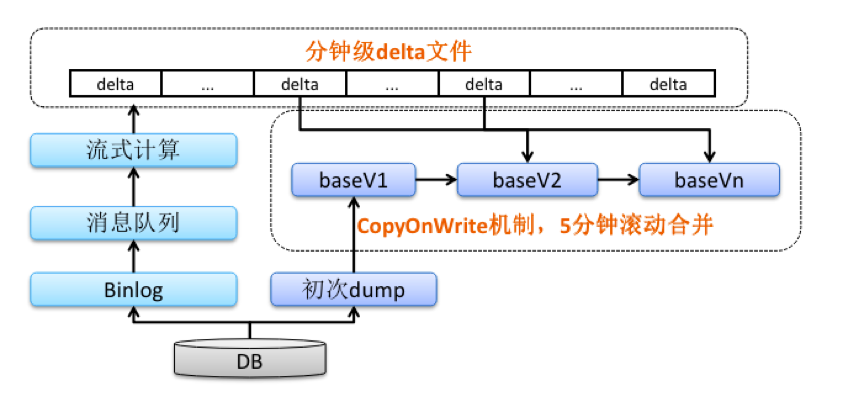
我们的解决方案大概是这样的,对于数据库数据,我们首先采集变更信息binlog,写入到消息队列中,然后采用CopyOnWrite机制,通过滚动5分钟合并过程,将base文件和delta文件进行合并,不断产生最新的可用版本。没有采用MergeOnRead方案,关键原因还是满足业务的诉求,业务对查询的时效性特别敏感,必须是秒级别,而对数据导入的时效性没有特别敏感,分钟级是可以满足需求的。
2)多表关联问题
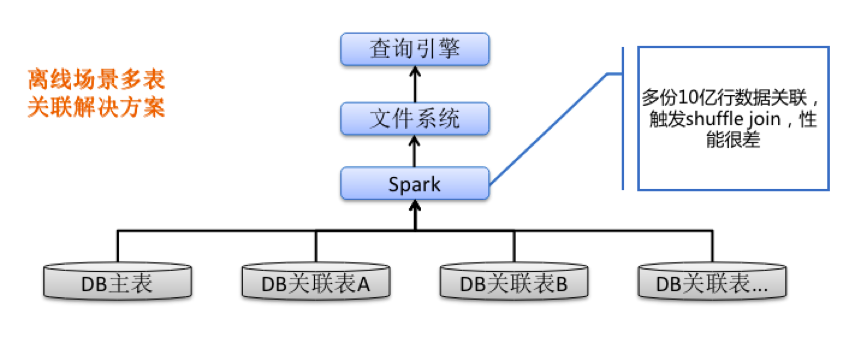
离线场景典型的数据关联方案大概是这样的,有一张db主表,几张关联表,通过spark或者其他的离线计算框架关联到一起,再写入到文件系统中,供查询引擎进行查询。每一个表的数据量可能都很大,就会触发shuffle join,关联性能非常差。
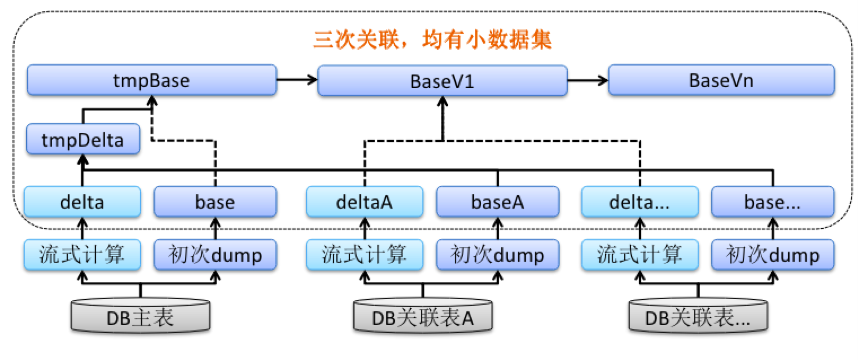
来看一下我们的解决方案,这个方案可以简单描述为三次关联:
每一张表都能够根据问题一的解决方案产生base文件和delta文件,base文件就包含了主表或者关联表的截止到某一个时刻的全部记录,那delta文件就包含了主表或者关联表在某个时间窗口内的变更记录。因为通常这种情况下,数据库的数据只是存量的记录比较多,但是增量的更新相对较少。所以每一个表的delta文件都是相对较小的,那这三次关联都是存在小数据集的,虽然关联了多次,但整体的时效还是满足预期的。
3)数据库和日志关联问题
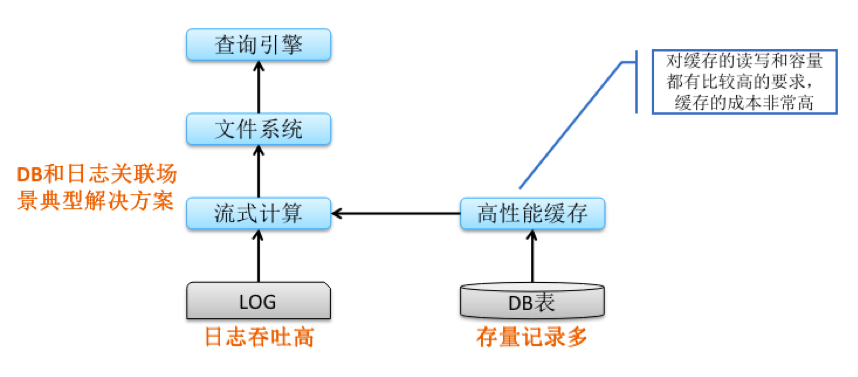
对于数据库和日志关联的问题,典型的解决方案大概是这样的,将数据库数据全量写入一个高性能缓存中,将日志数据在流式计算环节进行处理,然后通过查询高性能缓存的方式将数据库相关字段进行拼接,最终再通过固定的窗口写入到文件系统中,供查询引擎查询。那这个方案主要有这样的问题,存量的数据库记录非常多,这就要求缓存要有很大的容量,再一个是日志的吞吐特别高,这就会导致拼接的过程需要频繁查询缓存,也就是说,对缓存的读qps和容量都有比较高的要求,这就导致缓存的资源成本非常高。
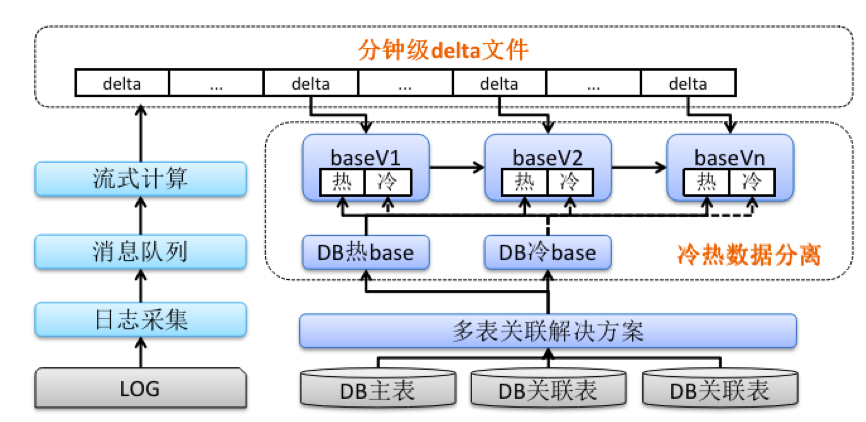
对于日志数据,通过日志采集写入到消息队列中,在流式计算环节通过固定的窗口产生delta文件,对于数据库数据,采用多表关联解决方案,能够滚动的产出可查询的版本,有变化的是采取了一个冷热数据分离的方案,日志的delta文件分钟级滚动合并的时候,只合并热数据,对于冷的数据进行天级别的合并。这个实现的降级其实也主要是以最低的成本,来满足业务最核心的诉求,业务最主要的诉求就是热数据能够快速查到,数据准确一致。这个方案整体上也是参考了一些Lambda架构的思想,虽然有冷热数据两次不同的合并,但是合并的逻辑是一致的不需要写两份代码,只不过资源层面会新增一份全量数据的关联,但是从整体看,既满足了需求,资源又没有增加太多。
4)数据水位问题
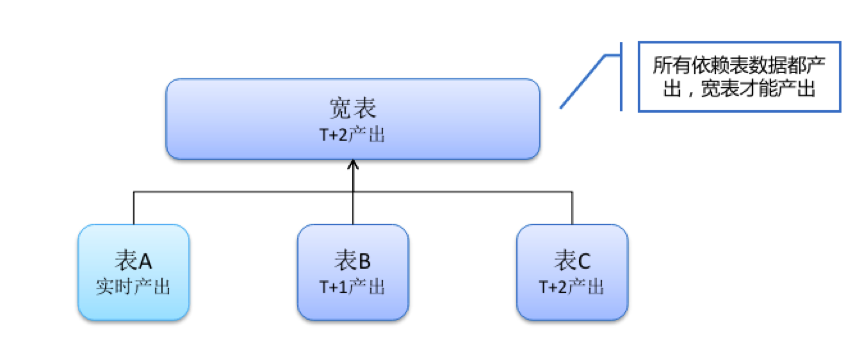
前面也说了,我们的建模从之前的分层建模改成了宽表建模,而宽表建模有个最大的问题就是数据到位时间问题,那通常情况下所有的依赖表数据都产出之后,宽表才能产出。
实际情况下,我们的数据源往往是复杂的,比如有一部分表能实时产出,分钟级延迟,但有些表因为一些特殊的逻辑只能T+1,甚至T+2产出。
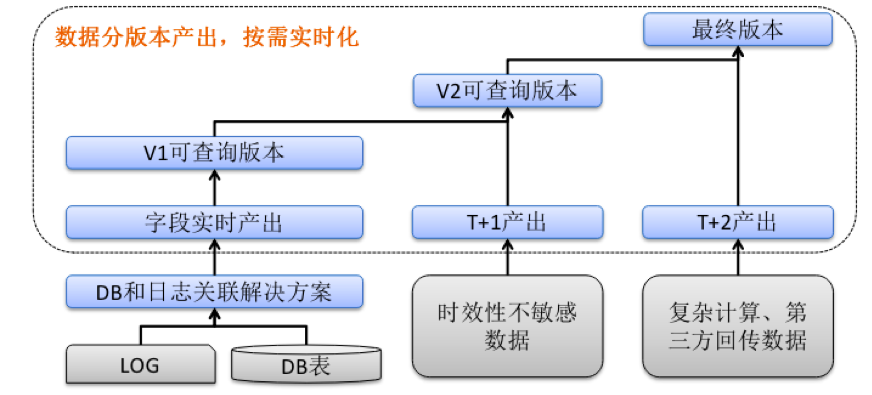
总体的方案就是数据按版本产出,字段按需实时化,原始的日志、数据库数据,通过前面讲的三个解决方案,能够保证实时的字段分钟级产出可查询版本,对于一些时效性不敏感的字段可能是T+1产出,对于一些复杂计算或者第三方回传的字段可能是T+2产出,但是整体的展现形式是一张宽表,同时在业务使用宽表的时候展示字段可用状态。
四、总结和规划
流批一体的实时数仓架构,大幅度降低了数据的导入延迟和数据查询的耗时。
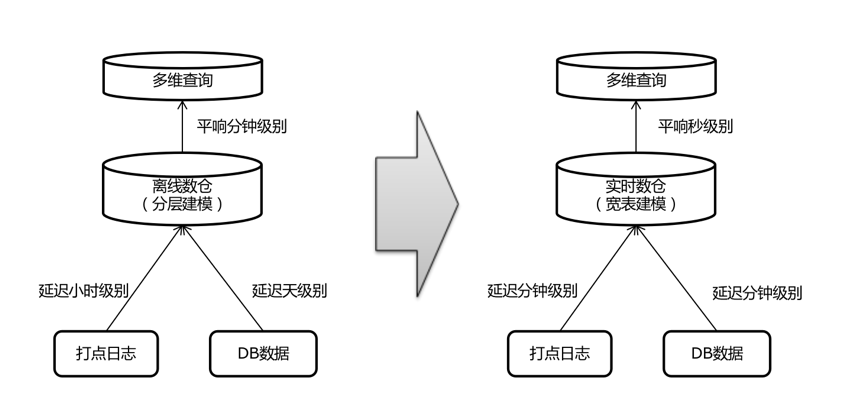
数据的导入延迟从之前的小时级别、天级别优化到分钟级别,数据查询的耗时从之前的分钟级别优化到秒级别,极大的提升了业务对于数据的时效性体验。另外实时离线逻辑统一,不再需要同时开发两套代码处理相同的逻辑,降低了开发和维护成本,也消除了长期困扰业务的在离线数据差异问题。
我们的后续规划有引擎查询性能持续提升,上层查询工具体验优化等方向,也欢迎业界感兴趣的同行们一起探讨。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721