
作者介绍
王鹏哲,转转数据智能部高级数据研发工程师,负责公司高斯自助分析平台及实时数据体系建设。
一、自助分析场景OLAP技术选型
1.1 背景
1.2 OLAP选型考量
1.3 ClickHouse
二、高斯平台自助分析场景
2.1 系统介绍
2.2 系统架构
2.3 ClickHouse在高斯平台的业务场景
三、ClickHouse的优化实践
3.1 内存优化
3.2 性能调优参数
3.3 亿级数据JOIN
四、ClickHouse未来的规划与展望
4.1 ClickHouse应用实践痛点
4.2 未来规划及展望
五、总结
公司每日产生海量数据,按业务需要进行统计产出各类分析报表,但巨大的数据量加上复杂的数据模型,以及个性化的分析维度,采用传统的离线预计算方式难以灵活支持,为此需引入一种满足实时多维分析场景的计算引擎框架来支撑业务精细化运营场景。本文将分享ClickHouse在自助分析场景中的探索及实践,文章将从以下4个方面介绍:
自助分析场景OLAP技术选型
高斯平台自助分析场景
ClickHouse的优化实践
ClickHouse未来的规划与展望
一、自助分析场景OLAP技术选型
1.1 背景

转转平台主要对业务运营数据(埋点)进行分析,埋点数据包含在售商品的曝光、点击、展现等事件,覆盖场景数据量很大,且在部分分析场景需要支持精确去重。大数据量加上去重、数据分组等计算使得指标在统计过程中运算量较大。除此之外,在一些数据分析场景中需要计算留存率、漏斗转化等复杂的数据模型。
虽然在离线数仓的数仓分层和汇总层对通用指标做了预计算处理,但由于这些模型的分析维度通常是不确定的,因此预计算无法满足产品或者运营提出的个性化报表的需求,需分析师或数仓工程师进行sql开发,使得数据开发链路长交付慢,数据价值也随着时间的推移而减少。
作为分析平台,既需要保证数据时效性、架构的高可用,也要做到任意维度、任意指标的秒级响应。基于以上情况,需要一个即席查询的引擎来实现。
1.2 OLAP选型考量
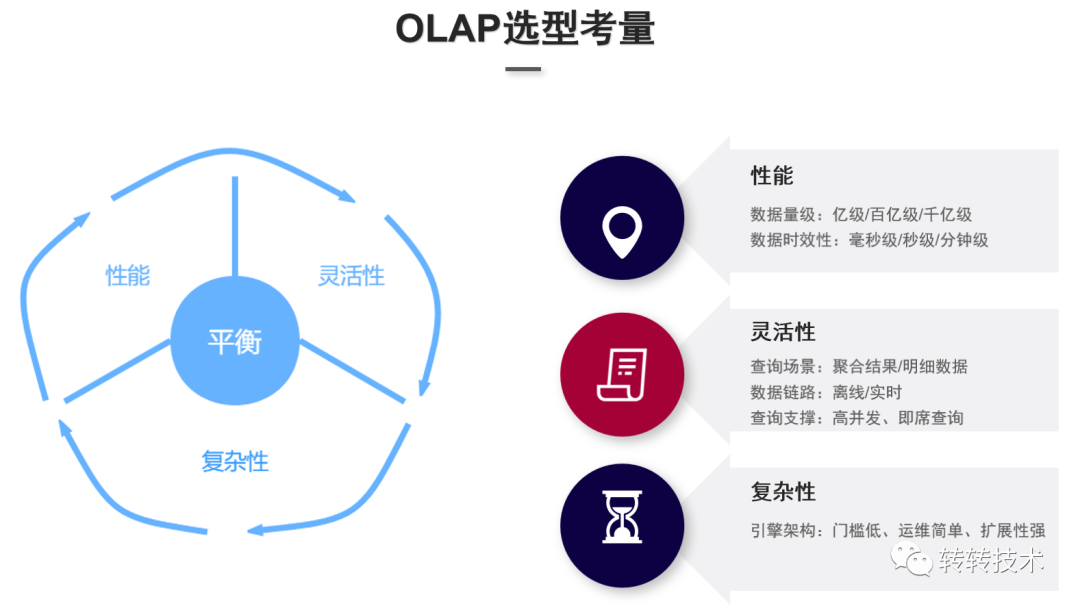
转转对OLAP引擎选型考量有三个方面:性能,灵活性,复杂性。
性能:
数据量级(亿级/百亿级/千亿级等)
数据计算反馈时效性(毫秒级/秒级/分钟级)
灵活性:
能否支持聚合结果或明细数据的查询,还是两者都支持
数据链路能否支持离线数据和实时数据的摄取
是否支持高并发的即席查询
复杂性:
架构简单
使用门槛低
运维难度低
扩展性强
根据这三个方面的考量,调研了目前主流的几类开源OLAP引擎:
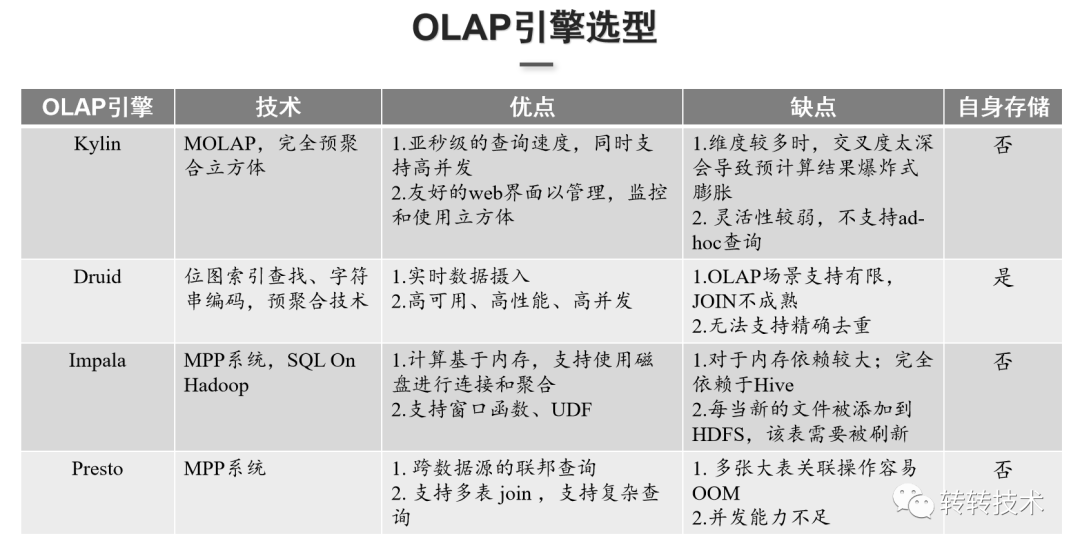
OLAP引擎主要分为两大类:
基于预计算的MOLAP引擎的优势是对整个计算结果做了预计算,查询比较稳定,可以保证查询结果亚秒级或者是秒级响应。但由于依赖预计算,查询的灵活性比较弱,无法统计预计算外的数据,代表是Kylin和Druid;
基于MPP架构的ROLAP引擎可以支持实时数据的摄入和实时分析,查询场景灵活,但查询稳定性较弱,取决于运算的数据量级和资源配比,基于MPP架构的OLAP一般都是基于内存的,代表是Impala和Presto;
Kylin采用的技术是完全预聚合立方体,能提供较好的SQL支持以及join能力,查询速度基本上都是亚秒级响应。同时,Kylin有良好的web管理界面,可以监控和使用立方体。但当维度较多,交叉深度较深时,底层的数据会爆炸式的膨胀。而且Kylin的查询灵活性比较弱,这也是MOLAP引擎普遍的弱点。
Druid采用位图索引、字符串编码和预聚合技术,可以对数据进行实时摄入,支持高可用高并发的查询,但是对OLAP引擎的分析场景支持能力比较弱,join的能力不成熟,无法支持需要做精确去重计算的场景。
Impala支持窗口函数和UDF,查询性能比较好,但对内存的依赖较大,且Impala的元数据存储在Hive Metastore里,需要与Hadoop组件紧密的结合,对实时数据摄入一般要结合Kudu这类存储引擎做DML操作,多系统架构运维也比较复杂。
Presto可跨数据源做联邦查询,能支持多表的join,但在高并发的场景下性能较弱的。
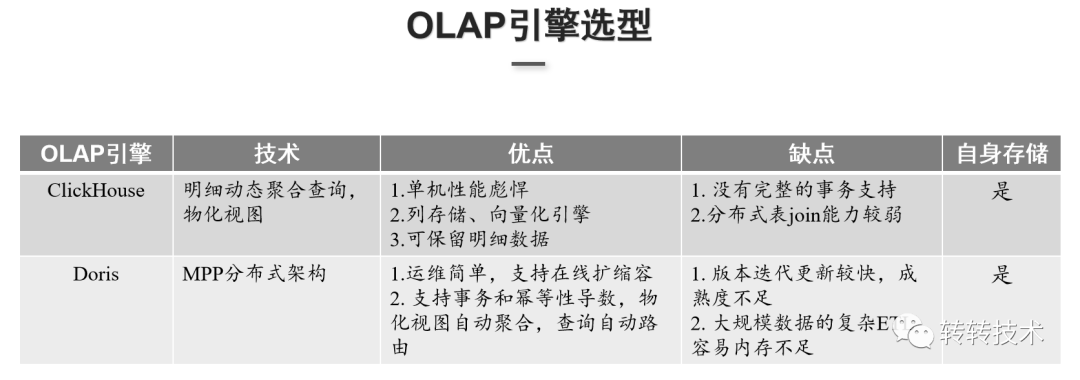
ClickHouse单机性能很强,基于列式存储,能利用向量化引擎做到并行化计算,查询基本上是毫秒级或秒级的反馈,但ClickHouse没有完整的事务支持,对分布式表的join能力较弱。
Doris运维简单,扩缩容容易且支持事务,但Doris版本更新迭代较快且成熟度不够,也没有像ClickHouse自带的一些函数如漏斗、留存,不足以支撑转转的业务场景。
基于以上考量,最终选择了ClickHouse作为分析引擎。
1.3 ClickHouse
ClickHouse是面向实时联机分析处理的基于列式存储的开源分析引擎,是俄罗斯于2016年开源的,底层开发语言为C++,可以支撑PB数据量级的分析。ClickHouse有以下特性:
具有完备的dbms功能,SQL支持较为完善。
基于列式存储和数据压缩,支持索引。
向量化引擎与SIMD提高CPU的利用率,多核多节点并行执行,可基于较大的数据集计算,提供亚秒级的查询响应。
支持数据复制和数据完整性。
多样化的表引擎。ClickHouse支持Kafka、HDFS等外部数据查询引擎,以及MergeTree系列的引擎、Distribute分布式表引擎。
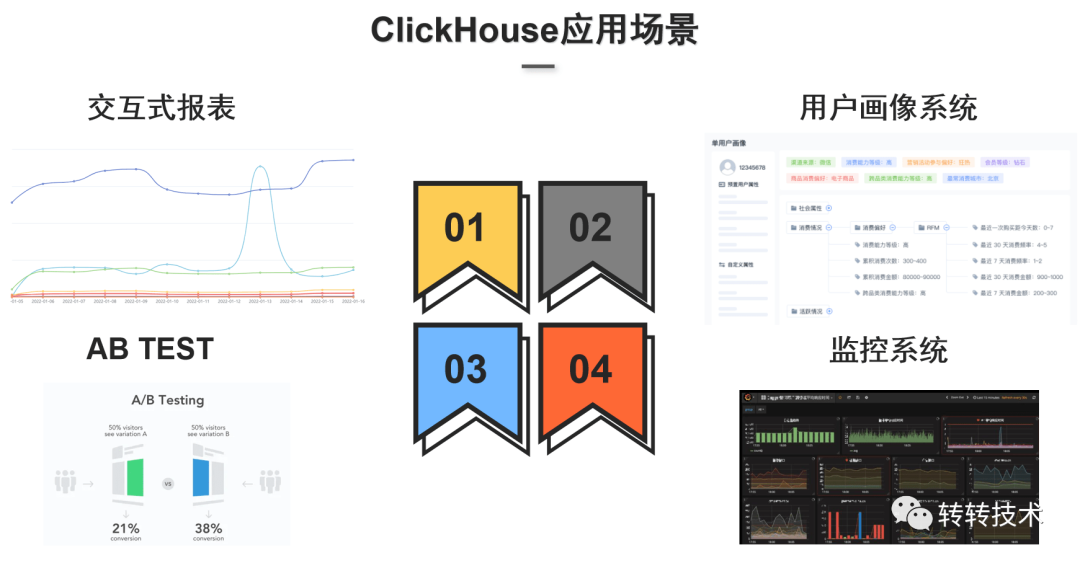
ClickHouse的查询场景主要分为四大类:
交互式报表查询:可基于ClickHouse构建用户行为特征宽表,对于多维度,多指标的计算能秒级给出计算反馈;
用户画像系统:在ClickHouse里面构建用户特征宽表,支持用户细查、人群圈选等;
AB测试:利用ClickHouse的高效存储和它提供的一些自带的函数,如grouparray函数,可以做到秒级给出AB实验的效果数据;
监控系统:通过Flink实时采集业务指标、系统指标数据,写到ClickHouse,可以结合Grafana做指标显示。
二、高斯平台自助分析场景
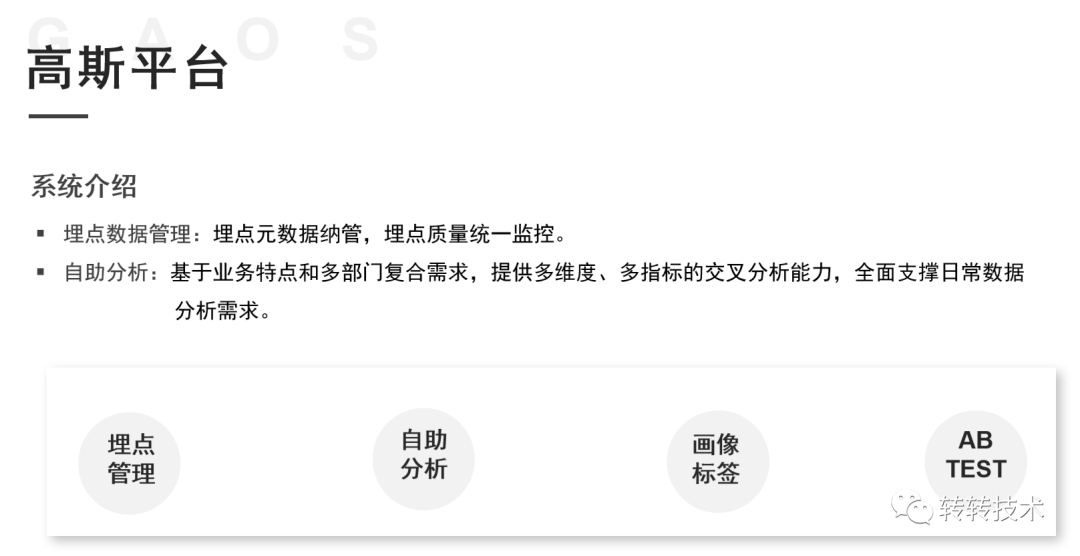
转转高斯平台的核心功能主要包含两个部分:
埋点数据管理:埋点元数据管理,埋点元数据质量监控和告警;
自助分析:基于业务特点和多部门复合需求,提供多维度、多指标的交叉分析能力,可以支持用户画像标签选择、人群圈选,AB TEST等分析功能,全面支撑日常数据分析需求。
2.2 系统架构
下图展示了高斯平台的系统架构,总共分为四层:
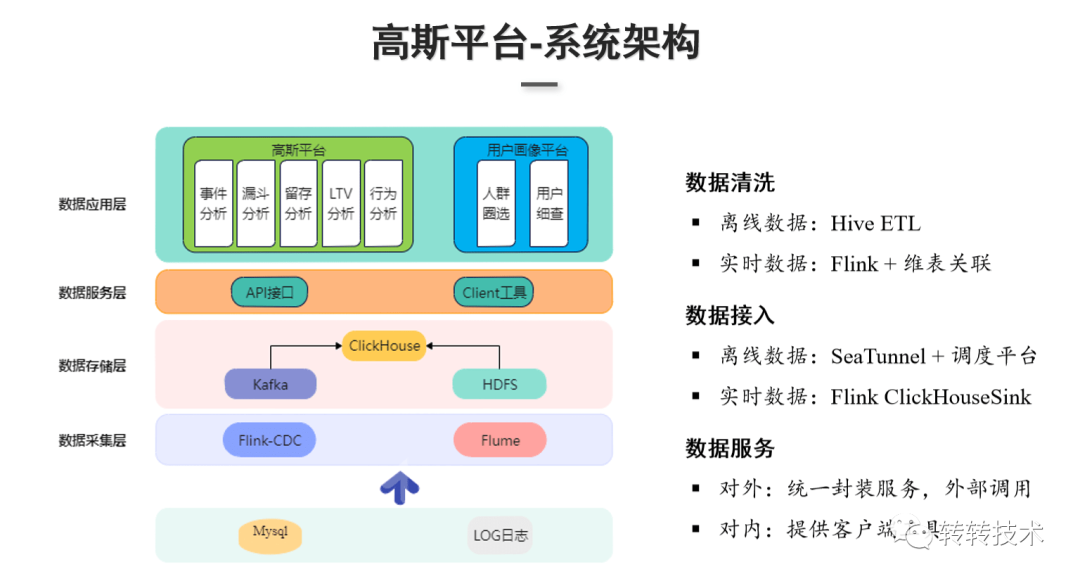
数据采集层:数据来源主要是业务库和埋点数据。业务库数据存储在MySQL里,埋点数据通常是LOG日志。MySQL业务库的数据通过Flink-CDC实时抽取到Kafka;LOG日志由Flume Agent采集并分发到实时和离线两条通道,实时埋点日志会sink写入Kafka,离线的日志sink到HDFS。
数据存储层:主要是对数据采集层过来的数据进行存储,存储采用的是Kafka和HDFS,ClickHouse基于底层数据清洗和数据接入,实现宽表存储。
数据服务层:对外统一封装的HTTP服务,由外部系统调用,对内提供了SQL化的客户端工具。
数据应用层:主要是基于ClickHouse的高斯自助分析平台和用户画像平台两大产品。高斯分析平台可以对于用户去做事件分析,计算PV、UV等指标以及留存、LTV、漏斗分析、行为分析等,用户画像平台提供了人群的圈选、用户细查等功能。
2.3 ClickHouse在高斯平台的业务场景
①行为分析
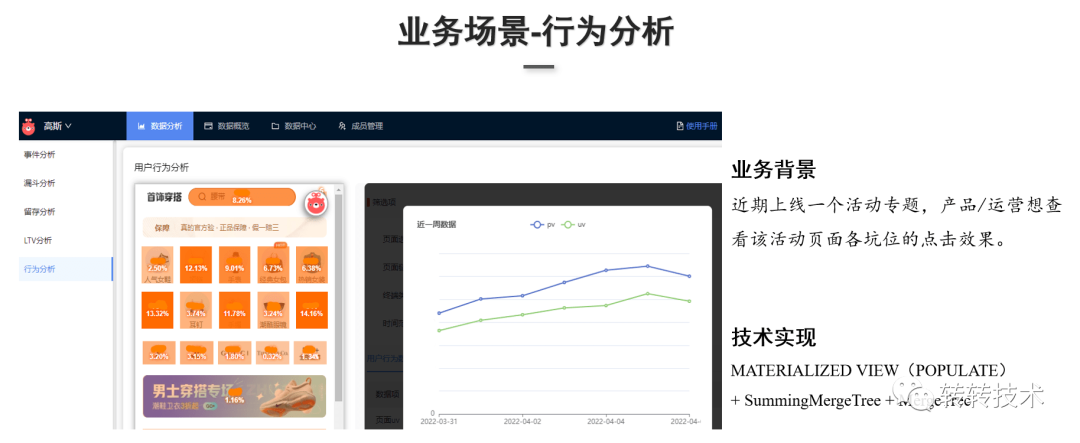
业务背景:App上线活动专题页,业务方想查看活动页面上线后各个坑位的点击的效果。
技术实现:采用ClickHouse的物化视图、聚合表引擎,以及明细表引擎。ClickHouse的物化视图可以做实时的数据累加计算,POPULATE关键词决定物化视图的更新策略。在创建物化视图时使用POPULATE关键词会对底层表的历史数据做物化视图的计算。
②AB-TEST分析
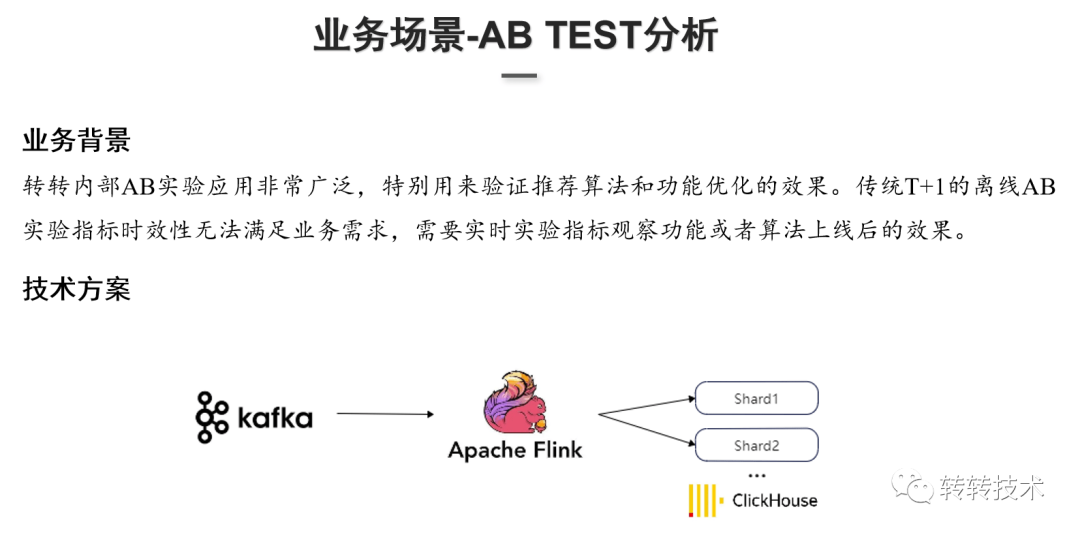
业务背景:转转早期AB-TEST采用传统的T+1日数据,但T+1日数据已无法满足业务需求。
技术方案:Flink实时消费Kafka,自定义Sink(支持配置自定义Flush批次大小、时间)到ClickHouse,利用ClickHouse做实时指标的计算。
三、ClickHouse的优化实践
3.1 内存优化

在数据分析过程中常见的问题大都是和内存相关的。如上图所示,当内存使用量大于了单台服务器的内存上限,就会抛出该异常。
针对这个问题,需要对SQL语句和SQL查询的场景进行分析:
如果是在进行count和disticnt计算时内存不足,可以使用一些预估函数减少内存的使用量来提升查询速度;
如果SQL语句进行了group by或者是order by操作,可以配置max_bytes_before_external_group_by和max_bytes_before_external_sort这两个参数调整。
3.2 性能调优参数
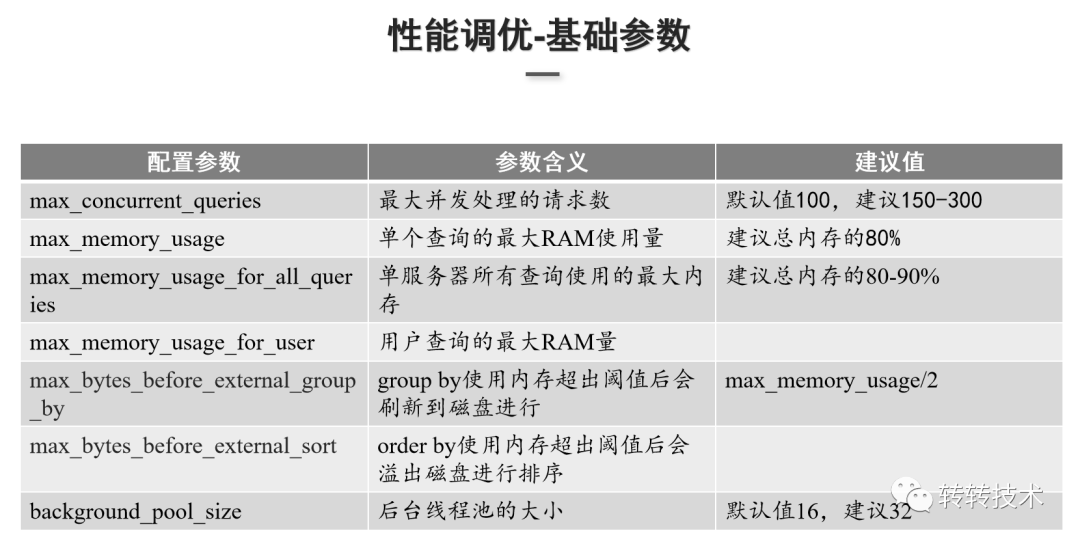
上图是实践的一些优化参数,主要是限制并发处理的请求数和限制内存相关的参数。
max_concurrent_queries:限制每秒的并发请求数,默认值100,转转调整参数值为150。需根据集群性能以及节点的数量来调整此参数值。
max_memory_usage:设置单个查询单台机器的最大内存使用量,建议设置值为总内存的80%,因为需要预留一些内存给系统os使用。
max_memory_usage_for_all_queries:设置单服务器上查询的最大内存量,建议设置为总内存的80%~90%。
max_memory_usage_for_user & max_bytes_before_external_sort:group by和order by使用超出内存的阈值后,预写磁盘进行group by或order by操作。
background_pool_size:后台线程池的大小,默认值为16,转转调整为32。这个线程池大小包含了后台merge的线程数,增大这个参数值是有利于提升merge速度的。
3.3 亿级数据JOIN
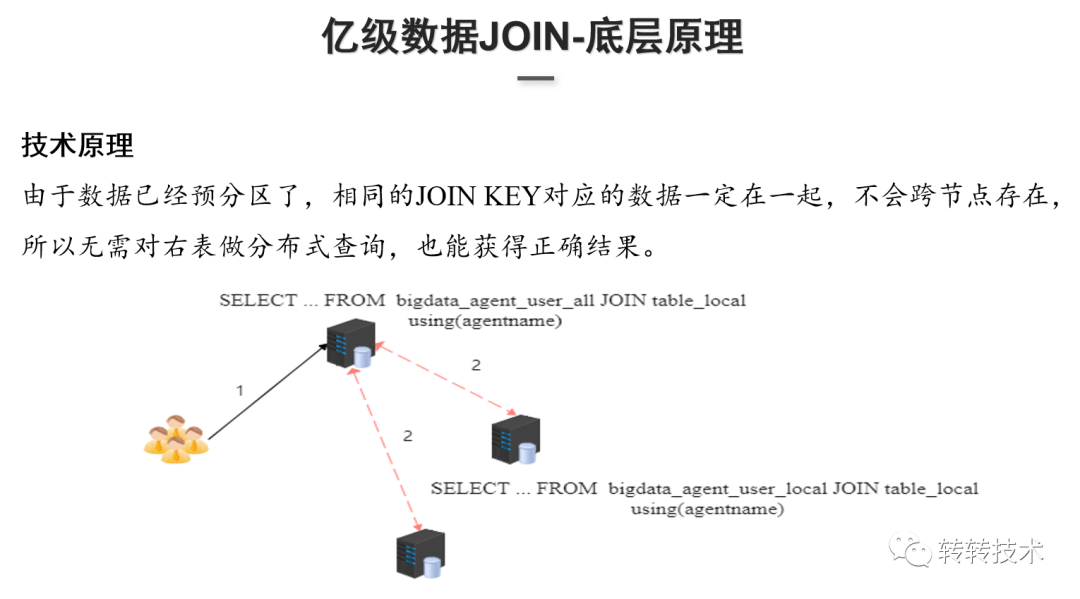
技术原理:在做用户画像数据和行为数据导入的时候,数据已经按照Join Key预分区了,相同的Join Key其实是在同一节点上,因此不需要去做两个分布式表跨节点的Join,只需要去Join本地表就行,执行过程中会把具体的查询逻辑改为本地表,Join本地表之后再汇总最后的计算结果,这样就能得到正确的结果。
四、ClickHouse未来的规划与展望
4.1 ClickHouse应用实践痛点
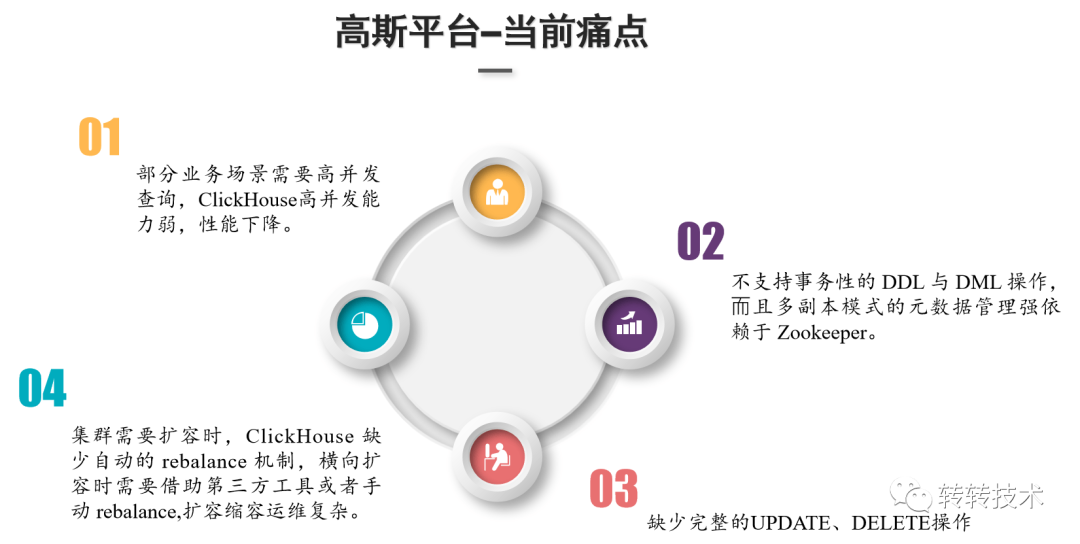
ClickHouse的高并发能力特别弱,官方的建议的QPS是每秒100左右。高并发查询时,ClickHouse性能下降比较明显;
ClickHouse不支持事务性的DDL和其他的分布式事务,复制表引擎的数据同步的状态和分片的元数据管理都强依赖于Zookeeper;
部分应用场景需要做到实时的行级数据update和delete操作,ClickHouse缺少完整的操作支持;
ClickHouse缺少自动的re-balance机制,扩缩容时数据迁移需手动均衡。
4.2 未来规划及展望

服务平台化,故障规范化:提高业务易用性,提升业务治理,比如:资源的多租户隔离,异常用户的限流熔断,以及对ClickHouse精细化监控报警,包括一些慢查询监控;
ClickHouse容器化的部署:支持数据的存算分离,更好的弹性集群扩缩容,扩缩容后自动数据均衡;
服务架构智能化:针对部分业务场景的高并发查询,ClickHouse本身的支持高并发能力比较弱,引入Doris引擎。基于特定的业务场景去自适应的选择ClickHouse或者是Doris引擎;
ClickHouse内核级的优化:包括实时写入一致性保证、分布式事务支持、移除Zookeeper的服务依赖。目前Zookeeper在ClickHouse数据达到一定量级是存在瓶颈的,所以移除Zookeeper服务依赖是迫切和必然的。
五、总结
在巨大的数据量面前,想追求极致的性能及全部场景适应性,必须在某些技术方案上进行取舍。ClickHouse从底层列式存储到上层向量化并行计算,都没有考虑存算分离、弹性扩展的技术方案,甚至于横向扩容数据需要手动re-balance。因此,如果要实现云上的可动态伸缩、存算分离,ClickHouse需要重构底层代码。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721