
有多大把握让集群稳定运行?
集群的吞吐量是多少?
集群性能如何?
集群中是否有足够的可用资源,它们是否易于扩展和维护?
集群大小合适吗?
每个人在新项目、新架构部署时都应该思考这些问题。在本文中,我们将深入讨论上面提到的性能、ES集群规模问题。并提供一套方法和建议,帮助你确定ES集群的规模,并对环境进行基准测试。
无论我们定义什么样的系统架构,我们都需要对用例以及我们提供的功能有一个清晰的理解,架构也可能受到现有硬件的约束,比如现有的硬件、公司的全球战略等诸多约束。这些都是我们在规模试验中需要考虑的因素。
一、硬件资源如何分配
性能取决于Elasticsearch执行什么任务,在什么平台上运行。对于每个搜索或索引操作,都涉及到以下资源:
1、磁盘存储
建议尽可能使用 SSD,特别是那些运行搜索和索引操作的节点。由于 SSD 存储的成本较高,建议使用热温架构来减少支出。
在裸机上操作时,本地磁盘才是王道!
Elasticsearch 不需要冗余存储(无需 RAID 1/5/10),日志和指标用例通常至少有一个副本分片,这是确保容错性的最低要求,同时又能最大限度地减少写入次数。
2、内存
JVM:存储关于集群、索引、分片、段和 Fielddata 的元数据。该项较为理想的设置是可用 RAM 的 50%。
OS Cache:Elasticsearch 将使用剩余的可用内存来缓存数据,避免在全文搜索、对文档值执行聚合和排序期间多次读取磁盘,从而实现性能的极大提升。
3、CPU
Elasticsearch 节点具有线程池和线程队列,它们会使用可用的计算资源。在 Elasticsearch 中,CPU 核心的数量和性能决定着数据操作的平均速度和峰值吞吐量。
4、网络
网络性能—带宽和延迟会影响节点之间的通信和集群之间的功能,如跨集群搜索和跨集群复制。
二、根据数据量确定集群规模
对于指标和日志用例,通常要管理大量的数据。因此,根据数据量初步确定Elasticsearch的聚类规模是有意义的。在测试开始时,需要考虑以下问题:
每天将索引多大量的原始数据 (GB)
数据保留多久
在 hot tier 存储多久
在 warm tier 存储多久
强制执行多少个副本分片
在确定规模时,一般增加5%或10%以适应误差,增加15%以保持低于磁盘阈值。此外,最好添加一个故障冗余节点。
1、掐指一算
数据总量 (GB) = 每日原始数据量 (GB) * 保留天数 *(副本数 + 1)
存储总量 (GB) = 数据总量 (GB) *(1 + 0.15 磁盘水位阈值 + 0.1 误差幅度)
数据节点总数 = ROUNDUP(存储总量 (GB) /每个数据节点的内存/内存与数据值比) 在大规模部署的情况下,添加一个节点用于故障转移容量会更安全。
2、小规模集群
假设每天1GB的数据,数据存储 9个月。
对于这种小型集群,每个节点分配 8G 内存。那么可以得出:
总数据量 (GB) = 1GB x(9 x 30 天)x 2 = 540GB
总存储量 (GB) = 540GB x (1+0.15+0.1) = 675GB
总数据节点数 = 675GB 磁盘存储量/ 8GB RAM /内存与数据比 30 = 3 个节点
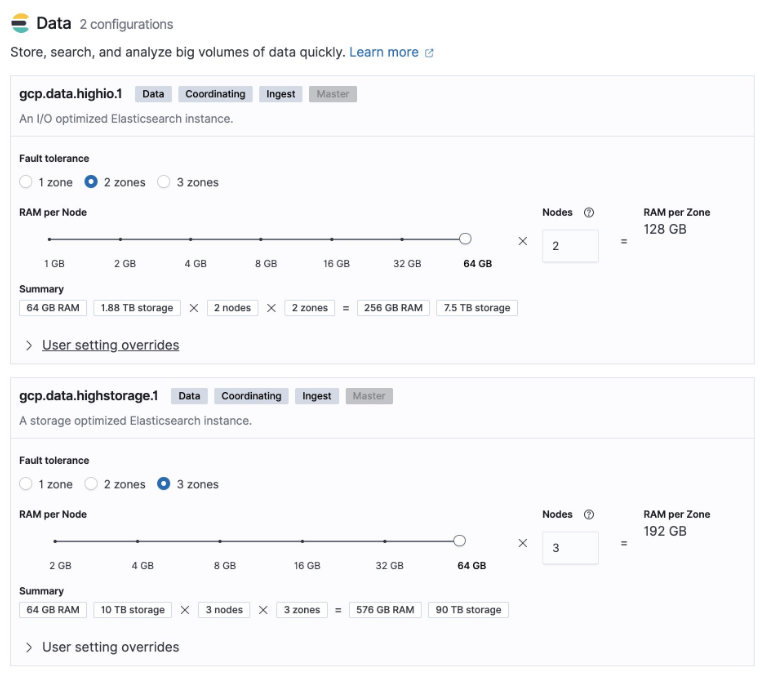
基于 Elastic Cloud 上构建部署:

3、大规模集群部署
假设:
每天产生 100GB 数据,并且需把数据在hot tier 中存储 30 天,在warm tier中存储 12 个月。
每个节点有 64GB 的内存,其中 30GB 分配给JVM,其余分配给 OS Cache。
所用 hot tier 内存与数据的典型比值是 1:30,warm tier是 1:160。
如果每天接收 100GB 的数据,并且必须将这些数据存储 30 天,那么可以得出:
hot tier中的数据总量 (GB) =(100GB x 30 天 * 2)= 6000GB
hot tier中的存储总量 (GB) = 6000GB x (1+0.15+0.1) = 7500GB
hot tier中的数据节点总数 = ROUNDUP(7500 / 64 / 30) + 1 = 5 个节点
warm tier中的数据总量 (GB) =(100GB x 365 天 * 2)= 73000GB
warm tier中的存储总量 (GB) = 73000GB x (1+0.15+0.1) = 91250GB
warm tier中的数据节点总数 = ROUNDUP(91250 / 64 / 160) + 1 = 10 个节点
在 Elastic Cloud 上构建集群:
三、基准测试
到目前为止,我们已经确定了合适的集群大小。接下来,我们需要确认所获得的值在实际条件下是否能够成立。为了在投入生产环境之前更有信心,我们需要进行基准测试,以确认我们可以实现预期的性能和目标SLA。
在这个基准测试中,我们将使用 Rally。该工具易于部署和执行,并且完全可配置。它可以测试多种场景。
为了简化结果分析,我们将基准分为两部分,即索引和搜索请求。
四、索引基准测试
对于索引基准测试,我们要尝试弄清楚以下几个问题:
集群的最大索引吞吐量是多少?
每天可以索引的数据量是多少?
集群是过大还是过小?
在这项基准测试中,我们将使用一个 3 节点集群,每个节点的配置如下:
8 vCPU
标准永久磁盘 (HDD)
32GB/16 堆
索引基准测试 1
这项基准测试使用的数据集是 Metricbeat 数据,规格如下:
1,079,600 个文档
数据量:1.2GB
平均文档大小:1.17 KB
指数的表现也将取决于指数层的表现,在这种情况下是反弹。在这个例子中,我们将执行多个基准测试来找出最佳的批处理大小和最佳的线程数量。
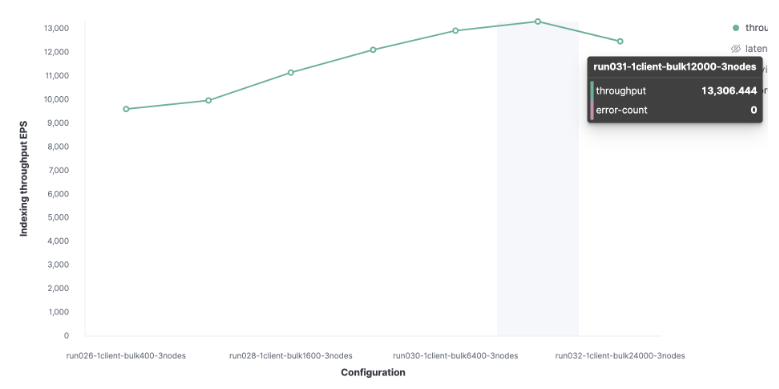
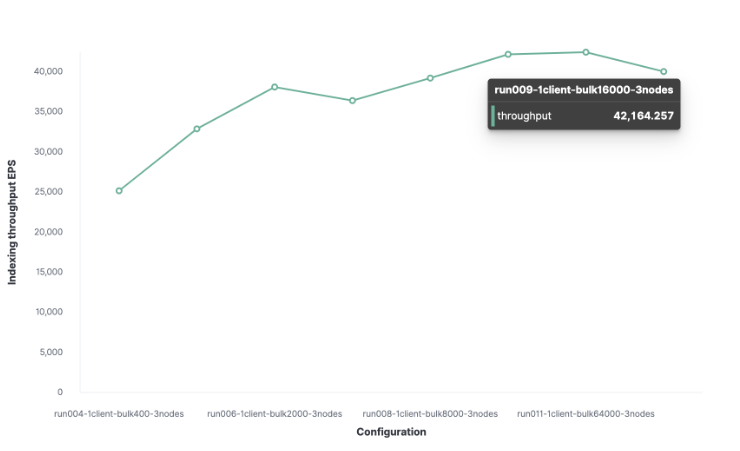
我们将从1个Rally客户开始寻找最佳批量。然后从100开始,在随后的运行中加倍。这表明我们的最佳批处理大小是12,000(大约13.7 MB),我们每秒可以索引13,000个请求。
接下来,使用类似的方法,我们发现客户端的最佳数量是16,这使我们能够每秒索引62,000个请求。
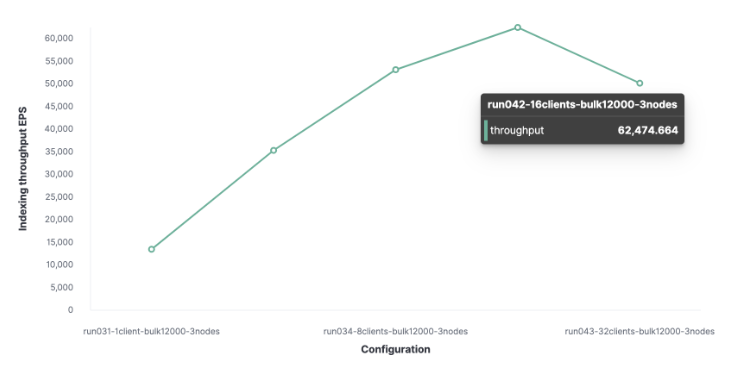
我们集群的最大索引吞吐量每秒可以处理62,000个请求。为了更进一步,我们需要添加一个新的节点。
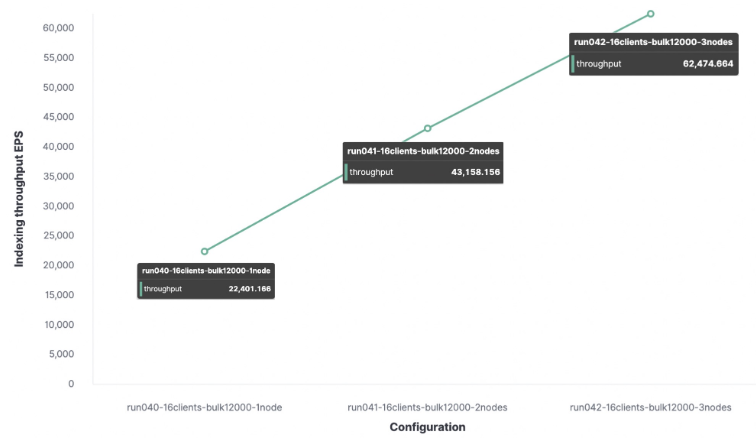
我很想知道一个节点可以处理多少个索引请求,所以我在一个节点集群和两个节点集群上执行了相同的跟踪,以观察不同之处。
结论
在我的测试环境中,最大索引吞吐量如下:
使用1个节点和1个 shard, 每秒得到22,000个请求。
使用2个节点和2个shard, 每秒得到43,000个请求。
使用3个节点和3个shard, 每秒得到62,000个请求。
任何其他索引请求都将被放入队列,当队列变满时,节点将发送一个拒绝响应。
我们的数据集影响集群的性能,这就是为什么使用您自己的数据来执行这些跟踪非常重要。
索引基准测试 2
在接下来的步骤中,使用以下配置对HTTP服务器日志数据执行相同的跟踪:
数据量:31.1GB
文档数:247,249,096
平均文档大小:0.8 KB
最优批量大小为 16,000 个文档。
得出的最优客户端数为 32 个。
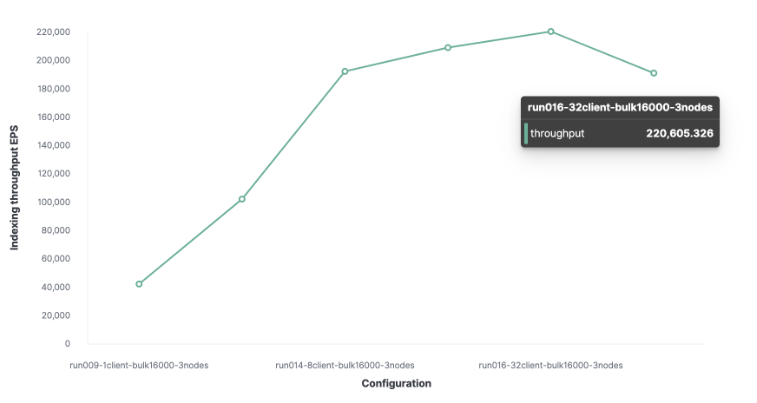
HTTP 服务器日志数据的最大索引吞吐量为每秒 220,000 个请求。
五、搜索基准测试
为了对搜索性能进行基准测试,我们将考虑使用 20 个客户端,目标吞吐量为 1000 OPS。
对于搜索,我们将执行三项基准测试:
1、查询的服务时间
我们将比较一组查询的服务时间 (90%)。
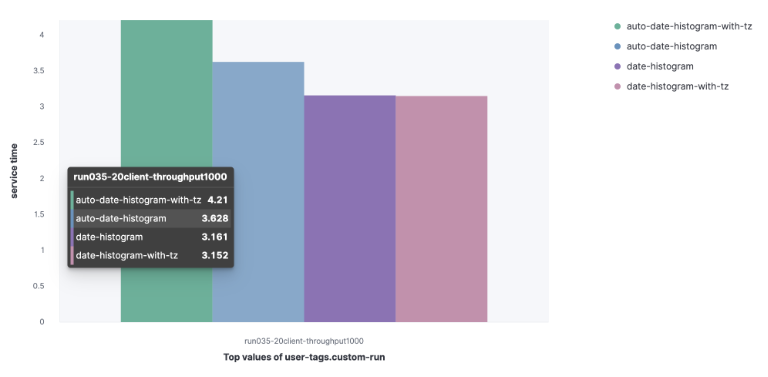
1)Metricbeat 数据集
auto-date-historgram
auto-data-histogram-with-tz
date-histogram
Date-histogram-with-tz
我们可以观察到,auto-data-histogram-with-tz 查询的服务时间更长。
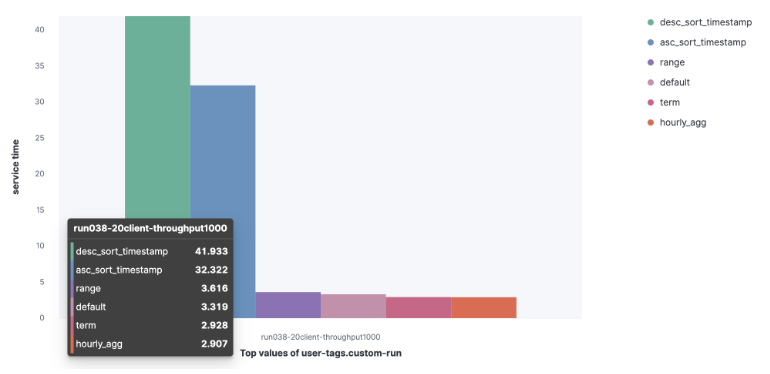
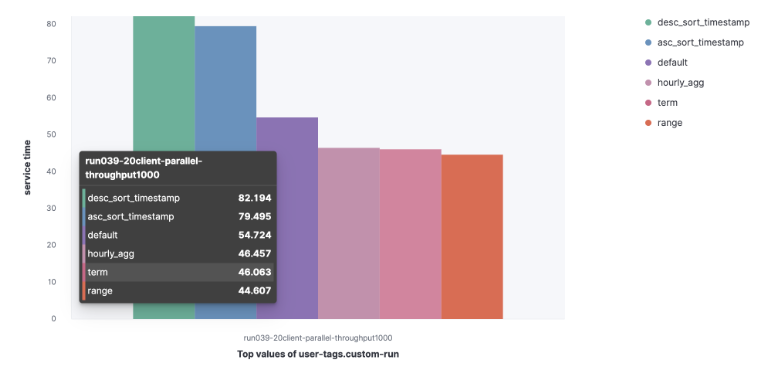
2)HTTP 服务器日志数据集
Default
Term
Range
Hourly_agg
Desc_sort_timestamp
Asc_sort_timestamp
我们可以观察到,desc_sort_timestamp and desc_sort_timestamp 查询的服务时间更长。
2、并行查询的服务时间
我们来看看,如果并行执行查询,90% 服务时间会增加。
3、并行索引的索引率和服务时间
我们将执行并行索引任务和搜索,以查看这些查询的索引率和服务时间。

我们来看看,当与索引操作并行执行时,查询的 90% 服务时间会增加。

4、读取结果
在 32 个客户端用于索引,20 个用户用于搜索时:
索引吞吐量为 173,000,小于先前提到的 220,000。
搜索吞吐量为每秒 1000 个请求。
六、结论
调整测试方法,可以得出一套根据数据量计算所需节点数量的方法。为了更好地规划集群的未来性能,还需要对基础设施进行基准测试。性能也取决于用例,所以建议使用最接近实际情况的数据和查询进行测试。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721