
李猛,数据领域专家,Elastic Stack国内顶尖实战专家,国内首批Elastic官方认证工程师21人之一。2012年入手Elasticsearch,对Elastic Stack技术栈开发、架构、运维、源码、算法等方面有深入实战经验。负责过多种Elastic Stack项目,包括大数据分析领域、机器学习预测领域、业务查询加速领域、日志分析领域、基础指标监控领域等。十余年技术实战从业经验,擅长大数据多种技术栈混合,系统架构领域。
序言
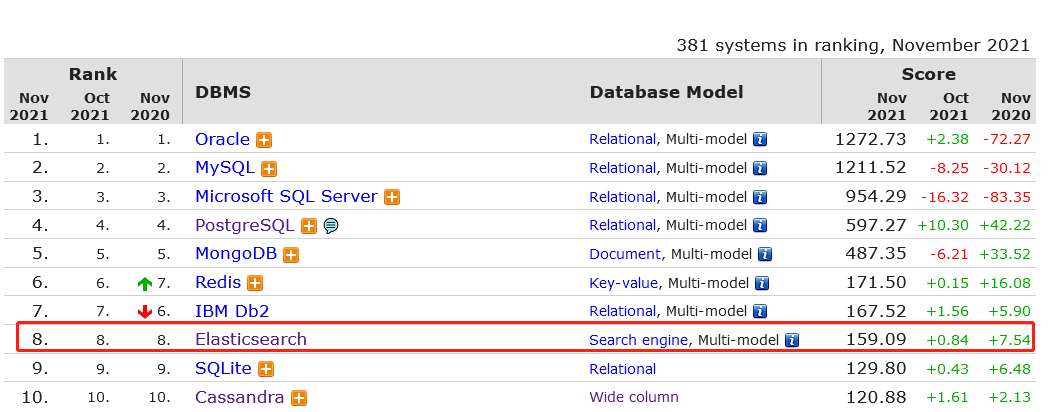
图示:Elasticsearch在DB-Engine综合排名第8
Elasticsearch除了在查询搜索领域非常强悍之外,在聚合统计分析领域也颇有造诣,且在业务应用场景特别受欢迎。ES提供了3大类型的聚合统计,Bucket分桶聚合(雷同MySQL分组Group)是应用最广泛的。
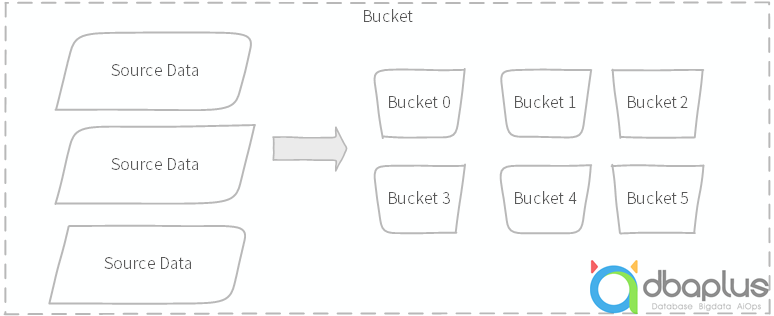
图示:分桶统计示意图
一、案例描述
既然要探讨ES聚合统计分析应用场景的造诣,当然得先从实战优化开始,下面就从一些实战案例展开。
某ES集群采用几十台物理机,单物理机部署多个ES实例,单集群总实例数不过百,单物理机内存与计算资源充足;集群总数据量在数百TB,索引总数量超过数千个,单索引采用单分片设计,单分片不超过50~70GB,属于官方建议的合理性范围。
集群数据实时写入,按照一定规则进行分流存储到各个索引,此处并没有什么问题,且性能一直表现很好。
业务场景需求,单次需要基于多个索引进行查询过滤,单次查询索引数量控制在10个以内,需要同时完成聚合分桶统计,且需要非常高的并发度,支持日均几千万次以上并发聚合统计,注意这里需要的高并发,是按照TP系统要求的,对于外部应用来说,几乎不能感知到AP的存在。
单次查询过滤,符合条件的明细数据也就几十条,上限不过百,然后基于这些明细结果进行嵌套多层的分桶聚合统计。由于需要支持非常高的并发,且做到极快应用响应时间,工程师在应用中做了一些性能埋点,经过统计分析,发现一些很奇怪的疑点,约近一半的查询聚合数据量多的执行得更快,数据条数越少反而执行得更慢,且相当不稳定,按正常理解,这显然很不符合常识逻辑。
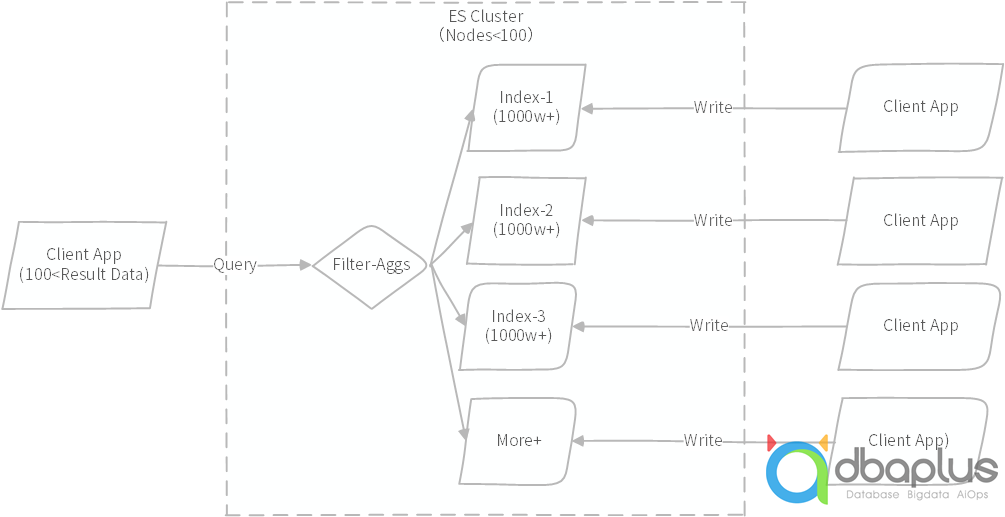
图示:集群案例架构查询示意图
经过来回多次沟通了解,基本很快确定了性能优化点,增加一个分桶属性设置即可。
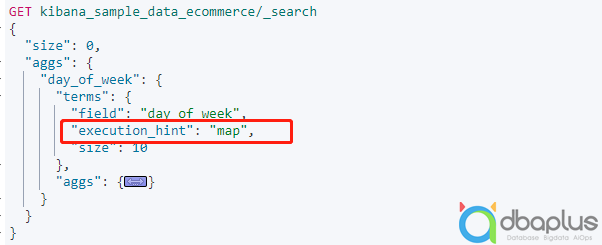
图示:DSL模拟聚会语法,案例基于官方数据编写
二、ES技术原理
本次案例排查与解决,涉及到一些ES内部实现的原理,常规情况下,如果不注意或者对于性能不是特别敏感,就直接忽略了,下面就借此简单聊聊ES一些内部原理与实现。
global_ordinals,直译“全局序号”,简言之此特性是为了提升“高基数”聚合统计性能的。当向ES写入"keyword”类型数据时,ES会内部生成一个内存映射表,来映射term词项与编号关系,故而叫“全局序号”,默认情况下,ES假定term在聚合统计下是“高基数”场景,默认会开启。初衷是好的,为了提升海量数据分桶统计性能,相反在少量数据统计聚合时,由于需要词项与编号之间的映射关系转换,性能反而会下降;再加上实时写入数据,词项的基数一直不稳定不固定,词项与序号映射关系也需要重建更新,故而就会出现上面案例的情况,部分数据量少的统计聚合性能执行时间反而更长。
为了解决少量“基数”数据统计性能问题,设计了一种无需“全局序号”的策略,直接基于词项分桶统计即可,设置统计属性“execution_hint=map”,通过在上面案例中增加改属性设置,聚合统计性能与业务需求明显符合期望认知。
{"aggs": {"tags": {"terms": {"field": "tags",/* 启用map统计模式*/"execution_hint": "map"}}}}
doc_values,中文意思“列式存储”,ES核心实现基于“倒排索引“”构建,擅长多条件搜索检索,但是反向过来,自定义排序非常不方便,为了解决此问题,设计了一种列式数据存储,通常简单的认为就是“正排索引”,与倒排刚好相反,也可以认为ES默认内部至少有两种不同的索引结构。我们都知道,列式存储特别擅长数据统计场景,所以在对比行式数据库与列式数据库时,一眼便知,哪种数据库产品更加适合数据统计。上面案例需求中,正式借助于ES强大的列式存储,实现了高效的聚合统计,面对日均千万次的聚合统计,既能保持高的执行速度,也能支持高的并发数。
默认情况下,doc_values是开启的,若不需要基于此字段聚合统计,也可以选择关闭,顺便节约一些资源消耗,同理ES提供了很多默认属性设置,如果足够了解,可以设置很多,优化性能的点多数源于这些细节。
{"mappings": {"properties": {"status_code": {"type": "keyword",/*默认开启*/"doc_values": true},"session_id": {"type": "keyword",/*显示关闭*/"doc_values": false}}}}
cross index search,直译“跨索引查询”,Elasticsearch核心基于Lucene,相比原始Lucene实现,最大的创新改进就是加入了“Shard”分片设计。一个索引就是一个或者多个分片组成,独立的分片实际就是一个独立的Lucene完整数据,搜索一个索引时,实际搜索的是承载索引的分片,搜索盖索引所有分片;同理,搜索多个索引也等同于搜索多个分片,与搜索单个索引多分片本质上一样。上面的案例中,需要基于业务条件选择几个索引进行查询统计,需要非常高的灵活性,正是利用了ES此种设计特性。
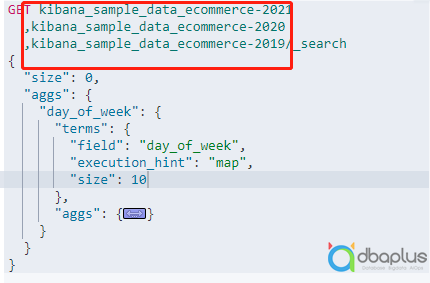
图示:跨多个索引查询语法示意图,来自官方案例
同比在传统数据库应用场景,为了解决海量数据存储,需要进行分库分表,但是分库分表之后需要进行组合查询,就非常麻烦,多数解决方案选择的正是ES,传统数据库的表转换可以映射到ES领域的索引或者分片,查询时,可以灵活组合,ES内部会自动进行路由。如果是异构的数据源,ES照样也可以执行多索引或者多分片查询。
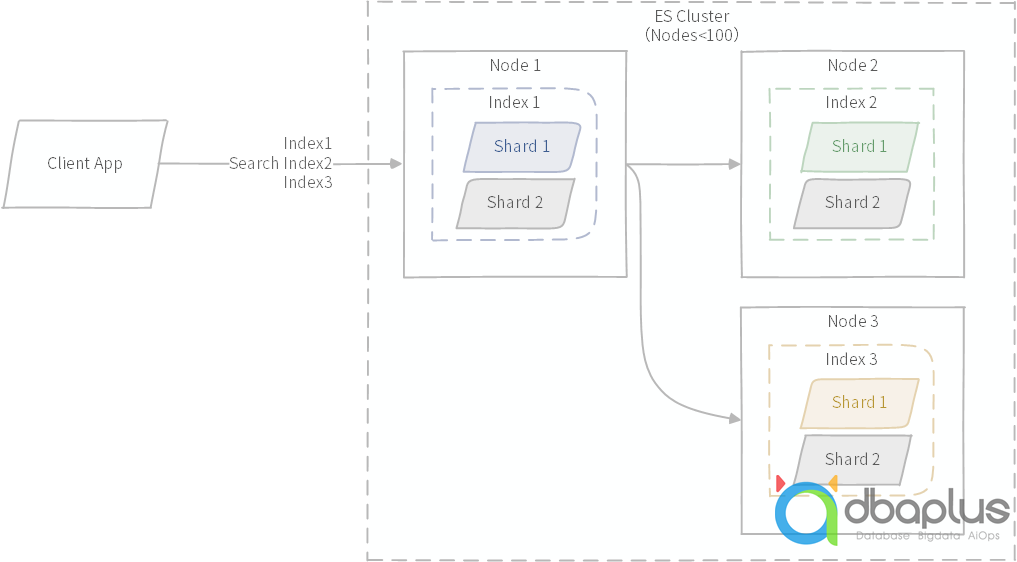
图示:跨多个索引查询与多分片查询示意图
三、OLTP与OLAP
进入了数据时代,人人都在谈大数据,人人都在进行大数据,各种数据厂家也纷纷为了展示自己的肌肉,各种性能比较碾压的文章特别多,给很多人带来了一些误导,特别是一些刚刚入行的工程师,以为xx性能特别好,只要掌握了就可以独步天下,其实不然。刚好借助上面的案例场景,来谈谈个人对于OLTP与OLAP的认知与观点。

图示:OLTP与OLAP比对,来自知乎某文章。
在企业项目实践中,到底是“TP”项目需求多还是“AP”项目需求多?答案显而易见,TP项目需求更多,而且是碾压式的。据一些专家统计,TP与AP项目需求比例约为9:1。
如上案例描述,表面看起来是个AP统计分析项目,有海量数据存储,有实时更新,更有实时分析统计诉求,实际上由业务部门开发落地,并不由大数据部门负责,业务部门选择了Elasticsearch,非常轻松快捷就实现了业务目标。
如上案例描述,业务单次查询与聚合,首先需要在单个或多个索引中基于筛选条件过滤,筛选前的数据量超过千万级甚至亿级,筛选后的数据量才几十条,聚合统计后更少,这种数据量级根本就不需要纯粹的OLAP产品来实现,或者说纯粹的OLAP产品也不能满足当下高并发查询需求。在纯粹的AP场景中,实际单次分析筛选过滤后还需要千万级或者亿级以上数据量的需求应该更少,多数都是案例所述场景。如下图所示:
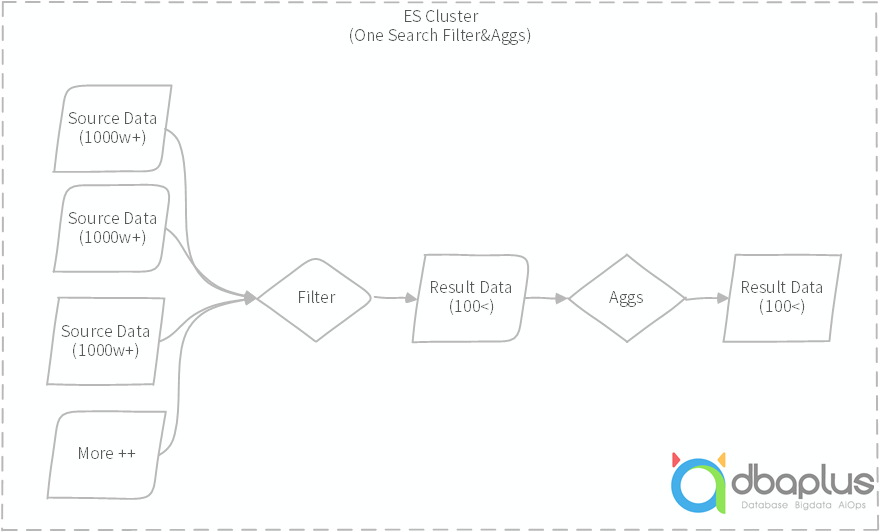
图示:案例查询过滤示意图,原始数据量很大,筛选之后结果数据极小。
严格意义上看,企业应用中所谓的数据分析型项目,都是为了满足业务应用需求,只是由于AP需求复杂度高,需要的技术栈复杂度提高,需要专业的技术栈来做,不能简单的采用常规的TP技术栈实现,但本质上都是应用系统,是业务需要的应用系统。如果按照TP与AP严格界定,那么项目的架构方案就会不一样,相应的技术栈选择也不一样,实施的复杂度与周期也就不一样,这应该不是企业需要的。
经常看到各种数据产品的性能比较文章,有的是一些在线培训机构,有的是一些产品厂家,多数都是参考价值不高的对比。纯粹的技术性能比较是毫无意义的,一定要基于业务需求前提。如,clickhouse、doris等,经常出现在各种性能对比的场景中,强调各自性能强悍,等你真上了船,发现一堆坑等着,填完一个接一个,实际使用为什么不是如文所示,到底哪里错了?
如上案例描述,集群数据量数百TB,又是查询聚合统计需求,参考一些性能对比文章,似乎应该采用clickhosue/doris,因为它们在数亿以上数据量聚合性能表现极快,但是相应的会带来更多的问题,如实时写入、复杂筛选条件查询、高并发等,从数据量上来看,它应该是AP场景,应该选择纯粹的AP数据产品,但从上游对接的业务系统,它又属于TP。
如上案例描述,业务系统需要实时写入,业务系统需要实时查询统计,按照大数据领域的技术流派,似乎应该采用Flink+来搞定,上游实时写入到kafka,中间采用Flink实时聚合计算,下游写入到某个数据产品里面供查询。看起来相当完美,实际上非常不合时宜,首先海量数据数百TB存储是个大问题,Flink不解决;其次业务系统数据实时写入更新,kafka只能解决实时写入,不能解决实时更新,Flink更不擅长数据存储;再次,业务系统实时查询聚合数据,依据多种筛选条件,需要基于历史数据与实时数据,Flink做不到此类型场景;最后,聚合结果实时查询,基于Flink的架构需要数据输出到某些数据产品,多数会选择Elasticsearch,因为其支持极高的写入与查询,若是这样,几乎就是宣告,数据走了一圈又回到了原点。
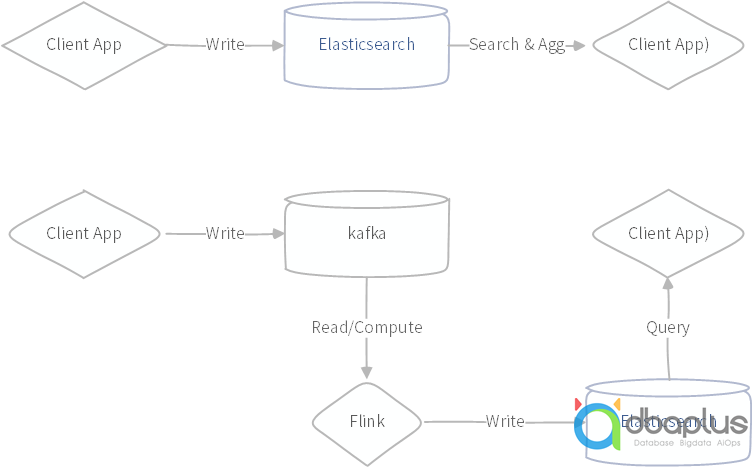
图示:Flink实现的实时计算示意图与Elasticsearch实时查询示意图
结语
以上从一次ES案例性能优化,谈到了ES的一些技术原理,谈到了业务形态与技术形态,仅代表个人观点认知,若有异议,欢迎讨论。
参考资料
terms-aggregation 分桶聚合统计
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations-bucket-terms-aggregation.html
term 性能优化提升 来自es官方性能优化提升博客
https://www.elastic.co/cn/blog/improving-the-performance-of-high-cardinality-terms-aggregations-in-elasticsearch








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721