
本文根据许鹏老师在〖2021 DAMS中国数据智能管理峰会〗现场演讲内容整理而成。

(点击文末“阅读原文”可获取完整PPT)
讲师介绍
许鹏,携程 研发总监。专注于分布式计算和存储,对Spark和PostgreSQL有深入研究,拥有多年Presto和Elasticsearch的运维经验。
分享概要
一、模型开发到部署 – 路漫漫
二、模型开发全生命周期管理
三、MLFLOW全链路管理
四、统一化部署
五、小结
机器学习模型的开发和使用日趋火热,随着较大范围的采用,一些隐藏的问题也浮出水面,最常见的就是模型开发部署链路太长,开发周期长,迭代成本高。本文就简单聊一聊携程机票是如何引入MLFLow来进行机器学习模型开发的全生命周期管理,对MLFlow进行了哪些适配和改进。
一、模型开发到部署 – 路漫漫
机器学习模型从开发到部署上线,并提供在线预测功能,是一个非常长的链路,用山路十八弯来形容一点不为过。
一般来说,整体流程涉及到以下几个阶段
特征工程
模型选择
模型训练
模型测试
模型部署
模型效果评估和迭代
在整个开发链路中,算法分析团队负责模型训练, 系统团队负责模型部署。但分析团队以何种方式把模型交给系统开发团队来部署呢? 常见的是PMML文件,这种方式最大的缺点就是模型调用前的数据预处理和预测后的数据整合要由系统开发团队来完成,这意味着机器学习模型的代码逻辑要同时由算法分析团队和系统开发团队来完成,不仅添加了转译成本,同时延长了整个模型上线的周期。
理想的方式是系统开发团队实现一个好的模型部署平台,算法分析人员开发的模型代码中包含了数据预处理和模型结果的后处理功能,并且这个模型代码可以被平台直接加载运行,系统开发团队不直接触及某一具体模型的代码开发。
算法分析人员负责模型开发,而系统开发人员负责整个模型平台的开发,以及满足测试性能的模型上线。算法分析团队和系统开发团队的职责范围和边界有清楚的规范和厘清。
二、模型开发全生命周期管理
有问题就有方案,在开源的世界里就是这么神奇!没有做不到,只有想不到。
模型开发到部署的全生命周期管理方案可能就是我们要找的方向, 但具体选用哪一家就成了一个问题。
模型开发全生命周期管理的方案有很多,MLFlow是知名度很高的一个,由Apache Spark之后的公司Databricks出品,具有天然的品牌优势和品牌号召力,该项目在github上获得的星数超过10K。
三、MLFLOW全链路管理
MLFlow中涉及到的概念和组件比较多,一下子抛出全图,会引起理解上的偏差和混乱。我们先从最简单最核心的问题开始,看看最朴素的方案是什么,然后以此为前提和MLFLOW这个成熟的方案中组件对应起来理解,就要方便很多。
模型生命周期管理中最核心的问题是模型的保存和加载, 如果由自己来实现这个功能,会如何进行操作?
其实思路也很简单和直接,大体步骤如下
训练模型
训练好的模型进行序列化
在生产环境反序列化模型并加载
以scikit-learn为例,举一个最精简的例子
1)模型训练和持久化
from sklearn import svmfrom sklearn import datasetsclf = svm.SVC()X, y= datasets.load_iris(return_X_y=True)clf.fit(X, y)import picklemodel_filename = 'finalized_model.sav'pickle.dumps(clf, open(model_filename, 'wb'))
2)模型加载和反序列化
model_filename = 'finalized_model.sav'clf2 = pickle.loads(model_filename,'rb')clf2.predict(X[0:1])
MLFLOW众多组件中, 以Tracking Server最为核心和关键,Tracking Server充当模型管理中心的角色。
训练阶段 训练好的模型序列化之后保存到Tracing Server
部署阶段 从tracking server下载文件并反序列化
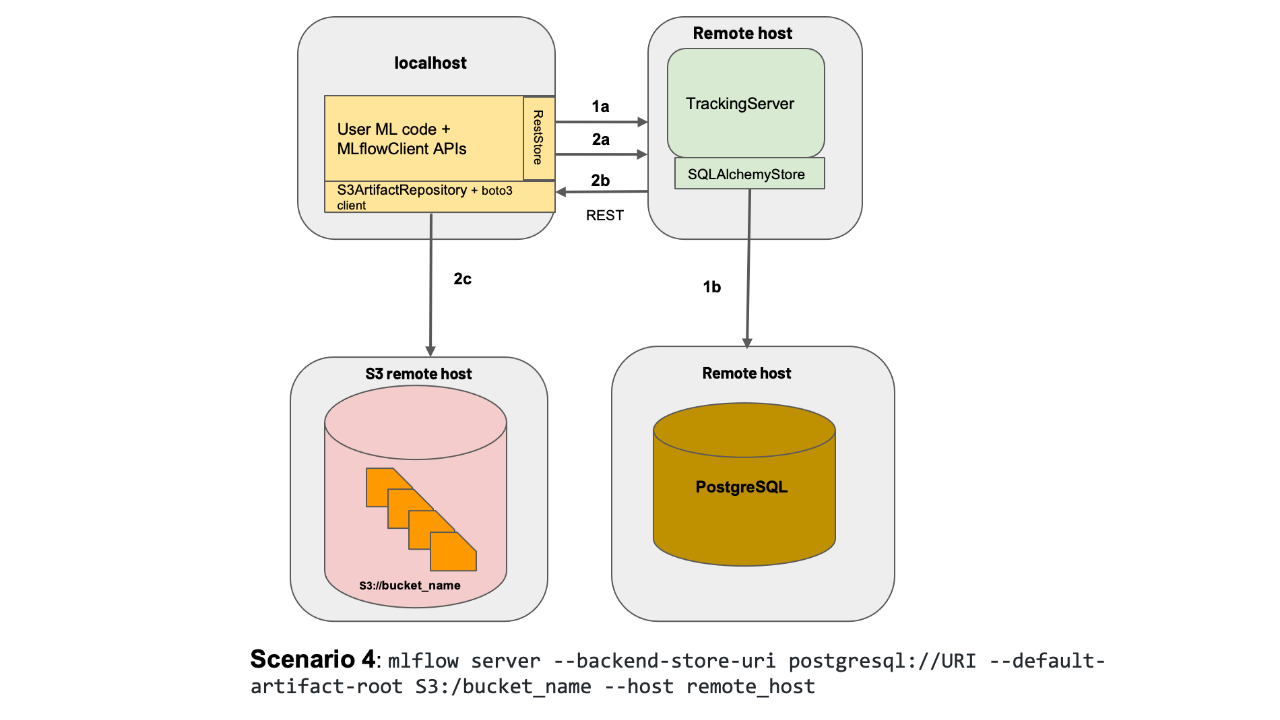
具体来说, Tracking Server负责保存的内容分为两大类:
模型文件 内容保存到artifacts server, 支持HDFS、S3、FTP Server
元数据 内容保存到数据库backend store, 支持的数据库包括MySQL、Sql Server、PostgreSQL
举一个例子吧, examples/sklearn_elasticnet_wine/train.py, 这是mlflow项目中的一个example, mlflow的git地址:https://github.com/mlflow/mlflow.git
import osimport warningsimport sysimport pandas as pdimport numpy as npfrom sklearn.metrics import mean_squared_error, mean_absolute_error, r2_scorefrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import ElasticNetfrom urllib.parse import urlparseimport mlflowimport mlflow.sklearnimport logginglogging.basicConfig(level=logging.WARN)logger = logging.getLogger(__name__)def eval_metrics(actual, pred):rmse = np.sqrt(mean_squared_error(actual, pred))mae = mean_absolute_error(actual, pred)r2 = r2_score(actual, pred)return rmse, mae, r2if __name__ == "__main__":warnings.filterwarnings("ignore")np.random.seed(40)# Read the wine-quality csv file from the URLcsv_url = ("http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv")try:data = pd.read_csv(csv_url, sep=";")except Exception as e:logger.exception("Unable to download training & test CSV, check your internet connection. Error: %s", e)# Split the data into training and test sets. (0.75, 0.25) split.train, test = train_test_split(data)# The predicted column is "quality" which is a scalar from [3, 9]train_x = train.drop(["quality"], axis=1)test_x = test.drop(["quality"], axis=1)train_y = train[["quality"]]test_y = test[["quality"]]alpha = float(sys.argv[1]) if len(sys.argv) > 1 else 0.5l1_ratio = float(sys.argv[2]) if len(sys.argv) > 2 else 0.5with mlflow.start_run():lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)lr.fit(train_x, train_y)predicted_qualities = lr.predict(test_x)(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)print("Elasticnet model (alpha=%f, l1_ratio=%f):" % (alpha, l1_ratio))print(" RMSE: %s" % rmse)print(" MAE: %s" % mae)print(" R2: %s" % r2)mlflow.log_param("alpha", alpha)mlflow.log_param("l1_ratio", l1_ratio)mlflow.log_metric("rmse", rmse)mlflow.log_metric("r2", r2)mlflow.log_metric("mae", mae)tracking_url_type_store = urlparse(mlflow.get_tracking_uri()).scheme# Model registry does not work with file storeif tracking_url_type_store != "file":# Register the model# There are other ways to use the Model Registry, which depends on the use case,# please refer to the doc for more information:# https://mlflow.org/docs/latest/model-registry.html#api-workflowmlflow.sklearn.log_model(lr, "model", registered_model_name="ElasticnetWineModel")else:mlflow.sklearn.log_model(lr, "model")
上述代码和一般的模型训练的区别不大,就是引入了mlflow包,注意持久化模型,需要执行 start_fun(), 然后结合使用到的机器学习库调用 log_model
1)训练和持久化模型
python train.py
模型训练完成后,接下来要做的是模型部署和线上测试。
虽然训练好的模型可以通过tracking server来拿到,但是为了成功实现反序列化, 模型使用到的依赖模块必须在运行环境中也要存在,不然会出现反序列化失败。
MLFLOW自身支持serve功能,serve需要依赖于conda, 把依赖的library用conda.yaml来进行声明。
2)MLProject
name: tutorialconda_env: conda.yamlentry_points:main:parameters:alpha: {type: float, default: 0.5}l1_ratio: {type: float, default: 0.1}command: "python train.py {alpha} {l1_ratio}"
3)conda.yaml
name: tutorialchannels:- conda-forgedependencies:- python=3.7- pip- pip:- scikit-learn==0.23.2- mlflow>=1.0- pandas
4)conda自动安装运行
mlflow models serve -m /Users/mlflow/mlflow-prototype/mlruns/0/7c1a0d5c42844dcdb8f5191146925174/artifacts/model -p 1234
如果模型非常复杂,需要同时使用scikit learn和keras中的模型,那么可以使用pyfunc模块来进行组装。
class MyModel(mlflow.pyfunc.PythonModel):def load_context(self, context):# load your artifactsdef predict(self, context, model_input):return my_predict(model_input.values)
1)模型持久化
mlflow.pyfunc.save_model(path=mlflow_pyfunc_model_path,python_model=MyModel(),artifacts=artifacts)
2)模型加载
loaded_model = mlflow.pyfunc.load_model(mlflow_pyfunc_model_path)
四、统一化部署
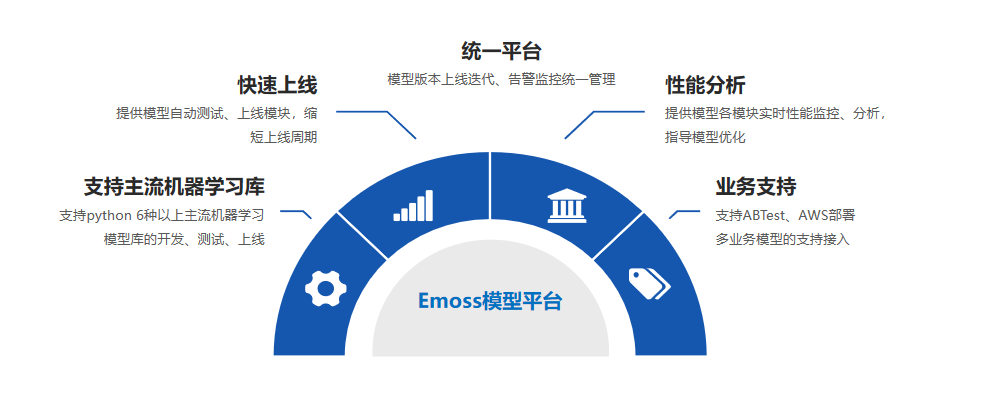
MLFlow社区版已经提供了模型的tracking和部署,能够满足基本的生产环境部署要求。如果我们需要部署更多的模型或者支持同一模型不断进行迭代,那么还需要做一些改进和加强。
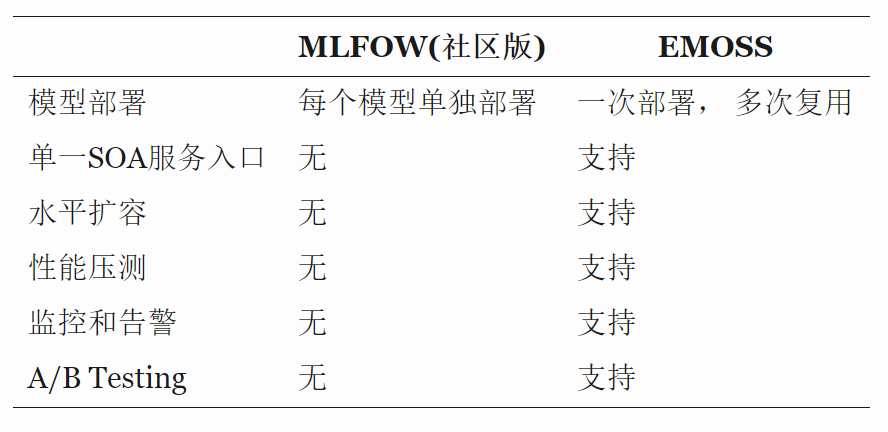
基于MLFLOW社区版,结合公司的生产部署工具,我们开发实现了EMOSS(Easy Model One-Stop Service), 下表给出了两者之间的区别。
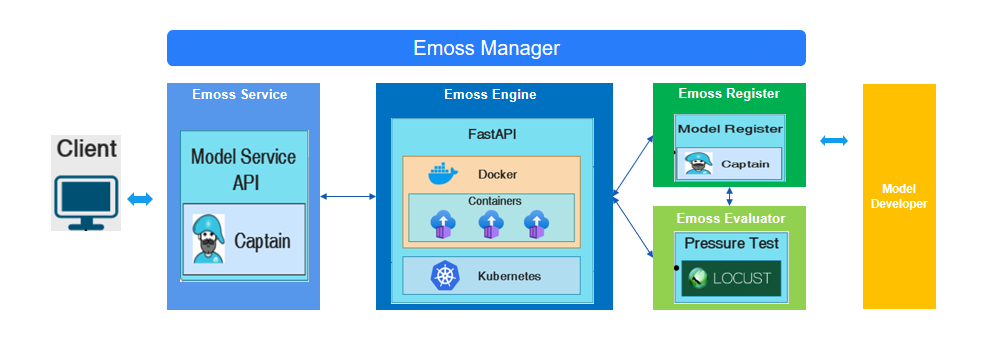
模型服务整体架构如上图,调用流程描述如下:
模型应用的客户端会首先和模型的SOA Server进行交互,传递的消息中含有要调用的Model名称和喂给Model的入参数据
Model SOA Server根据Model名称,把请求智能路由到后台的Model Restapi Server
Model Restapi Server负责模型的真正预测
class MyModel(mlflow.pyfunc.PythonModel):def preProcess(self, context, model_input):# preprocessdef load_context(self, context):# load your artifactsdef postProcess(self, context, model_input):# postprocessdef predict(self, context, model_input):#preProcess#real_model = load_real_model#predict#postProcess
每一个模型抽像成,预测前/预测/预测后
预测前: 负责数据处理和部分特征加载
预测: 将处理好的数据喂给真正的模型
预测后:将预测后的结果处理成客户端易于理解的形式并返回
Model Restapi Server运行在Docker环境, 所需要的Python Module会在Dockerfile指明,这样生成的镜像就会含有运行时所有的依赖文件。如果后续迭代的模型版本依赖文件发生更改,就意味着要修改Dockerfile并重新生成镜像。
Model Restapi Server基于FastAPI进行开发, 采用和uvicorn结合的方式,请求能在较短时间内完成处理,提供了很好的服务性能。
如果模型调用的请求量非常大,需要考虑水平扩容。在水平扩容的方案上,使用的是7层代理的模式,使用公司提供的SLB服务,我们可以在几分钟内完成扩容工作。
这当中遇到的问题是基于7层的代理来水平扩容,会有比较明显的长尾效应,P999的响应时间不是特别好。后续会尝试Service Mesh和其它方案。
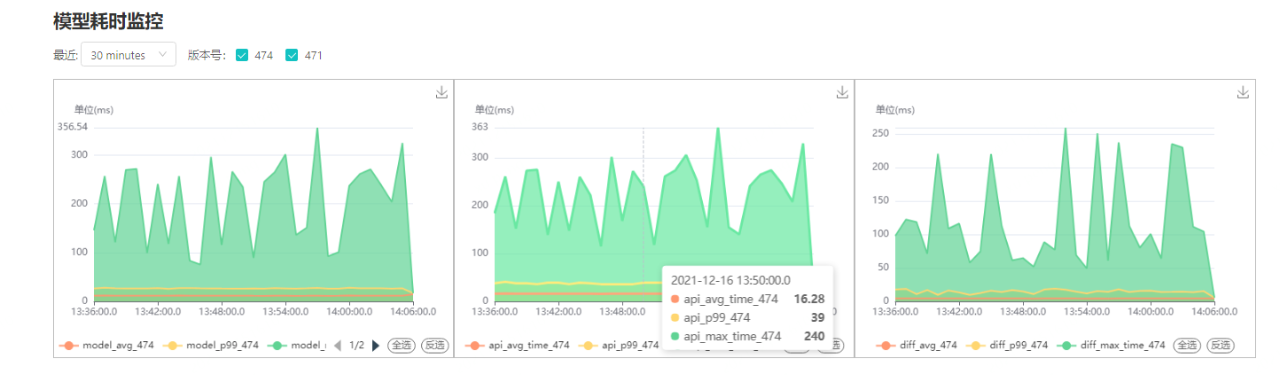
为了方便性能监控,在Model SOA Server侧和Model Restapi Server侧分别进行了性能埋点,利用这些埋点数据可以方便计算出预测耗时和接口调用耗时。
这些埋点数据首先会落入到Kafka, 利用Flink同步到PostgreSQL, 在PostgreSQL中使用了timescaledb插件 ,该插件对时序数据自动进行分区,基于时间过滤掉不必要的分区,我们很快计算出相应的性能指标。
五、小结
在我们的实践中,还没有涉及到单一一个请求,在做预测的时候,计算非常复杂,需要分布式计算才能满足性能要求的场景, 这一块如果后续在实际业务中有需求时,我们会做进一步的调研和试用。
本文的描述比较简略,MLFLOW的功能很强大,迭代速度也很快,我们只使用到其中部分功能,难免有不够准确的地方,还请各位看官多指正。
↓点这里可下载本文PPT,提取码:xp17








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721