
诸葛子房
大数据专家
原就职于京东,参与京东618实时数据大屏。后就职于BAT,在大数据行业有多年从业经验。
今天主要从以下几个方面展开讲述:

一、引言
第一主要讲一下大数据的处理流程。比如说大数据的话主要是面向于OLAP的这种、线上业务的话就是OLTP,像是线上产生的在京东上的购物、订单数据,在抖音上的浏览、日志数据等。
在大数据建设过程中,通用的建设思路:从数据埋点——数据采集——数据清洗(ETL)——数据服务——数据可视化。整体流程可参考下图:
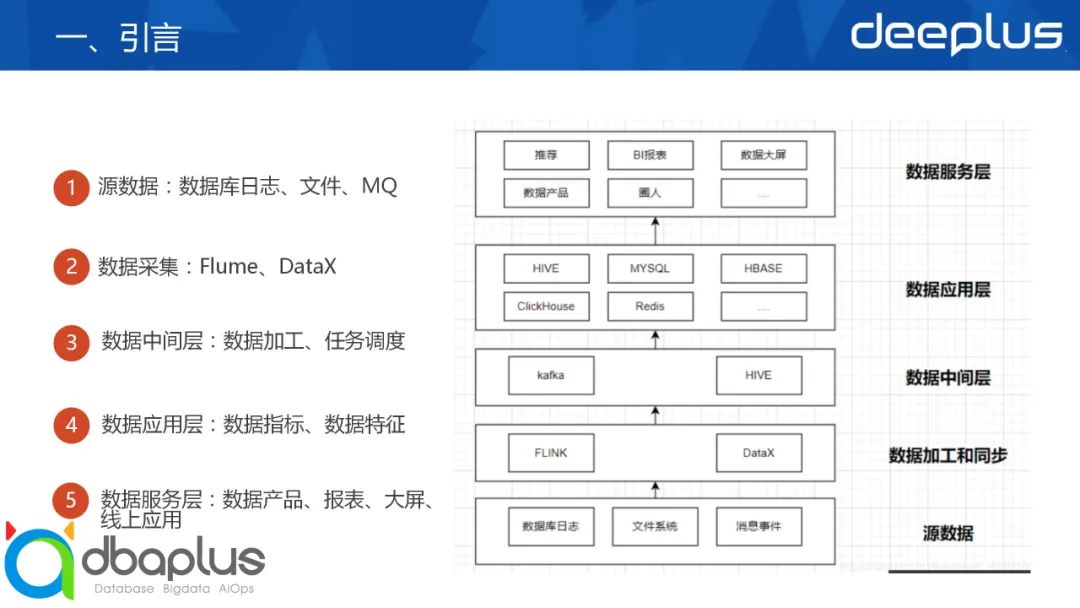
二、背景
1)场景多样化:推荐、营销、报表、大屏、数据产品
2)数据接口形式多样化:API、RPC、实时流、文件
3) 数据接口性能要求多样化:QPS、RT
推荐:QPS亿级、RT毫秒级
报表:QPS低、RT秒级、报表数量2w+
大屏:QPS低、RT毫秒级,数据推送实时更新
营销圈人:QPS要求低、RT要求低,圈人数据量大(千万甚至亿级)
数据产品:数据产品服务多样化,数据服务10w+
4)数据存储多样化:Hbase、Redis、MySQL、Doris、Hive...
5)执行引擎多样化:java、C++、Go、Client、SQL
6)数据指标多样化
比如说同一个指标在不同的场景下它的定义可能不太一样
销售指标
流量指标
用户特征
因此数据服务化迫在眉睫!
接下来讲一下数据服务化需要解决的问题,即“三个One”:
数据服务统一化:接口不同QPS和RT,不同的接口服务(HTTP、RPC、文件传输等),即:OneAPI
存储解析统一化,一套语言支持多种数据存储接入,即:OneSQL
数据模型统一化,支持多种数据源接入, 即:OneModel
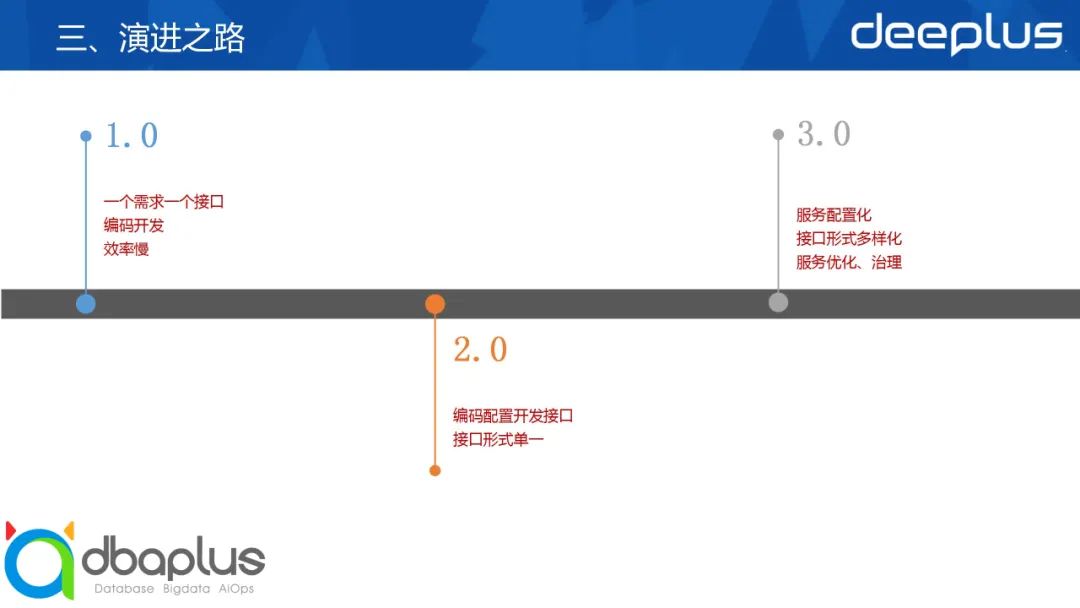
三、演进之路
如图所示,大数据平台的演进之路主要分为三个阶段:
接下来讲述一下大数据服务平台的核心架构。
四、核心架构设计
数据服务平台能够解决数据服务统一化,便于数据服务的治理、指标口径的统一。能够提升业务的开发效率,更快的面对业务的变化。数据服务平台主要分如下三层:
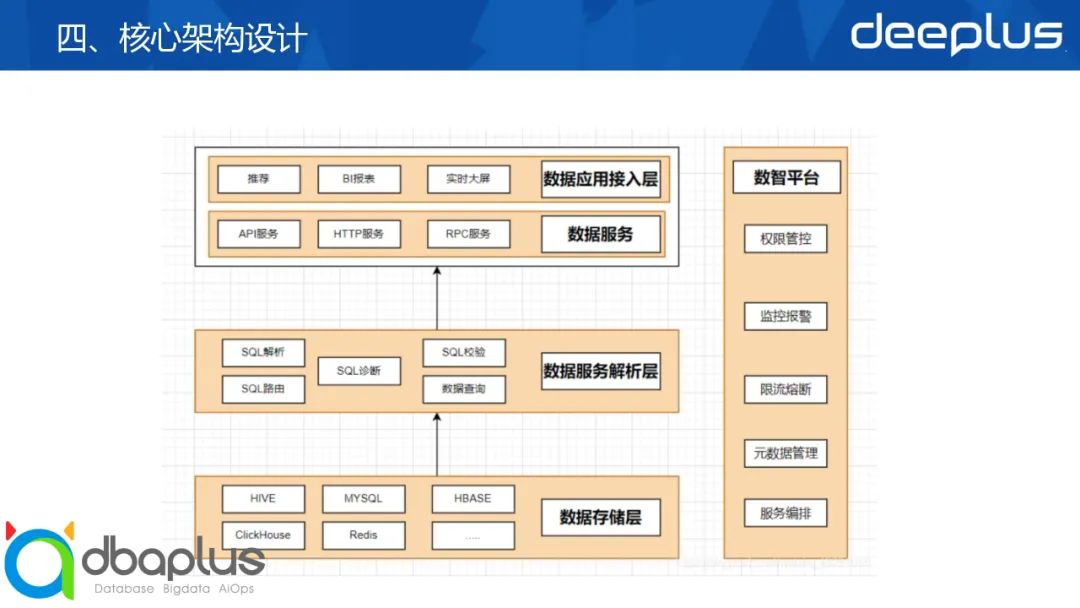
旁边的话主要是对平台的管控,比如权限管理、监控、限流熔断、元数据管理、服务编排等,这一块后面会展开给大家讲一下。
数据应用接入层:主要是针对外部应用接入,包含:HTTP服务、RPC服务、Client 服务、流服务、文件服务
数据服务解析层:主要通过SQL方式访问各种数据存储,然后生成对应数据服务。基于Apache Calcite。核心功能:SQL解析、SQL校验、SQL路由、SQL优化、SQL执行、SQL诊断限流
这里简单解释一下SQL诊断限流。比如说我们很多报表都在用同一个库里的某一张表,然后可能有些人写的SQL不是很准确或者说有问题,但它也能跑出来数据。比如BI,他们的SQL能力可能没有那么强,不会优化SQL,可能写的SQL就有问题。然后跑出来的数据就非常慢,可能会导致它的请求一直在挡这个表,把这个表拖垮,甚至可能导致这个库被拖垮,这样的话我们就需要对它进行诊断。当我们发现它超过一个耗时还没有返回数据,我们就需要把它的请求截断,避免影响其他业务。
数据存储层:主要包含数据的存储管理,MySQL、Redis、Hive等等。都能很好的支持、提供API服务
接下来我们来看一下数据服务生产的整体流程:
选择数据存储(Hbase、MySQL等等)
配置查询SQL和参数
//统计某一天的每个店铺的销售额selectshop_id,sum(gmv) as total_gmv from (select * from table where dt=#{dt}) tgroup by shop_id;
根据选择数据存储引擎,将SQL转化成可执行的语言进行执行
生成原子接口服务
至此一个API服务就完完整整的生成了,可以理解为一个原子服务。
但是问题仍然来了,生产了一个根据用户id查询订单的原子服务A,生产一个根据订单id查询商品的信息的原子服务B。流程图如下:
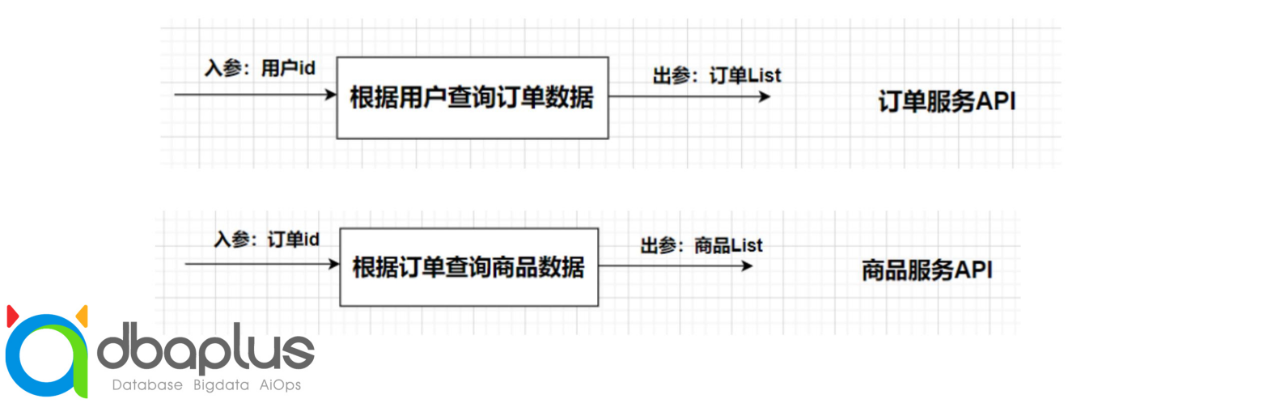
如果需要查询出某个用户下某个订单的所有商品信息,就需要先调用订单服务API,然后根据返回的结果调用商品服务API,最后才能拿到想要的信息。
这个过程可能需要调两个服务。大家可能会想:我自己用代码写一个不就完了嘛。现在是两个服务,以后可能是三个服务、四个服务,服务之间可能有一些业务逻辑,这样的话你是用代码能够写出来。但是如果需求再变更,你是不是还要修改自己的代码或修改自己的业务逻辑?然后加上上线、测试等等,这种耗时是非常长的
当调用的服务越来越多,需要手动开发的成本越来越高,上线、发版还有测试这种时间是非常长的。中间的数据转化成本也越来越高,像上文所说,一个接口的出参不一定是另一个接口的入参,这样的话你可能需要做一些参数的转换。
因此,低代码平台(Low Code)服务编排应运而生。
服务编排:指对于原子服务进行串接、参数转换,以及一些业务逻辑的判断进行处理,只需要编写少量的代码即可完成
下面用例子来讲解一下:
服务串行:

订单服务的出参经过数据格式的转换作为商品服务的入参,将服务串联起来。
服务并行:
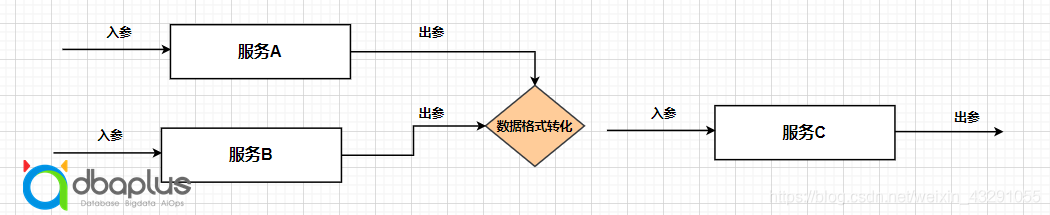
C接口需要等待AB接口同时调完才能进行。
服务不同逻辑处理:
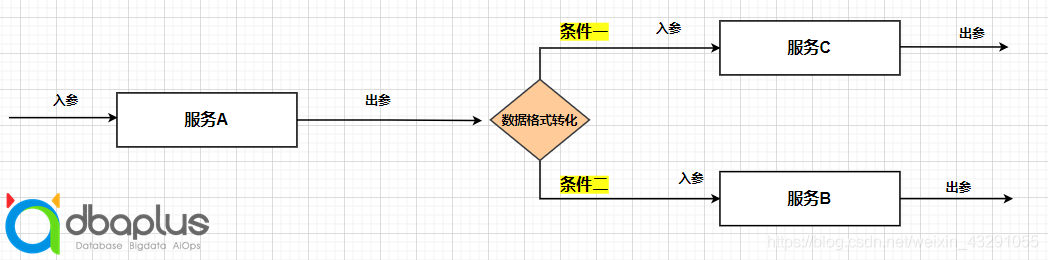
这里需要进行一个逻辑的判断。
五、展望与总结
本次演讲内容介绍大数据服务平台整体建设思路和实践,但仍然难免有些疏漏:
随着国内数据库发展迅速,比如:国产IOT相关的数据库,Tdengine,如何将IOT相关的场景引入进来,更快地支持更多的数据存储。
数据平台服务化在大数据整体建设中如何扩大其服务对象,包括对:数据分析人员、运营人员甚至算法训练师,而不仅仅是针对数据人员和开发人员;
面向算法人员:支持算法服务化、算法编排、策略编排;
面向分析师和运营人员:支持报表数据管控。
参考资料
某互联网大厂亿级大数据服务平台的建设和实践
https://blog.csdn.net/weixin_43291055/article/details/119669207
唯品会亿级数据服务平台落地实践
https://www.infoq.cn/article/SNhV8IWXfl6j7O0GuVRB
《阿里巴巴大数据之路》
Q&A
Q1:低代码平台是否能满足所有的数据服务需求?
A1:基本上是能满足所有的数据服务要求的,但是非常负责的业务逻辑的话是不建议的。
Q2:报表的数据服务是什么样的?
A2:主要是看报表支持数据的形式,比如说:如果是http就以http来进行支持。
Q3:能讲一下数据服务平台的技术框架吗?
A3:技术的话,主要分三层:
数据存储层主要是一些数据存储组件
数据解析层是采用Apache Calticle 来进行解析的
数据服务层是一些API服务
整体框架其实基于spring boot来搭建的一个服务平台
Q4:在平台初步建设时是否有相应的措施来保证平台稳定性和可拓展性?
A4:这个的话其实就是考虑如何做到扩展性了,比如说不同的数据存储,我们通过抽象的方式预留可能会新增的数据存储引擎来达到可拓展性
稳定性这块的话,其实一个平台的核心,无论是初期还是后来,初期上线之前建议自测+测试,上线之后完善相应的监控,后续上线迭代的时候尽量灰度上线,避免影响线上业务。
Q5:SQL解析用的组件,是拿来直接用吗?需要二次开发来适配各个存储引擎吗?
A5:如果新引入组件的话,是需要进行简单开发的。这边设计的时候对存储引擎的解析这块做了抽象,因此新的存储引擎接入的话,开发成本不会太高。
Q6:底层能支持哪些存储?
A6:目前已经实现了Hbase、MySQL、Redis、ClickHouse 这些场景的数据存储。
Q7:sql的诊断目前只用耗时来判断的吗?
A7:Sql诊断这块的话,现在是主要靠耗时来进行判断,当然也会结合QPS同时进行判断。
Q8:sql的限流跟服务的限流区别是啥?
A8:服务限流的话,主要是针对服务的QPS来进行处理的,而SQL的限流的话,主要是针对于SQL耗时这块进行处理的。
Q9:我理解这个数据服务平台需要和数据采集,大数据平台,数据开发中心,数据资产平台搭配使用。
A9:这个是一整套的大数据解决方案,但是我提到的数据服务平台其实是可以独立出来的,因为不同的公司可能大数据处理和采集是不一样的,但是存储这块其实都是一些数据存储引擎,了不起可能有些公司会多一些,这部分其实可单独出来。
Q10:和linkis有什么区别?
A10:Linkis是微众开源的大数据解决方案,我分享的内容其实主要核心是希望通过OneSQL 来构建服务化,毕竟SQL 是最简单的语言,相信我这么说没人有质疑吧。
Q11:如何在平台演讲过程中保证数据的质量与安全?
A11:数据安全的话,其实数据服务平台这块主要是针对API服务是需要申请的。
数据质量的话,服务平台这块暂时不会考虑接入进来,因为市面上其实也有一些数据质量相关的平台,比如说开源的Apache Griffin。毕竟大数据服务平台的核心是服务化。
Q12:异构数据源查询能支持吗?异构数据源混合查询呢?
A12:数据服务平台是根据选择的存储引擎来构建服务的,因此每次生成的是原子服务,是支持持一种数据源的。可以通过结合低代码平台进行组装实现不同的原子服务来进行编排,因此是能支持异构数据的。
Q13:API生命周期管理以及安全控制是怎么做的?
A13:API管理的话,第一部分就是权限管理,比如说你创建的API服务,其他需要申请才能访问和使用,这是对于数据安全的管控。
API生命周期主要是对于一些API可能没有被调用,需要进行下线。这样的话,我们就需要定期对于那些没有流量访问的API进行追踪或者下线了。
获取本期PPT,请添加群秘微信号:dbachen
↓点这里可回看本期直播
阅读原文









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721